本文由 简悦 SimpRead 转码, 原文地址 www.zhihu.com
iker 同学
简单来说,右值引用就是这个东东, 比我们传统所了解的左值引用多了一个 & 符号。
1 | T&& |
老规矩,先从概念入手。拆分一下有两个概念:右值 和 引用。引用自然不必多说,先看看什么叫右值。
根据
https://en.cppreference.com/w/cpp/language/value_category#cite_ref-1
现代 c++ 把表达式分为三种主要类型,每一个 c++ 表达式都可以被确切的分为以下某一类:
实际上 prvalue 和 xvalue 都属于右值。
1. 值分类
1.1 左值(lvalue)
左值不能简单理解为就是等号左边的值,其实只要能取地址,那这个表达式就是左值。可以取地址意味着在程序的某块内存地址上已经存储了他的内容。
举例一些常见的左值:
- 具名的变量名
- 左值引用
- 右值引用也是左值
- 返回左值引用的函数或是操作符重载的调用语句。
- a=b, a+=b, 等内置的赋值表达式。
- 前缀自增。如 ++a, –a 是左值。
- 字符串常量
- 左值引用的类型转换语句。如 static_cast
1 | int a = 1; |
这里 a 是左值,因为 a 这个变量确实被存到内存里了,并且在内存里面写入的值是 1. 同理,str 也是左值。
那数字常量 1 是左值吗?并不是,1 是在运行到这行代码是,临时产生的一个值,他是没有地址的, 仅仅存在寄存器中用作临时运算。所以数字常量 1 不是左值。
那么 “hello” 这个字符串常量,请问他是左值还是右值? 按照惯性思维,既然前面的数字常量 1 都不是左值,那这里字符串常量是不是也不是左值?
然而事实上, “hello” 这个字符串常量实实在在的是左值,原因如下:
简单来说,编译的时候, hello 这个字符串会真的被单独的存放在某一内存地址上存储,一般是静态数据区。所以你直接对 hello 这个字符串常量 取地址(&),是完全可以取到的。能取到地址说明他就是个左值。
而为什么要特意把字符串常量存放在静态数据区呢?思考一下,当要赋值 hello 字符串给某个变量的时候。 hello 这个字符串从哪里来呢呢?运行时再让寄存器构造一个 hello 的值吗。这显然不是高效的做法。既然编译的时候我就知道了程序总共用到了哪些字符串常量,我提前把所有的字符串常量都放在某块内存地址上,用到的时候再从这里拷贝就好了。况且如果是字符串常量重复使用的话,还可以节省效率。
总之,我们知道只要能取得地址,那就说明是左值。因为能取地址,那么我们就能修改它的值 (理论上都能修改,只是比如字符串常量一般是不能修改的),所以左值是能放在等号左边的,我们能给左值进行赋值。
引出几个问题: 左值一定能赋值?
不是, 字符串常量是左值,但不能修改其值。
左值一定能取地址? 是的。
1.2 纯右值(prvalue)
prvalue 是纯右值,他是属于右值的一种。
右值是临时产生的值,不能对右值取地址,因为它本身就没存在内存地址空间上。
举例纯右值如下:
- 除字符串以外的常量,如 1,true,nullptr
- 返回非引用的函数或操作符重载的调用语句。
- a++, a– 是右值
- a+b, a << b 等
- &a,对变量取地址的表达式是右值。
- this 指针
- lambda 表达式
理解也很简单,其实就是一些运算时的中间值,这些值只存在寄存器中辅助运算,不会实际写到内存地址空间中,因此也无法对他们取地址。
1.3 将亡值(xvalue)
xvalue 叫将亡值,顾名思义,就是即将销毁的东西。xvalue 也是右值的一种。
主要记住这两种就行了:
- 返回右值引用的函数或者操作符重载的调用表达式。如某个函数返回值是 std::move(x), 并且函数返回类型是 T&&
- 目标为右值引用的类型转换表达式。如 static
xvalue 和 prvalue 都是属于右值,你不必对它们过度的区分。
2. 左值引用和右值引用
说了这么多,其实没必要去真的纠结哪些是左值,哪些是右值。心里有点数能区分常见的就行了。右值引用才是重点。先复习一下左值引用。
2.1 左值引用
左值引用是我们很熟悉的老朋友了,左值引用可以分为两种:非 const 左值引用 和 const 左值引用。
有很重要的一点是,非 const 左值引用只能绑定左值;const 左值引用既能绑定左值,又能绑定右值!
