Design a notification System - middle
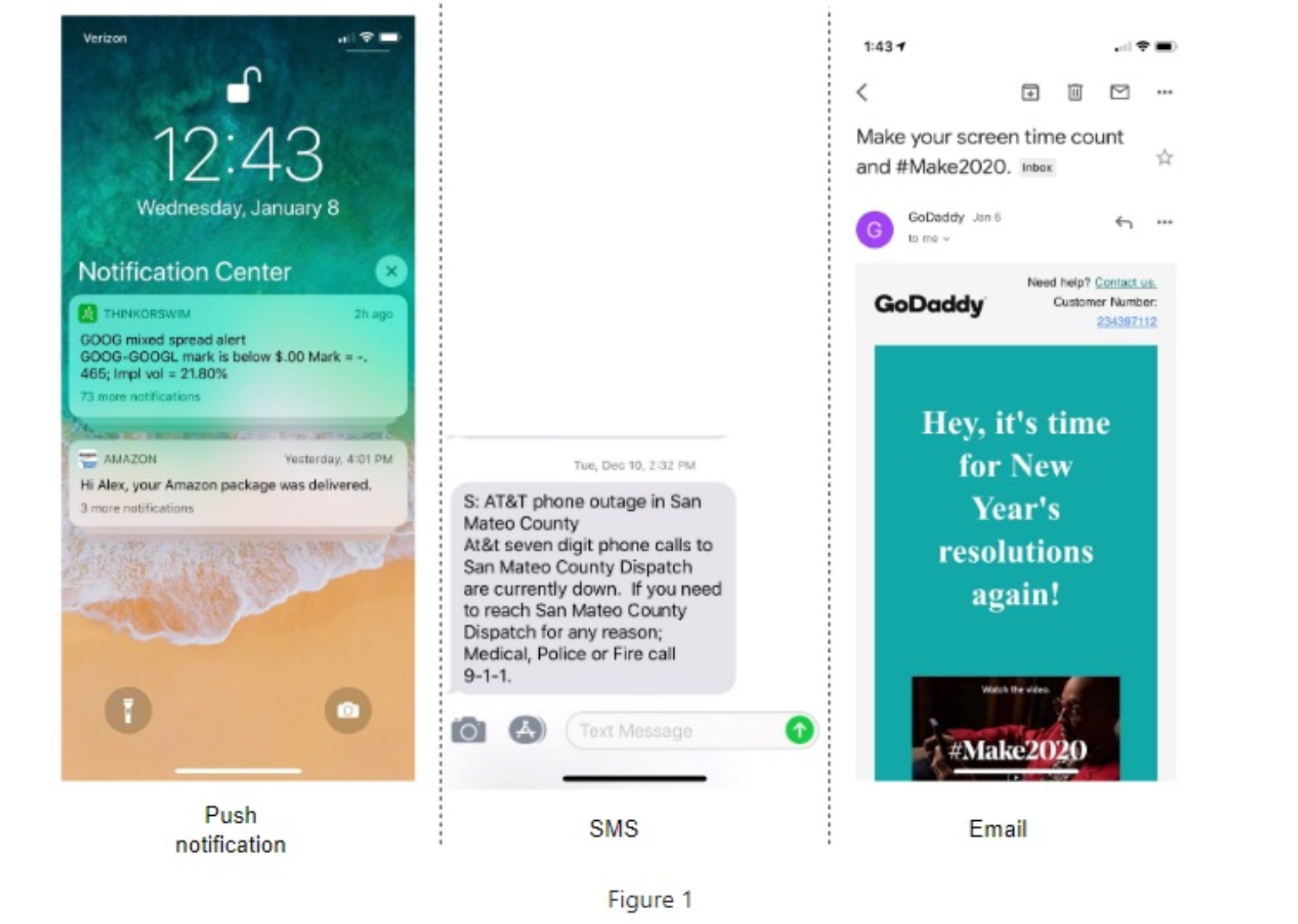
3 types of notification formats are:
- mobile push notification
- SMS message
step1-Understand the problem and establish design scope
- Candidate: What types of notifications does the system support?
- Interviewer: Push notification, SMS message, and email.
- Candidate: Is it a real-time system?
- Interviewer: Let us say it is a soft real-time system. We want a user to receive notifications as soon as possible. However, if the system is under a high workload, a slight delay is acceptable.
- Candidate: What are the supported devices?
- Interviewer: iOS devices, android devices, and laptop/desktop.
- Candidate: What triggers notifications?
- Interviewer: Notifications can be triggered by client applications. They can also be scheduled on the server-side.
- Candidate: Will users be able to opt-out(用户选择退出、不参与某个功能或服务) ?
- Interviewer: Yes, users who choose to opt-out will no longer receive notifications.
- Candidate: How many notifications are sent out each day?
- Interviewer: 10 million mobile push notifications, 1 million SMS messages, and 5 million emails.
