更多好用的一键脚本请转 https://github.com/ToyoDAdoubi/doubi
ssr.sh
- 脚本说明: ShadowsocksR 一键安装管理脚本,支持单端口/多端口切换和管理
- 系统支持: CentOS6+ / Debian6+ / Ubuntu14+
- 使用方法: https://doub.io/ss-jc42/
- 项目地址: https://github.com/ToyoDAdoubiBackup/shadowsocksr
. . .
更多好用的一键脚本请转 https://github.com/ToyoDAdoubi/doubi
. . .
脚本会递归目录的子目录import moviepy.editor as mp
# vfc = mp.VideoFileClip("binary_tree_preorder_traversal.gif")
# vfc.write_videofile("binary_tree_preorder_traversal.mp4")
# vfc = mp.VideoFileClip(".\\mp/binary_tree_preorder_traversal.gif")
# vfc.write_videofile(".\\mp/binary_tree_preorder_traversal1231.mp4")
import os
def getfilelist(rlist,path, ex_filter):
for dir,folder,file in os.walk(path):
for i in file:
if ex_filter not in i:
continue
t = "%s/%s"%(dir,i)
rlist.append(t)
all_gif_path = []
getfilelist(all_gif_path, ".", ".gif")
print all_gif_path
for _gif_path in all_gif_path:
vfc = mp.VideoFileClip(_gif_path)
vfc.write_videofile(_gif_path.replace(".gif", ".mp4"))
推荐参考本博客总结的 algo_newbie
https://github.com/no5ix/no5ix.github.io/blob/source/source/code/test_algo_practice.py
二叉树递归强化
