分布式系统设计实践
基本的理论和策略简单介绍这么多,后面本人会从工程的角度,细化说一下”数据分布“、”副本控制”和”高可用协议”
在分布式系统中,无论是计算还是存储,处理的对象都是数据,数据不存在于一台机器或进程中,
这就牵扯到如何多机均匀分发数据的问题,此小结主要讨论”哈希取模”,”一致性哈希“,”范围表划分“,”数据块划分“
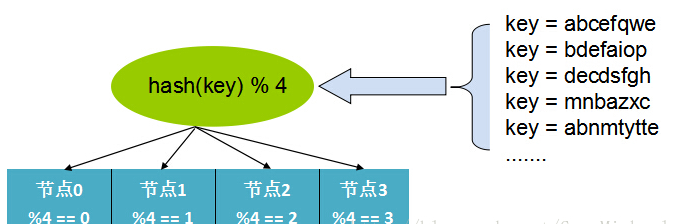
哈希取模:
哈希方式是最常见的数据分布方式,实现方式是通过可以描述记录的业务的id或key(比如用户 id),
通过Hash函数的计算求余。
余数作为处理该数据的服务器索引编号处理。
如图:
这样的好处是只需要通过计算就可以映射出数据和处理节点的关系,不需要存储映射。
难点就是如果id分布不均匀可能出现计算、存储倾斜的问题,在某个节点上分布过重。
并且当处理节点宕机时,这种”硬哈希“的方式会直接导致部分数据异常,还有扩容非常困难,原来的映射关系全部发生变更。
此处,如果是”无状态“型的节点,影响比较小,但遇到”有状态“的存储节点时,会发生大量数据位置需要变更,发生大量数据迁移的问题。
这个问题在实际生产中,可以通过按2的幂的机器数,成倍扩容的方式来缓解,如图:
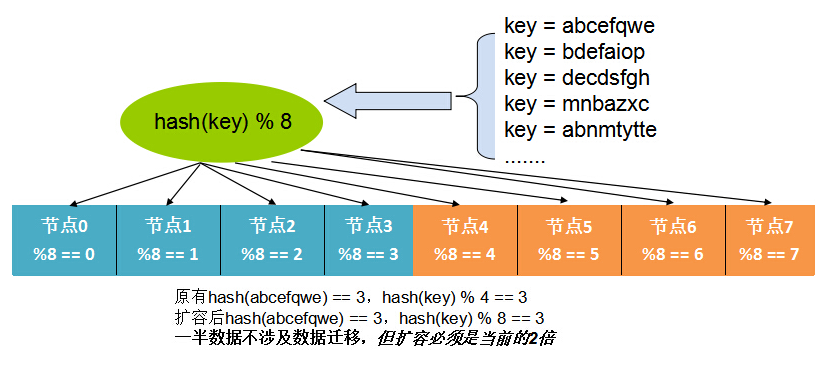
不过扩容的数量和方式后收到很大限制。
下面介绍一种”自适应“的方式解决扩容和容灾的问题。
一致性哈希:
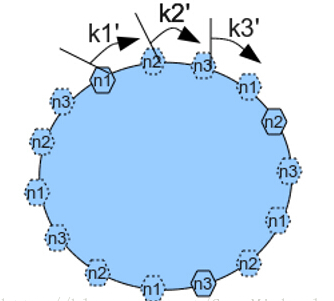
一致性哈希 – Consistent Hash 是使用一个哈希函数计算数据或数据特征的哈希值,令该哈希函数的输出值域为一个封闭的环,最大值+1=最小值。
将节点随机分布到这个环上,每个节点负责处理从自己开始顺
时针至下一个节点的全部哈希值域上的数据,如图:
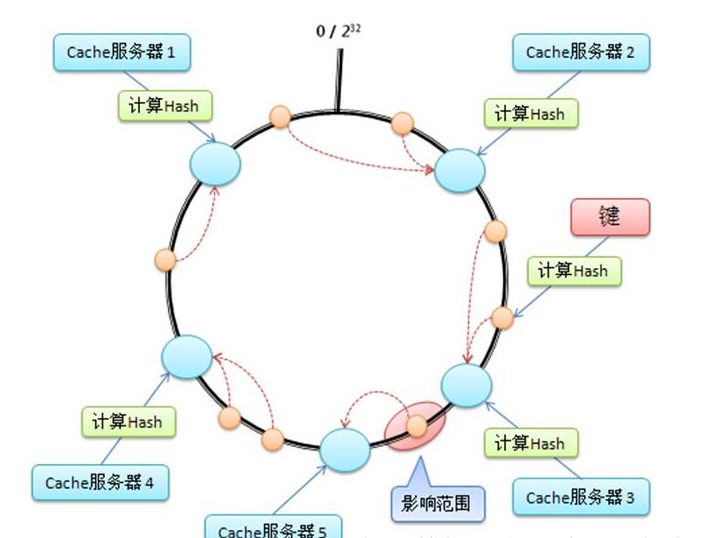
一致性哈希的优点在于可以任意动态添加、删除节点,每次添加、删除一个节点仅影响一致性哈希环上相邻的节点。
为了尽可能均匀的分布节点和数据,一种常见的改进算法是引入虚节点的概念,系统会创建许多虚拟节点,个数远大于当前节点的个数,均匀分布到一致性哈希值域环上。
读写数据时,首先通过数据的哈希值在环上找到对应的虚节点,然后查找到对应的real节点。
这样在扩容和容错时,大量读写的压力会再次被其他部分节点分摊,主要解决了压力集中的问题。
如图:
数据范围划分:
有些时候业务的数据id或key分布不是很均匀,并且读写也会呈现聚集的方式。
比如某些id的数据量特别大,这时候可以将数据按Group划分,从业务角度划分比如id为0~10000,已知8000以上的id可能访问量特别大,那么分布可以划分为[[0~8000],[8000~9000],[9000~1000]]。
将小访问量的聚集在一起。
这样可以根据真实场景按需划分,缺点是由于这些信息不能通过计算获取,需要引入一个模块存储这些映射信息。
这就增加了模块依赖,可能会有性能和可用性的额外代价。
数据块划分:
许多文件系统经常采用类似设计,将数据按固定块大小(比如HDFS的64MB),将数据分为一个个大小固定的块,然后这些块均匀的分布在各个节点,这种做法也需要外部节点来存储映射关系。
由于与具体的数据内容无关,按数据量分布数据的方式一般没有数据倾斜的问题,数据总是被均匀切分并分布到集群中。
当集群需要重新负载均衡时,只需通过迁移数据块即可完成。
如图: