Java-fullstack SD:
美国 Java 全栈开发的系统设计(System Design)面试中,常见的题目聚焦在高并发、可扩展性、数据一致性、微服务架构等核心问题。以下是最常考的系统设计题(尤其是中高级职位或全栈岗位):
Java 全栈岗位额外可能考察的系统设计内容:
- 前后端解耦设计(API 设计规范、接口版本管理)
- 微服务架构设计(Spring Cloud, Netflix OSS, gRPC)
- 前端 SSR vs CSR 的选择(React 服务端渲染)
- CI/CD 与 DevOps 集成(Jenkins, Docker, Kubernetes)
- 数据一致性与 CAP 理解(尤其是 eventual consistency)
Backend SD 真题参考:
- notification system
- youtube
- uber
- comment system
- distributed MQ
- distributed counter
- Data platform
Frontend SD:
- 写一个流水灯,支持自动500ms 切换和手动切换两种. Χ
- 找一个csv格式的api table. 获取处理数据render成表单,支持分页,搜索
- React实现节流和防抖
- 如何有关一个渲染很慢的列表,提出两种以上解决方案
- 实现一个modal弹窗组件,支持嵌套
- 设计一个倒计时器,设计一个数字输入框,点击确定是开始倒计时,支持停止,继续,reset功能
- 模拟电视遥控器输入,画一个含有1-9,a-z的键盘,通过键盘上下左右控制方向,每当按下enter录入字符,将点击字符显示出来并且backspace控制删除字符。注意到达键盘边界特殊情况
- 登录表单(输入邮箱和密码,简单验证)
- 从API加载用户列表.
- 大列表懒加载
- 多步表单(Wizard)(比如注册分步骤)
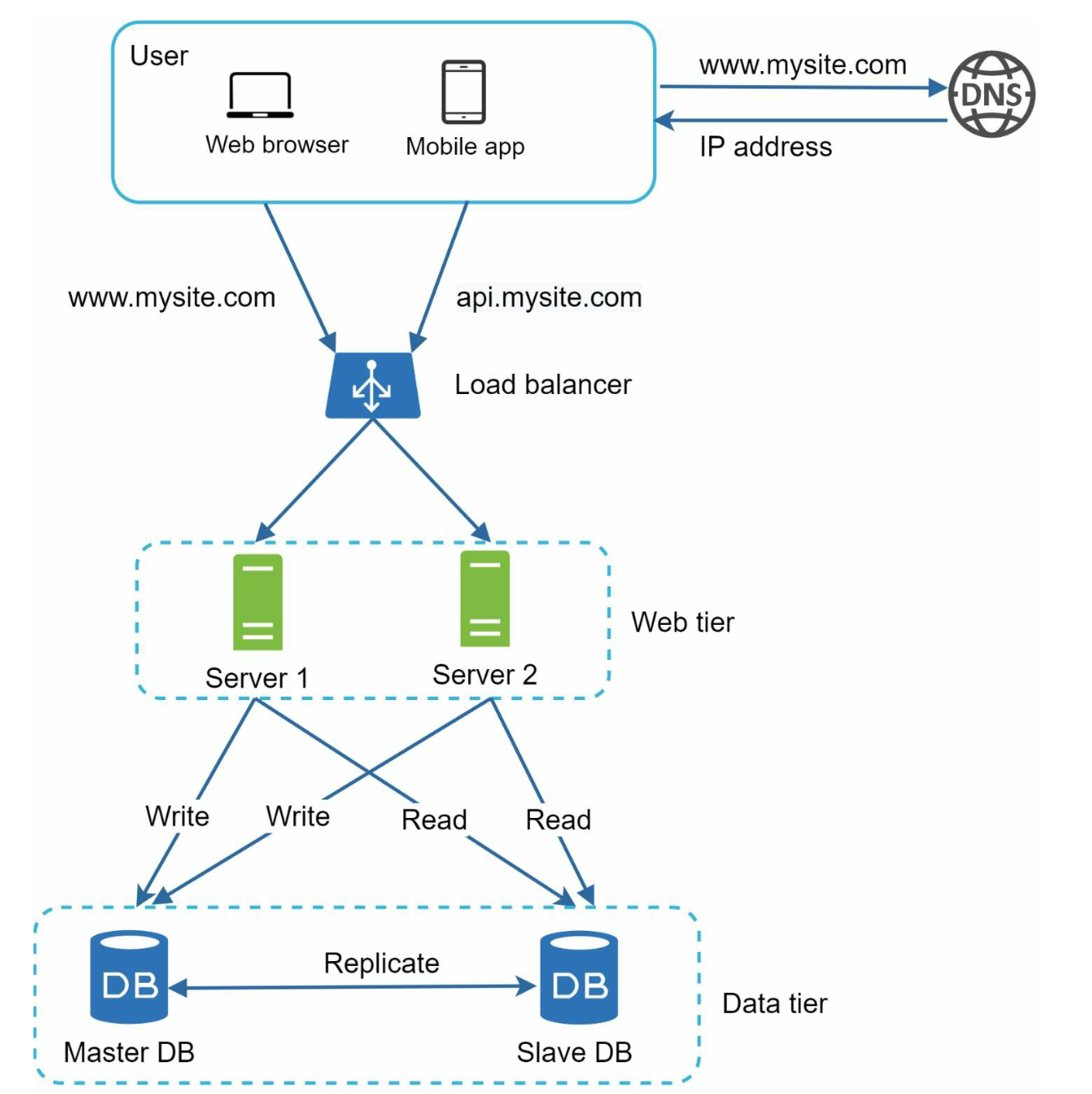
Scaling - prerequisite knowledge
Single server setup
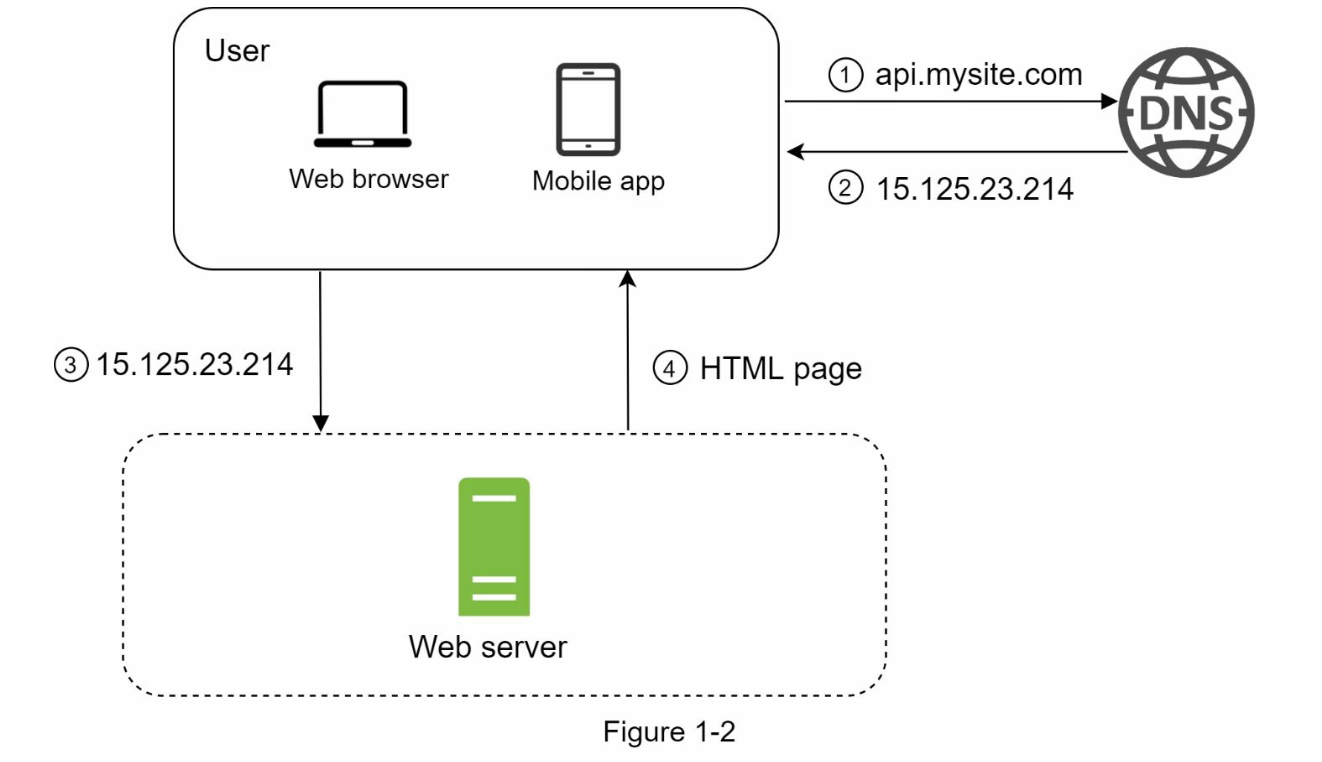
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
Database
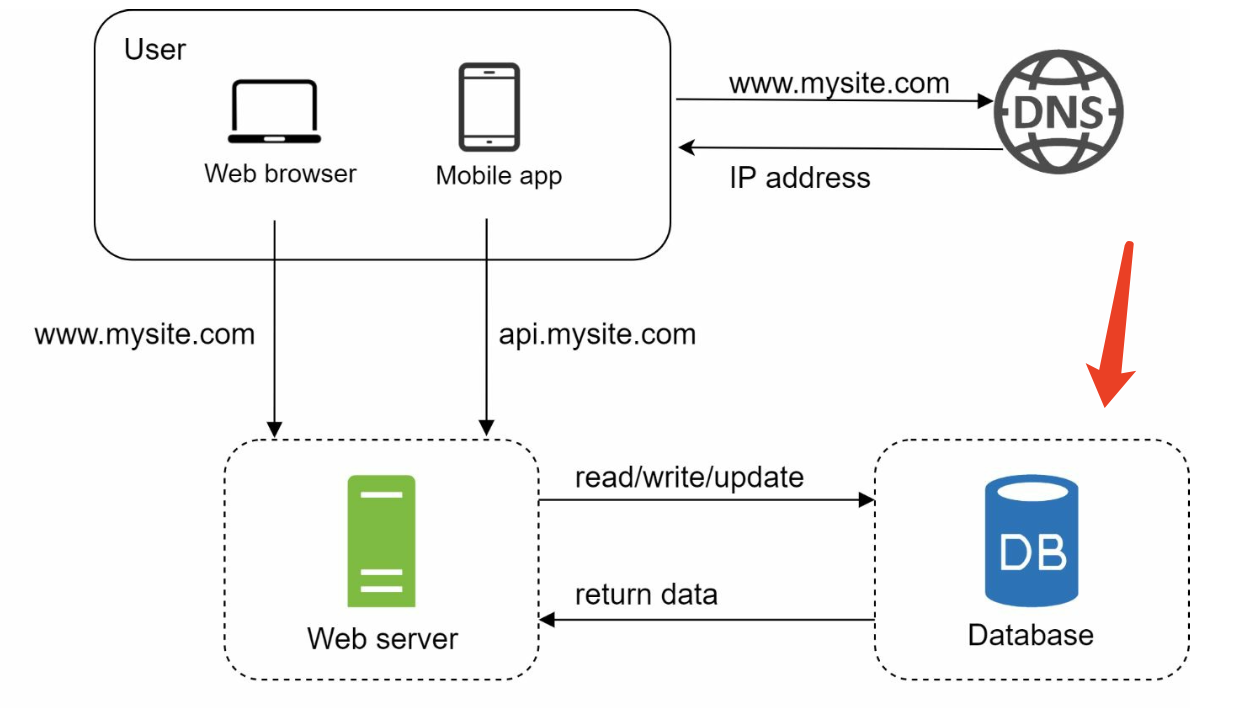
Non-relational databases might be the right choice if:
- • Your application requires super-low latency.
- • Your data are unstructured, or you do not have any relational data.
- • You only need to serialize and deserialize data (JSON, XML, YAML, etc.).
- • You need to store a massive amount of data.
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
Vertical scaling vs horizontal scaling
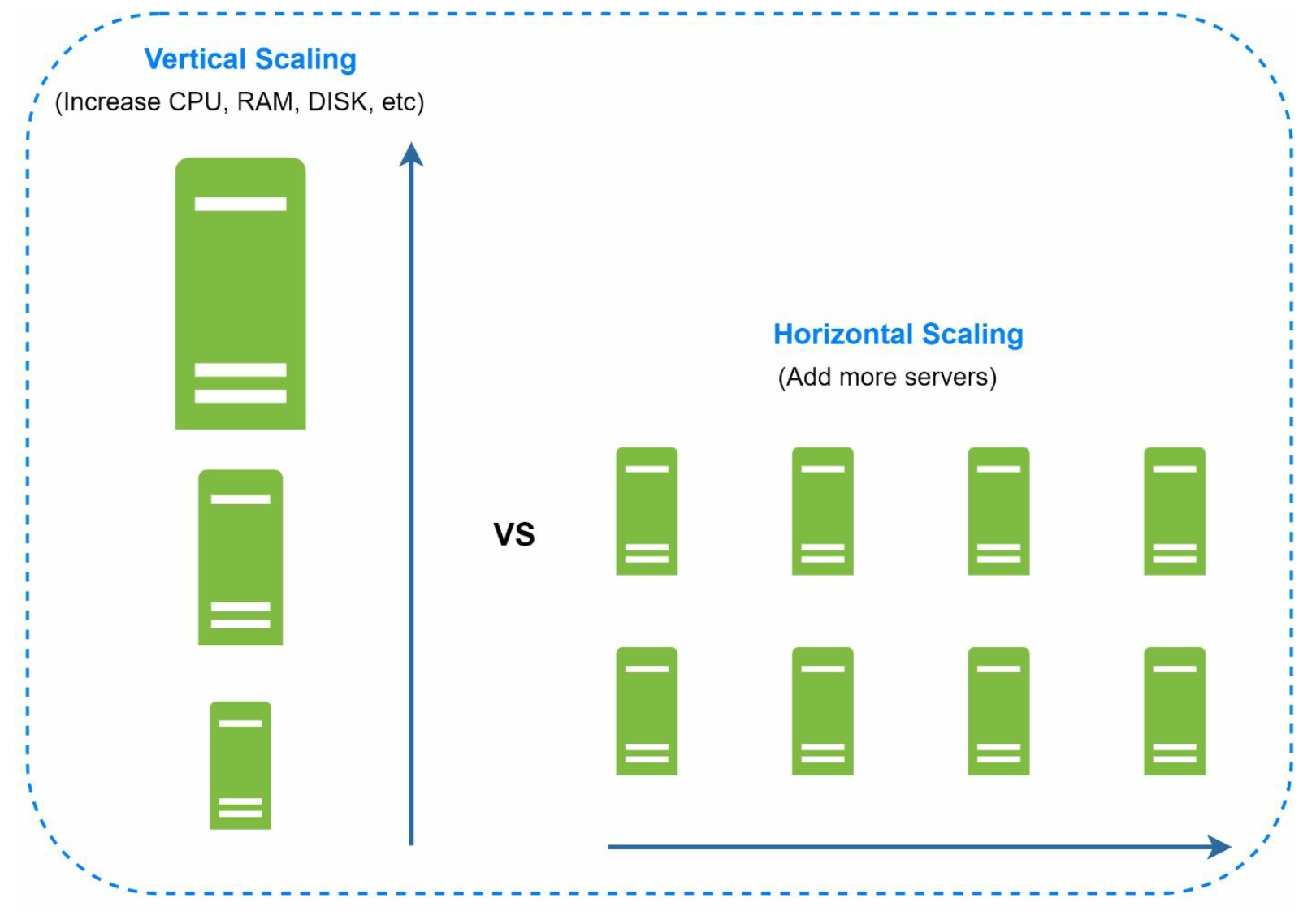
- Vertical scaling, referred to as “scale up”
- means the process of adding more power (CPU, RAM, etc.) to your servers.
- it comes with serious limitations:
- • Vertical scaling has a hard limit. It is impossible to add unlimited CPU and memory to a single server.
- • Vertical scaling does not have failover and redundancy. If one server goes down, the website/app goes down with it completely.
- Horizontal scaling, referred to as “scale out”
- allows you to scale by adding more servers into your pool of resources.
- Horizontal scaling is more desirable for large scale applications due to the limitations of vertical scaling
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
Load balancer
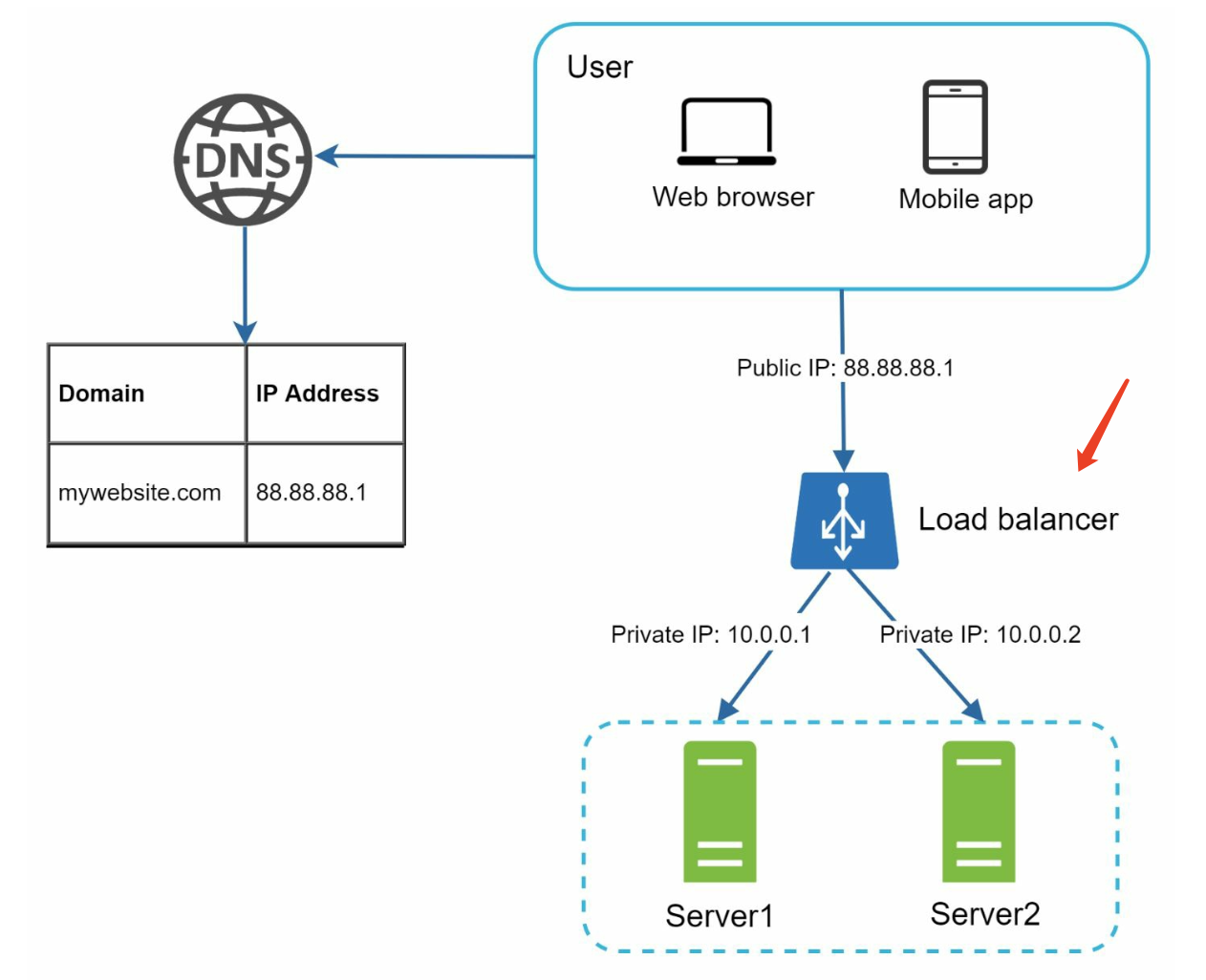
after a load balancer and a second web server are added, we successfully
solved no failover issue and improved the availability of the web tier. Details are explained
below:
- • If
server 1goes offline, all the traffic will be routed toserver 2. This prevents the website from going offline. We will also add a new healthy web server to the server pool to balance the load. - • If the website traffic grows rapidly, and two servers are not enough to handle the traffic, the load balancer can handle this problem gracefully. You only need to add more servers to the web server pool, and the load balancer automatically starts to send requests to them.
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
Database replication
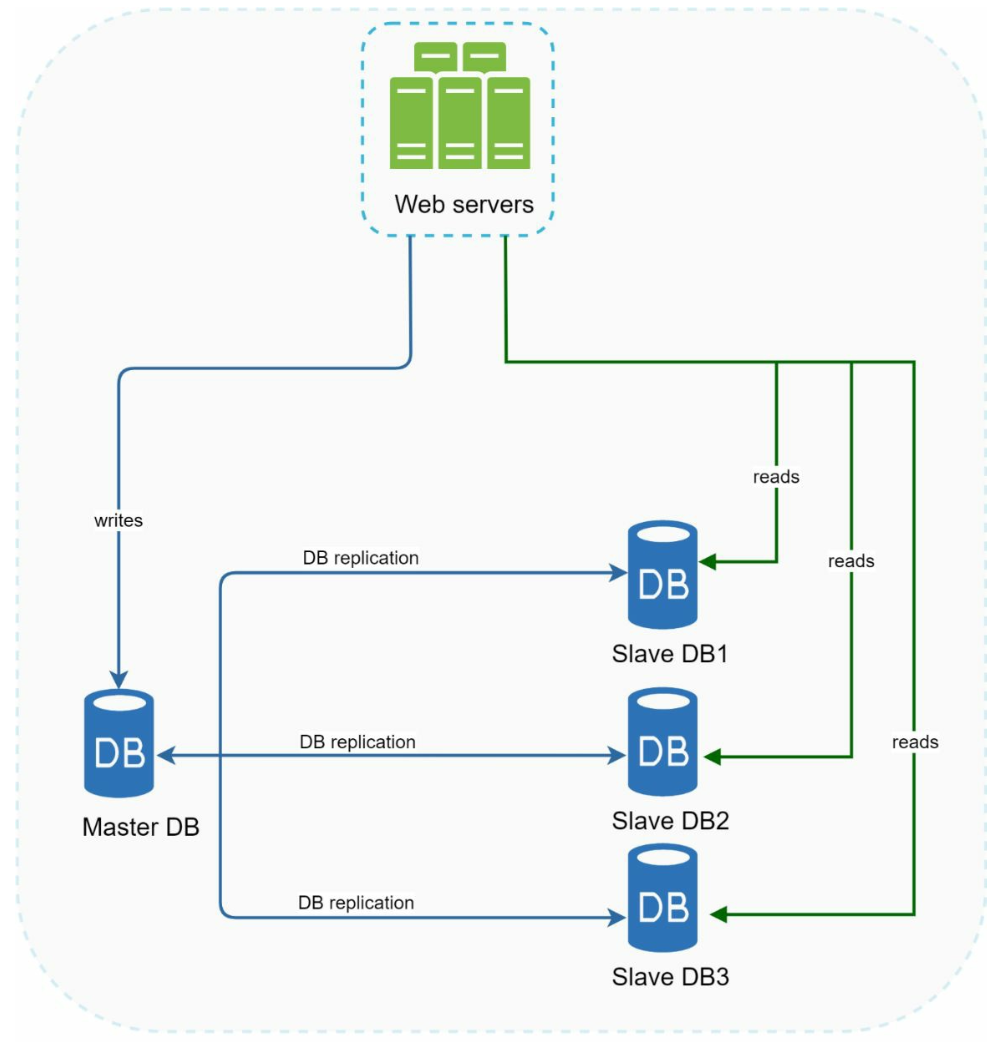
Advantages of database replication:
- Reliability
- Better performance:
- High availability:
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
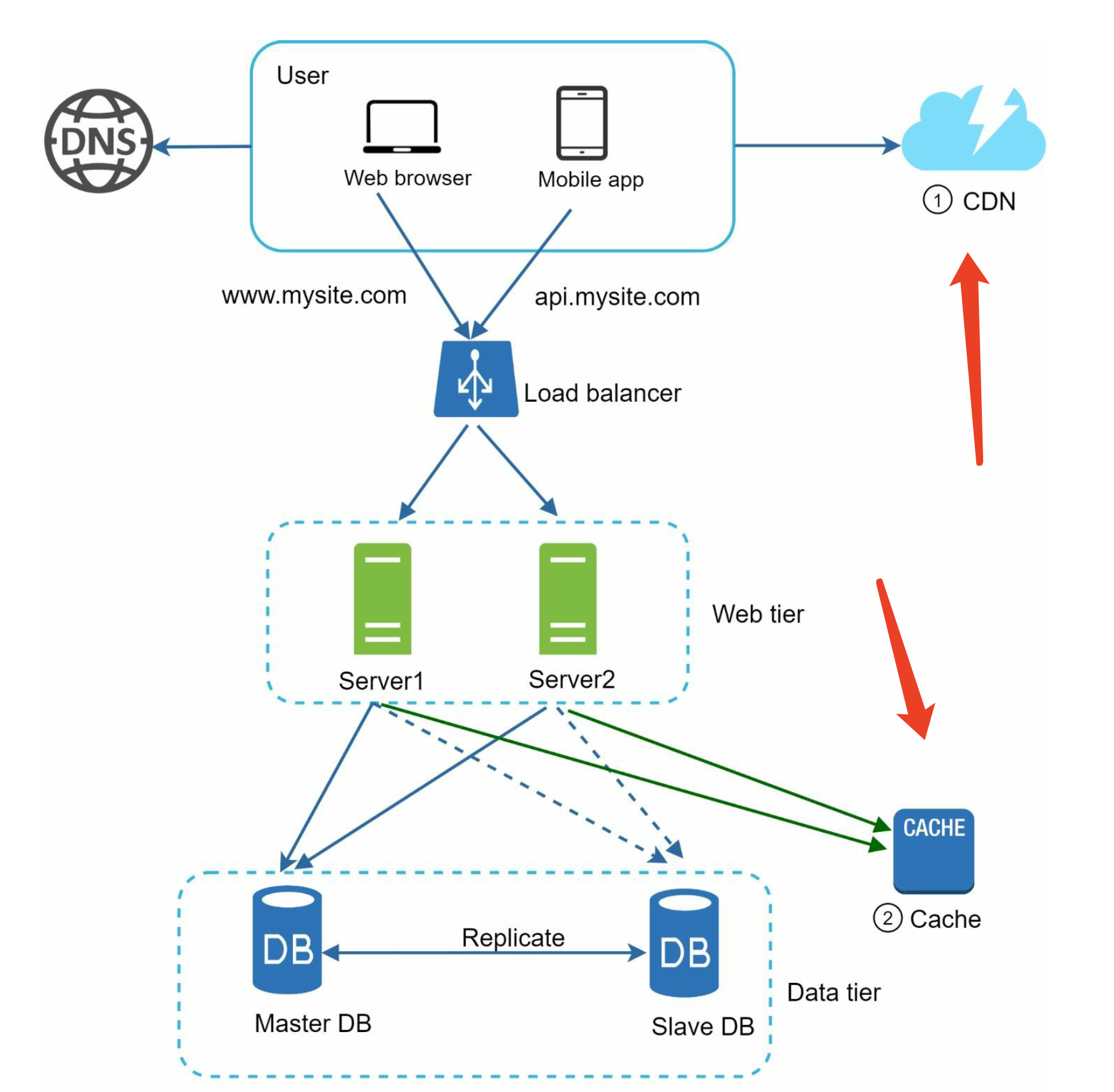
Cache

Considerations for using cache:
- • Decide when to use cache. Consider using cache when data is read frequently but modified infrequently.
- • Expiration policy. It is a good practice to implement an expiration policy. Once cached data is expired, it is removed from the cache.
- • Consistency: This involves keeping the data store and the cache in sync. Inconsistency can happen because data-modifying operations on the data store and cache are not in a single transaction.
- When scaling across multiple regions, maintaining consistency between the data store and cache is challenging. For further details, refer to the paper titled “Scaling Memcache at Facebook” published by Facebook [7].
- • Mitigating failures: A single cache server represents a potential single point of failure (SPOF), defined in Wikipedia as follows: “A single point of failure (SPOF) is a part of a system that, if it fails, will stop the entire system from working” [8].
- As a result, multiple cache servers across different data centers are recommended to avoid SPOF.
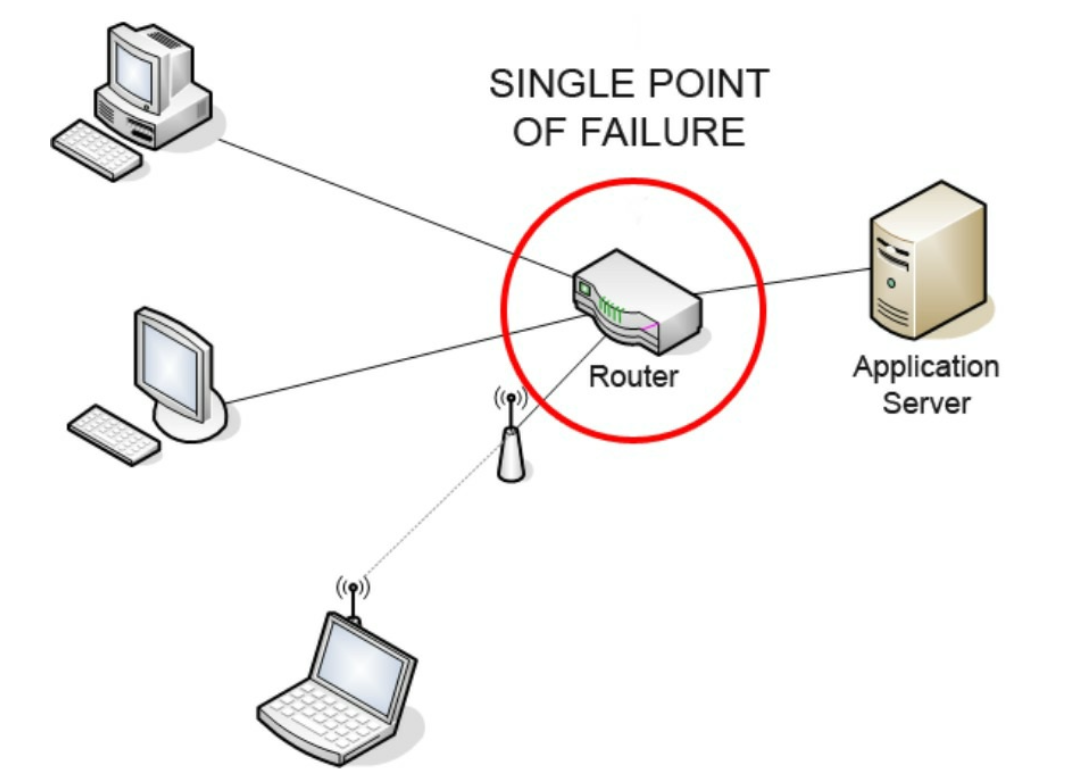
- • Eviction Policy: Once the cache is full, any requests to add items to the cache might cause existing items to be removed. This is called cache eviction. Least-recently-used (LRU) is the most popular cache eviction policy.
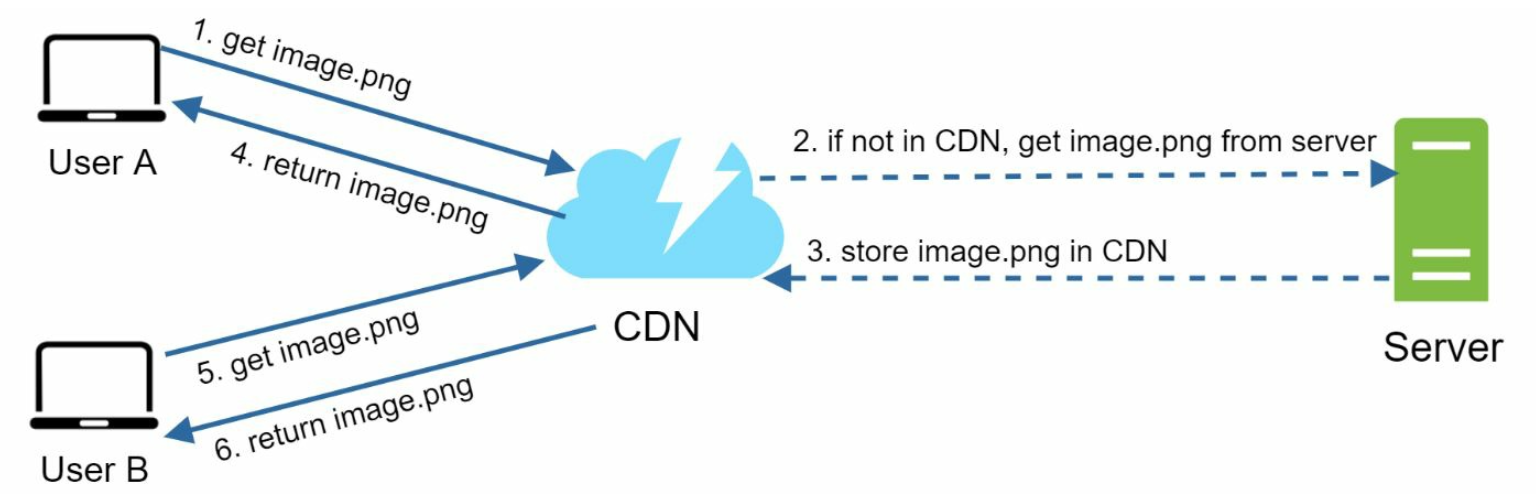
CDN
A CDN is a network of geographically dispersed servers used to deliver static content. CDN
servers cache static content like images, videos, CSS, JavaScript files, etc.
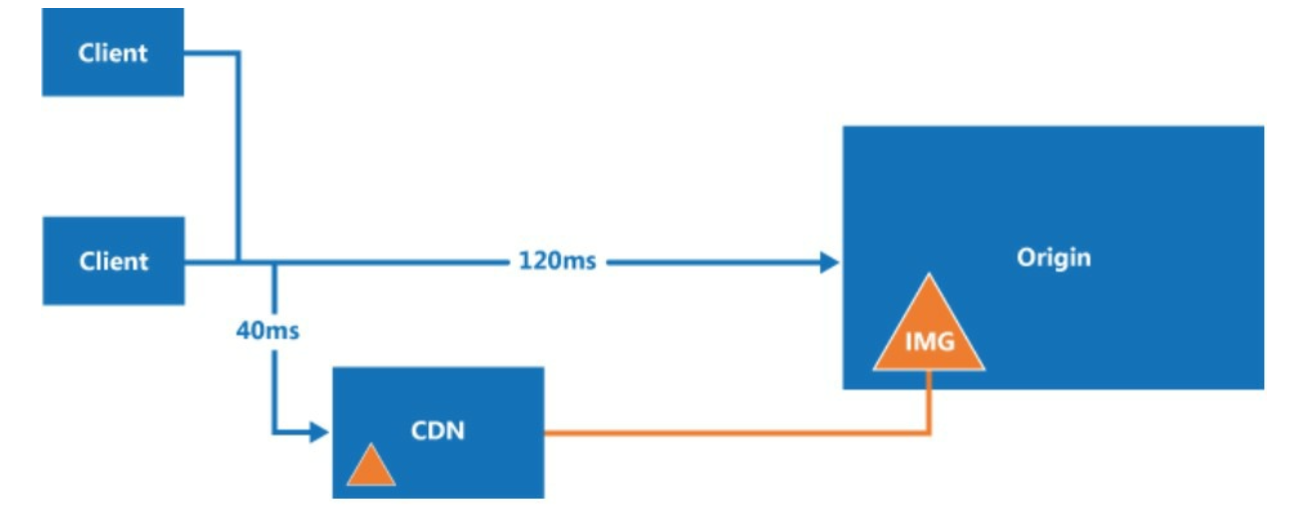
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
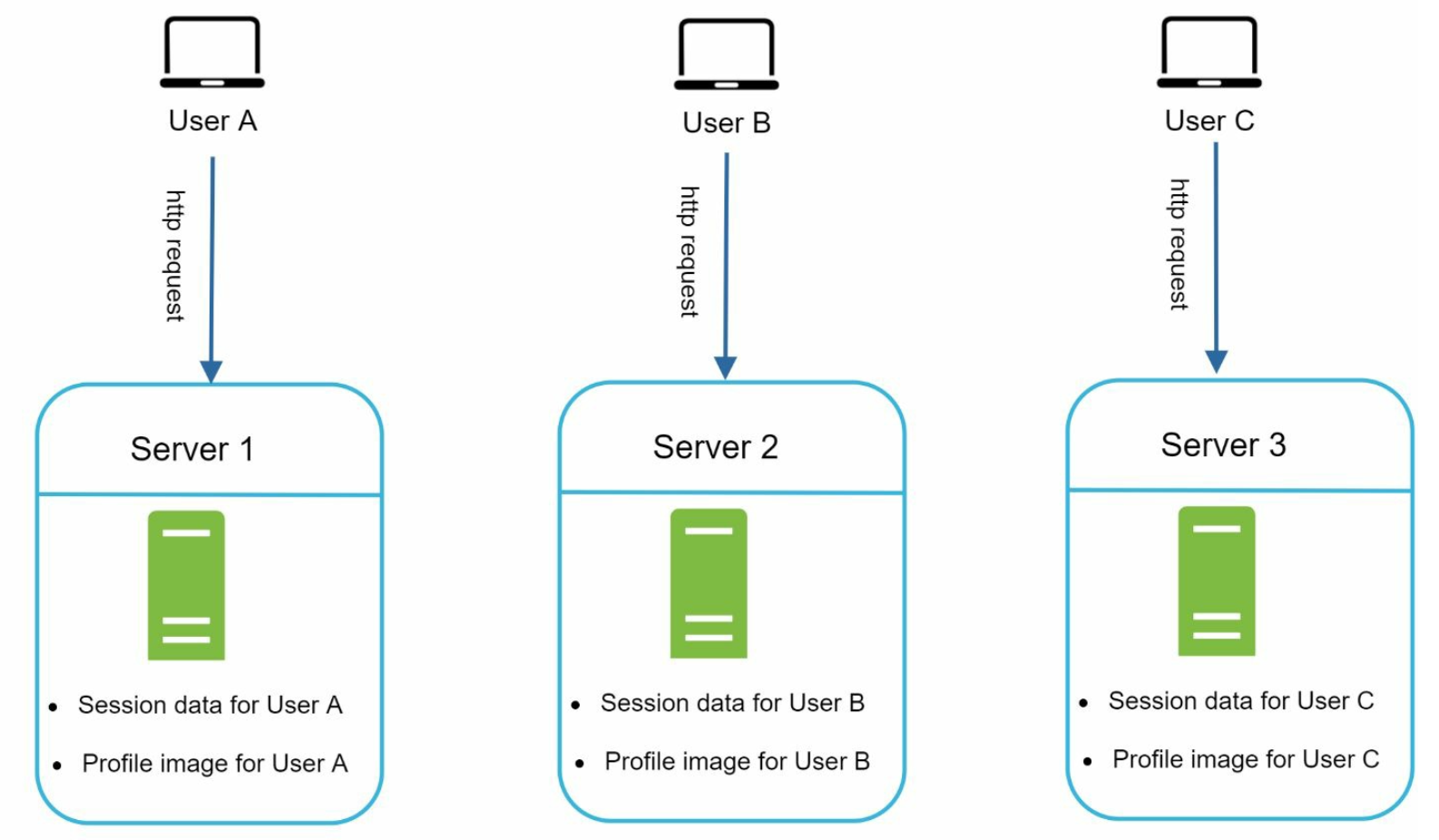
Stateless web tier
Stateful architecture:
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
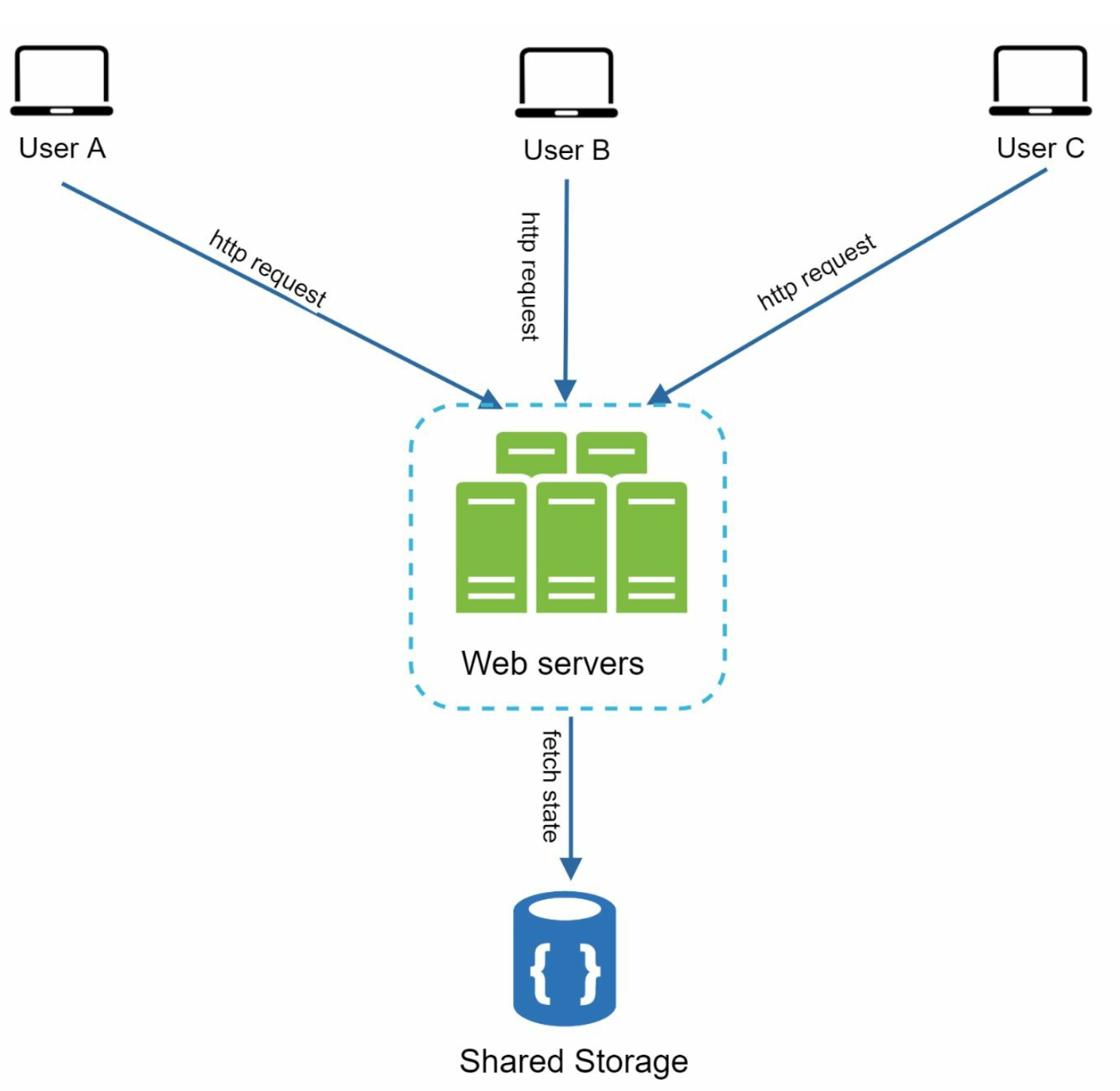
Stateless architecture:
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
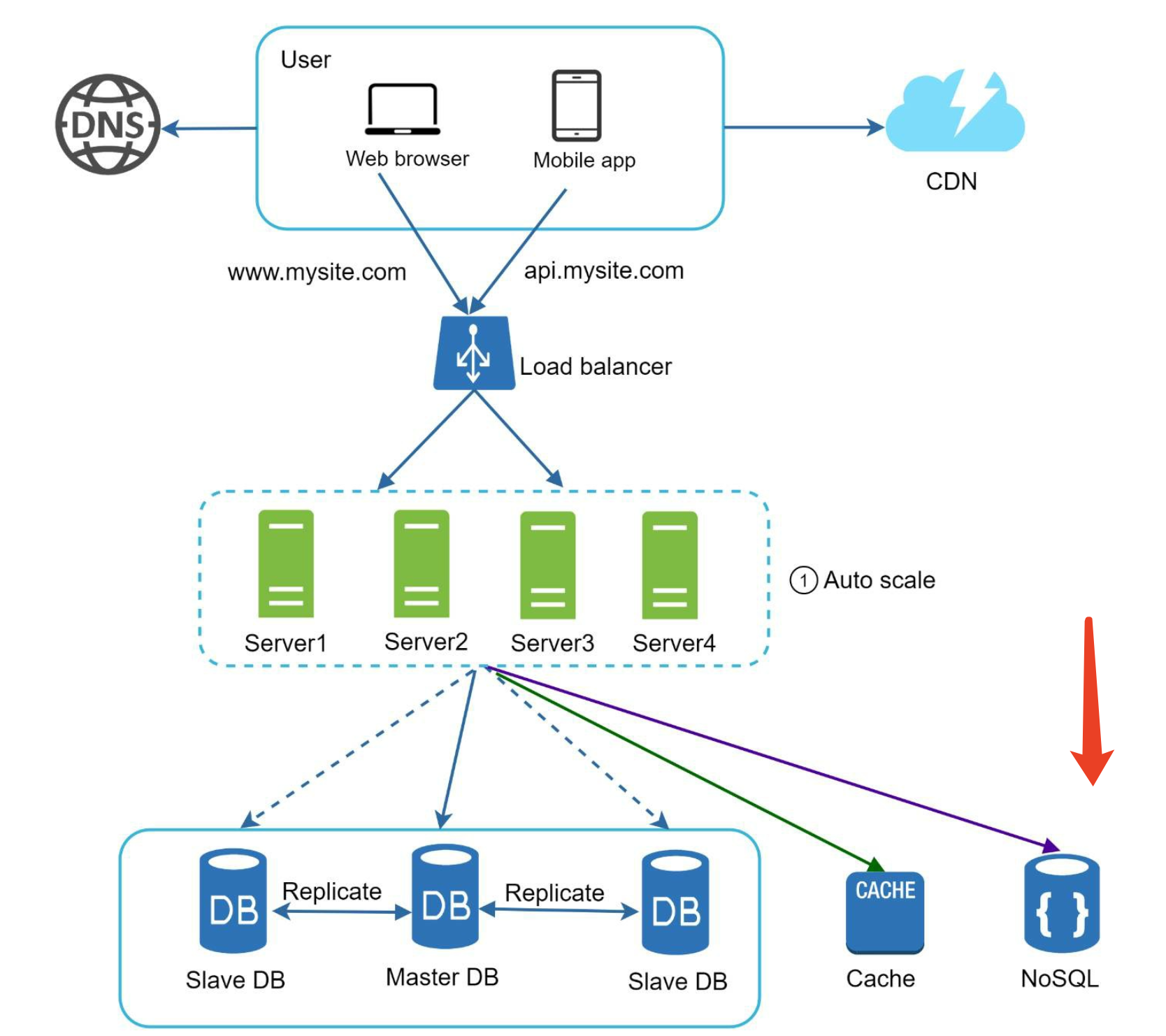
we move the session data out of the web tier and store them in the persistent data store. The shared data store could be a relational database, or Memcached/Redis, NoSQL, etc.
