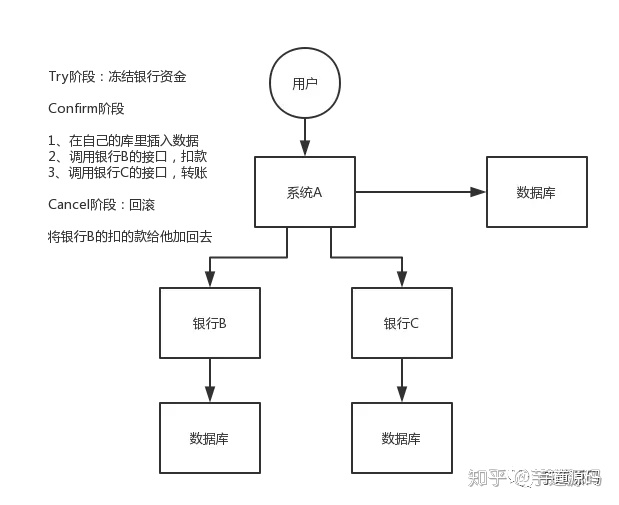
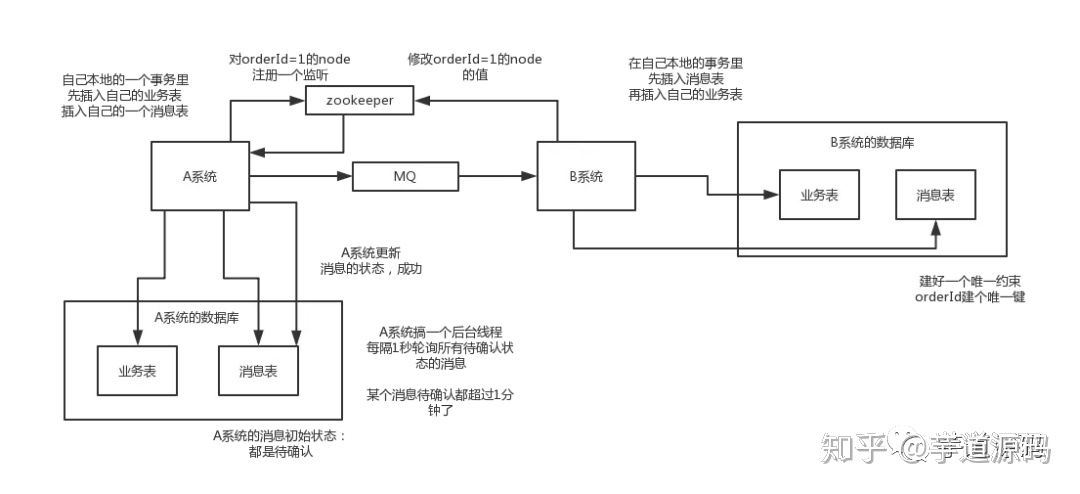
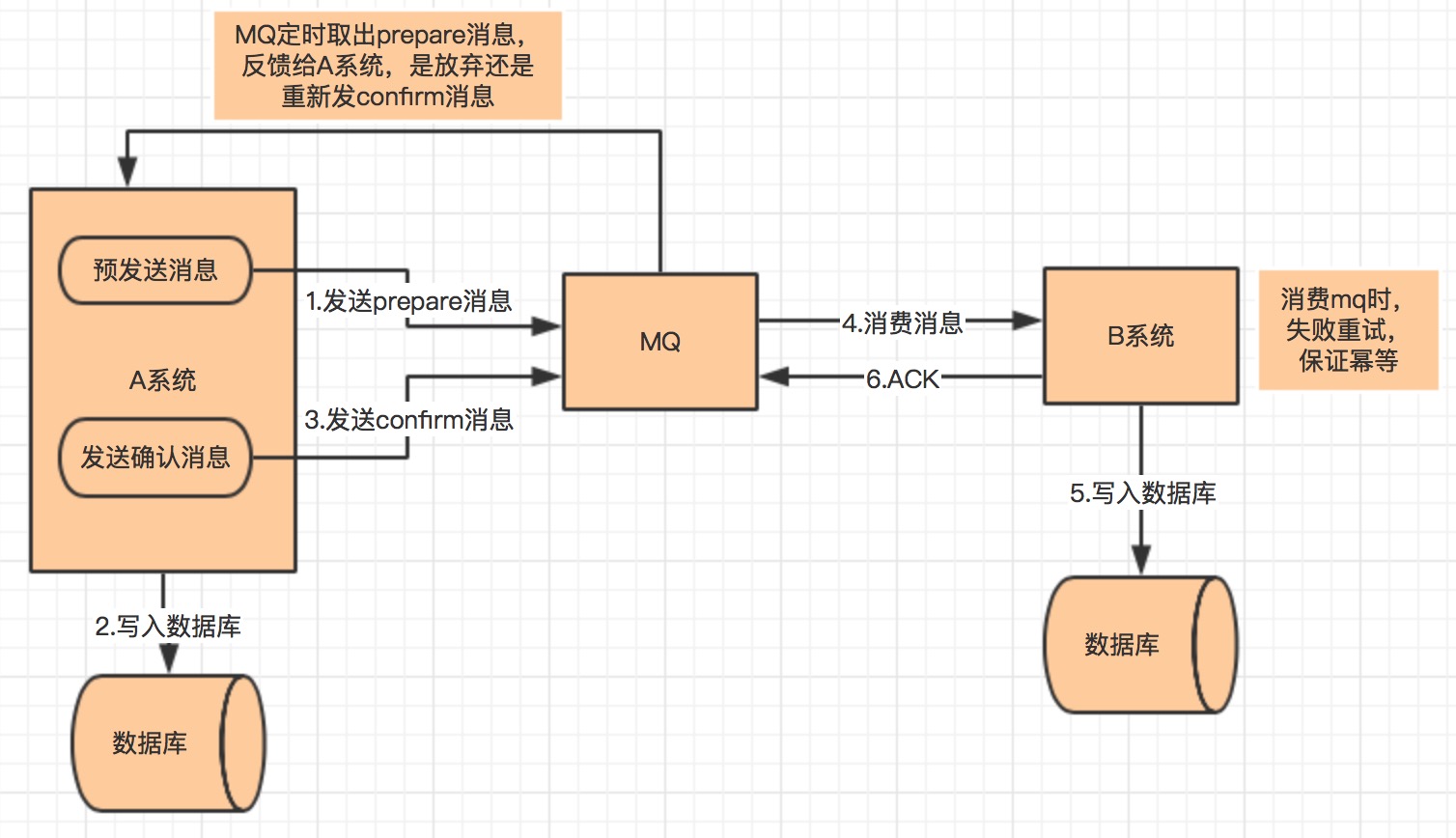
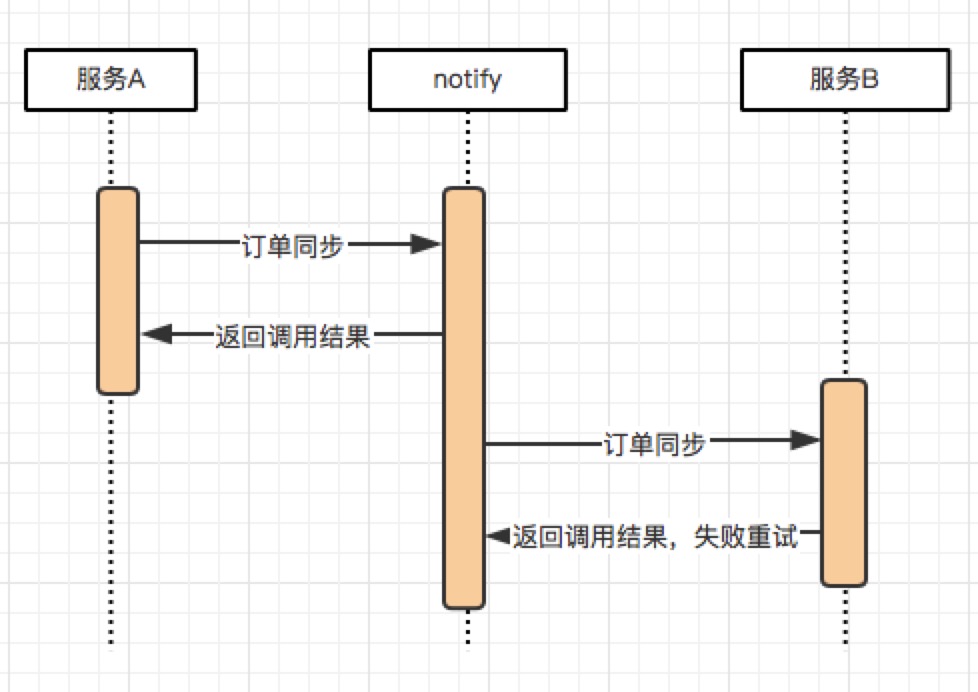
0. 导语
大家好,我是光城,欢迎关注公众号:guangcity。在 STL 编程中,容器和算法是独立设计的,即数据结构和算法是独立设计的,连接容器和算法的桥梁就是迭代器了,迭代器使其独立设计成为可能。如下图所示:
上图给出了 STL 的目标就是要把数据和算法分开,分别对其进行设计,之后通过一种名为 iterator 的东西,把这二者再粘接到一起。
设计模式中,关于 iterator 的描述为:一种能够顺序访问容器中每个元素的方法,使用该方法不能暴露容器内部的表达方式。而类型萃取技术就是为了要解决和 iterator 有关的问题的。
它将范型算法 (find, count, find_if) 用于某个容器中, 最重要的是要给算法提供一个访问容器元素的工具,iterator 就扮演着这个重要的角色。
而在算法中我们可能会定义简单的中间变量或者设定算法的返回变量类型,这时候需要知道迭代器所指元素的类型是什么,但是由于没有 typeof 这类判断类型的函数, 我们无法直接获取,那该如何是好?本文就来具体阐述。
对于迭代器来说就是一种智能指针,因此,它也就拥有了一般指针的所有特点——能够对其进行 * 和 -> 操作。但是在遍历容器的时候,不可避免的要对遍历的容器内部有所了解,所以,干脆把迭代器的开发工作交给容器的设计者好了,如此以来,所有实现细节反而得以封装起来不被使用者看到,这正是为什么每一种 STL 容器都提供有专属迭代器的缘故。
而 Traits 在bits/stl_iterator_base_types.h中:
template<class _Tp> |
看的一脸懵逼吧,没事,看完本节,入门 STL,哈哈~
1.template 参数推导
首先,在算法中运用迭代器时,很可能会用到其相应型别(associated type)(迭代器所指之物的型别)。假设算法中有必要声明一个变量,以 “迭代器所指对象的型别” 为型别,该怎么办呢?