step2-Propose high-level design and get buy-in
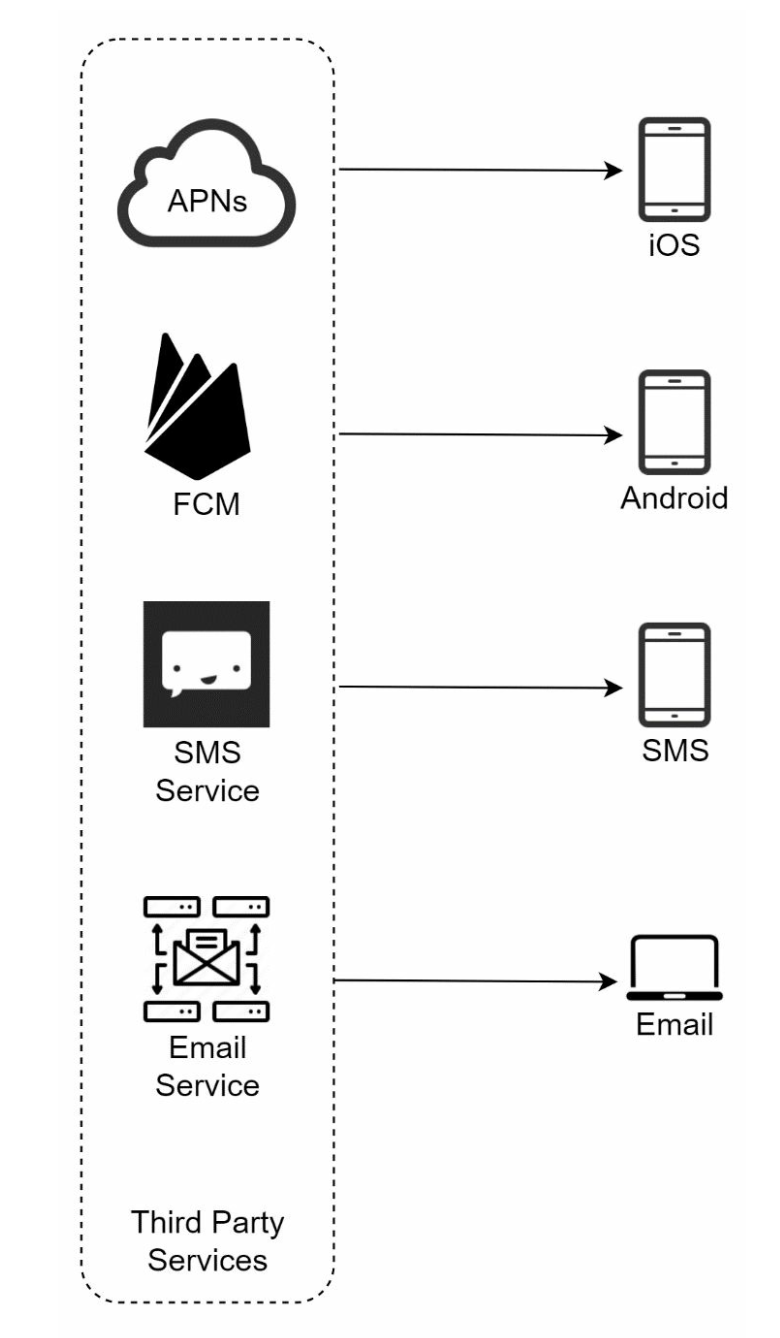
iOS push notification
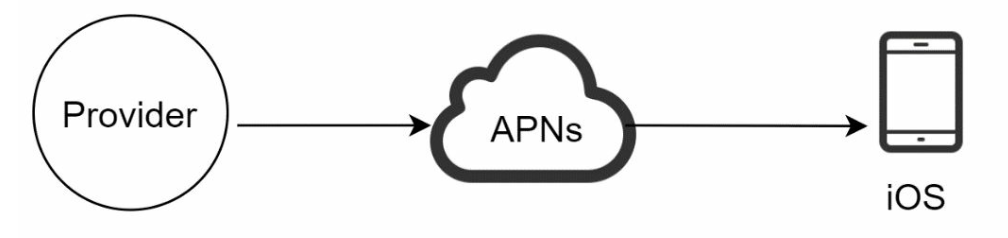
Provider. A provider builds and sends notification requests to Apple Push Notification Service (APNS). To construct a push notification, the provider provides the following data:
- • Device token: This is a unique identifier used for sending push notifications.
- • Payload: This is a JSON dictionary that contains a notification’s payload:
payload {
"aps": {
"alert": {
"title": "Game Request",
"body": "Bob wants to play chess",
"action-loc-key": "PLAY"
},
"badge": 5
}
}
APNS: This is a remote service provided by Apple to propagate push notifications to iOS devices.
- iOS Device: It is the end client, which receives push notifications.
Android push notification
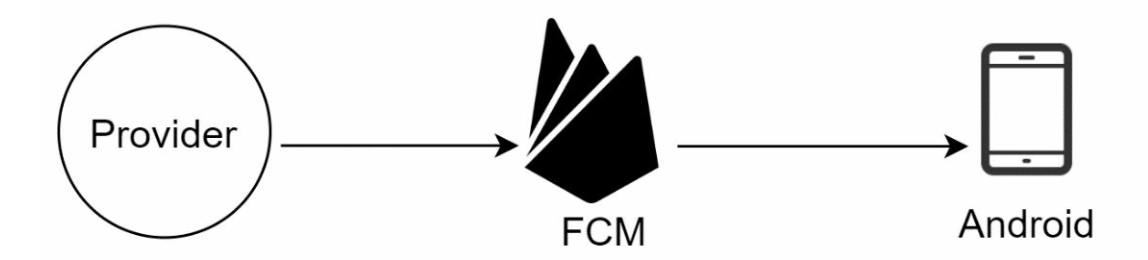
Instead of using APNs, Firebase Cloud Messaging (FCM) is commonly used to send push notifications to android devices.
SMS message
including all the third-party services
Contact info gathering flow
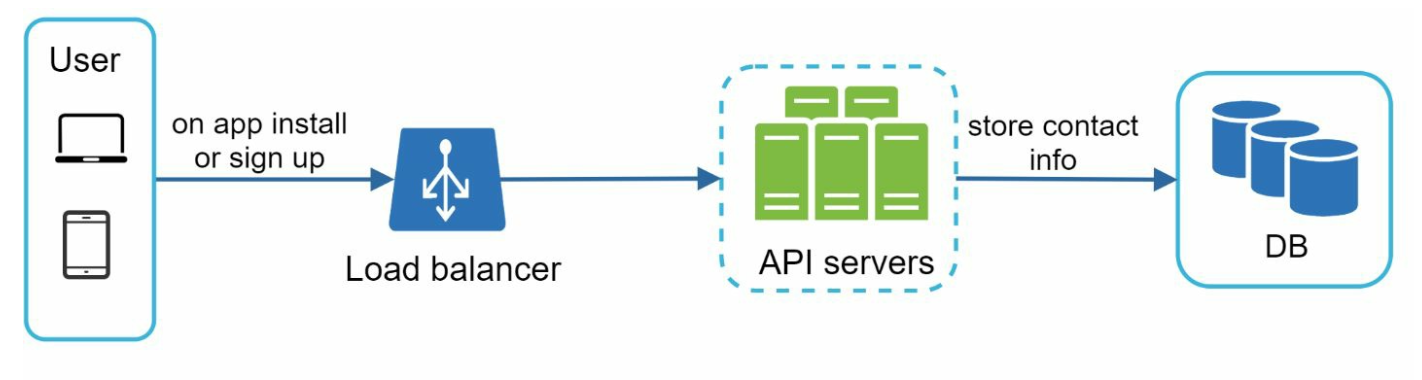
when a user installs our app or signs up for the first time,
API servers collect user contact info and store it in the database.