However, The NoSQL data store is chosen as it is easy to scale.
Data center
In normal operation, users are geoDNS-routed, also known as geo-routed, to the closest data center,
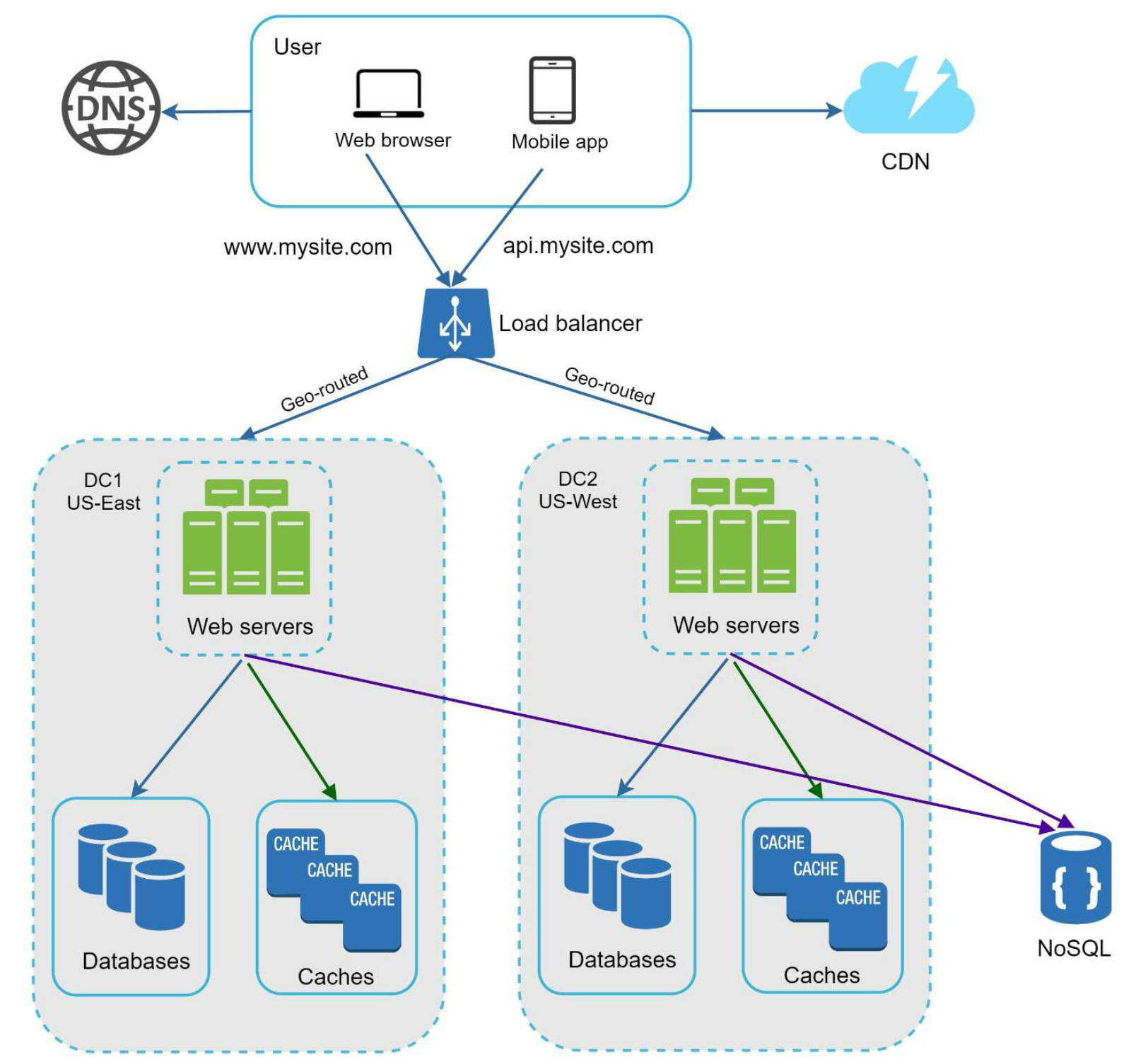
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
In the event of any significant data center outage, we direct all traffic to a healthy data center.
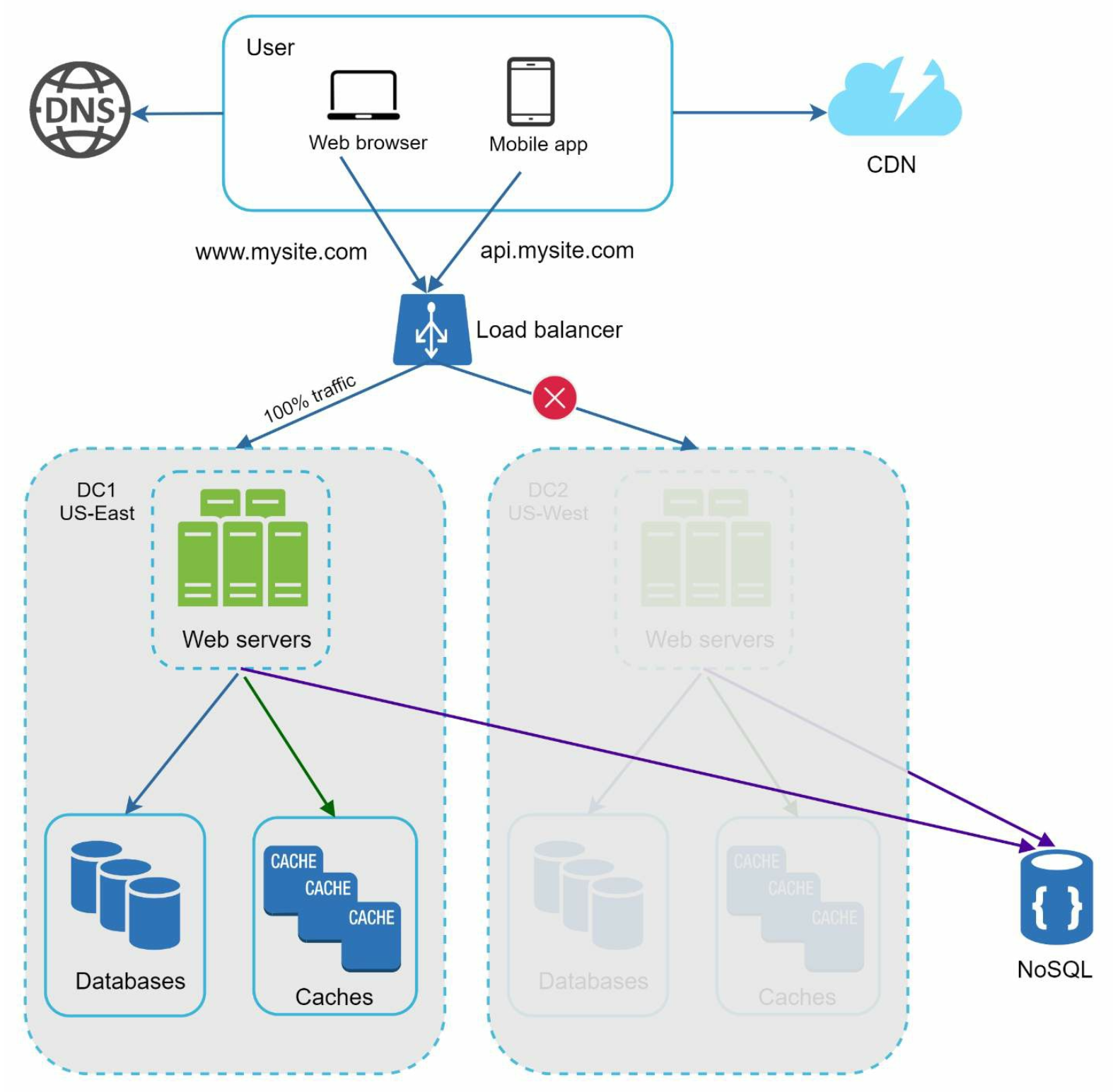
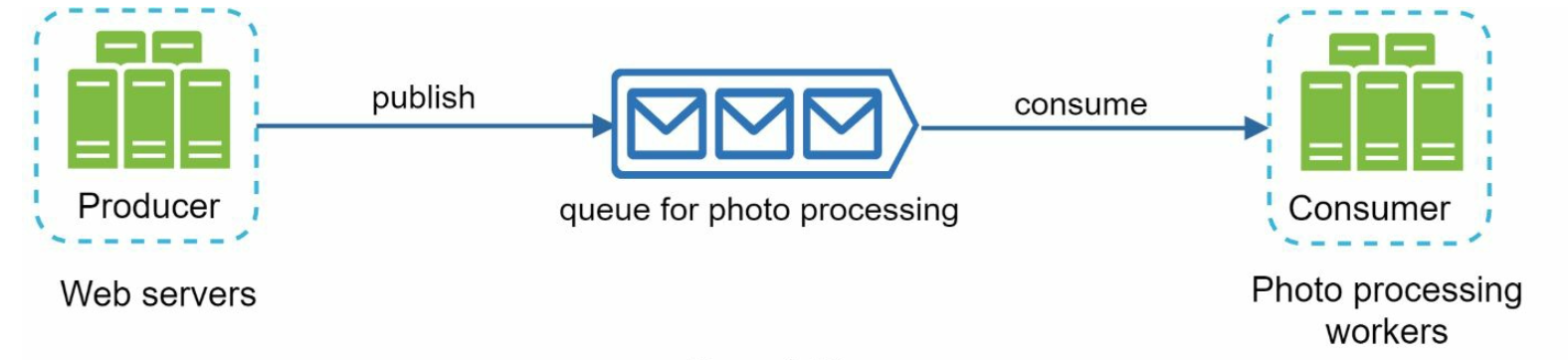
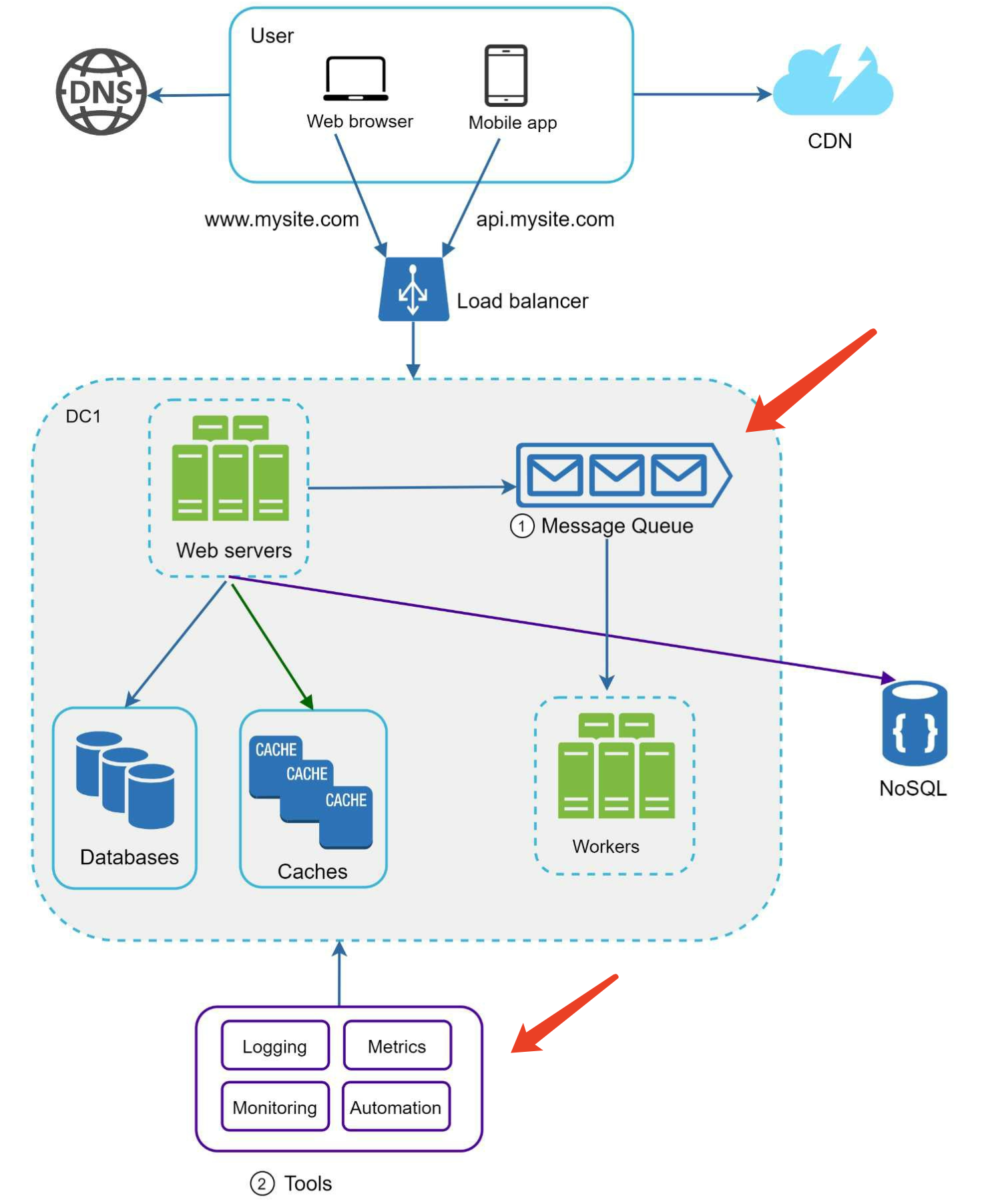
Message queue

To further scale our system, we need to decouple different components of the system so they
can be scaled independently. Messaging queue is a key strategy employed by many real-
world distributed systems to solve this problem.
Logging, metrics, automation
- Logging: Monitoring error logs is important because it helps to identify errors and problems
in the system. - Metrics: Collecting different types of metrics help us to gain business insights and understand
the health status of the system. Some of the following metrics are useful:- • Host level metrics: CPU, Memory, disk I/O, etc.
- • Aggregated level metrics: for example, the performance of the entire database tier, cache tier, etc.
- • Key business metrics: daily active users, retention, revenue, etc.
- Automation: CI/CD, When a system gets big and complex, we need to build or leverage automation
tools to improve productivity.
Database scaling - Sharding
sharding:
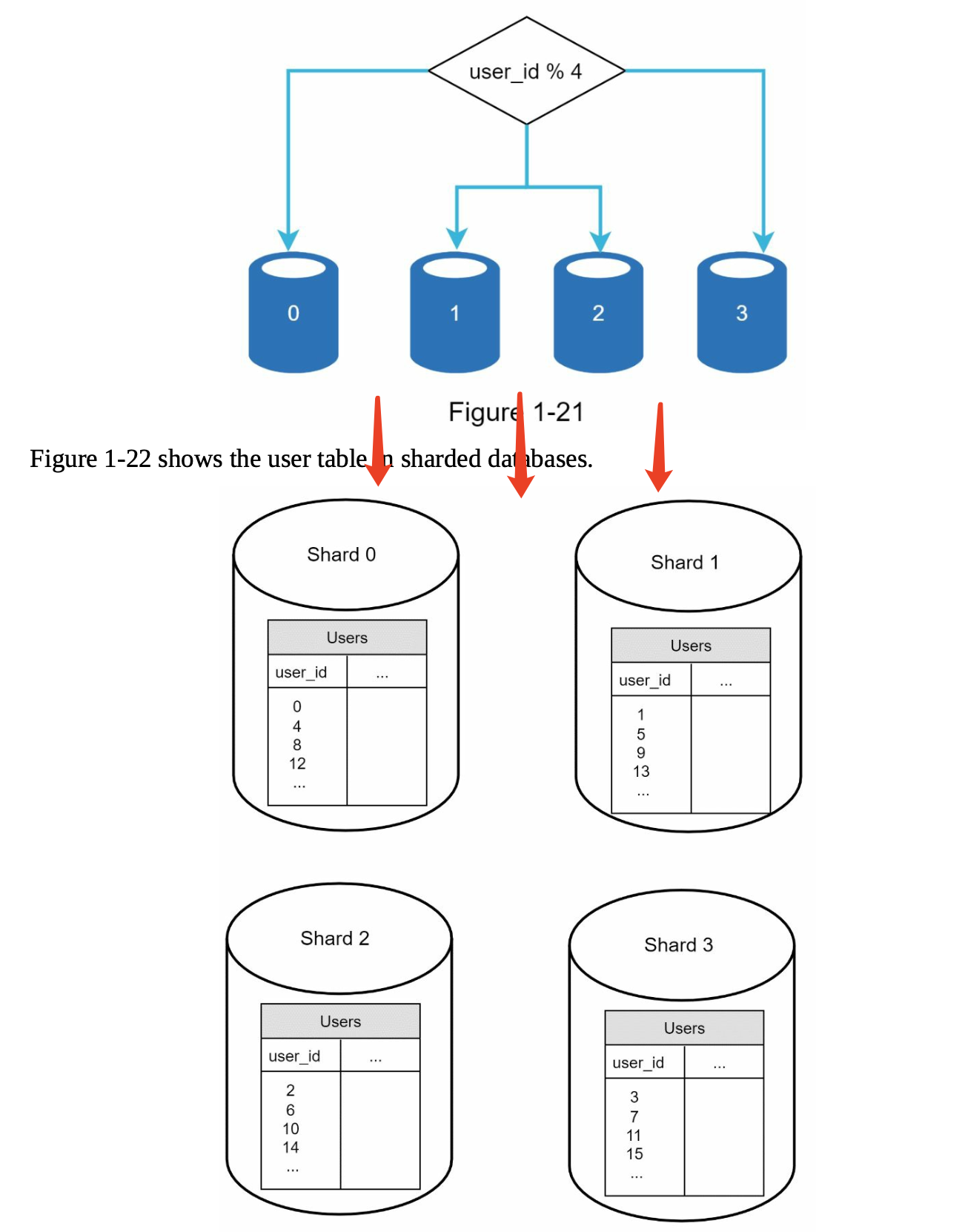
It introduces complexities and new challenges to the system:
- Resharding data: Resharding data is needed when
- 1) a single shard could no longer hold more data due to rapid growth.
- 2) Certain shards might experience shard exhaustion faster than others due to uneven data distribution.
- Consistent hashing, is a commonly used technique to solve this problem.
- Celebrity problem: This is also called a
hotspotkey problem. Excessive access to a specific shard could cause server overload.- Imagine data for Katy Perry, Justin Bieber, and Lady Gaga all end up on the same shard. For social applications, that shard will be overwhelmed with read operations.
