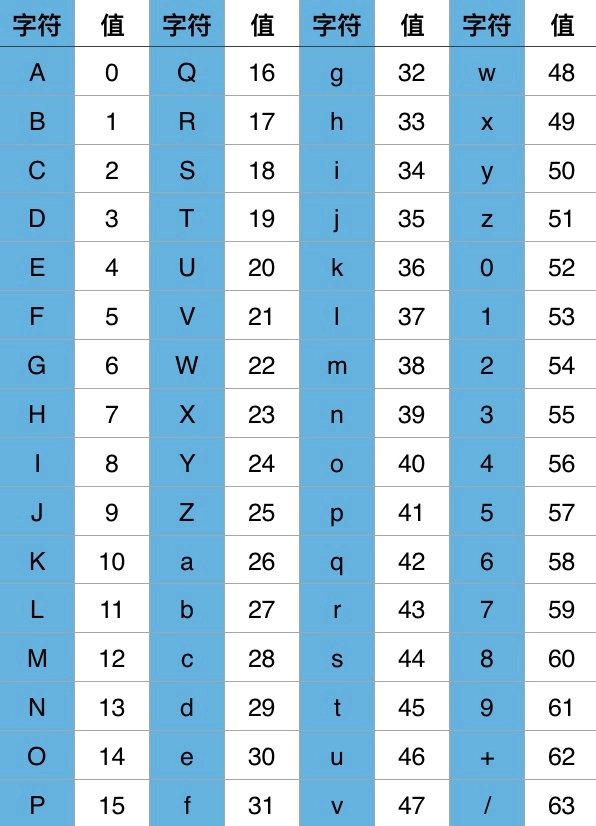
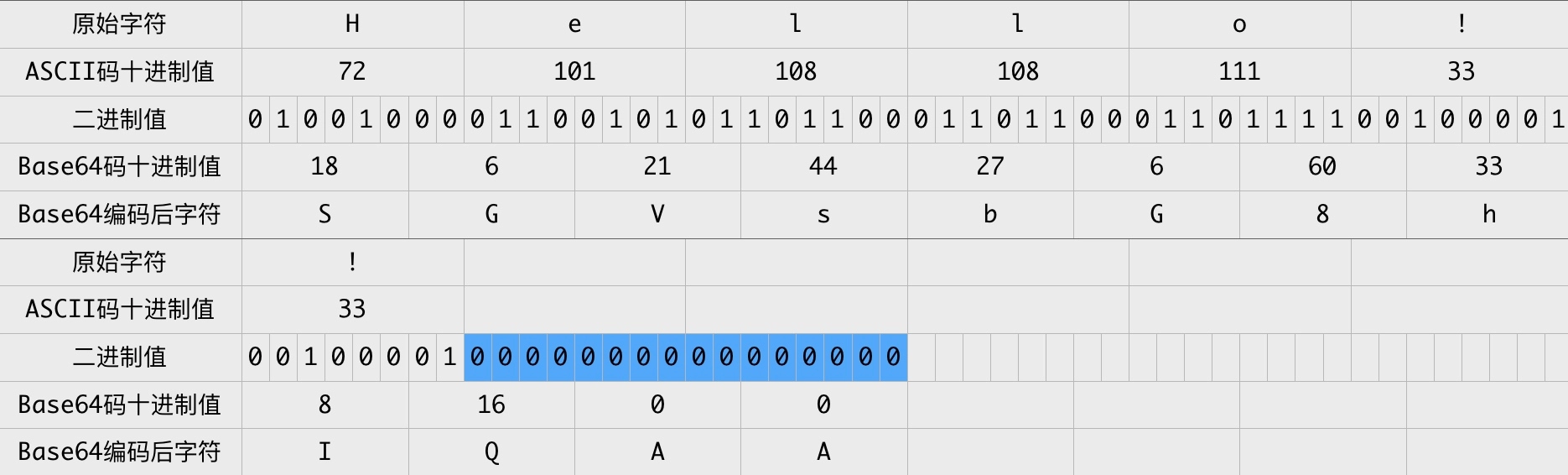
hexo s
…
50 句高频超市购物英语实用清单
A. 寻找商品 (Asking for Items)
Where can I find the milk/frozen shrimp?
(请问我在哪里可以找到牛奶/冷冻虾?)What aisle (/aɪl/ 货架通道) is the frozen seafood in?
(冷冻海鲜在哪个通道?)I’m looking for tomatoes/the produce (/ˈprɒdjuːs/ 农产品) section(/ˈsekʃ(ə)n/ 区域).