1 | int a = 1; |
可以看到,lref_const_rvalue 是 const 左值引用,但是他直接绑定到一个右值(数字常量 999)上了。有没有想过为什么 c++ 要这么设计呢?
举个例子,你要设计 print 方法。如何设计 print 方法的参数呢?
首先,考虑到值传递参数会产生额外的拷贝,这是难以接受的。于是你想到了引用传递(你要用指针?那这篇文章不用看了。。。)。
1 | void print(int& a); |
于是添加数据需要这样:
1 | int a = 1; |
好像有点麻烦,有时候你只需要添加一个常量(数字常量就是右值)进去,你还有首先声明一个变量,有点麻烦,如果能直接这样添加就好了:
1 | print(1); |
也就是说,无论入参是左值和右值,push 函数都能正常接收。于是,用 const 左值引用 可以解决这个问题。实际上不知不觉中我们很多代码都用到了这种参数形式。
1 | void print(const int& a); |
然后就只可以直接 print(1) 了。当然,由于是 const 左值引用,因此你无法修改其值。只可读不可写。
ok, 左值引用掌握到这种程度就可以了。接下来是右值引用。
2.2 右值引用
不像左值引用那么麻烦,右值引用只能绑定到右值上。如下:
1 | int b = 2; |
2.3 move 语义
那如果是一个左值,我们有办法把它标记为右值吗。可以,使用 move 语义。
std::move 也是随着右值引用诞生的重要语法。move 这个词看上去像是做了资源的移动,其实真的吗?并不是。 move 唯一做的事情其实就是个类型转换。如 cppreference 原文:
In particular, std::move produces an xvalue expression that identifies its argument t. It is exactly equivalent to a static_cast to an rvalue reference type.
翻译过来就是:move(x) 产生一个将亡值 (xvalue) 表达式来标识其参数 x。他就完全等同于 static_cast
所以说,move 并不作任何的资源转移操作。单纯的 move(x) 不会有任何的性能提升,不会有任何的资源转移。它的作用仅仅是产生一个标识 x 的右值表达式。
而经过 move 之后,就能用右值引用将其绑定:
1 | int b = 2; |
2.3 函数重载
到这里,你会发现右值引用以及 move 好像都也没什么用, 凸显不出它跟左值引用有什么特殊点。其他它们主要用在函数参数中。以下是摘自 cppreference 的一个例子:
1 | void f(int& x) |
当函数参数既有左值引用重载,又有右值引用重载的时候, 我们得到重载规则如下:
- 若传入参数是非 const 左值,调用非 const 左值引用重载函数
- 若传入参数是 const 左值,调用 const 左值引用重载函数
- 若传入参数是右值,调用右值引用重载函数 (即使是有 const 左值引用重载的情况下)
因此,f(3) 和 f(std::move(i)) 会调用 f(int&&), 因为他们提供的入参都是右值。
所以,通过 move 语义 和 右值引用的配合,我们能提供右值引用的重载函数。这给我们一个机会,一个可以利用右值的机会。特别是对于 xvalue(将亡值)来说,他们都是即将销毁的资源,如果我们能最大程度利用这些资源的话,这显然会极大的增加效率、节省空间。
2.4 实现真正的资源转移
前面说过,单纯的 move 不会有任何的资源转移,那么到底资源是在哪里转移的呢?