- To solve this problem, we may need to allocate a shard for each celebrity. Each shard might even require further partition.
- Join and de-normalization: Once a database has been sharded across multiple servers, it is hard to perform join operations across database shards.
- A common workaround is to
de-normalize(反规范化) the database so that queries can be performed in a single table.
- A common workaround is to
Denormalization(反规范化)
Denormalization(反规范化)的操作,是指在设计数据库时有意引入冗余,以提升读取性能、减少跨表查询(特别是在分布式系统中)。常见的具体操作包括:
复制字段(Field Duplication)
将某些字段从关联表复制到当前表中,避免 JOIN。
例:将用户姓名从 users 表复制到 orders 表,避免查询订单时还要 JOIN users。
合并表(Table Merging)
将多个高度关联的表合并成一个宽表(wide table)。
例:将 users 和 user_profiles 合并成一个 user_full_info 表。
添加冗余数据(Redundant Data)
存储一些计算后的字段或聚合数据。
例:在商品表中直接保存评论数量或平均评分,而不是每次去评论表计算。
嵌套结构(常用于NoSQL)
在文档型数据库(如 MongoDB)中,直接把关联数据嵌套到一个文档中。
例:一个用户文档中嵌套其所有订单数据。
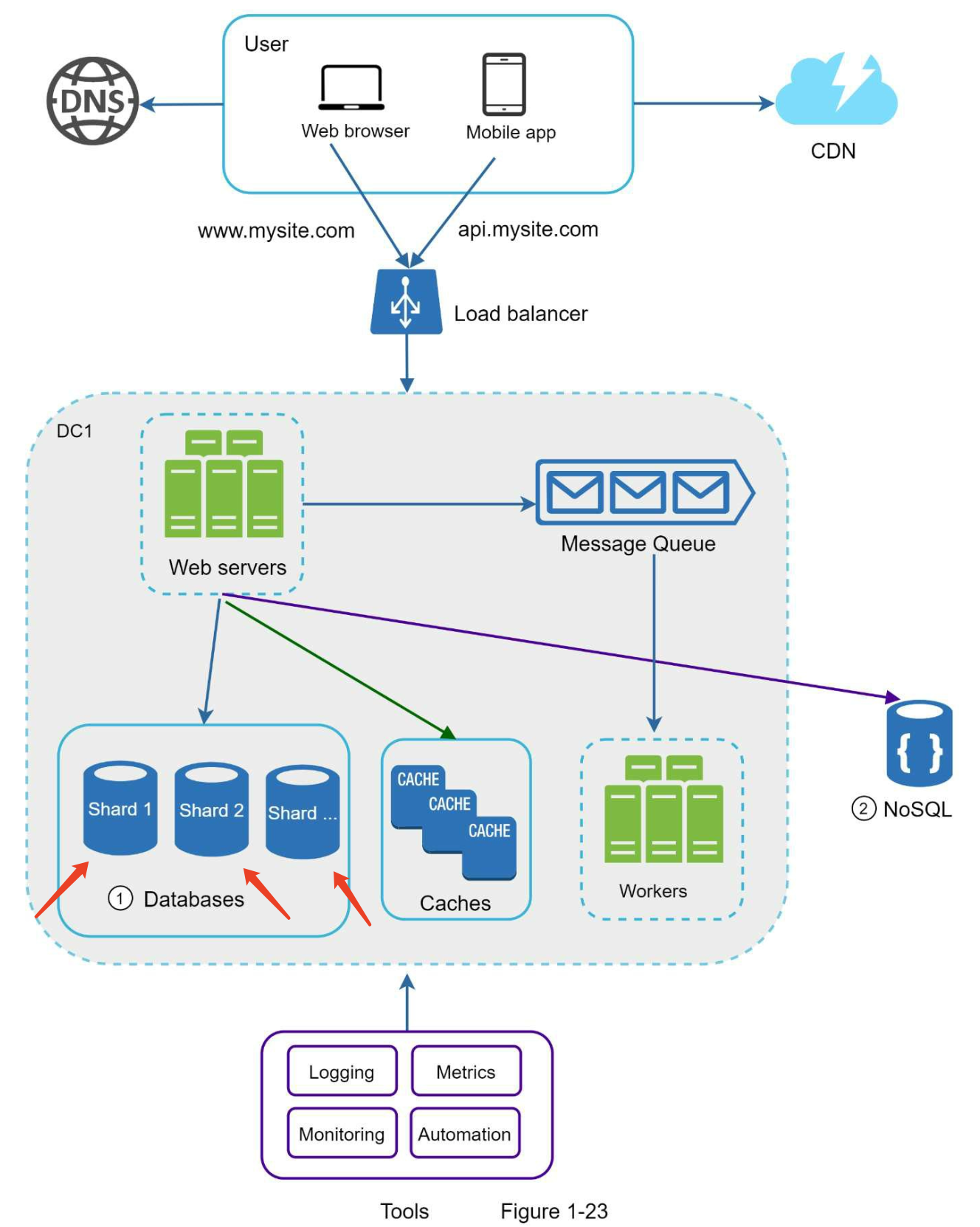
Conclusion
To conclude this chapter, we provide a summary of how we scale our system to support millions of users:
- • Keep web tier stateless
- • Build redundancy at every tier
- • Cache data as much as you can
- • Support multiple data centers
- • Host static assets in CDN
- • Scale your data tier by sharding
- • Split tiers into individual services
- • Monitor your system and use automation tools
Back-of-the-envelope Estimation
Back-of-the-envelope estimation(粗略估算)是指用非常简单、快速的方法进行大致计算,不追求精确,只为评估一个数量级或判断某个方案是否可行。
这个术语来自字面意思:“在信封背面随手写下的计算”,常见于系统设计、商业分析、工程等场景
面试中常见:
“你设计一个视频上传服务,预估每天有多少数据写入?”
你可以:
- 假设每天 1 亿个用户中有 1% 上传视频
- 每个视频平均 100MB
- 那就是:
1,000,000 × 100MB= 约 100TB/天
这就是典型的 back-of-the-envelope 估算。
Example: Estimate Twitter QPS and storage requirements
Please note the following numbers are for this exercise only as they are not real numbers from Twitter:
Assumptions:
- 300 million monthly active users.
- 50% of users use Twitter daily.
- Users post 2 tweets per day on average.
- 10% of tweets contain media.
- Data is stored for 5 years.
Answer Estimations:
- Query per second (QPS) estimate:
- Daily active users (DAU) =
300 million * 50%= 150 million - Tweets QPS =
150 million * 2 tweets / 24 hour / 3600 seconds=~3500 - Peek QPS =
2 * QPS= ~7000
- Daily active users (DAU) =
- We will only estimate media storage here.
- Average tweet size:
- tweet_id 64 bytes
- text 140 bytes
- media 1 MB
- Media storage:
150 million * 2 * 10% * 1 MB=30 TBper day15M * 2 * 1MB=30M * 1MB=30, 000, 000 MB=30 TB
- 5 - year media storage:
30 TB * 365 * 5=~30 TB * 1500=~55, 000 TB=~55 PB
Framework for SD interview
If you are asked to design a news feed system:
step1-Understand the problem and establish design scope
“Design scope” 指的是你在做系统设计时,这个设计要解决的边界、范围和目标。
更具体地说: Design scope = 你要设计什么、不设计什么、解决哪些问题、考虑到哪些场景。
One of the most important skills as an engineer is to ask the right questions, make the proper assumptions, and gather all the information needed to build a system.
So, do not be afraid to ask questions:
- Is this a mobile app? Or a web app? Or both?
- What are the most important features for the product?
- How many friends can a user have?
- What is the traffic volume?
step2-Propose high-level design and get buy-in
“buy-in” 是一个商业和产品开发中的术语,意思是:关键相关人(如团队成员、管理层、客户)对某个提议或设计的认可、支持与承诺。对方认可并决定按照这个设计推进开发,这就叫他们 give buy-in
we aim to develop a high-level design and reach an agreement with the interviewer on the design:
- Come up with an initial blueprint for the design. Ask for feedback. Treat your interviewer as a teammate and work together. Many good interviewers love to talk and get involved.
- Draw box diagrams with key components on the whiteboard or paper. This might include clients (mobile/web), APIs, web servers, data stores, cache, CDN, message queue, etc.
- Do back-of-the-envelope calculations to evaluate if your blueprint fits the scale constraints. Think out loud. Communicate with your interviewer if back-of-the-envelope is necessary before diving into it.
feed publishing: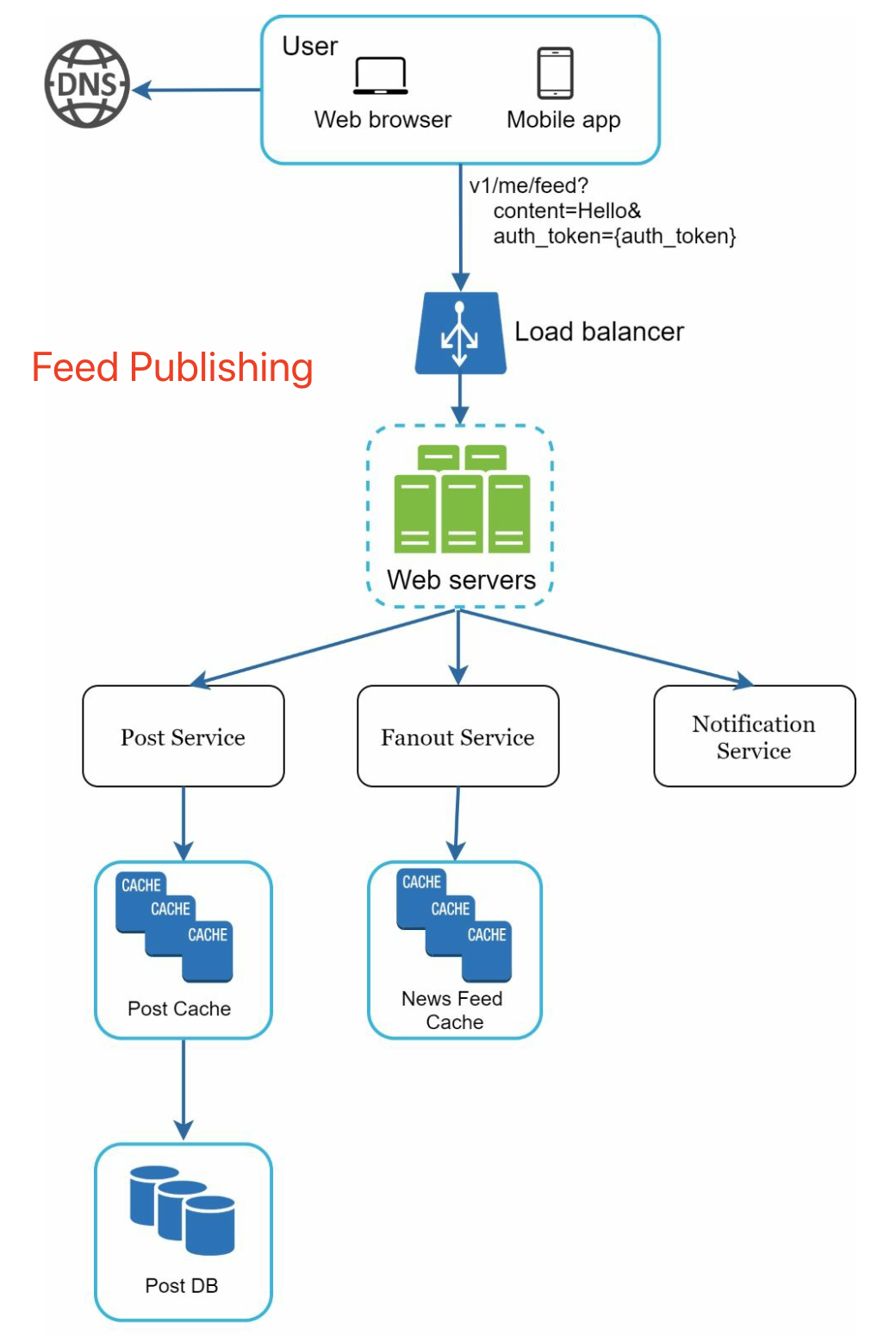
news feed building: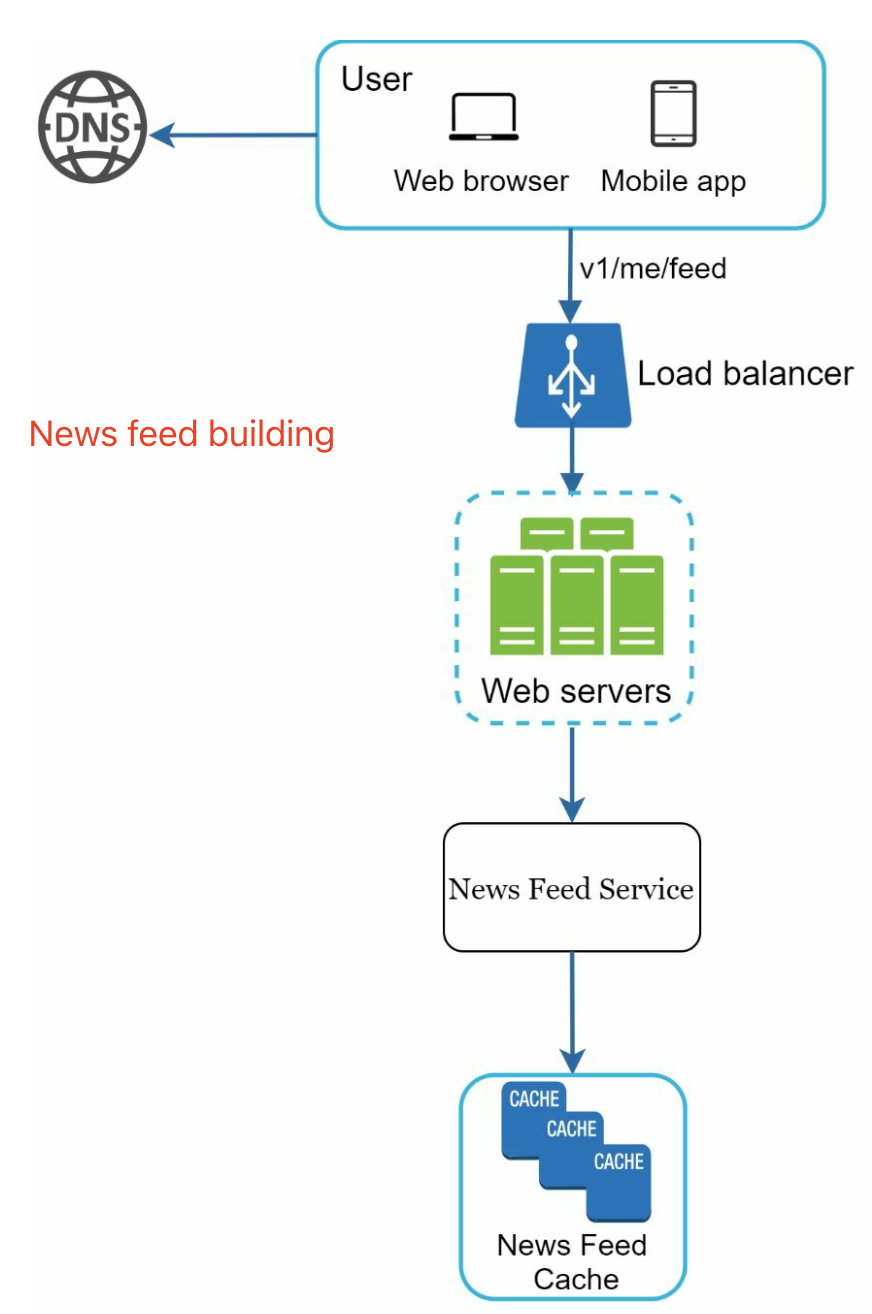
step3-Design deep dive
Sometimes, for a senior candidate interview, the discussion could be on the system performance characteristics, likely focusing
on the bottlenecks and resource estimations. In most cases, the interviewer may want you to
dig into details of some system components.
- For URL shortener, it is interesting to dive into the hash function design that converts a long URL to a short one.
- For a chat system, how to reduce latency and how to support online/offline status are two interesting topics.
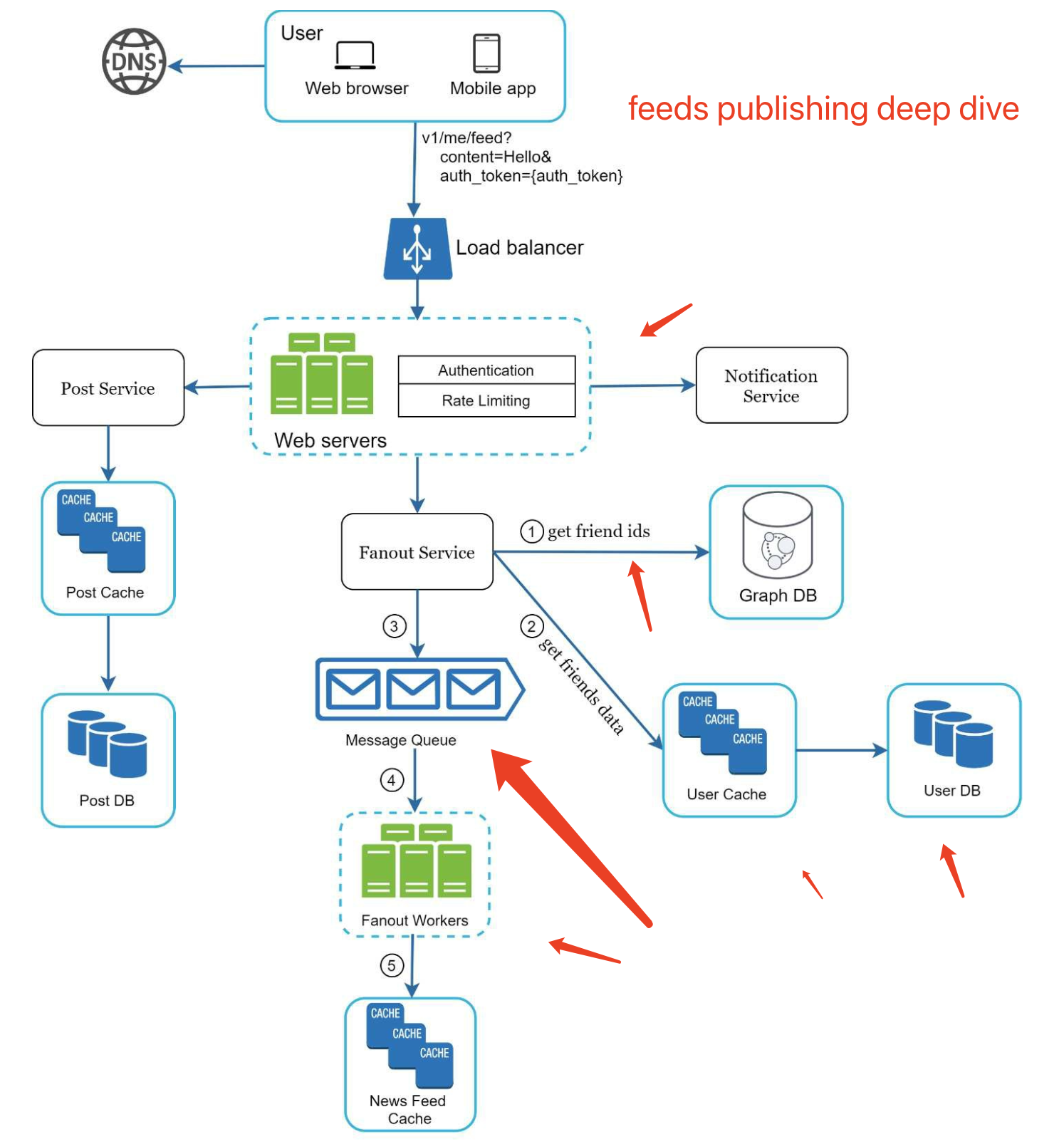
step4-Wrap up
In this final step, the interviewer might ask you a few follow-up questions or give you the freedom to discuss other additional points. Here are a few directions to follow:
- The interviewer might want you to identify the system bottlenecks and discuss potential improvements
- Error cases (server failure, network loss, etc.) are interesting to talk about.
- Operation issues are worth mentioning. How do you monitor metrics and error logs? How to roll out(逐步部署并上线系统或功能,让用户可以开始使用) the system?
- How to handle the next scale curve(随着系统规模扩大(scale),系统资源需求、性能瓶颈或架构复杂度等的增长趋势曲线) is also an interesting topic.
- For example, if your current design supports 1 million users, what changes do you need to make to support 10 million users?
Time allocation on each step
- Step 1 Understand the problem and establish design scope: 3 - 10 minutes
- Step 2 Propose high-level design and get buy-in: 10 - 15 minutes
- Step 3 Design deep dive: 10 - 25 minutes
- Step 4 Wrap: 3 - 5 minutes
Unique IDs generation
Here’s a complete production-ready design for generating unique IDs, suitable for platforms like Twitter or Instagram, focused on global uniqueness, scalability, and reliability — no code, just design:
- Globally unique IDs
- High throughput, high concurrency
- Horizontally scalable
- Roughly time-ordered (ascending)
- Resilient to clock issues
- Sharding-friendly
ID Structure (Based on Twitter Snowflake - 64 bits)
| 1 bit | 41 bits Timestamp | 5 bits Datacenter ID | 5 bits Machine ID | 12 bits Sequence |
Field Breakdown:
- 1 bit: Sign bit, always 0 (because
longis signed) - 41 bits: Timestamp in milliseconds (can support ~69 years)
- 5 bits: Datacenter ID (up to 32 data centers)
- 5 bits: Machine ID (up to 32 machines per DC)
- 12 bits: Sequence number (up to 4096 IDs per millisecond per machine)
This ensures IDs are globally unique, roughly ordered, and can be generated independently without coordination.
Assigning Datacenter and Machine IDs:
- Use a configuration service (e.g. Nacos, Consul) or service registry (e.g. ZooKeeper) to assign and manage IDs for each machine.
- Ensure no duplication across machines.
