概述
一些面向对象的编程方式,提供了一种构建对象间复杂网络互连的能力。当对象们连接在一起时,它们就可以相互提供服务和信息。
通常来说,当某个对象的状态发生改变时,你仍然需要对象之间能互相通信。但是出于各种原因,你也许并不愿意因为代码环境的改变而对代码做大的修改。也许,你只想根据你的具体应用环境而改进通信代码。或者,你只想简单的重新构造通信代码来避免类和类之间的相互依赖与相互从属。
问题
当一个对象的状态发生改变时,你如何通知其他对象?是否需要一个动态方案――一个就像允许脚本的执行一样,允许自由连接的方案?
解决方案
观察者模式 :定义对象间的一种一对多的依赖关系, 当一个对象的状态发生改变时, 所有依赖于它的对象都得到通知并被自动更新。
观察者模式允许一个对象关注其他对象的状态,并且,观察者模式还为被观测者提供了一种观测结构,或者说是一个主体和一个客体。主体,也就是被观测者,可以用来联系所有的观测它的观测者。客体,也就是观测者,用来接受主体状态的改变 观测就是一个可被观测的类(也就是主题)与一个或多个观测它的类(也就是客体)的协作。不论什么时候,当被观测对象的状态变化时,所有注册过的观测者都会得到通知。
观察者模式将被观测者(主体)从观测者(客体)种分离出来。这样,每个观测者都可以根据主体的变化分别采取各自的操作。(观察者模式和 Publish/Subscribe 模式一样,也是一种有效描述对象间相互作用的模式。)观察者模式灵活而且功能强大。对于被观测者来说,那些查询哪些类需要自己的状态信息和每次使用那些状态信息的额外资源开销已经不存在了。另外,一个观测者可以在任何合适的时候进行注册和取消注册。你也可以定义多个具体的观测类,以便在实际应用中执行不同的操作。
将一个系统分割成一系列相互协作的类有一个常见的副作用:需要维护相关对象间的一致性。我们不希望为了维持一致性而使各类紧密耦合,因为这样降低了它们的可重用性。
适用性
在以下任一情况下可以使用观察者模式:
- 当一个抽象模型有两个方面, 其中一个方面依赖于另一方面。将这二者封装在独立的对象中以使它们可以各自独立地改变和复用。
- 当对一个对象的改变需要同时改变其它对象 , 而不知道具体有多少对象有待改变。
- 当一个对象必须通知其它对象,而它又不能假定其它对象是谁。换言之 , 你不希望这些对象是紧密耦合的。
结构
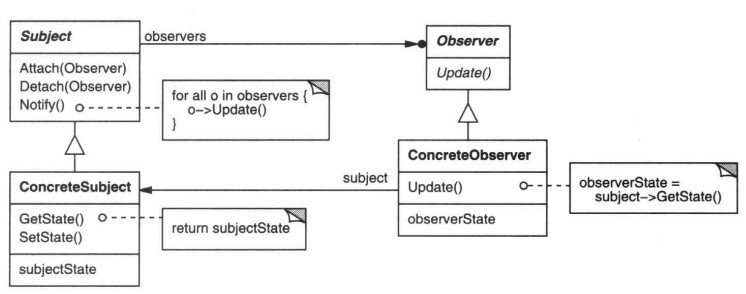
模式的组成
观察者模式包含如下角色:
- 目标(Subject): 目标知道它的观察者。可以有任意多个观察者观察同一个目标。 提供注册和删除观察者对象的接口。
- 具体目标(ConcreteSubject): 将有关状态存入各 ConcreteObserver 对象。
- 观察者 (Observer): 为那些在目标发生改变时需获得通知的对象定义一个更新接口。当它的状态发生改变时, 向它的各个观察者发出通知。
- 具体观察者 (ConcreteObserver): 维护一个指向 ConcreteSubject 对象的引用。存储有关状态,这些状态应与目标的状态保持一致。实现 O b s e r v e r 的更新接口以使自身状态与目标的状态保持一致。
观察者模式的优缺点
Observer 模式允许你独立的改变目标和观察者。你可以单独复用目标对象而无需同时复用其观察者, 反之亦然。它也使你可以在不改动目标和其他的观察者的前提下增加观察者。
下面是观察者模式其它一些优点 :
- 观察者模式可以实现表示层和数据逻辑层的分离, 并定义了稳定的消息更新传递机制,抽象了更新接口,使得可以有各种各样不同的表示层作为具体观察者角色。
- 在观察目标和观察者之间建立一个抽象的耦合 :
一个目标所知道的仅仅是它有一系列观察者 , 每个都符合抽象的 Observer 类的简单接口。目标不知道任何一个观察者属于哪一个具体的类。这样目标和观察者之间的耦合是抽象的和最小的。因为目标和观察者不是紧密耦合的, 它们可以属于一个系统中的不同抽象层次。一个处于较低层次的目标对象可与一个处于较高层次的观察者通信并通知它 , 这样就保持了系统层次的完整。如果目标和观察者混在一块 , 那么得到的对象要么横贯两个层次 (违反了层次性), 要么必须放在这两层的某一层中 (这可能会损害层次抽象)。 - 支持广播通信 : 不像通常的请求, 目标发送的通知不需指定它的接收者。通知被自动广播给所有已向该目标对象登记的有关对象。目标对象并不关心到底有多少对象对自己感兴趣 ; 它唯一的责任就是通知它的各观察者。这给了你在任何时刻增加和删除观察者的自由。处理还是忽略一个通知取决于观察者。
- 观察者模式符合 “开闭原则” 的要求。
观察者模式的缺点 :
- 如果一个观察目标对象有很多直接和间接的观察者的话,将所有的观察者都通知到会花费很多时间。
- 如果在观察者和观察目标之间有循环依赖的话,观察目标会触发它们之间进行循环调用,可能导致系统崩溃。
- 观察者模式没有相应的机制让观察者知道所观察的目标对象是怎么发生变化的,而仅仅只是知道观察目标发生了变化。
- 意外的更新 因为一个观察者并不知道其它观察者的存在 , 它可能对改变目标的最终代价一无所知。在目标上一个看似无害的的操作可能会引起一系列对观察者以及依赖于这些观察者的那些对象的更新。此外 , 如果依赖准则的定义或维护不当,常常会引起错误的更新 , 这种错误通常很难捕捉。
简单的更新协议不提供具体细节说明目标中什么被改变了 , 这就使得上述问题更加严重。如果没有其他协议帮助观察者发现什么发生了改变,它们可能会被迫尽力减少改变。
实现
在 php 的 SPL 支持观察者模式,SPL 提供了 SplSubject 和 SplObserver 接口。
SplSubject 接口提供了 attach()、detach()、notify() 三个方法。而 SplObserver 接口则提供了 update() 方法。
SplSubject 派生类维护了一个状态,当状态发生变化时 - 比如属性变化等,就会调用 notify() 方法,这时,之前在 attach() 方法中注册的所有 SplObserver 实例的 update() 方法就会被调用。接口定义如下:
1 |
|
实现代码:
1 |
|
我们扩展上面的例子,根据目标状态而更新不同的观察者:
1 |
|
与其他相关模式
- 终结者模式 Mediator: 通过封装复杂的更新语义 , ChangeManager 充当目标和观察者之间的中介者。
- 单例模式 Singleton: ChangeManager 可使用 Singleton 模式来保证它是唯一的并且是可全局访问
的。
总结与分析
通过 Observer 模式,把一对多对象之间的通知依赖关系的变得更为松散,大大地提高了程序的可维护性和可扩展性,也很好的符合了开放 - 封闭原则。