考虑一个很简单的 string 类,我们提供简单的 构造函数 和 拷贝构造函数:
1 | class string { |
注意,由于 m_ptr 是个指针,需要在堆上申请内存空间存放实际的字符串。因此在实现拷贝构造函数的时候,必须要深拷贝,即重新申请内存空间,并且将其内存数据使用 memcpy 拷贝过来。
当向一个数组里面添加 string 元素时:
1 | tmeplate<T> |
当调用 push 方法时,由于入参是左值,因此调用到了函数:
1 | void push(const string& v) { |
函数里面此处调用了拷贝构造函数,将对象 a 完全拷贝了一份到临时对象 tmp 中,再把对象 v 放入到 vector 中。
如图所示:
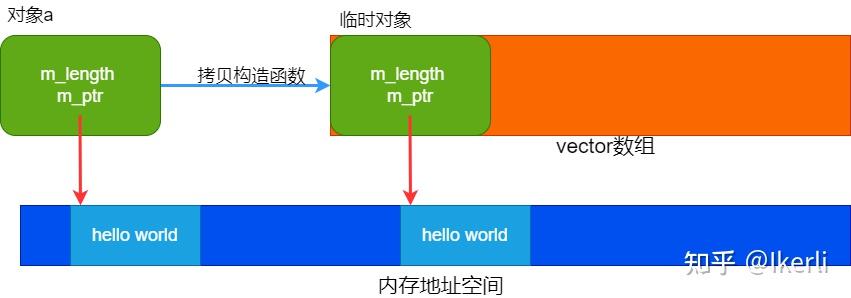
然而实际上我们可以看出来,fun 函数中 a 这个对象已经没用了,出了作用域就被析构掉了。有没有办法能把 a 对象的资源移动,而不是重新拷贝一份呢。这样就能节省很多资源,最大化提高利用率。
有两个问题:
- push 函数如何通过入参来区分对象是应该拷贝资源还是应该移动资源
- 如何用已有的 string 对象通过资源转移构造出另一个 string,而不是调用拷贝构造函数
先思考问题 1,事实上我们知道右值可以用来标识对象即将要销毁,因为他是临时值,只要 push 能区分入参是左值还是右值就知道应该拷贝还是移动了。然而 const T& 这种形参既能接收左值,又能接收右值。
因此需要为 push 函数提供右值引用的重载,根据调用规则,右值会优先调用到右值引用参数的函数 (注意优先级比 const T& 高)。
1 | // const 左值引用 |
如何调用到这个右值引用重载的版本呢,答案是使用 move 。 std::move(a) 产生一个将亡值,将亡值的含义就代表这个变量将要销毁,不应该在使用。注意,move 本身只相当于一个类型转换,而并未对变量做什么移动操作。所以实际上你仍然可以使用 move 后的变量,但这是未定义行为。
然后思考问题 2. 既然不能拷贝,那么需要确保不能调用到拷贝构造函数, 而是一种新的构造函数,这个函数能够通过转移旧对象的资源去构造新对象。
使用右值引用作为参数来重载构造函数能很好解决这个问题,于是在 string 类里面新增加了函数:
1 | string(string&& b) { |
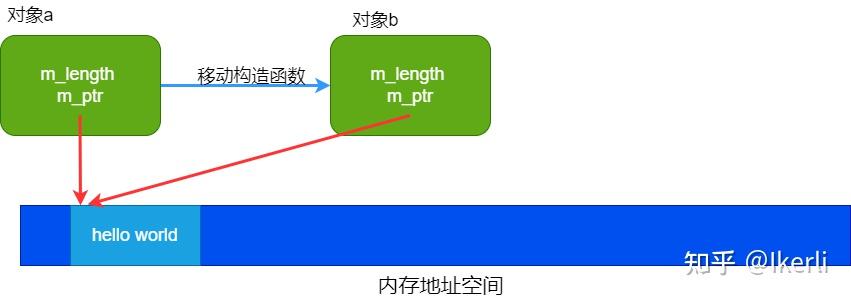
是的,这个函数叫做 移动构造函数。它的参数是右值引用,并且从实现中可以看到,并没有像拷贝构造函数那样重新调用 malloc 申请资源,而是直接用了另一个对象的堆上的资源。也就是在移动构造函数中,才真正完成了资源的转移。
根据前面左右引用函数重载的规则,要想调用移动构造函数,那么必须传入参数为右值才行。使用 move 可以将左值转换为右值:
1 | string a("hello world", 11); |
这里通过移动构造函数将对象 a 资源移动到对象 b 中,如下图所示:
还没完,看前面的代码,我们调用的是 vector 的 push 方法
1 | string a("hello world", 11); |
而此时我想要通过 string 的移动构造函数来转移 a 对象的资源,还需要完善右值引用重载的 push 方法:
1 | // 右值引用重载版本 |
注意必须要加 move。因为 v 虽然是右值引用,但是他是个左值(参考前面所说,具有名字的右值引用是一个左值)。如果没有 move, 那么入参是个左值,将会调用拷贝构造函数。
当我们传入右值时,如:
1 | string a("hello world", 11); |
此时优先匹配到函数 push(string&& v), 自然就调用移动构造函数了。
1 | void push(string&& v); |
