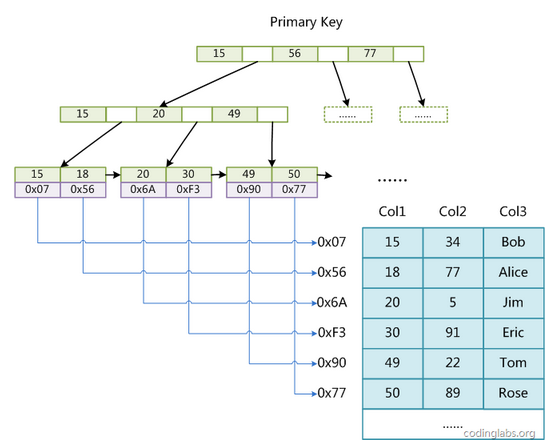
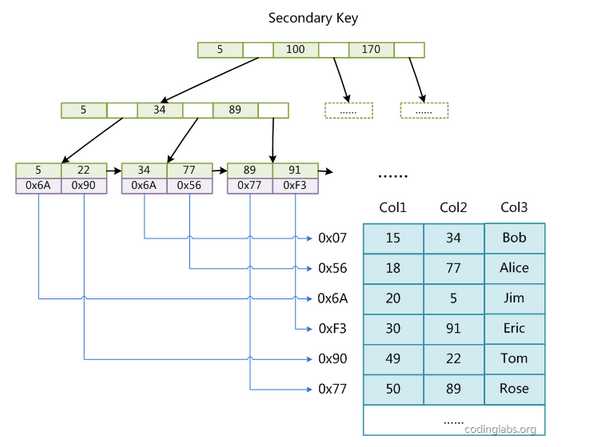
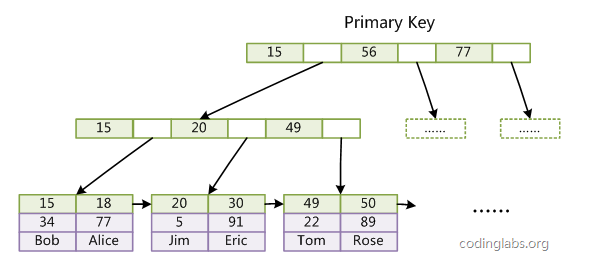
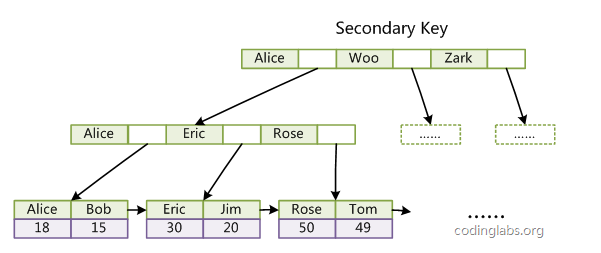
linux常用文本处理的命令的使用率很高, 所以整理了一些之前的笔记,用markdown来记录备忘。
首先抛出问题, 带着问题来学记忆知识更有动力:
如何通过一条命令取得eth0的IP4地址 :
ifconfig eth0 | grep -w 'inet' | awk '{print $2}' | awk -F: '{print $2}'
如何通过一条命令替换当前路径下所有文件中的所有“xxx”为“yyy“ :
ls -alF | grep '^-' | awk '{print $NF}' | xargs sed -i 's/xxx/yyy/g'
如何通过一条命令杀掉占用端口34600的进程 :
sudo lsof -i:34600 | grep -v 'PID' | awk '{print $2}' | xargs kill -9
这些命令它们分别具体是什么意思呢?为何能达到上述效果?
. . .