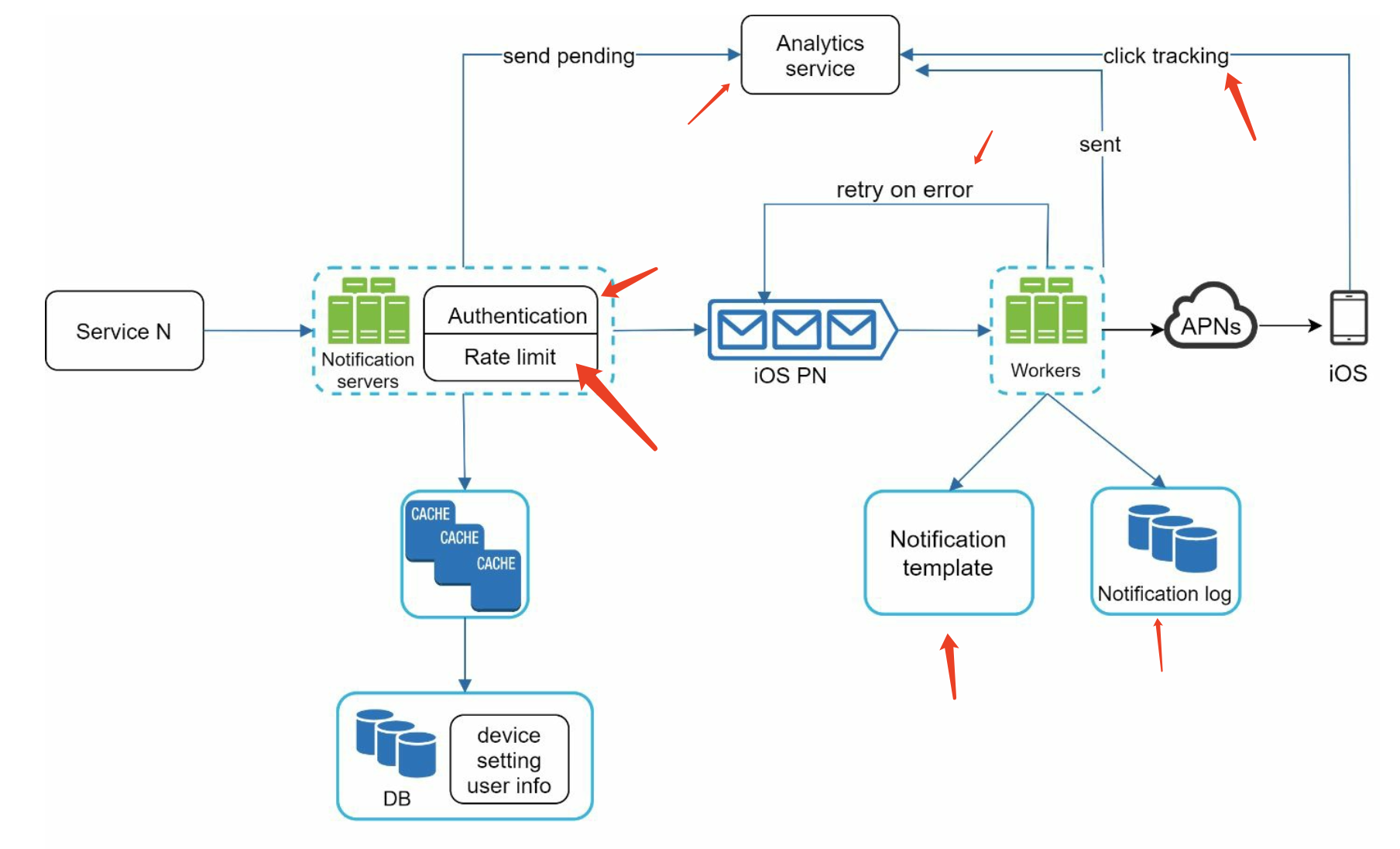
High-level design
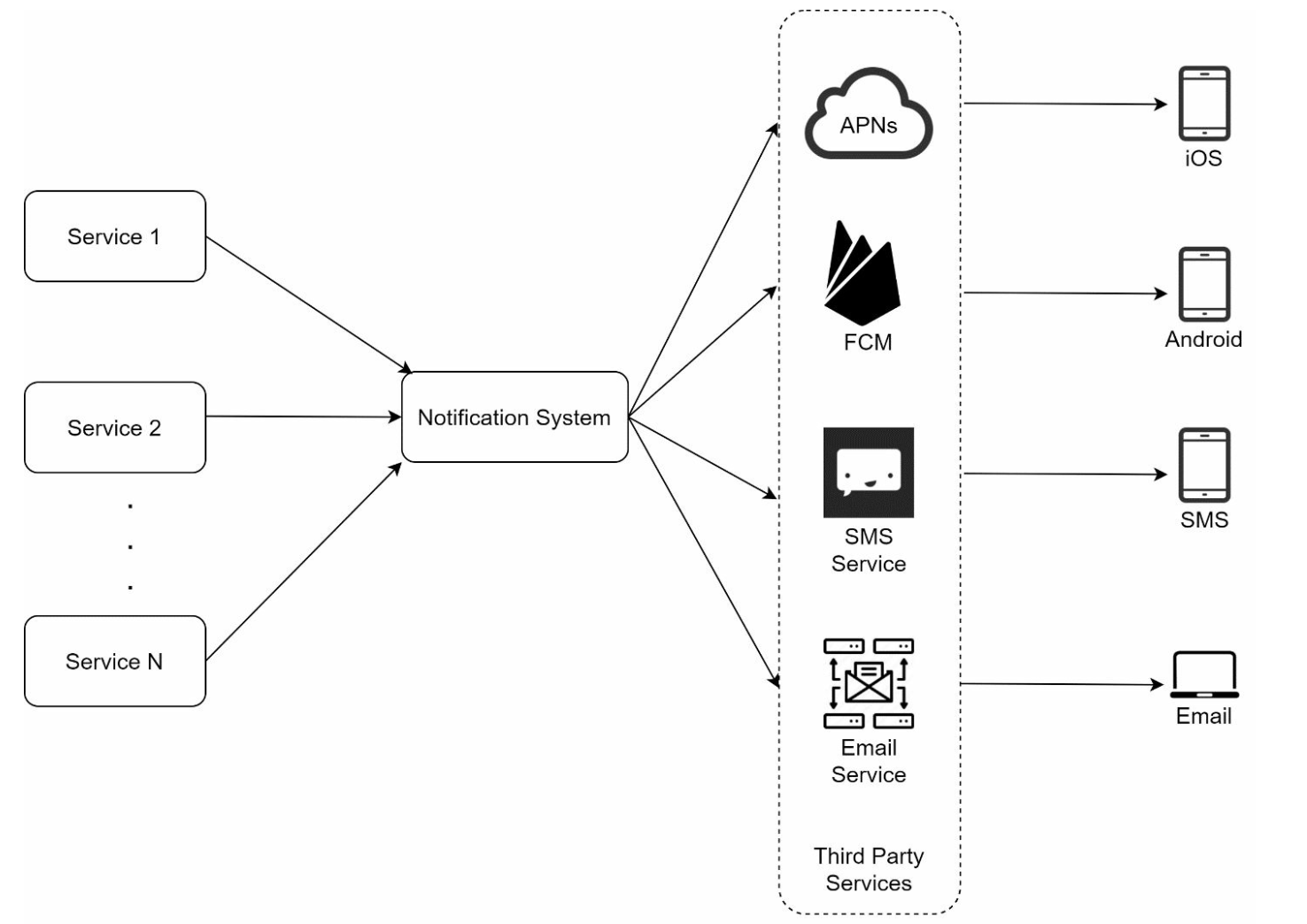
- Service 1 to N: A service can be a micro-service, a cron job, or a distributed system that triggers notification sending events.