以上只介绍了移动构造函数,实际上还有移动赋值运算重载,本质是一样的,不再另说。
当然,STL 标准库的 vector 容器已经提供了右值引用的 push_back 重载,可以用如下代码测试上面的结论:
1 | #include <iostream> |
总之,除了标准库提供的类型,如 string 等。我们自定义类的移动资源操作都需要自己通过编写移动构造函数来实现。
2.5 什么时候应该实现移动构造函数?
先看上面 string 的拷贝构造函数和移动构造函数:
1 | // 拷贝构造函数 |
可以看到,移动构造函数对比拷贝构造函数而言,大多数地方都是相同的复制操作。其实只要是栈上的资源,都是采用复制的方式。而只有堆上的资源,才能复用旧的对象的资源。
为什么栈上的资源不能复用,而要重新复制一份?因为你不知道旧的对象何时析构,旧的对象一旦析构,其栈上所占用的资源也会完全被销毁掉,新的对象如果复用的这些资源就会产生崩溃。
为什么堆上的资源可以复用,因为堆上的资源不会自动释放,除非你手动去释放资源。
可以看到,在移动构造函数特意将旧对象的 m_ptr 指针置为 null,就是为了预防外面对其进行 delete 释放资源。
所以说,只有当你的类申请到了堆上的内存资源的时候,才需要专门实现移动构造函数,否则其实没有必要,因为他的消耗跟拷贝构造函数是一模一样的。
举个例子,如果类成员中有 std::string,那么自己实现移动构造函数是合理的,因为 string 里面存在堆上的资源。反之,如果类成员全是一些 int 变量,那就没必要额外去实现移动构造函数,即使你写了也会发现跟拷贝构造函数是一模一样的。
2.6 万能引用与完美转发
先要了解一下前置知识:引用折叠。
利用 模板 或 typedef,允许出现引用的引用。这些引用会按照一定的规则最终折叠起来:
- 右值引用的右值引用折叠为右值引用
- 其他所有类型折叠为左值引用
1 | typedef int& lref; |
万能引用:万能引用又被叫做转发引用,他既可能是左值引用,又可能是右值引用。 当满足以下两种情况时,此时属于万能引用:
- 函数参数是 T&&, 且 T 是这个函数模板的模板类型
1 | template<class T> |
- auto&&,并且不能是由初始化列表推断出来。
1 | auto&& vec = foo(); |
我们暂时只关注模板参数这种情况。为什么说他是万能引用,是因为它同时支持左值和右值入参。
当我们入参传入左值时,他就是个左值引用;当我们入参传入右值时,他就是个右值引用。通过这个规则,我们可以进而推断出 T 的类型, 以 string 为模板为例:
- 假设入参是一个 string 左值: 此时 T&& 应该等同于 string&, 根据引用折叠的规则,T 应该是一个左值引用,于是得到 T 为 string&,即非 const 左值引用
- 假设入参是一个 const string 左值: 此时 T&& 等同于 const string&,得到 T 为 const string &,即 const 左值引用。
- 假设入参是右值,如 move(string): 此时 T&& 等同于 string&&, 于是得到 T 为 string&&,即右值引用。
我们再思考另外一个问题,当需要在 f 函数中调用其他函数,并且转发参数的时候,例如调用之前讲的 push 函数:
1 | template<class T> |
直接 push(x) 吗? 好像不对。由于这里是万能引用,传进来的入参有可能是个左值,有可能是一个右值。然而形参 x 一定是一个左值,因为他是个具名的对象。直接 push(x) 的话,就相当于入参传递的一定是左值了。
也就是说,不论我们实际入参是左值还是右值,最后都会被当做左值来转发。即我们丢失了它本身的值类型。有没有办法能仍然保留其值属性?左值就按照左值转发,右值按照右值转发?