Handling Clock Skew / Time Rollback
Primary Strategy:
- If current time < last generated time:
- If small offset (< 5ms): wait until time catches up
- If large offset: log alert and fail the request
Preventative Measures:
- Disable automatic time sync (e.g., via BIOS/NTP)
- Use “slew” mode NTP to avoid sudden clock jumps
- Deploy in HA mode with backup ID generators
Alternative ID Schemes:
| Method | Characteristics | Suitable For |
|---|---|---|
| Snowflake-style | Local generation, ordered, scalable | High-scale backend systems |
| UUID + DB check | Simple but less performant | Small-scale systems |
| Leaf (Meituan) | DB-segment-based allocation | DB-centric systems |
| MongoDB ObjectId | Built-in time/machine info | Document stores like MongoDB |
MongoDB vs Cassandra
MongoDB vs Cassandra:两者都是 NoSQL 数据库,但设计哲学和使用场景完全不同。
| 特性 | MongoDB | Cassandra |
|---|---|---|
| 数据模型 | 文档型(JSON/BSON) | 宽列存储(Column Family) |
| 架构模型 | 主从复制(Replica Set) | 去中心化 P2P,无主架构 |
| 写入性能 | 中等(依赖磁盘和主节点) | 极高(LSM Tree + 去中心化) |
| 读性能 | 高,适合频繁查询 | 依赖数据模型设计和副本读取策略 |
| 可扩展性 | 水平扩展支持有限(Sharding 复杂) | 原生支持线性扩展(新节点即扩容) |
| 一致性模型 | 强一致(默认读写主节点) | 最终一致(可调一致性级别) |
| 事务支持 | 支持 ACID 事务(4.x+) | 不支持传统事务,提供轻量级事务 |
| 查询语言 | 丰富的查询语法(Mongo Query) | CQL(类 SQL) |
| 典型使用场景 | CRUD 密集型应用、实时分析、JSON 数据 | 大规模写密集场景、IoT、日志、时序数据 |
什么时候用 MongoDB?
- 数据结构灵活,字段频繁变动, 需要 NoSQL 版的 MySQL
- 需要复杂查询或聚合
- 数据量不是超大规模分布式,或你能接受通过 Sharding 扩容
- 需要事务或强一致性
什么时候用 Cassandra?
- 高并发、大吞吐写入, 但是读不太行
- 容忍最终一致性(如日志、传感器数据)
- 需要高可用、高扩展性(跨数据中心)
- 想避免单点故障
简明总结:
- MongoDB 更像 NoSQL 版的 MySQL,开发友好,功能丰富,适合数据驱动型应用。
- Cassandra 是写入吞吐怪兽,适合分布式、海量数据写入但查询简单的场景。
选谁:要看你的业务写多还是读多,数据结构是否固定,是否追求强一致或高可用
Algorithms to fetch nearby stuff
this kind of algo is the key to design a efficient LBS(location-based service), which is to find nearby businesses for a given radius and locations.
Geohash
Geohash 是一种将经纬度坐标编码为字符串的空间索引方法,适用于地理位置的快速查询、排序和分片,广泛用于地图服务、LBS、数据库地理索引等场景。
It works by reducing the two-dimensional longitude and latitude data into a one-dimensional string of letters and digits. Geohash algorithms work by recursively dividing the world into smaller and smaller grids with each additional bit.
它通过将二维的经度和纬度数据简化为一个由字母和数字组成的一维字符串来实现。地理哈希算法通过随着每增加一位而递归地将世界划分为越来越小的网格来起作用。
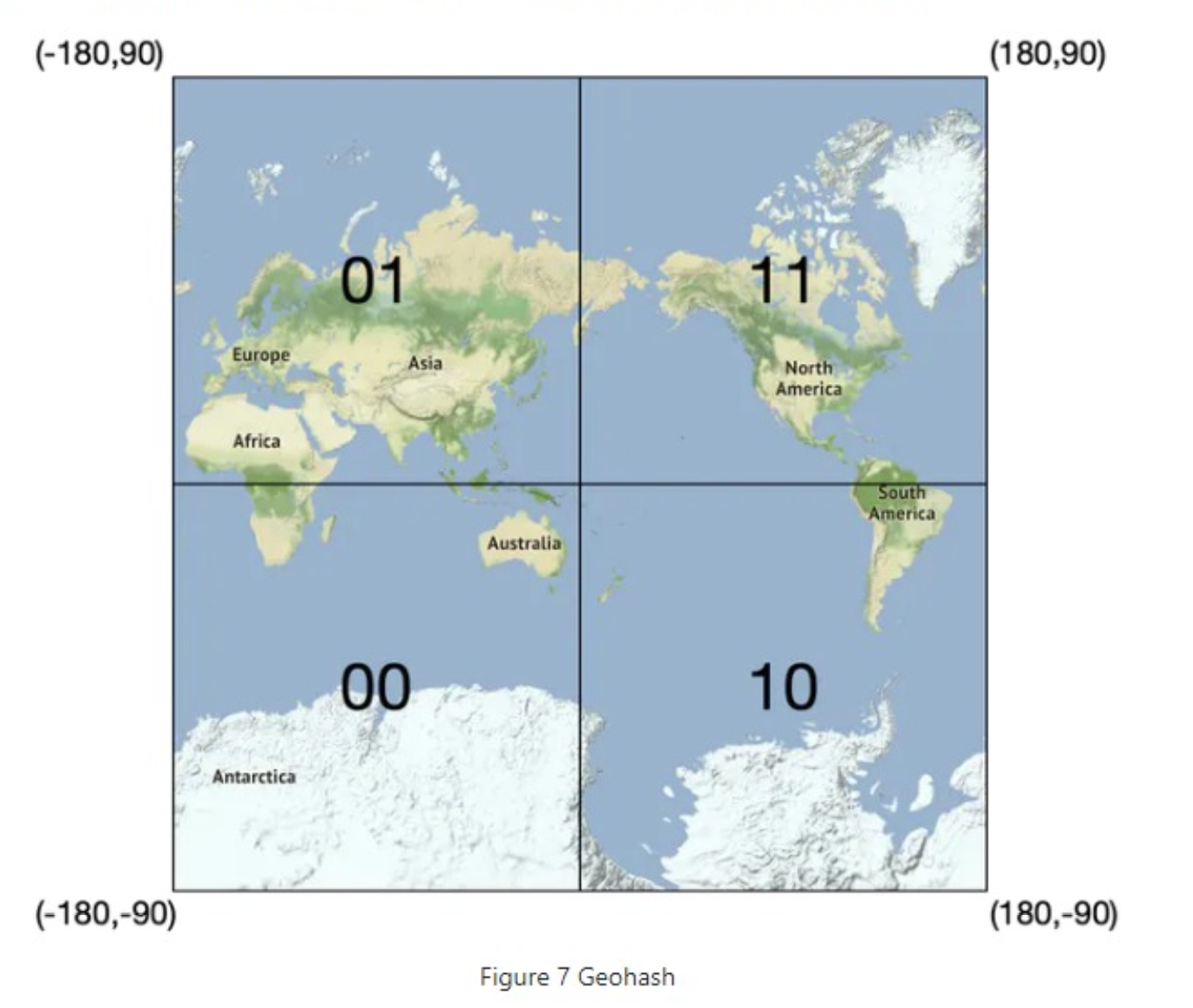
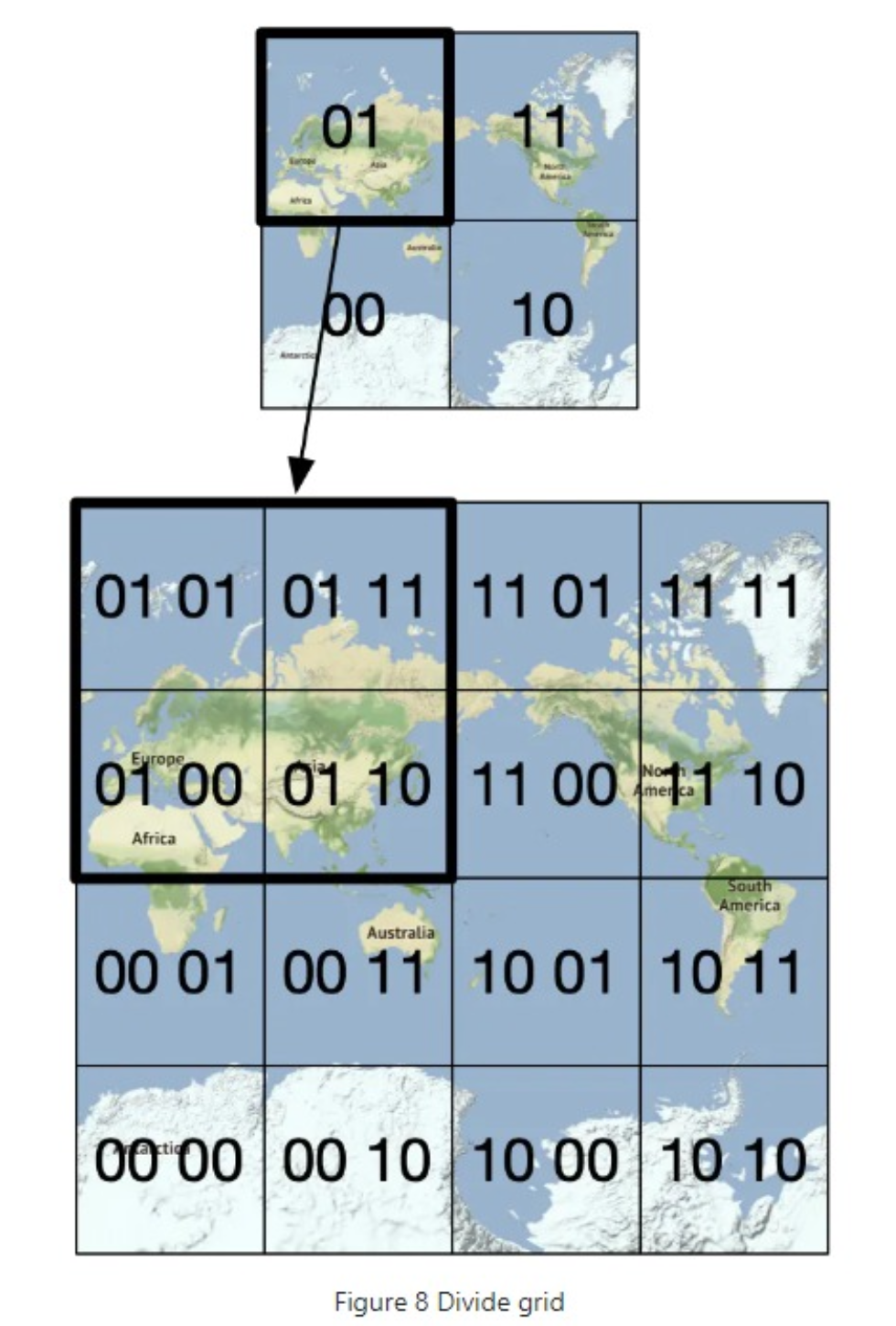
Geohash 通过递归二分法对经度、纬度交错编码,然后映射为 Base32 字符串:
- 经度范围:
[-180, 180],纬度范围:[-90, 90] - 每次将经度和纬度各二分一半,判断目标坐标落在哪个半区,转为 0 或 1
- 按照“经度一位、纬度一位”交错排列成一个二进制串
- 每 5 位转为一个 Base32 字符
例子:
坐标:(39.92324, 116.3906) |
结构特性1: 越长的 Geohash,表示的区域越小,精度越高:
| 长度 | 精度范围(约) |
|---|---|
| 5 | ~4.9km × 4.9km |
| 7 | ~153m × 153m |
| 9 | ~5m × 5m |
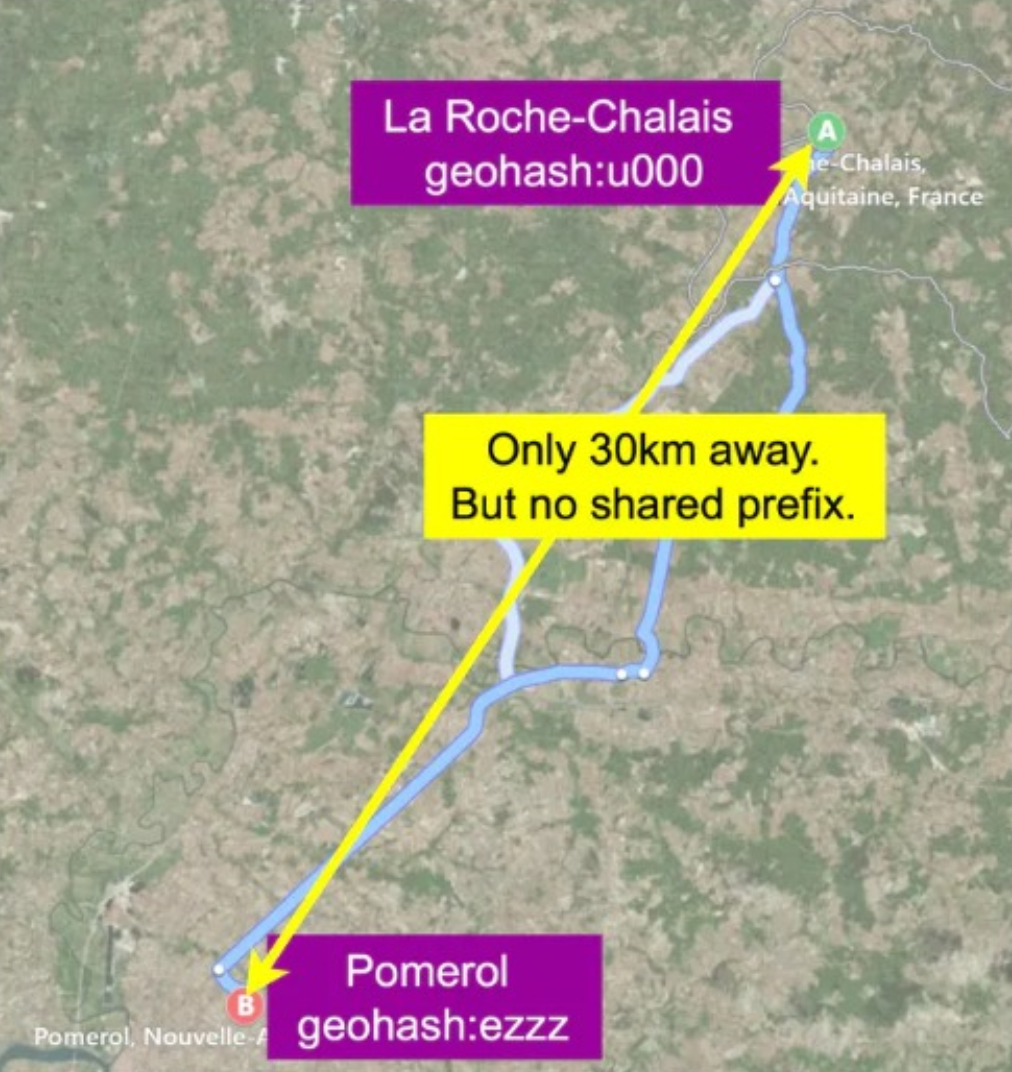
结构特性2: 同一前缀代表相近区域(前缀匹配):
wx4g0ec1和wx4g0ec2表示两个相邻的 5 米小区域- 可以用字符串前缀过滤“附近”点
优点:
- 可索引、可排序:字符串可用于数据库中的 B+ 树索引
- 易于分片与聚合:可按前缀聚合或分片(如 Redis、Elasticsearch、HBase)
- 支持模糊匹配:查找前缀为
wx4g0的所有位置即可获取某区域内所有点
缺点:
- 边界问题:邻近两个位置可能 Geohash 不连续(如正好在两个格子边界)
- two positions can have a long shared prefix, but they belong to different geohashes
- 形状问题:编码区域是矩形,与圆形范围查询不完全重合
- 赤道和极地精度不一致:因为经度划分间隔在纬度变化时变形
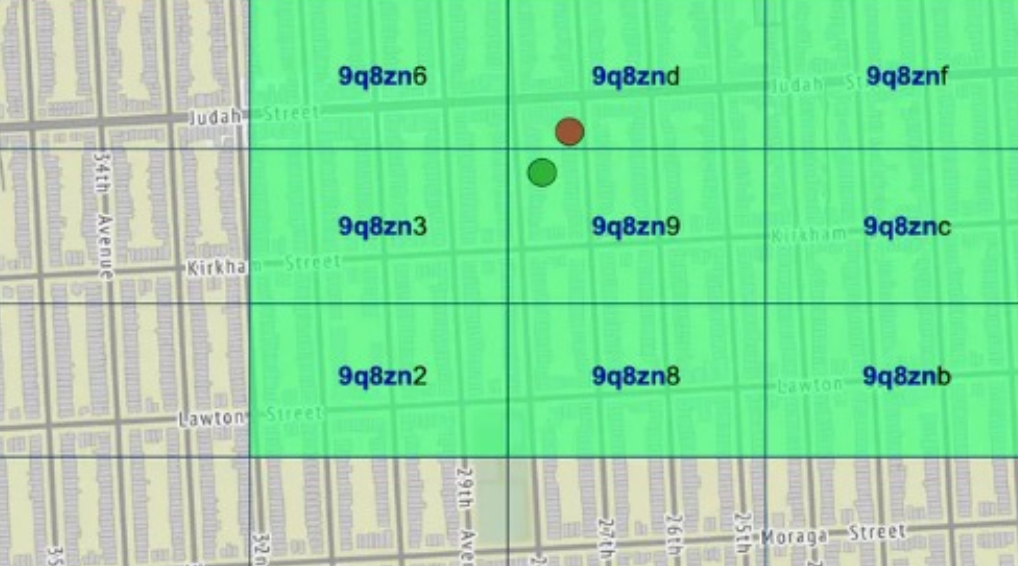
缺点解决方案: 扩展邻居格子,联合查询
每个 Geohash 区块最多有 8 个邻居(上下左右 + 对角线):
[NW] [ N ] [NE] |
步骤:
- 查询时,先找到目标坐标的 Geohash 编码(如
wx4g0ec1) - 再查询它的 8 个相邻格子(如
wx4g0ec0,wx4g0ec2,wx4g0ebz等) - 将这些格子内的点一并查出
- 最后使用精确距离计算(如 Haversine)过滤真实的“附近”结果
应用场景:
- 附近搜索(如“3km 内找司机”)配合邻近 Geohash 块 + 精确距离过滤
- 数据分片:根据 Geohash 前缀分 Redis key、数据库表
- 空间聚合:按 Geohash 分组聚合位置热力数据
- 轨迹压缩:把轨迹坐标点压缩成 Geohash 序列,节省存储
Quadtree
四叉树(Quadtree)是一种针对二维空间的递归划分树结构,广泛用于地理信息系统(GIS)、游戏地图、图像压缩和空间索引等场景。它的核心是将每个区域分成四个子区域,实现高效定位与空间查询。
Another popular solution is a quadtree. A quadtree is a data structure that is commonly used to partition a two - dimensional space by recursively subdividing it into four quadrants (grids) until the contents of the grids meet certain criteria.
Note that quadtree is an in-memory data structure and it is not a database solution. It runs on each LBS server, and the data structure is built at server startup time.
另一个流行的解决方案是一个四叉树。一个四叉树[18]是一种数据结构,通常用于通过递归地将二维空间细分为四个象限(网格),直到网格中的内容满足特定标准。
请注意,四叉树是一种内存数据结构,它不是一个数据库解决方案。它在每个基于位置的服务(LBS)服务器上运行,并且数据结构是在服务器启动时构建的。
每个节点代表一个矩形区域,包含最多 4 个子节点,
每个子区域继续细分为 NW、NE、SW、SE 四部分,直到满足某种终止条件(如点数少于阈值或区域最小尺寸).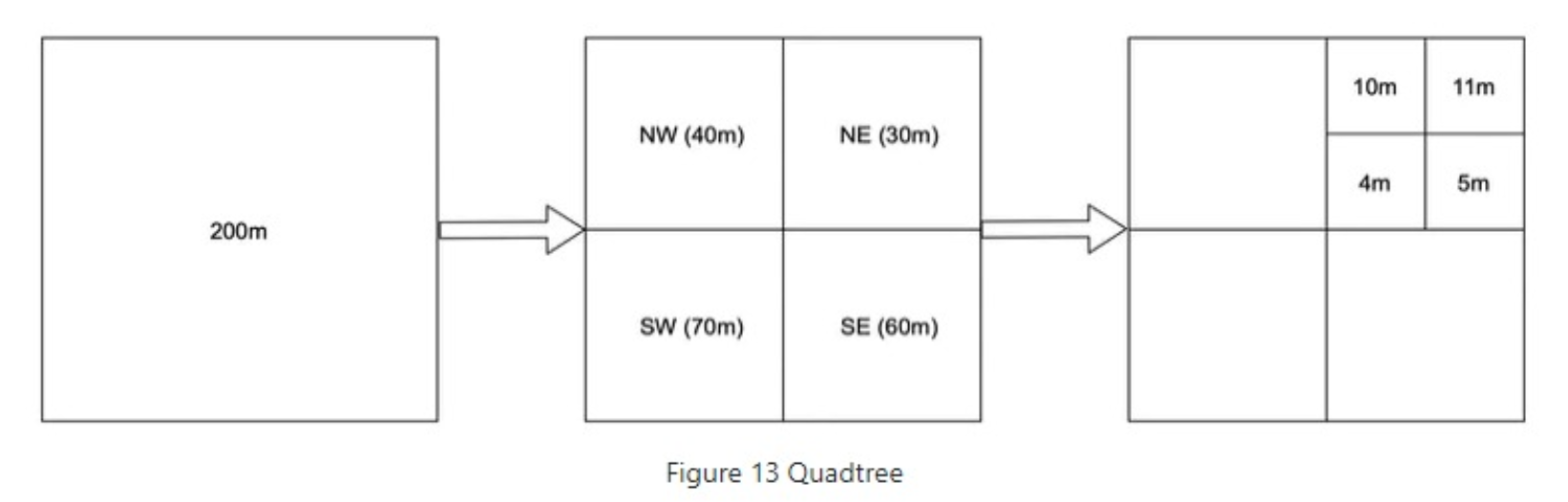
The Figure below explains the quadtree building process in more detail. The root node represents the whole world map. The root node is recursively broken down into 4 quadrants until no nodes are left with more than 100 businesses.”