- For example, a billing service sends emails to remind customers of their due payment or a shopping website tells customers that their packages will be delivered tomorrow via SMS messages.
- Notification system: The notification system is the centerpiece of sending/receiving notifications. Starting with something simple, only one notification server is used. It provides APIs for services 1 to N, and builds notification payloads for third party services.
High-level design (improved)

we improve the design as listed below:
- • Move the database and cache out of the notification server.
- • Add more notification servers and set up automatic horizontal scaling.
- • Introduce message queues to decouple the system components.
New:
- Notification servers: They provide the following functionalities:
- • Provide APIs for services to send notifications. Those APIs are only accessible internally or by verified clients to prevent spams.
- • Carry out basic validations to verify emails, phone numbers, etc.
- • Query the database or cache to fetch data needed to render a notification.
- • Put notification data to message queues for parallel processing.
- Cache: User info, device info, notification templates are cached.
- DB: It stores data about user, notification, settings, etc.
- Message queues: They remove dependencies between components. Message queues serve as buffers when high volumes of notifications are to be sent out. Each notification type is assigned with a distinct message queue so an outage in one third-party service will not affect other notification types.
- Workers: Workers are a list of servers that pull notification events from message queues and send them to the corresponding third-party services.
step3-Design deep dive
How to prevent data loss?
To satisfy this requirement,
the notification system persists notification data in a database and implements a retry
mechanism. The notification log database is included for data persistence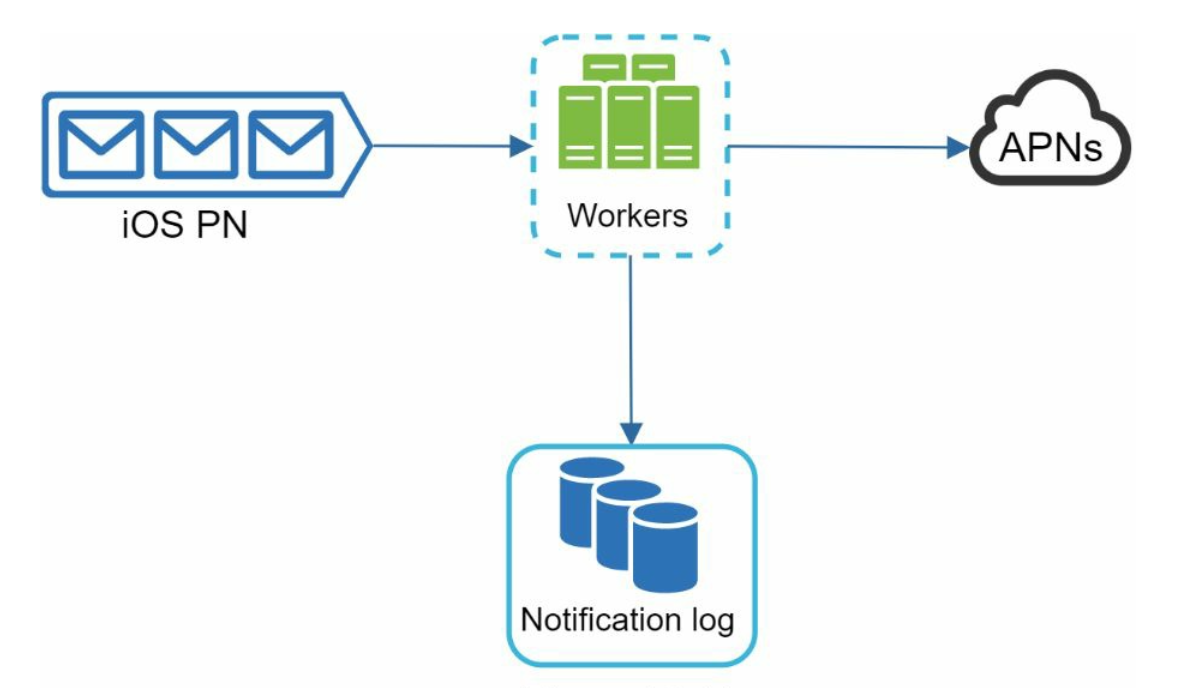
Will recipients receive a notification exactly once?
When a notification event first arrives, we check if it is seen before by checking the event ID.
If it is seen before, it is discarded. Otherwise, we will send out the notification.
Notification template
A large notification system sends out millions of notifications per day, and many of these
notifications follow a similar format. Notification templates are introduced to avoid building every notification from scratch.
A notification template is a preformatted notification to create your unique notification by customizing parameters, styling, tracking links, etc. Here is an example template of push notifications.
BODY: |
Notification setting
Before any notification is sent to a user, we first check if a user is opted-in to receive this type
of notification.
| 字段名 | 类型 | 描述 |
|---|---|---|
user_id |
bigInt |
用户唯一标识 |
channel |
varchar |
通知渠道,例如 push notification、email、SMS |
opt_in |
boolean |
用户是否同意接收该渠道的通知(是否选择接收) |
Rate limiting
To avoid overwhelming users with too many notifications, we can limit the number of
notifications a user can receive. This is important because receivers could turn off
notifications completely if we send too often.
Retry mechanism
When a third-party service fails to send a notification, the notification will be added to the
message queue for retrying. If the problem persists, an alert will be sent out to developers.
Security in push notifications
For iOS or Android apps, appKey and appSecret are used to secure push notification APIs. Only authenticated or verified clients are allowed to send push notifications using our APIs.
