分布式系统设计策略
重试机制
一般情况下,写一段网络交互的代码,发起rpc或者http,都会遇到请求超时而失败情况。
可能是网络抖动(暂时的网络变更导致包不可达,比如拓扑变更)或者对端挂掉。
这时一般处理逻辑是将请求包在一个重试循环块里,如下:
[cpp] view plain copy print?
int retry = 3;
while(!request() && retry–)
sched_yield(); // or usleep(100)
此种模式可以防止网络暂时的抖动,一般停顿时间很短,并重试多次后,请求成功!但不能防止对端长时间不能连接(网络问题或进程问题)
心跳机制
心跳顾名思义,就是以固定的频率向其他节点汇报当前节点状态的方式。
收到心跳,一般可以认为一个节点和现在的网络拓扑是良好的。
当然,心跳汇报时,一般也会携带一些附加的状态、元数据信息,以便管理。
如下图:
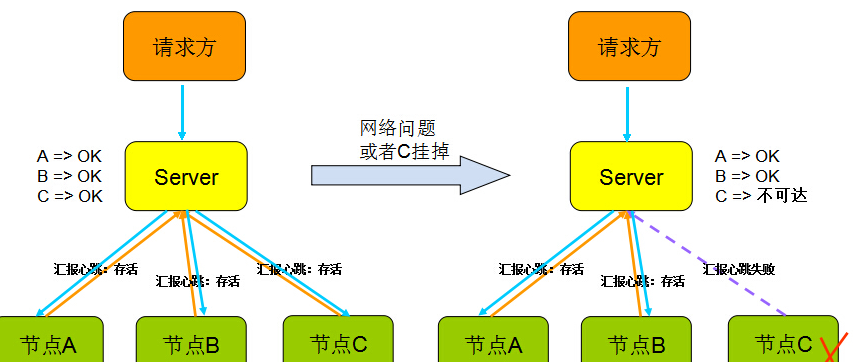
但心跳不是万能的,收到心跳可以确认ok,但是收不到心跳却不能确认节点不存在或者挂掉了,因为可能是网络原因倒是链路不通但是节点依旧在工作。
所以切记,”心跳“只能告诉你正常的状态是ok,它不能发现节点是否真的死亡,有可能还在继续服务。
(后面会介绍一种可靠的方式 – Lease机制)
副本
副本指的是针对一份数据的多份冗余拷贝,在不同的节点上持久化同一份数据,当某一个节点的数据丢失时,可以从副本上获取数据。
数据副本是分布式系统解决数据丢失异常的仅有的唯一途径。
当然对多份副本的写入会带来一致性和可用性的问题,比如规定副本数为3,同步写3份,会带来3次IO的性能问题。
还是同步写1份,然后异步写2份,会带来一致性问题,比如后面2份未写成功其他模块就去读了(下个小结会详细讨论如果在副本一致性中间做取舍)。
中心化/无中心化
系统模型这方面,无非就是两种:
中心节点,例如mysql的MSS单主双从、MongDB Master、HDFS NameNode、MapReduce JobTracker等,有1个或几个节点充当整个系统的核心元数据及节点管理工作,其他节点都和中心节点交互。
这种方式的好处显而易见,数据和管理高度统一集中在一个地方,容易聚合,就像领导者一样,其他人都服从就好。
简单可行。
但是缺点是模块高度集中,容易形成性能瓶颈,并且如果出现异常,就像群龙无首一样。
无中心化的设计,例如cassandra、zookeeper,系统中不存在一个领导者,节点彼此通信并且彼此合作完成任务。
好处在于如果出现异常,不会影响整体系统,局部不可用。
缺点是比较协议复杂,而且需要各个节点间同步信息。