下面的图更详细地解释了四叉树的构建过程。根节点代表整个世界地图。根节点被递归地分解为四个象限,直到不存在包含超过100家企业的节点为止。
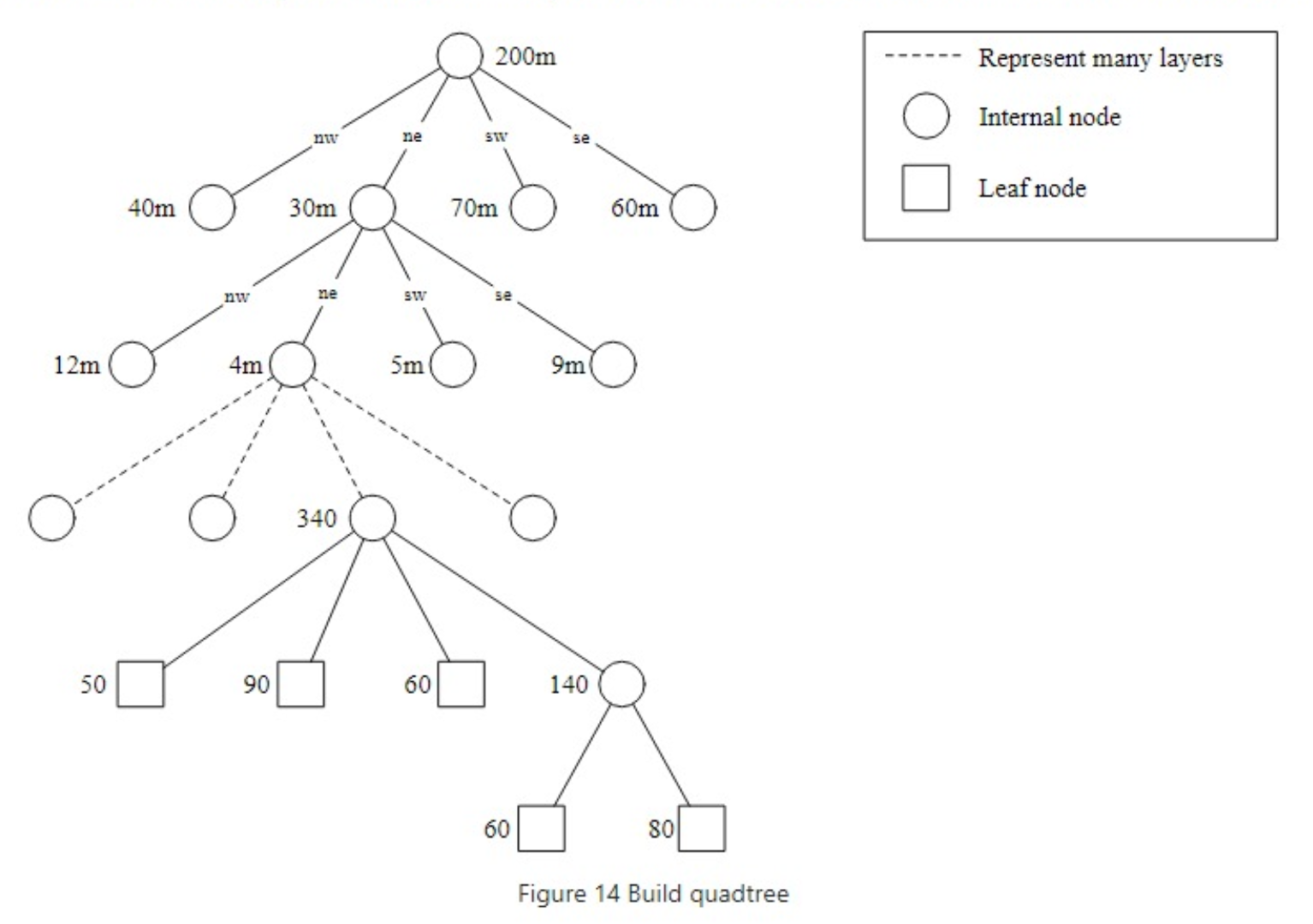
How to get businesses with quadtree?
- Build the quadtree in memory.
- After the quadtree is built, start searching from the root and traverse the tree, until we find the leaf node where the search origin is. If that leaf node has 100 businesses, return the node. Otherwise, add businesses from its neighbors until enough businesses are returned.
Real-world quadtree example: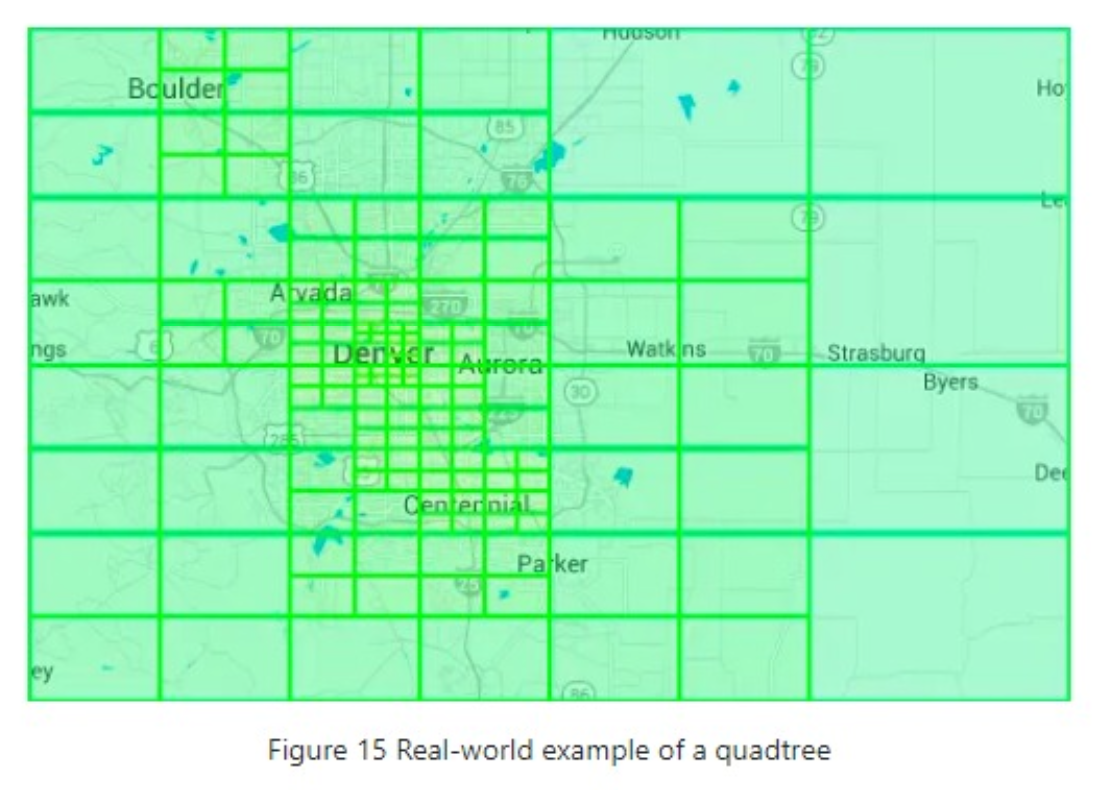
为何查找快(原理)? 空间查询(如查找某点附近的点)时,只访问与查询区域相交的节点:
- 不需要遍历所有数据点(不像线性搜索)
- 每层缩小 1/2 空间,平均查询复杂度接近 O(log N)
- 类似于“二分查找 + 空间定位”的结合体
例如:
- 你要找 1km 内的司机,只需要遍历与该范围相交的几个子节点
- 大部分与该区域无交集的节点会被“剪枝”,不会遍历
适用场景(尤其适合 Uber/LBS):
| 场景 | 作用 |
|---|---|
| 附近资源查找 | 查找附近车辆、充电桩、订单等,效率远高于全表扫描 |
| 空间索引 | 构建内存中位置索引树,支持动态更新和快速匹配 |
| 空间负载分片 | 用于按地理位置将数据分布到不同服务器或服务节点 |
| 热区识别与聚合 | 高密度区域可自动加深层级,便于精细化控制与调度 |
Geohash对比Quadtree
| 特性 | Geohash | Quadtree |
|---|---|---|
| 面试讲解难度 | 简单, 推荐 | 较难 |
| 存储形式 | 编码为字符串 | 树状结构(每节点四个子区) |
| 查询速度 | 快,适合范围模糊匹配,边界需手动扩展 | 更快,适合精确空间搜索 |
| 插入/删除 | 直接更新编码,容易但不结构化 | 快速局部更新 |
| 空间结构 | 固定网格(Base32 分段) | 动态划分,不均匀适应密度 |
| 易部署性 | 简单,字符串易分布式部署 | 复杂,适合内存索引 |
Video transcoding
Directed acyclic graph(DAG) model
To support different video processing pipelines and maintain high parallelism, it is important to add some level of abstraction and let client programmers define what tasks to execute.
For example, Facebook’s streaming video engine uses a directed acyclic graph (DAG) programming model, which defines tasks in stages so they can be executed sequentially or parallelly [8].