Monitor queued notifications
A key metric to monitor is the total number of queued notifications. If the number is large,
the notification events are not processed fast enough by workers. To avoid delay in the
notification delivery, more workers are needed.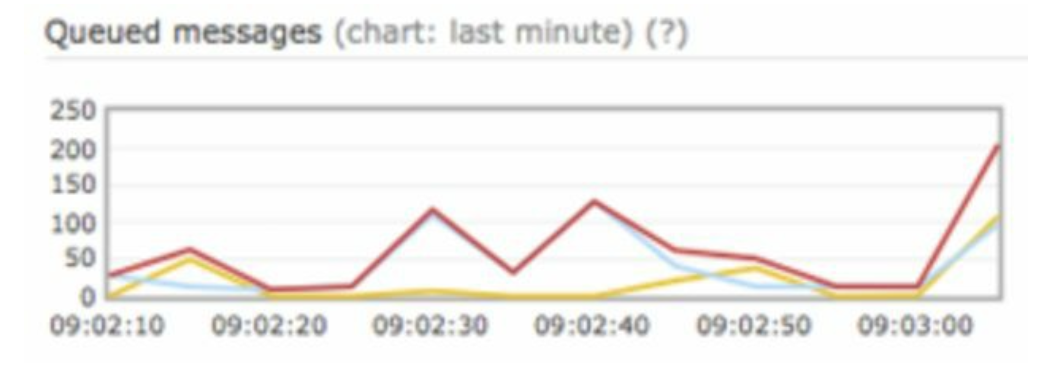
Events tracking
Notification metrics, such as open rate, click rate, and engagement are important in
understanding customer behaviors. Analytics service implements events tracking. Integration
between the notification system and the analytics service is usually required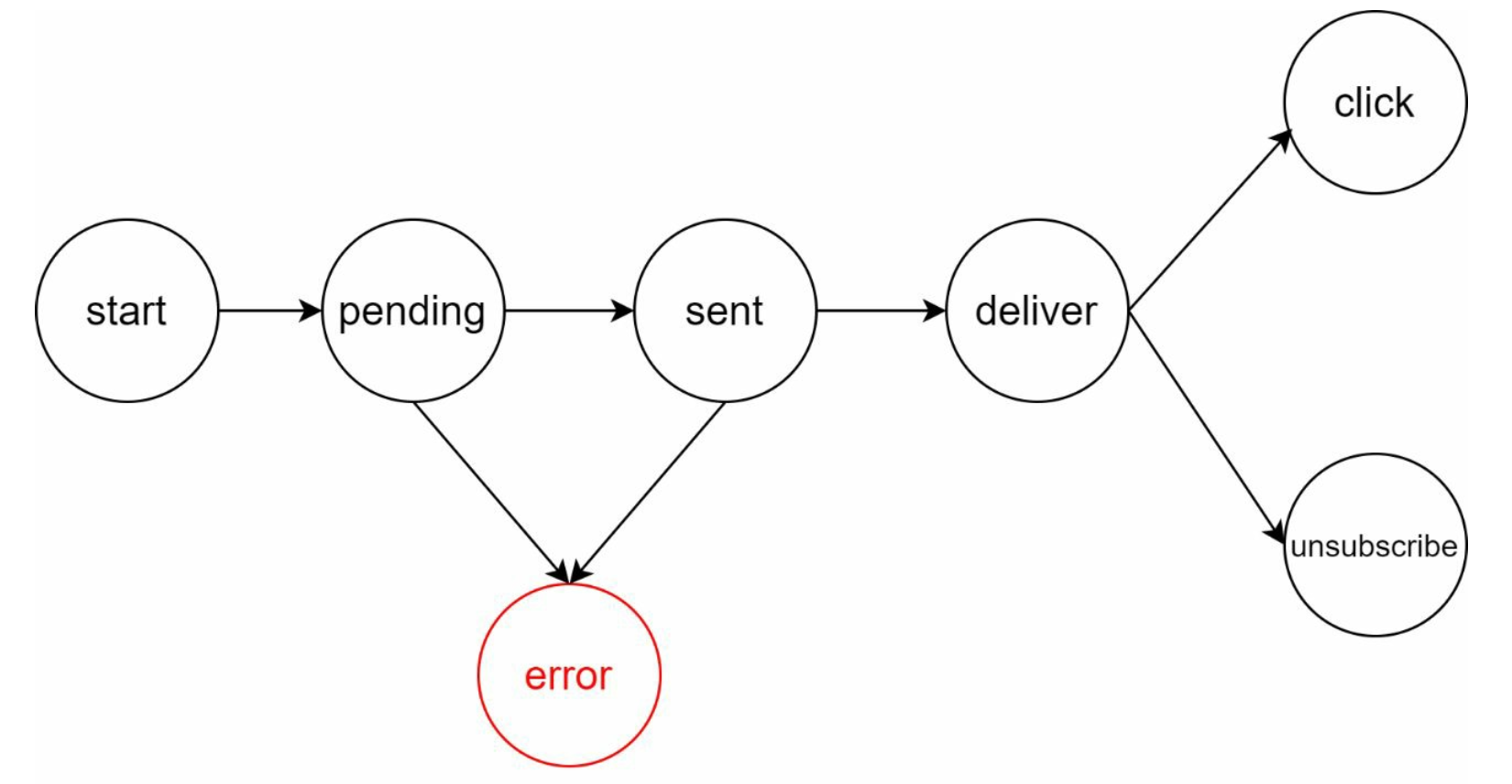
updated design
Design a Social Network (like Twitter) - middle
- 关注/粉丝系统设计(fanout on write vs fanout on read)
- 动态(Feed)生成
- 分布式数据库与缓存优化(Redis, Cassandra, etc.)
Requirements
Functional Requirements:
- Users should be able to post new tweets.
- A user should be able to follow other users.
- Users should be able to mark tweets as favorites.
- The service should be able to create and display a user’s timeline consisting of top tweets from all the people the user follows.
- Tweets can contain photos and videos.
Non-functional Requirements:
- Our service needs to be highly available.
- Acceptable latency of the system is 200ms for timeline generation.
- Consistency can take a hit (in the interest of availability); if a user doesn’t see
a tweet for a while, it should be fine.
Capacity Estimation and Constraints
Let’s assume we have one billion total users with 200 million daily active users
(DAU). Also assume we have 100 million new tweets every day and on average each
user follows 200 people.