有的,完美转发 std::forward 就派上用场了。它的定义如下:
1 | template< class T > |
在转发时,只需要这样做就行了:
1 | template<class T> |
是不是迷惑为什么它能实现完美转发?很简单,注意观察 std::forward 的返回值是什么,是 T&&。 根据前面推断模板类型 T 的过程:
- 若入参是 string 左值,则 T 为 string&. 那么 T&& = string& && = string&. 也就是等同于 push(string&) , 自然就会调用到左值引用重载去。
- 若入参是 const string 左值,T 为 const string&, 同理得到 push(const string&), 优先匹配 const 左值引用重载。
- 若入参是 string 右值,T 为 string&&, T&& = string&& && = string&&; 得到 push(string&&), 调用右值引用重载。
可以看到,forward 让完美的保留了参数的值类型,左值就按照左值转发,右值按照右值转发。这也是为什么他可以叫做完美转发。
2.7 copy elision
copy elision 直译过来就是拷贝省略, 简单来说就是在某些情况下,编译器会智能的省略拷贝操作,实现零拷贝,从而提升效率。
为什么在这里提及 copy elision, 它本身与右值引用毫无关系. 但我见过很多误区,一些自以为是的写法导致实际减低了程序的性能。
主要是以下几种情况:
case1: 在函数 return 语句中,返回的操作数是一个与函数返回类型(忽略 const )相同的 prvalue 值,如:
1 | T f() |
在这种情况下,编译器不会调用的拷贝构造函数或是移动构造函数,而是直接使用这个临时变量。整个过程只会调用一次构造函数,没有任何拷贝。这个优化过程叫做 Return Value Optimization(RVO).
另外这种情况也会 copy elision:在初始化一个对象时,如果初始化表达式是一个与类类型相同(忽略 const)的 prvalue , 如:
1 | // 只会调用一次构造函数 |
需要注意的是, RVO 在 c++11 是可选的(非必须,编译器自行决定是否使用),但在 c++17 之后会变成必须的。
case2: 函数 return 语句中,返回的操作数是一个与返回类型相同的(忽略 const)非 volatile 对象,并且不是函数参数。这个优化叫 Named Return Value Optimization(NRVO). NRVO 是可选的。
1 | A g() { |
可以看到,RVO 和 NRVO 都是省略了拷贝的过程,直接复用临时对象。这无疑是一种优化。然而一些自以为是的错误写法可能会导致 RVO 和 NRVO 无法实施,从而反而降低了性能. 例如,以下这几种情况都会降低性能:
case1: 返回 std::move,并且函数返回类型是值类型
1 | A f() { |
这是一种非常典型的错误写法,由于返回返回类型与 return 的操作数的类型不一致,NRVO 无法实施,从而进行了拷贝。不论是拷贝构造还是移动构造都降低了性能。
case2: 返回 std::move,且函数返回类型是右值引用
1 | A&& f() { |
这种情况倒是不会产生拷贝,但返回了局部对象的引用,会导致运行时错误。如果返回的是左值引用,一样的道理。