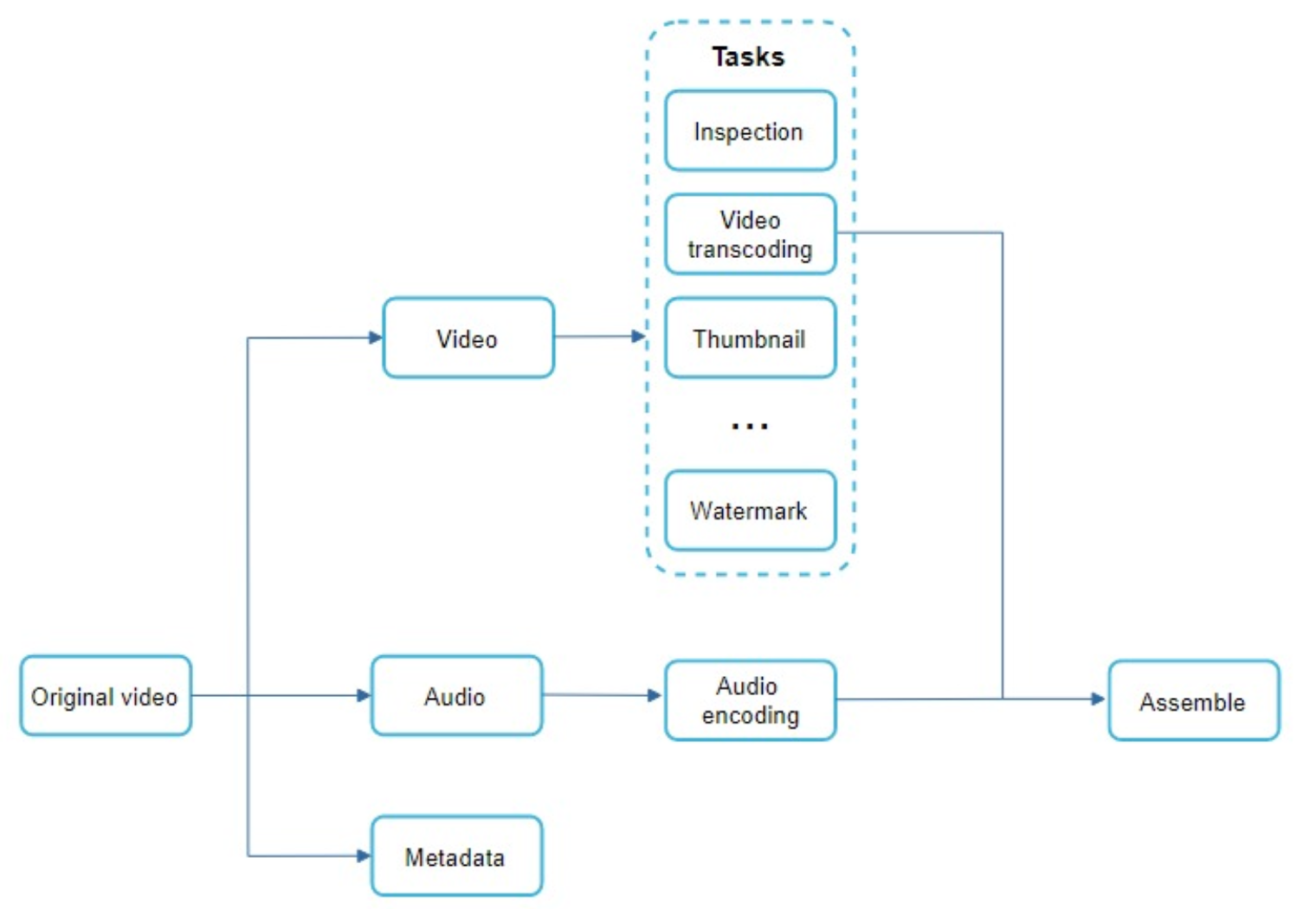
video encodings:
Video transcoding architecture: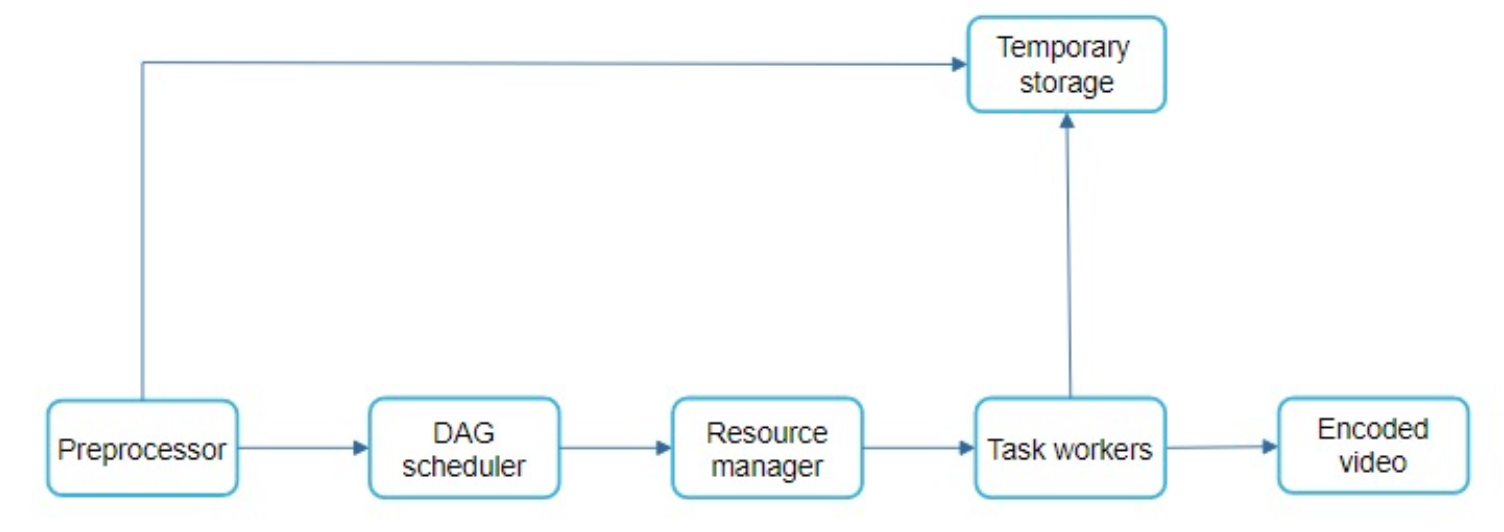
The DAG scheduler: splits a DAG graph into stages of tasks and puts them in the task queue in the resource manager.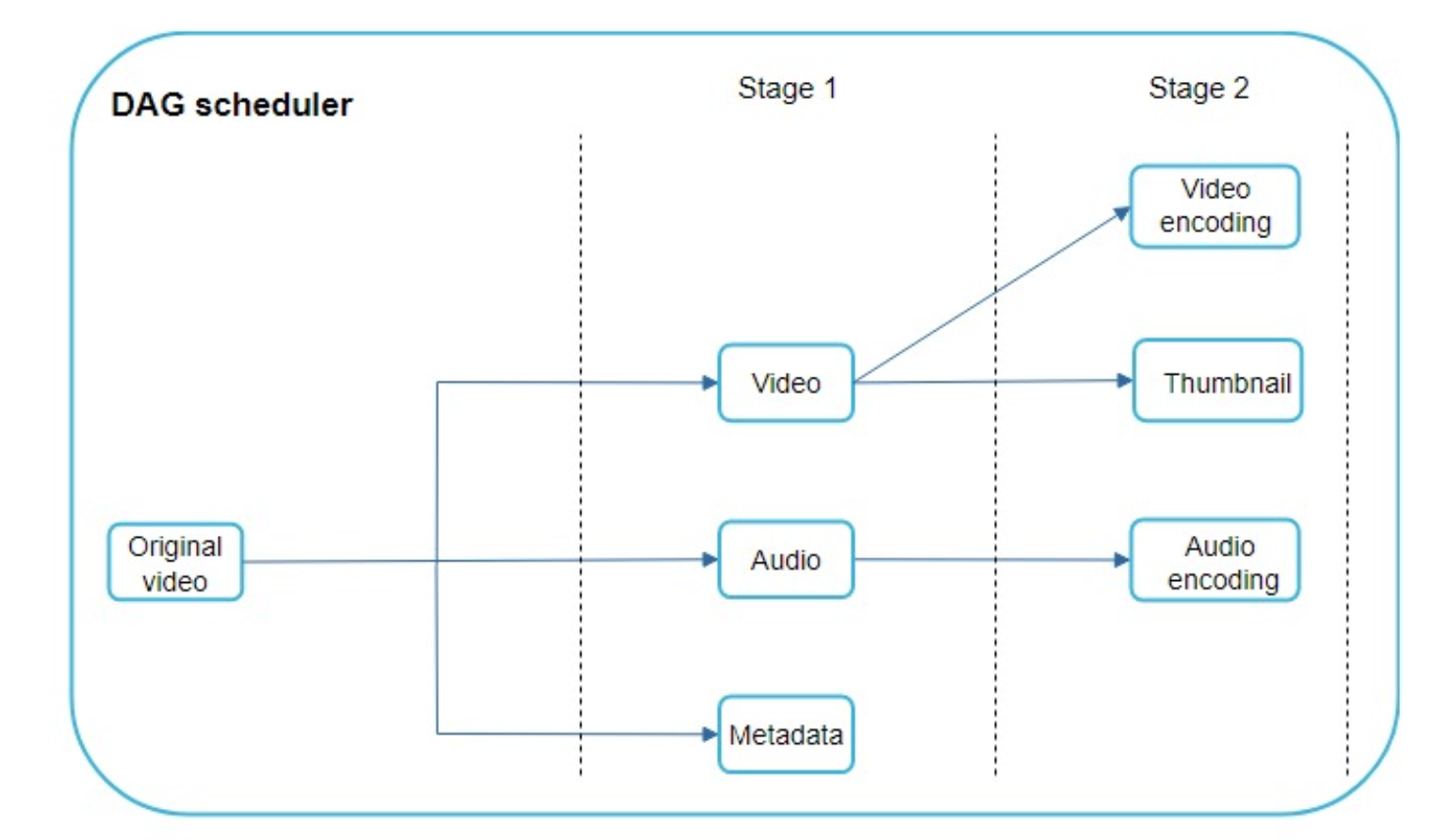
resource manager: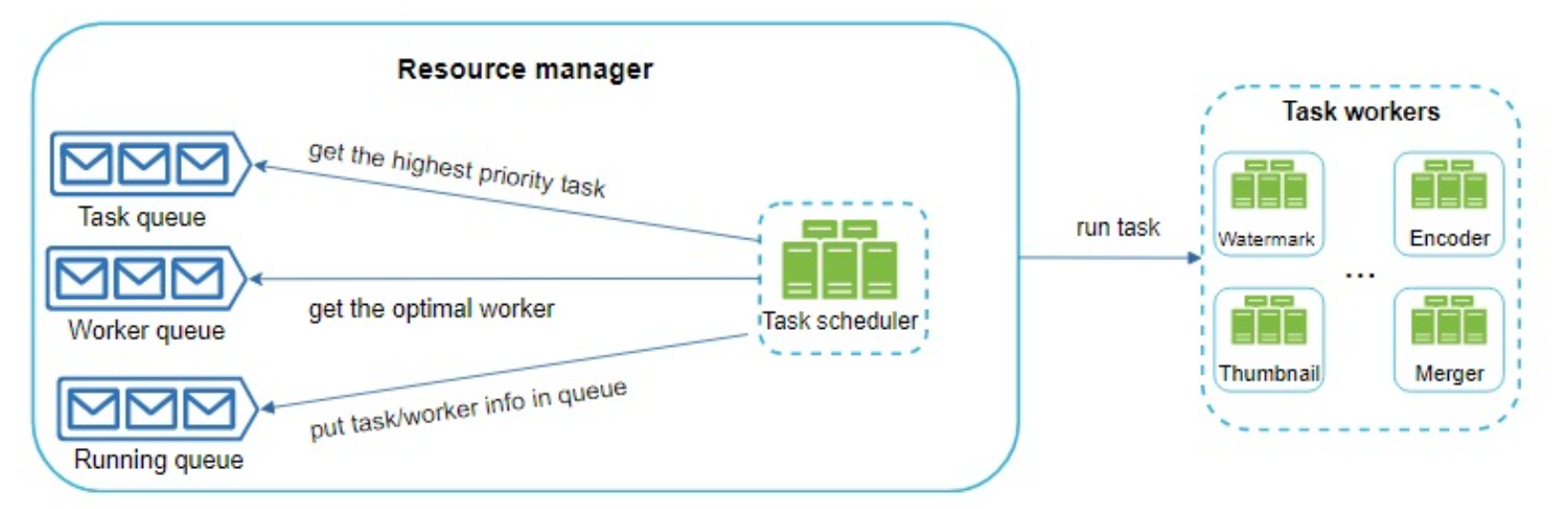
optimizations
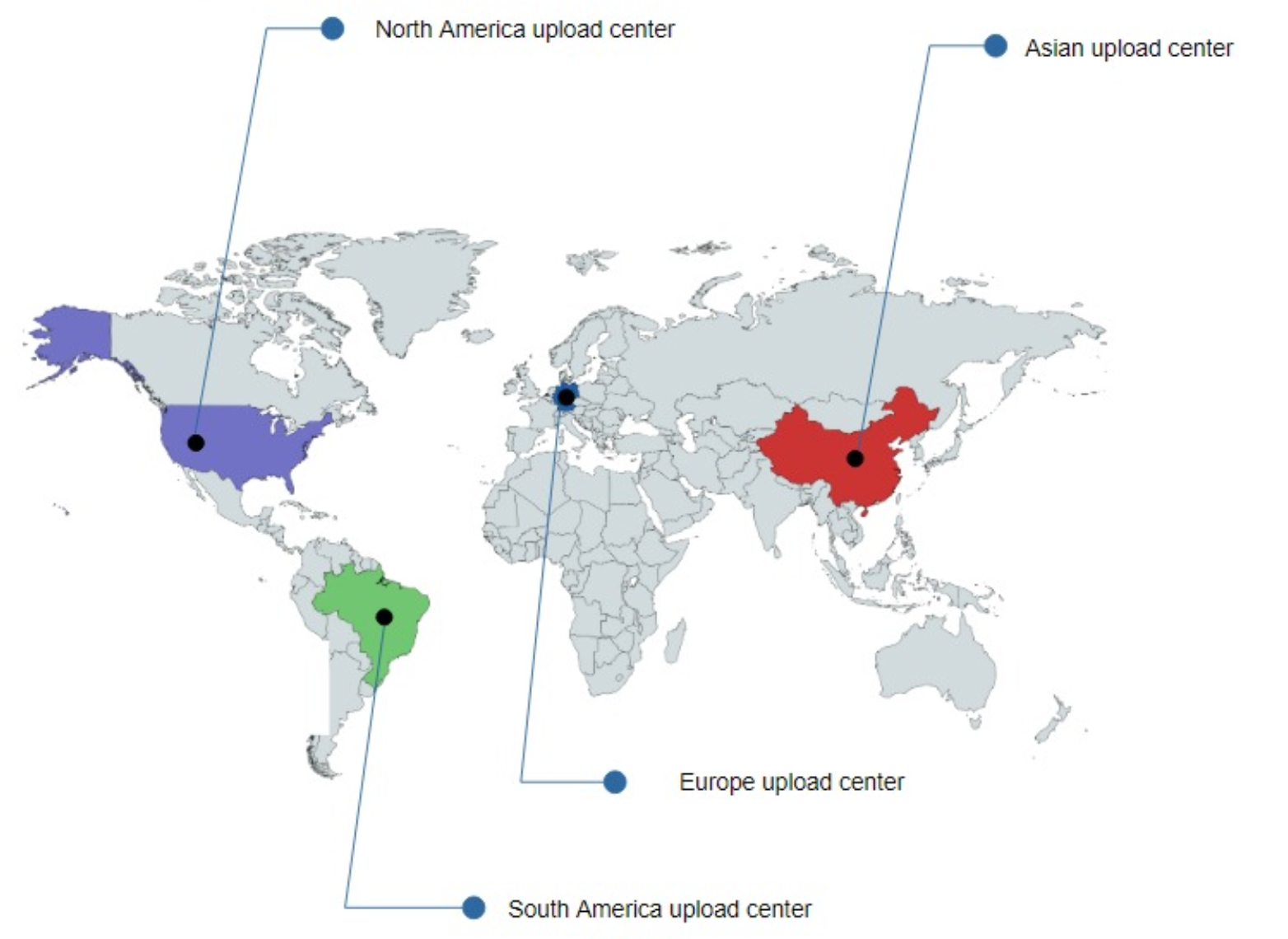
- parallelize video uploading:
- place upload centers close to users:
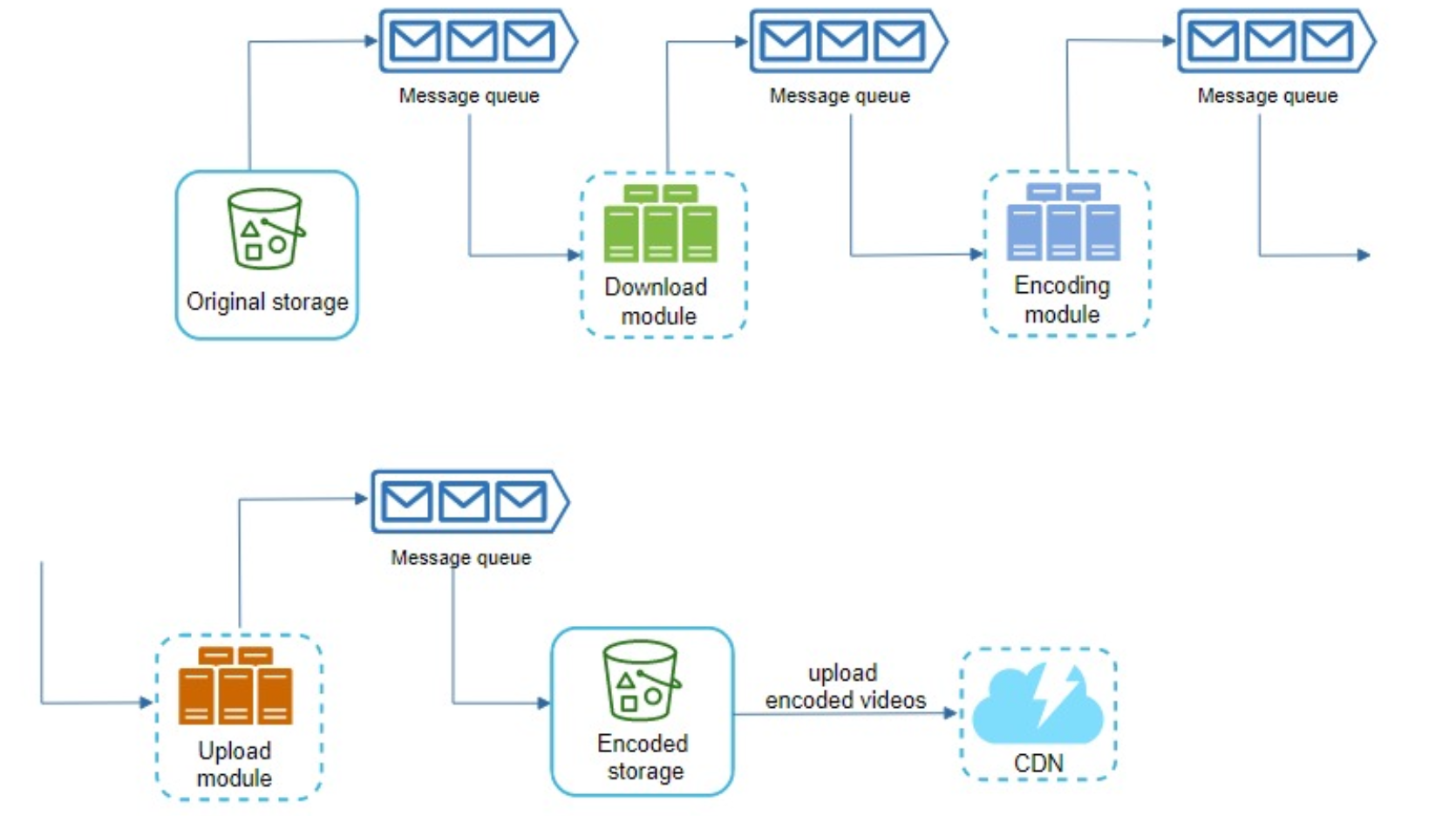
- After the message queue is introduced, the encoding module does not need to wait for the output of the download module anymore. lf there are events in the message queue, the encoding module can execute those jobs in parallel:
pre-signedupload URL:- The client makes a HTTP request to APl servers to fetch the pre-signed URL, which gives the access permission to the object identified in the URl. The term pre-signed URL is used by uploading files to Amazon s3.
- Once the client gets the response, it uploads the vid using the
pre-signed URL 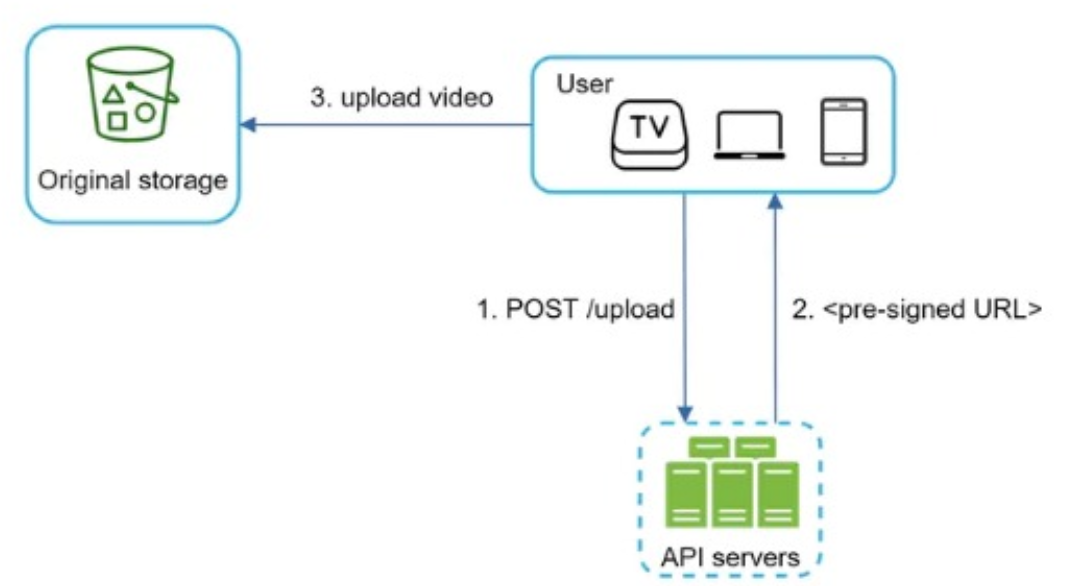

Payment flow
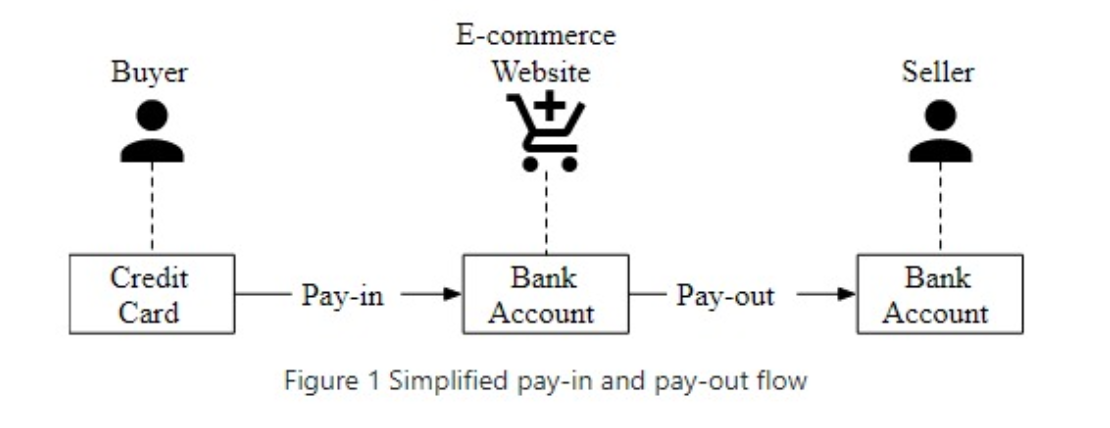
Pay-in flow: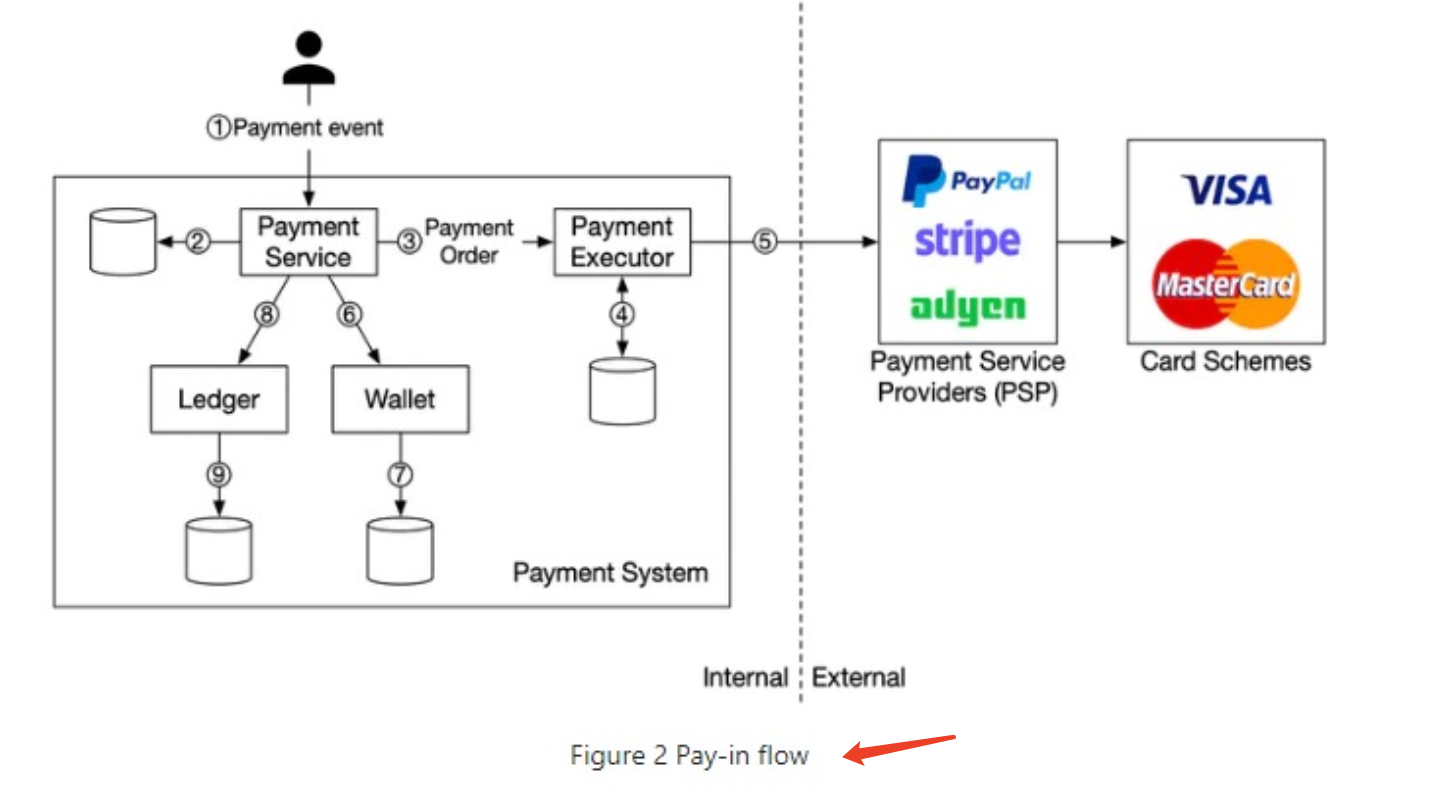
Payment Service Provider(PSP), PSP integration: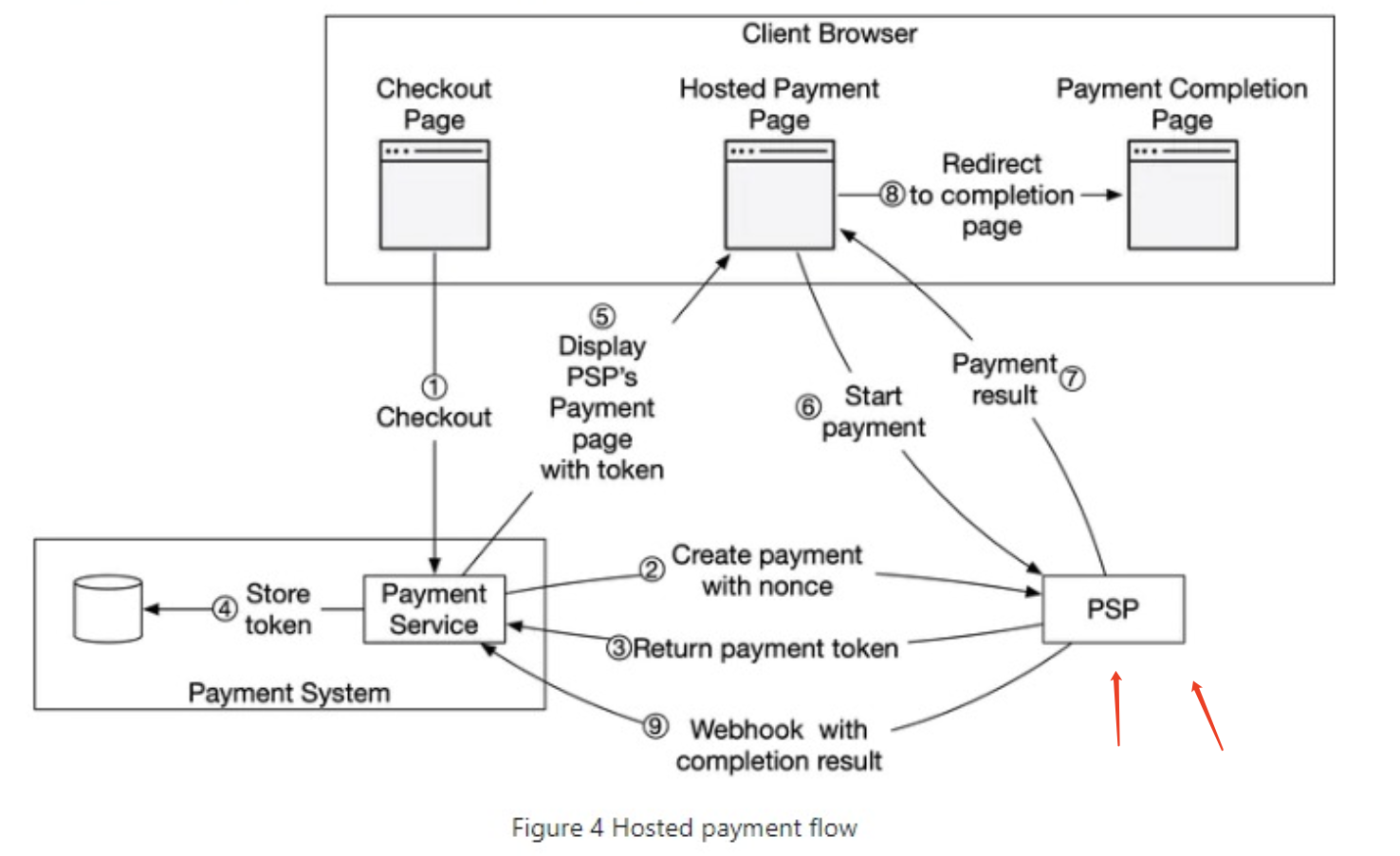
Reconciliation(对账):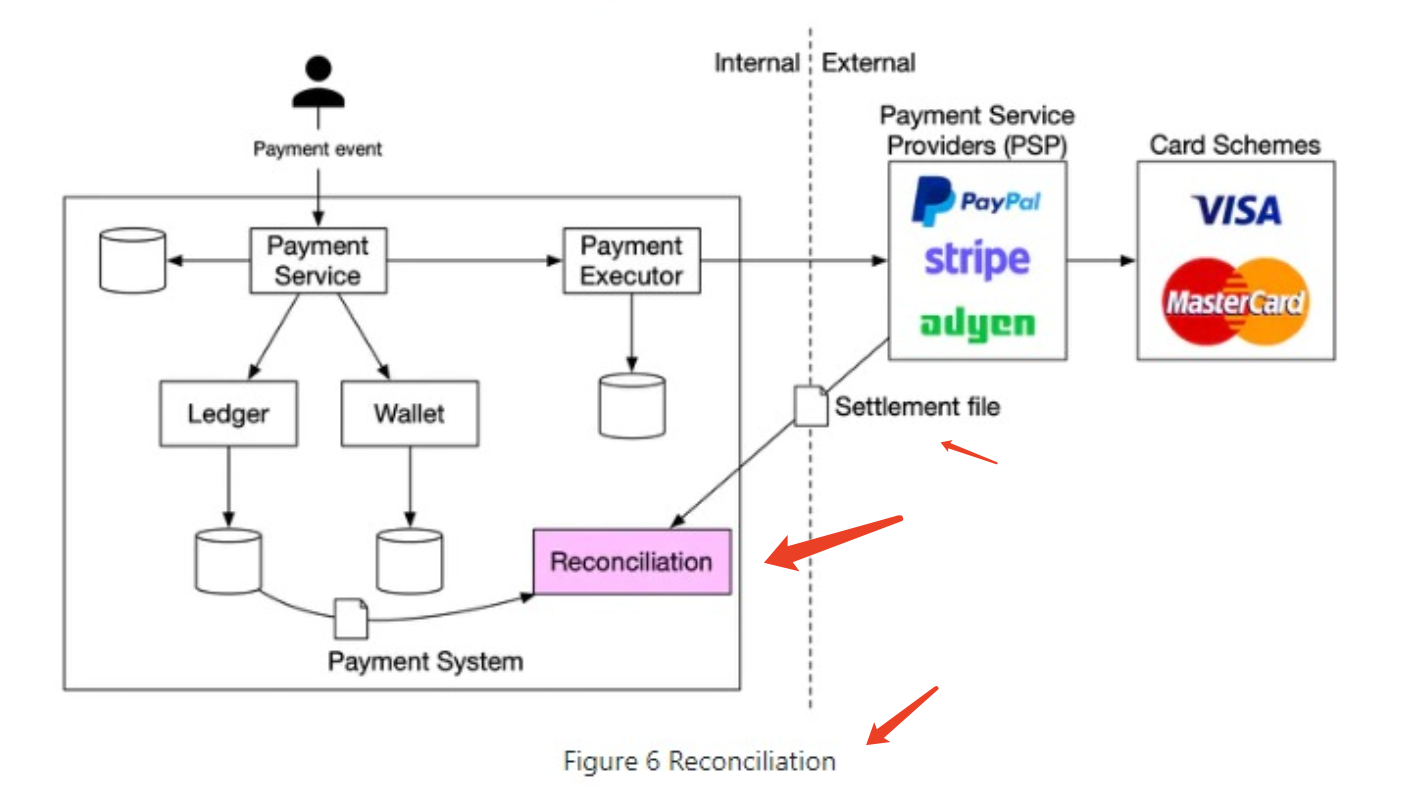
what if a customer clicks the “pay” button quickly twice?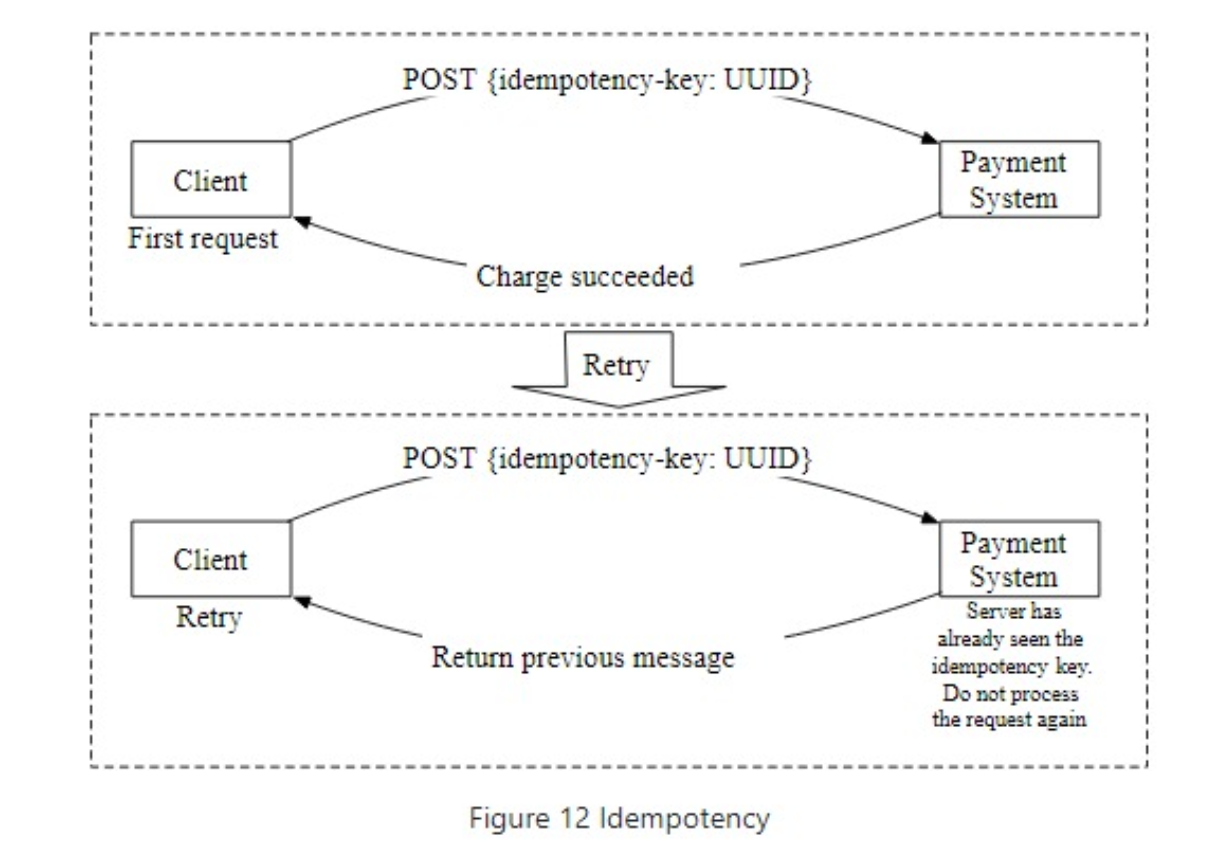
Distributed transaction - Saga
question: There is no guarantee that both updates would succeed.