How many favorites per day? If, on average, each user favorites five tweets per day
we will have:200M users * 5 favorites => 1B favorites
How many total tweet-views will our system generate? Let’s assume on average
a user visits their timeline 2 times a day and visits 5 other people’s pages. On
each page if a user sees 20 tweets, then our system will generate 28B/day total
tweet-views:200M DAU * ((2 + 5) * 20 tweets) => 28B/day
Storage Estimates: Let’s say each tweet has 140 characters and we need 2 bytes to
store a character without compression. Let’s assume we need 30 bytes to store
metadata with each tweet (like ID, timestamp, user ID, etc.). Total storage we would
need:100M * (280 + 30) bytes => 100M * 300bytes => 100M * 0.3KB => 30, 000, 000KB => 30, 000 MB => 30GB/day
What would our storage needs be for five years? How much storage we would need
for users’ data, follows, favorites? We will leave this for the exercise.
Not all tweets will have media, let’s assume that on average every fifth tweet has a
photo and every tenth has a video. Let’s also assume on average a photo is 200KB
and a video is 2MB. This will lead us to have 24TB of new media every day.(100M/5 photos * 200KB) + (100M/10 videos * 2MB) ~= 24TB/day
计算如下:
20M * 0.2MB = 4,000,000 MB10M * 2MB = 20,000,000 MB- 总和:
4,000,000 + 20,000,000 = 24,000,000 MB
换算为其他单位:
24,000,000 MB = 24,000 GB = 24 TB
Bandwidth Estimates: Since total ingress is 24TB per day, this would translate into290MB/sec.
Remember that we have 28B tweet views per day. We must show the photo of every
tweet (if it has a photo), but let’s assume that the users watch every 3rd video they
see in their timeline. So, total egress(/ˈiːɡres/ n. 外出;出口) will be:(28B * 280 bytes) / 86400s of text => 93MB/s
+ (28B/5 * 200KB ) / 86400s of photos => 13GB/S
+ (28B/10/3 * 2MB ) / 86400s of Videos => 22GB/s
Total ~= 35GB/s
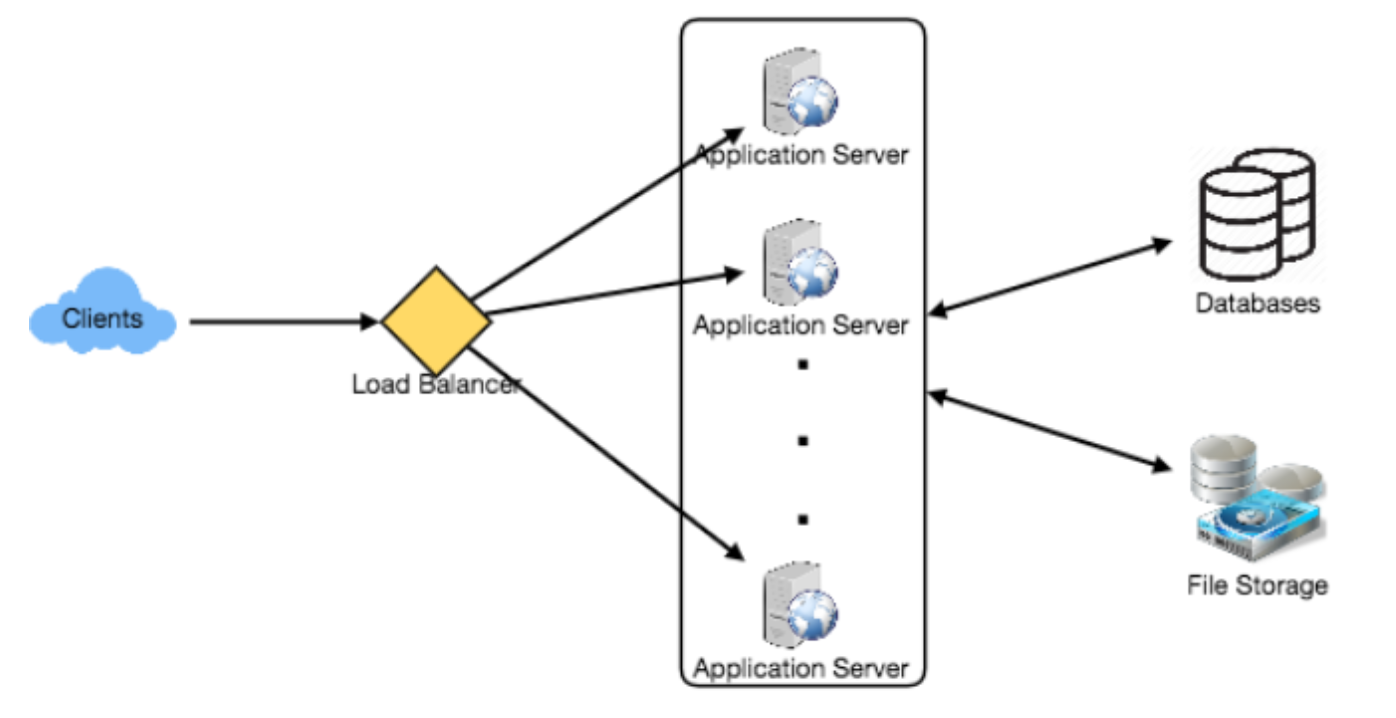
High level SD
Database Schema
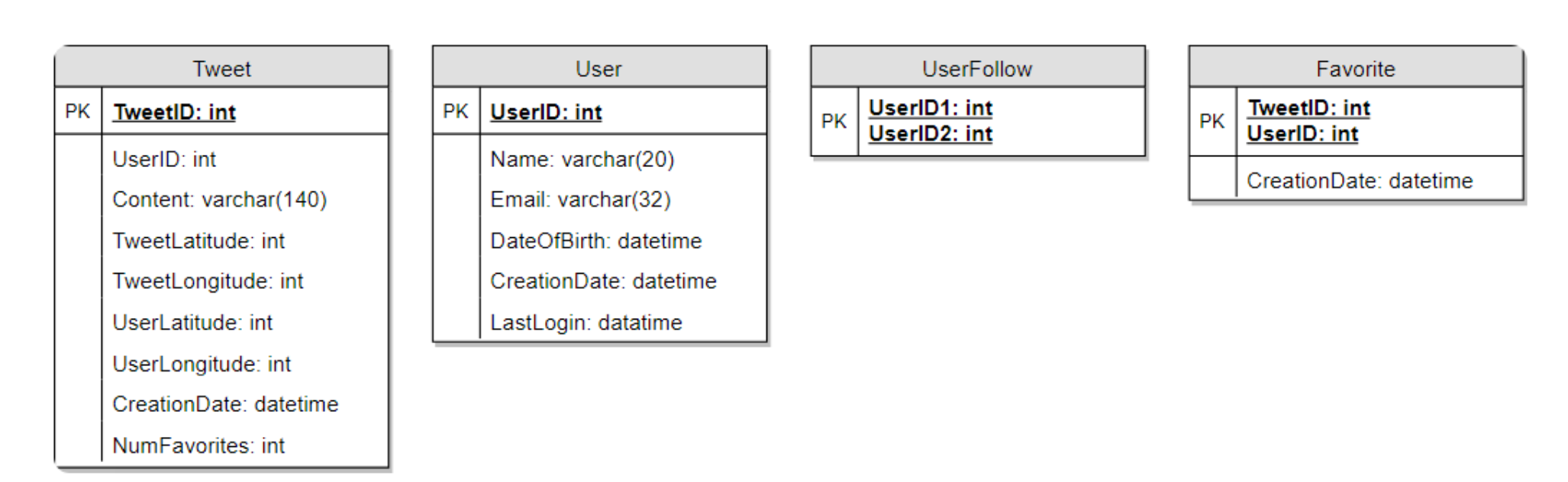
A straightforward approach for storing the above schema would be to use an
RDBMS like MySQL since we require joins. But relational databases come with their
challenges, especially when we need to scale them.