(我正在找西红柿/农产品区。)Which aisle is the bread in?
(面包在哪个货架(通道)?)Could you tell me where the frozen meals are?
(您能告诉我冷冻食品在哪里吗?)Is the pasta on this shelf?
(意大利面在这个架子上吗?)
Where are the spices and condiments (/ˈkɒndɪmənts/ 调味品)?
(香料和调味品在哪里?)I need help finding the cereal.
(我需要帮助寻找麦片。)Could you show me the way to the detergent (/dɪˈtɜːrdʒənt/ 洗涤剂)?
(您能带我去洗涤剂区吗?)
B. 关于商品细节 (About Products & Details)
Is this fruit ripe?
(这个水果熟了吗?)How much does this cost per pound?
(这个一磅多少钱?)What is the expiry (/ɪkˈspaɪəri/ 到期, 期满) date on this yogurt?
(这盒酸奶的保质期是多久?)Is this bread freshly baked?
(这个面包是新鲜出炉的吗?)Do you have a smaller portion (/ˈpɔːrʃn/ 一部分, 一份)?
(你们有小份一点的吗?)Are there any items on sale (/seɪl/ 销售, 特价)?
(有什么商品在打折(特价)吗?)Is this beef grass-fed?
(这个牛肉是草饲的吗?)Where is the debit (/ˈdebɪt/ 借方, 扣款) card machine?
(借记卡机(刷卡机)在哪里?)Does this contain any allergens (/ˈælərdʒənz/ 过敏原)?
(这个含有任何过敏原吗?)Could I get a small bag of apples?
(我能拿一小袋苹果吗?)
C. 生鲜区/服务台 (Deli/Meat/Service Counter)
- I’d like half a pound of ham, please. (请给我半磅火腿。)
Can you slice this cheese thinly?
(您能把这个奶酪切薄一点吗?)What’s the leanest (/ˈliːnɪst/ 最瘦的, 最精的) cut of chicken you have?
(你们最精(瘦)的鸡肉是哪一块?)I need one pound of ground beef.
(我需要一磅绞肉。)Can I sample this before I buy it?
(我买之前可以尝一下吗?)Could you wrap this separately (/ˈseprətli/ 分开地, 个别地)?
(您可以把这个分开包起来吗?)Do you have any fresh salmon today?
(你们今天有新鲜的鲑鱼吗?)What kind of dressing (/ˈdresɪŋ/ 沙拉酱, 调料) do you recommend?
(您推荐哪种沙拉酱?)Can I place a special order (/ˈɔːrdər/ 订单, 定制)?
(我可以下特殊订单(定制)吗?)How long will this stay fresh?
(这个能保持新鲜多久?)
D. 购物车与援助 (Cart & Assistance)
Where are the shopping carts?
(购物车在哪里?)Do you have a small basket?
(你们有小购物篮吗?)Could you help me reach that item on the top shelf?
(您能帮我拿到顶层货架上的东西吗?)Where is the restroom?
(请问洗手间在哪里?)Excuse me, is there a store employee nearby?
(打扰一下,附近有店员吗?)My cart wheel is stuck (/stʌk/ 卡住的, 动不了的).
(我的购物车轮子卡住了。)Do you offer home delivery (/dɪˈlɪvəri/ 递送, 送货)?
(你们提供送货服务吗?)Is there a limit (/ˈlɪmɪt/ 限制, 限额) on this item?
(这个商品有限购吗?)Can I leave my cart here for a minute?
(我可以把购物车在这里放一会儿吗?)Where is the customer service desk (/desk/ 服务台, 办公桌)?
(顾客服务台在哪里?)
E. 结账区 (At the Checkout)
Where is the shortest line?
(哪条队伍(结账通道)最短?)Do you take credit cards?
(你们收信用卡吗?)Can I get cash back with this transaction (/trænˈzækʃn/ 交易)?
(这笔交易我可以拿现金返还(提现)吗?)Could you please scan this again?
(您能再扫一下这个商品吗?)I have a coupon for this.
(我有这个商品的优惠券。)Please use paper bags instead of plastic.
(请用纸袋代替塑料袋。)Could you void (/vɔɪd/ 使无效, 取消) this item? I changed my mind.
(您能取消这个商品吗?我改变主意了。)Could I get a receipt, please?
(请给我一张收据。)How much is the total?
(总共多少钱?)I need to return this item.
(我需要退货。)