一个桶里面有白球. 黑球各 100 个,现在按下述的规则取球:
i . 每次从桶里面拿出来两个球;
ii. 如果取出的是两个同色的球,就再放入一个黑球;
iii. 如果取出的是两个异色的球,就再放入一个白球。
问:最后桶里面只剩下一个黑球的概率是多少?
1 ^ 2 ^ 3 ^ 1 ^ 2 ^ 3 ^ 3 = (3 ^ 3 ^ 3) ^ (1 ^ 1) ^ (2 ^ 2) = 3^ 0 ^ 0 = 3。现有一个随机数生成器可以生成0到4的数,现在要让你用这个随机数生成器生成0到6的随机数,要保证生成的数概率均匀。
def rand4(): |
连续整数求和(leetcode第829题, hard实际有思路就easy),要求时间复杂度小于O(N)
class Solution: |
N % (M+1) 的余数, 此处为 1000 % (8+1) = 1, 求得此余数Y后, 先拿的人第一次就拿Y个, 然后假如B同学第二次拿X个比如是4个, 不管B拿多少个, A之后都拿 (M+1)-X个即 (8+1)-4=5个和B同学拿的4个凑成(8+1)=9个, 这样就保证了A是最后一个拿完棋子的人有一个整数数组,请你根据快速排序的思路,找出数组中第K大的数。
给定一个整数数组a,同时给定它的大小n和要找的K(K在1到n之间),请返回第K大的数,保证答案存在。
测试样例:
[1,3,5,2,2],5,3
返回:2
class Solution_find_top_k_num(object): |
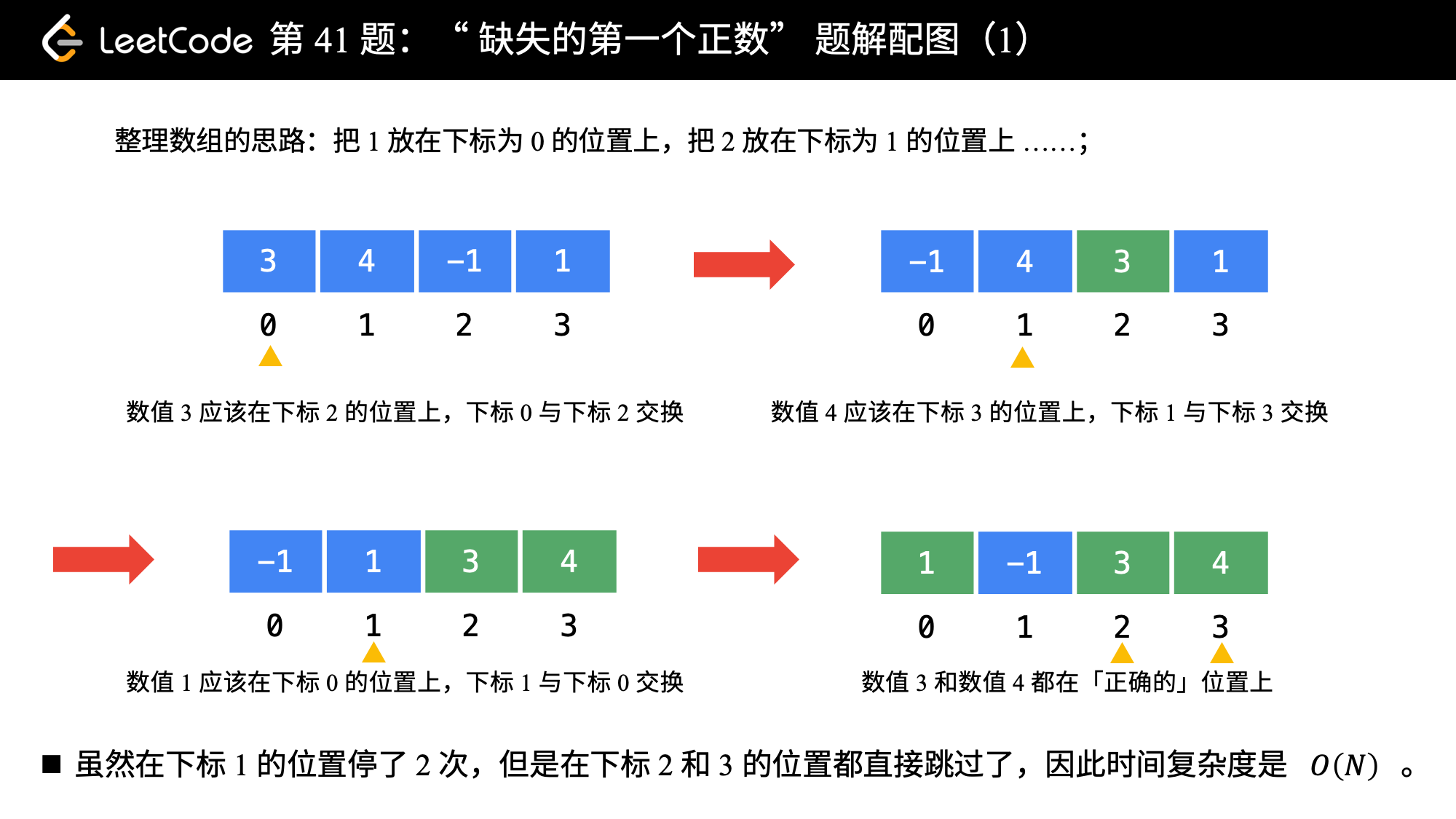
lc41, hard 缺失的第一个正数(leetcode第41题)
给你一个未排序的整数数组,请你找出其中没有出现的最小的正整数。
示例 1:
输入: [1,2,0]
输出: 3
示例 2:
输入: [3,4,-1,1]
输出: 2
示例 3:
输入: [7,8,9,11,12]
输出: 1
提示:你的算法的时间复杂度应为O(n),并且只能使用常数级别的额外空间。
参考
我们可以采取这样的思路:就把 11 这个数放到下标为 00 的位置, 22 这个数放到下标为 11 的位置,按照这种思路整理一遍数组。然后我们再遍历一次数组,第 11 个遇到的它的值不等于下标的那个数,就是我们要找的缺失的第一个正数。
这个思想就相当于我们自己编写哈希函数,这个哈希函数的规则特别简单,那就是数值为 i 的数映射到下标为 i - 1 的位置。
class Solution_lc41(object): |