- We can store
photosin a distributed file storage like HDFS orS3. - We can store the above
schemain a distributed key-value store to enjoy the benefits offered by NoSQL.- All the metadata related to photos can go to a table where the ‘key’ would be the ‘PhotoID’ and the ‘value’ would be an object containing PhotoLocation, UserLocation, CreationTimestamp, etc.
- We need to store relationships between users and photos, to know who owns which photo. We also need to store the list of people a user follows.
- For both of these tables, we can use a wide-column datastore like Cassandra.
- For the ‘UserPhoto’ table, the ‘key’ would be ‘UserID’ and the ‘value’ would be the list of ‘PhotoIDs’ the user owns, stored in different columns. We will have a similar scheme for the ‘UserFollow’ table.
Cassandraor key-value stores in general, always maintain a certain number of replicas to offer reliability. Also, in such data stores, deletes don’t get applied instantly, data is retained for certain days (to support undeleting) before getting removed from the system permanently.
Twitter这类应用,更适合使用 Cassandra 这样的宽列数据库(或类似架构),原因如下:
Twitter 特征分析:
- 写入密集型:用户不断发推、点赞、关注等,每秒写入量极高。
- 读性能可通过反范式设计优化:例如,用户主页 Feed 是预构建好的,而不是实时聚合查询。
- 高可用要求极高:宕机意味着全球范围的服务不可用。
- 全球部署,需要多数据中心支持。
- 一致性可以适当放松(最终一致性是可接受的)。
为什么是 Cassandra?
For an app like Twitter, we need a extremely high write throughput, because users constantly post tweets, like, follow, so the system needs to handle very high write throughput.
The read side is usually optimized by precomputing the user feeds rather than doing real-time aggregation queries.
Also, availability is super critical. Any downtime affects users worldwide. Since Twitter is deployed across multiple data centers globally, the database needs to support multi-region replication.
Cassandra fits well because it doesn’t have a single leader node—it’s decentralized and highly fault-tolerant. Plus, it offers tunable consistency, and eventual consistency is acceptable for this kind of application.