解决方法是:利用 function template 的参数推导机制。
例如:
如果 T 是某个指向特定对象的指针,那么在 func 中需要指针所指向对象的型别的时候,怎么办呢?这个还比较容易,模板的参数推导机制可以完成任务,
template <class I> |
通过模板的推导机制,我们轻而易举的或得了指针所指向的对象的类型。
template <class I, class T> |
但是,函数的 “template 参数推导机制” 推导的只是参数,无法推导函数的返回值类型。万一需要推导函数的传回值,就无能为力了。因此,我们引出下面的方法。
2. 声明内嵌型别
迭代器所指对象的型别,称之为迭代器的 value type。
尽管在 func_impl 中我们可以把 T 作为函数的返回值,但是问题是用户需要调用的是 func。
template <class I, class T> |
如果去编译上述代码,编译失败!
这个问题解决起来也不难,声明内嵌型别似乎是个好主意,这样我们就可以直接获取。只要做一个 iterator,然后在定义的时候为其指向的对象类型制定一个别名,就好了,像下面这样:
template <class T> |
很漂亮的解决方案,看上去一切都很完美。但是,实际上还是有问题,因为 func 如果是一个泛型算法,那么它也绝对要接受一个原生指针作为迭代器,但是显然,你无法让下面的代码编译通过:
int *p = new int(5); |
我们的 func 无法支持原生指针,这显然是不能接受的。此时,template partial specialization 就派上了用场。
3. 救世主 Traits
前面也提到了,如果直接使用typename I::value_type,算法就无法接收原生指针,因为原生指针根本就没有 value_type 这个内嵌类型。
因此,我们还需要加入一个中间层对其进行判断,看它是不是原生指针,注意,这就是 traits 技法的妙处所在。
如果我们只使用上面的做法,也就是内嵌 value_type,那么对于没有 value_type 的指针,我们只能对其进行偏特化,这种偏特化是针对可调用函数 func 的偏特化,假如 func 有 100 万行行代码,那么就会造成极大的视觉污染。
(1)函数偏特化
函数偏特化:
template <class T> |
输出:
class version |
(2)加入中间层
在 STL 中 Traits 是什么呢?看下图:
利用一个中间层iterator_traits固定了func的形式,使得重复的代码大量减少,唯一要做的就是稍稍特化一下 iterator_tartis 使其支持 pointer 和 const pointer:)
|
上述的过程是首先询问iterator_traits<I>::value_type,如果传递的 I 为指针, 则进入特化版本,iterator_traits直接回答T; 如果传递进来的I为class type, 就去询问T::value_type.
上述的通俗解释为算法 (func) 问 iterator_traits(我),但是 iterator_traits(我)发现手上是指针的时候,就由我来替它回答。如果是 class type,iterator_traits(我)就继续问(他 —T::value_type)。
总结:通过定义内嵌类型,我们获得了知晓 iterator 所指元素类型的方法,通过 traits 技法,我们将函数模板对于原生指针和自定义 iterator 的定义都统一起来,我们使用 traits 技法主要是为了解决原生指针和自定义 iterator 之间的不同所造成的代码冗余,这就是 traits 技法的妙处所在。
学习书籍:
侯捷《 STL 源码剖析》
学习文章:
https://juejin.im/post/5b1a43fb51882513bf1795c6
https://www.cnblogs.com/mangoyuan/p/6446046.html
http://www.cppblog.com/nacci/archive/2005/11/03/911.aspx