So overall, Cassandra’s write performance, high availability, global distribution support, and relaxed consistency model make it a great fit for Twitter-like systems.
| 要求 | Cassandra 提供 |
|---|---|
| 高写入吞吐 | LSM Tree + 去中心化架构,写性能极高 |
| 无单点故障 | P2P 架构,每个节点都能接收写 |
| 高可用 | 数据自动多副本,容错能力强 |
| 多数据中心部署 | 原生支持,多活同步写入 |
| 可调一致性 | 可根据业务选择强一致或最终一致 |
| 反范式建模支持 | 宽列模型天然支持冗余字段、反规范化存储 |
MongoDB 不太适合 Twitter 的原因:
- 写入压力高时主节点可能成为瓶颈。
- Sharding 和分布式部署复杂度更高。
- 多活写支持不如 Cassandra 成熟。
Data Sharding
Since we have a huge number of new tweets every day and our read load is extremely
high too, we need to distribute our data onto multiple machines such that we can
read/write it efficiently. We have many options to shard our data; let’s go through
them one by one:
- Sharding based on UserID
- Sharding based on TweetID
- Sharding based on Tweet creation time


Cache
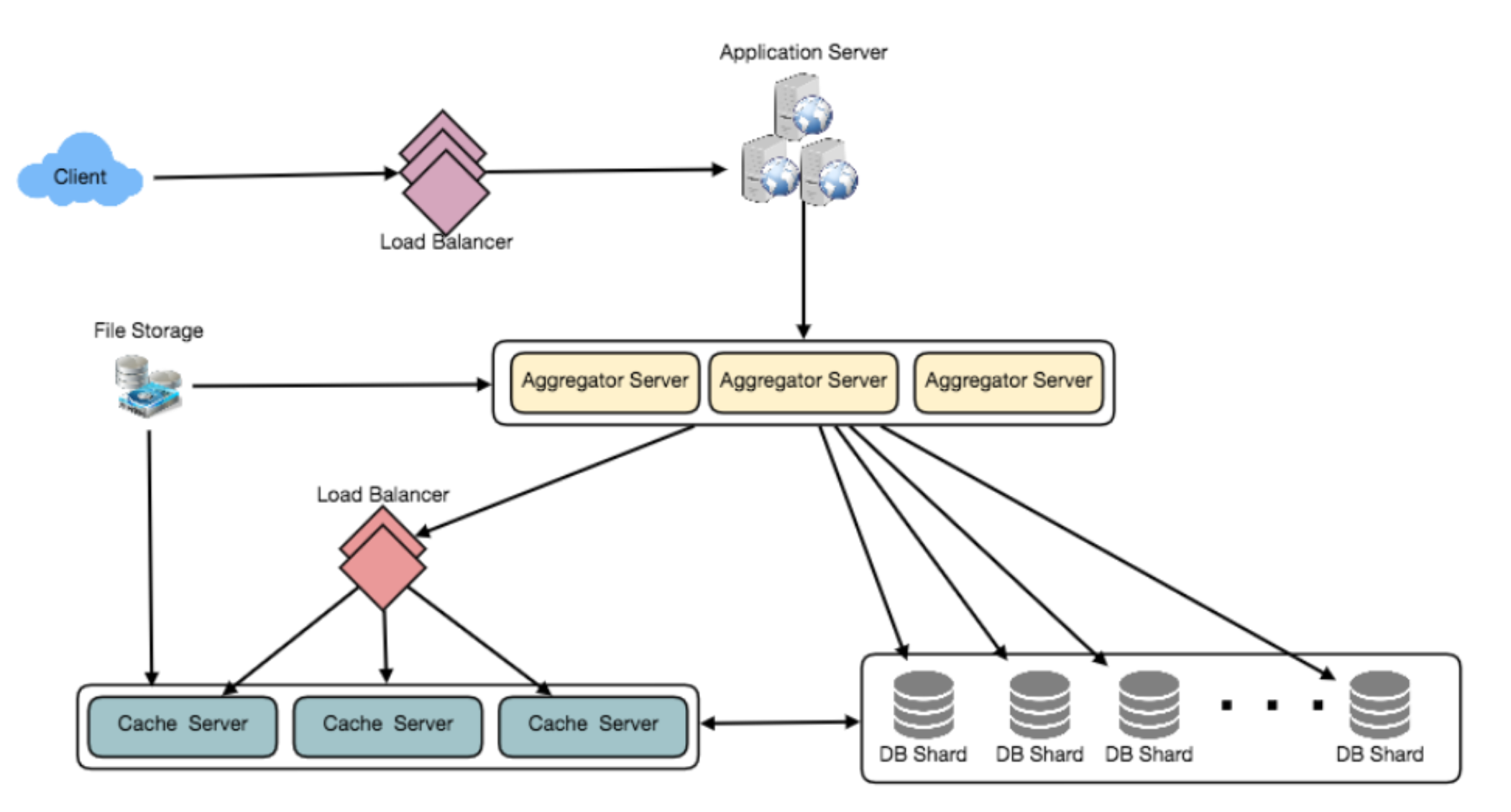
Timeline generation
- Feed generation: News feed is generated from the posts (or feed items) of users and
entities (pages and groups) that a user follows.- Offline generation for newsfeed: We can have dedicated servers that are continuously generating users’ newsfeed and storing them in memory. So, whenever a user requests for the new posts for their feed, we can simply serve it from the pre-generated, stored location.
- Feed publishing: The process of pushing a post to all the followers is called a fanout
- the
pushapproach is calledfanout-on-write, - the
pullapproach is calledfanout-on-load. hybrid
- the
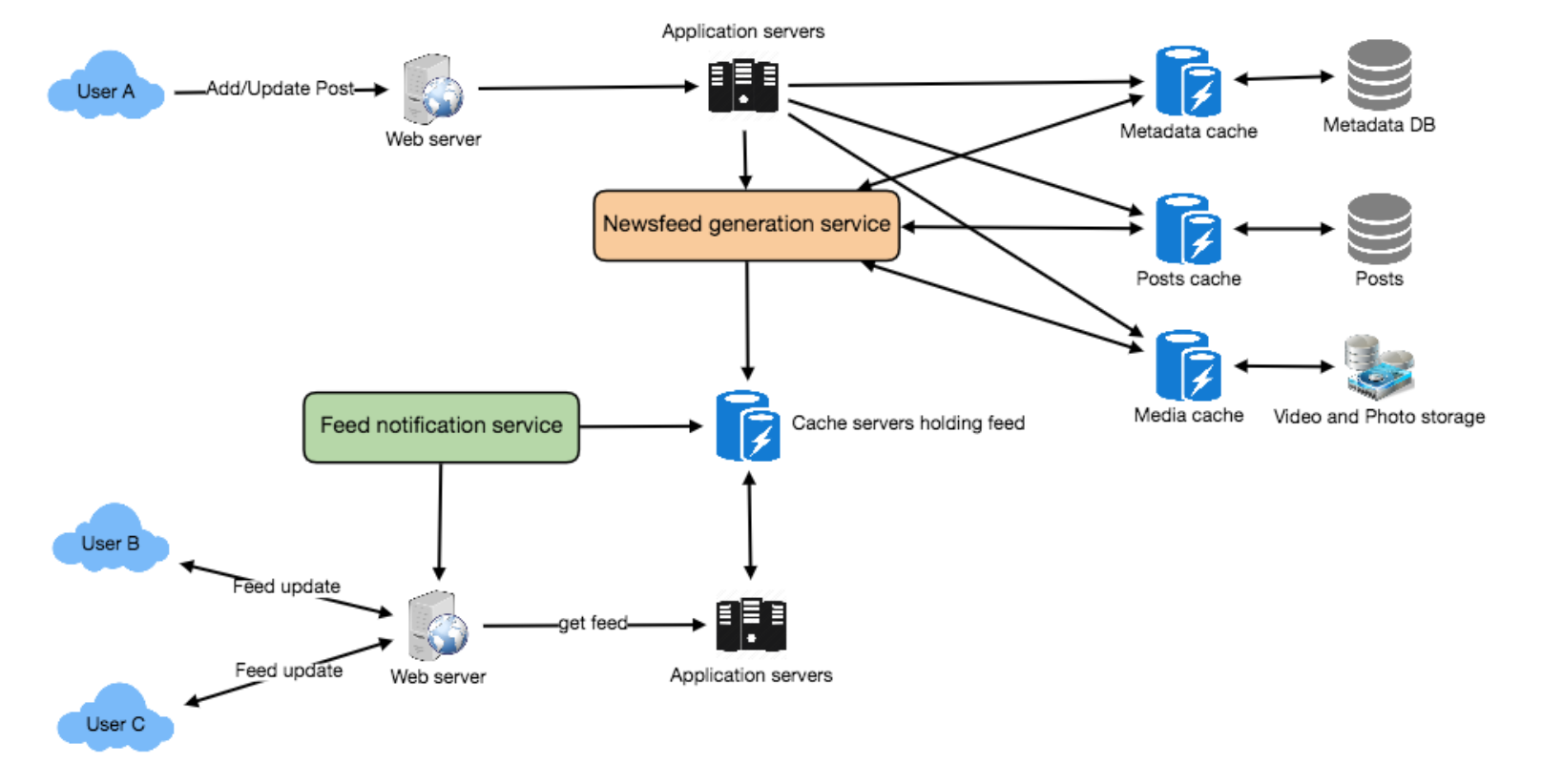
Design FB Live Comments - middle
Design Uber - hard
Design Youtube - hard
Design Web Crawler - hard
Design Ad Click Aggregator - hard
Design a RESTful API backend for a fullstack web app
- 身份验证(JWT, OAuth)
- 多用户协作(文档编辑、聊天)
- 前端状态同步机制(useEffect + polling / WebSocket)
- 如何在 React 前端和 Spring Boot 后端协同设计接口