If, for example, the wallet service node crashes after the first update has gone through but before the second update is done, it would result in an incomplete transfer, The two updates need to be in a single atomic transaction.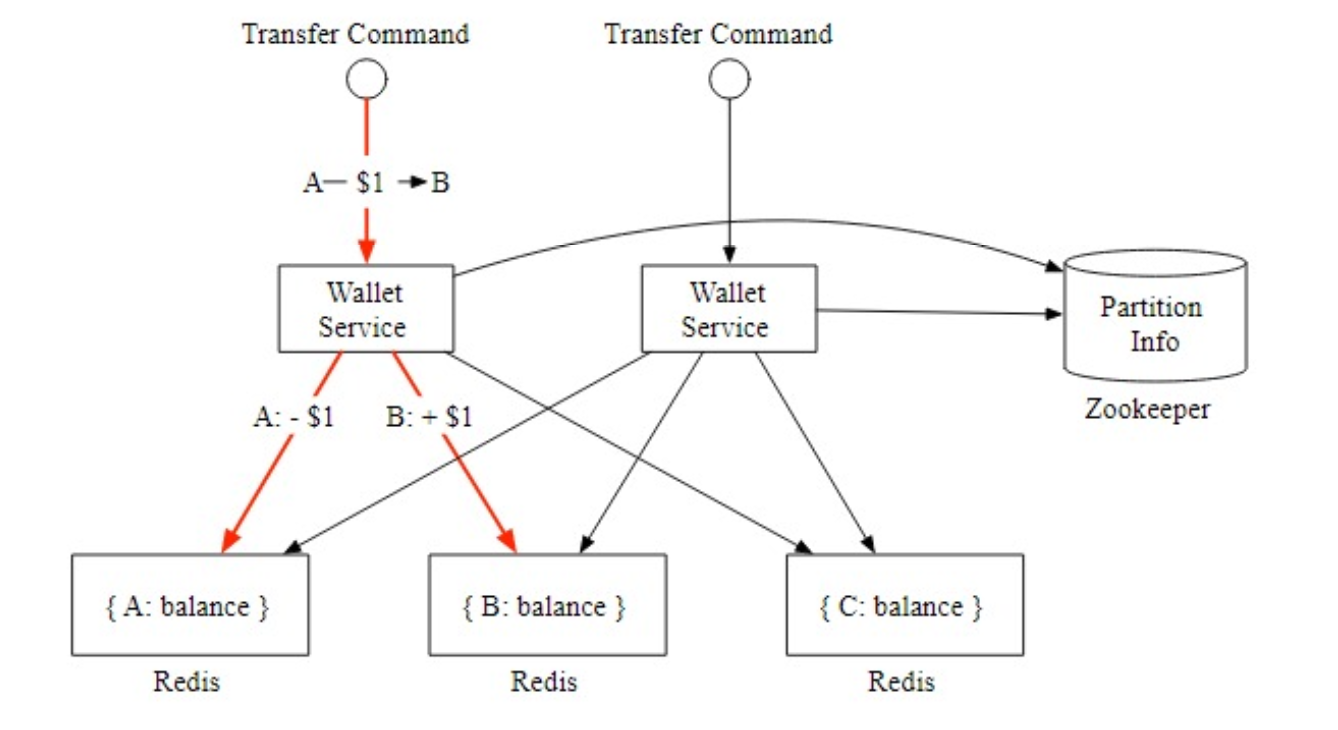
Solution: Saga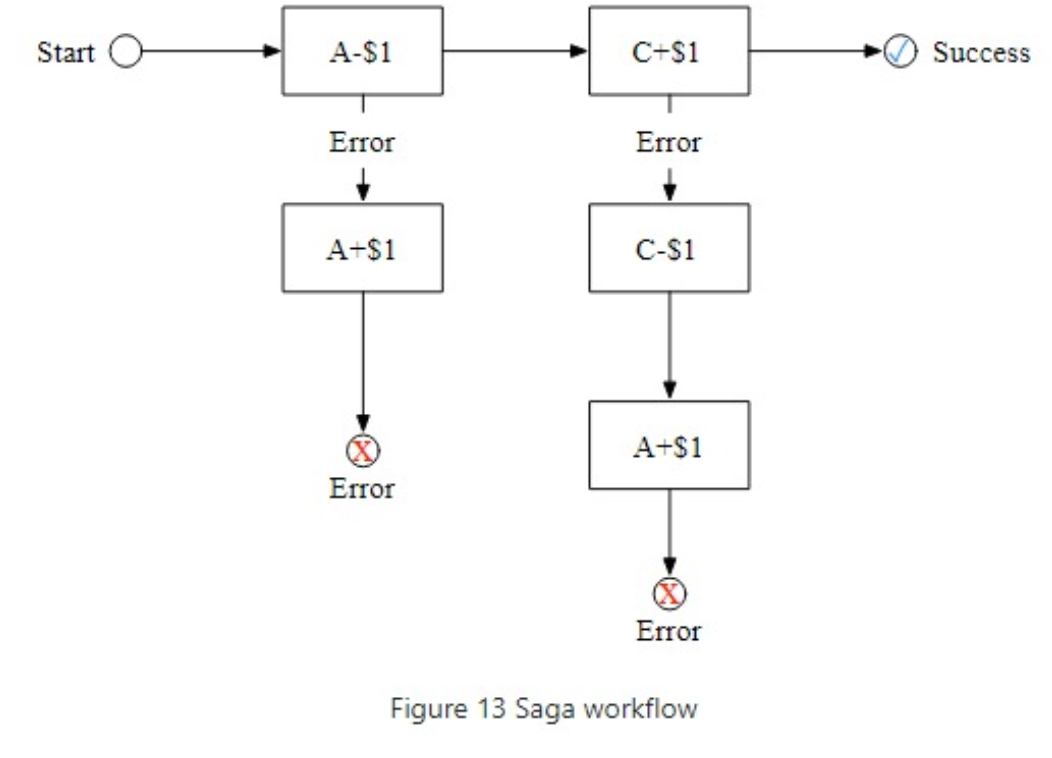
It is easier to understand this by using an example. the figure above shows the Saga workflow to transfer $1 from accountA to account C :
- The top horizontal line shows the normal order of execution.
- The two vertical lines show what the system should do when there is an error.
- When it encounters an error, the transfer operations are rolled back and the client receives an error message.
How do we coordinate the operations? There are two ways to do it:
- Choreography(
/ˌkɔːriˈɑːɡrəfi/, n. 编舞;舞蹈艺术;舞艺). in a microservice architecture, all the services involved in the Saga distributed transaction do their jobs by subscribing to other services’ events. So it is fully decentralized coordination.- It can become hard to manage when there are many services
- Orchestration(prefer). A single coordinator instructs all services to do their jobs in the correct order. the coordinator is indeed a potential single point of failure (SPOF), so how to solve it?
- a. Make the Coordinator Stateless + Persistent Log: Store all Saga state transitions in a durable log (e.g., relational DB, Kafka, or a durable event store). If the coordinator crashes, a new instance can pick up from the log and resume. This makes the system crash-recoverable, even with a single coordinator.
- b. Leader Election + Replication: Run multiple instances of the coordinator. Use *leader election (e.g., via
ZooKeeper,etcd) to ensure only one acts at a time. Replicate Saga state to followers to enable fast failover.
Design a notification System
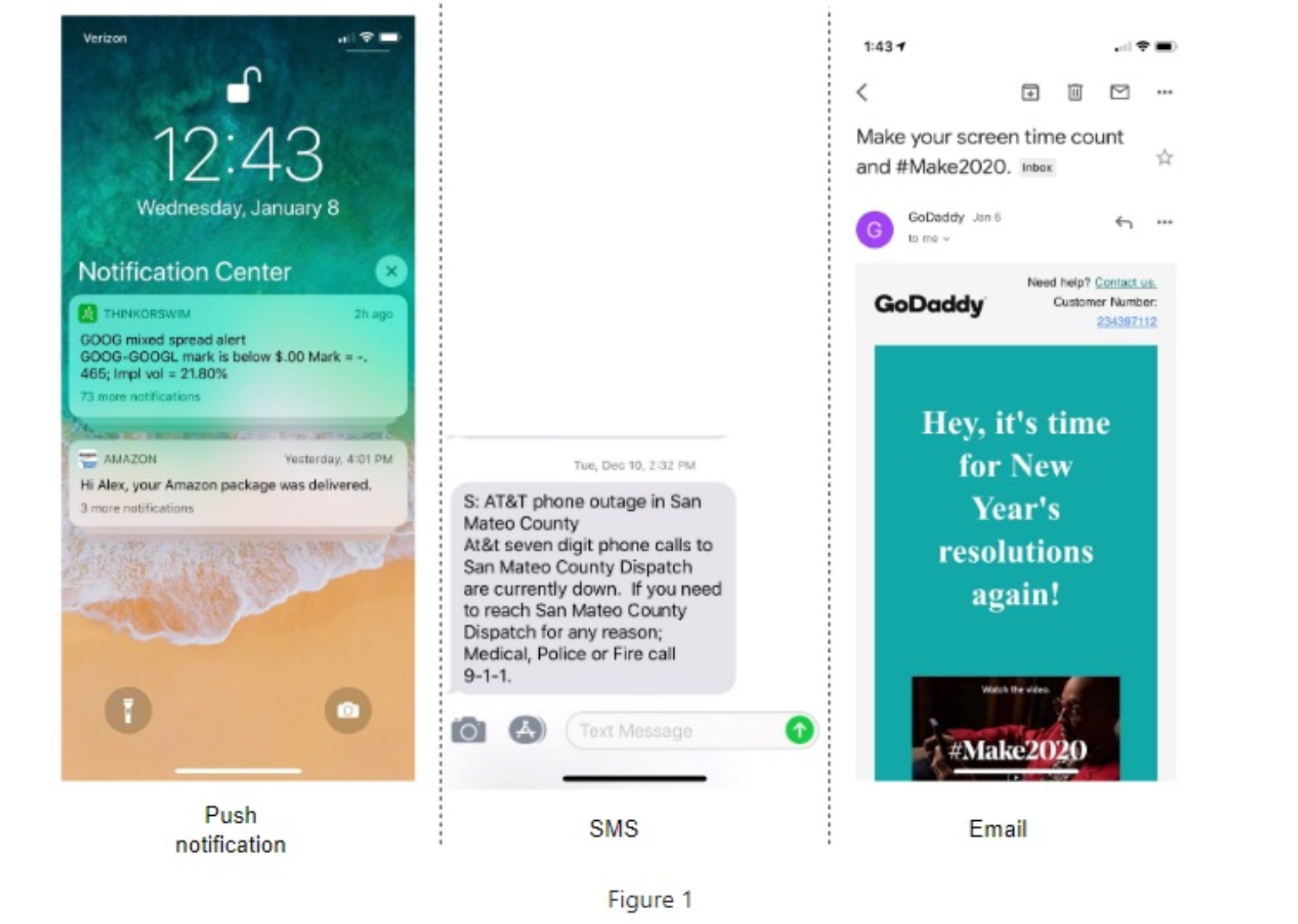
3 types of notification formats are:
- mobile push notification
- SMS message
step1-Understand the problem and establish design scope
- Candidate: What types of notifications does the system support?
- Interviewer: Push notification, SMS message, and email.
- Candidate: Is it a real-time system?
- Interviewer: Let us say it is a soft real-time system. We want a user to receive notifications as soon as possible. However, if the system is under a high workload, a slight delay is acceptable.
- Candidate: What are the supported devices?
- Interviewer: iOS devices, android devices, and laptop/desktop.
- Candidate: What triggers notifications?
- Interviewer: Notifications can be triggered by client applications. They can also be scheduled on the server-side.
- Candidate: Will users be able to opt-out(用户选择退出、不参与某个功能或服务) ?
- Interviewer: Yes, users who choose to opt-out will no longer receive notifications.
- Candidate: How many notifications are sent out each day?
- Interviewer: 10 million mobile push notifications, 1 million SMS messages, and 5 million emails.
step2-Propose high-level design and get buy-in
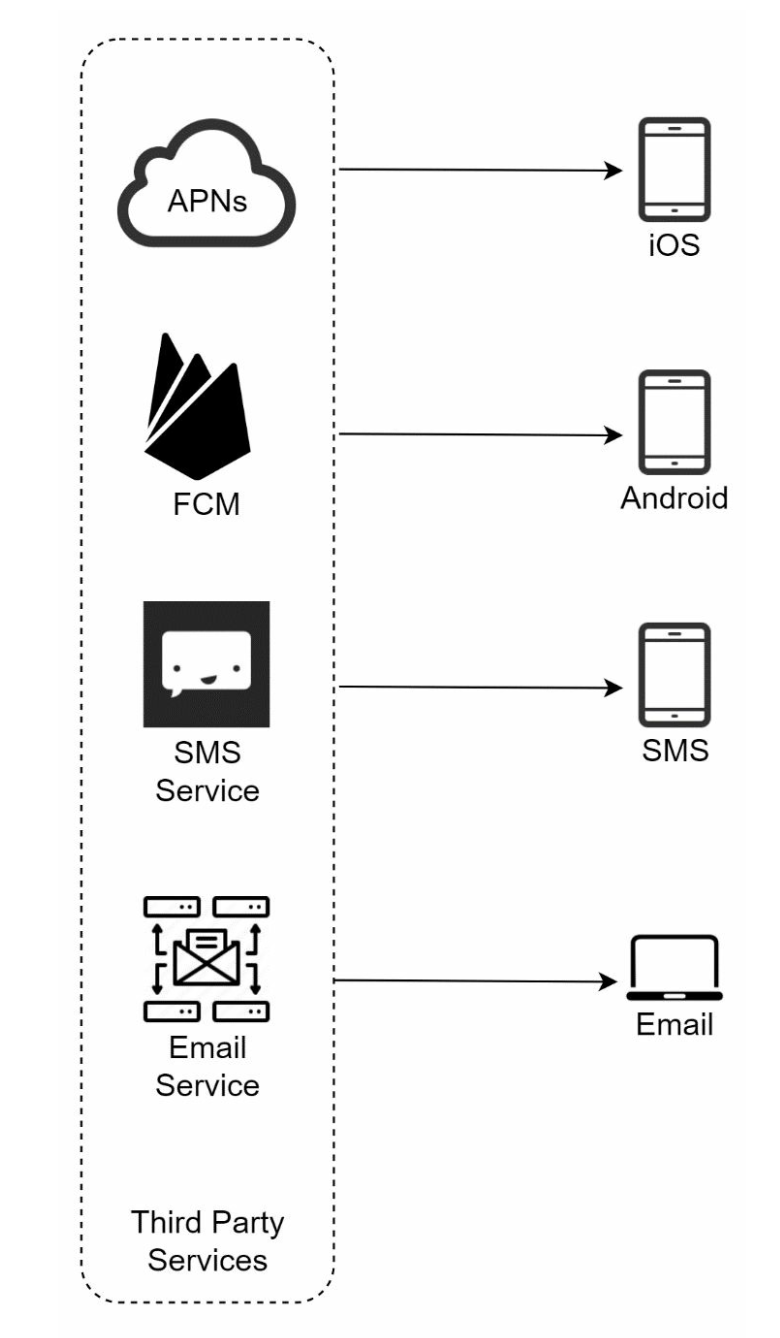
iOS push notification
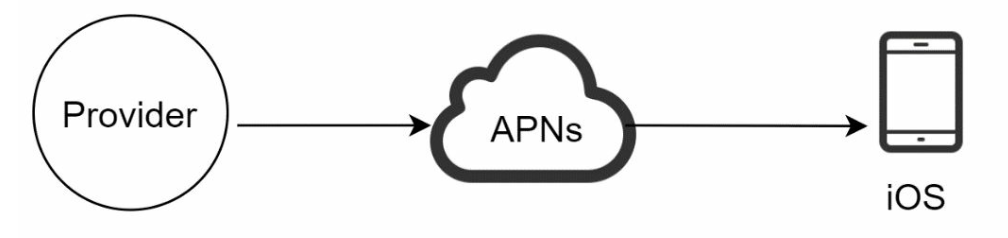
Provider. A provider builds and sends notification requests to Apple Push Notification Service (APNS). To construct a push notification, the provider provides the following data:
- • Device token: This is a unique identifier used for sending push notifications.
- • Payload: This is a JSON dictionary that contains a notification’s payload:
payload {
"aps": {
"alert": {
"title": "Game Request",
"body": "Bob wants to play chess",
"action-loc-key": "PLAY"
},
"badge": 5
}
}
APNS: This is a remote service provided by Apple to propagate push notifications to iOS devices.
- iOS Device: It is the end client, which receives push notifications.
Android push notification
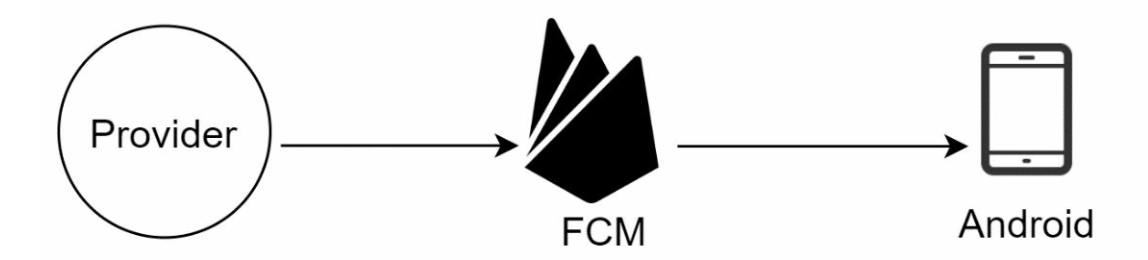
Instead of using APNs, Firebase Cloud Messaging (FCM) is commonly used to send push notifications to android devices.
SMS message
including all the third-party services
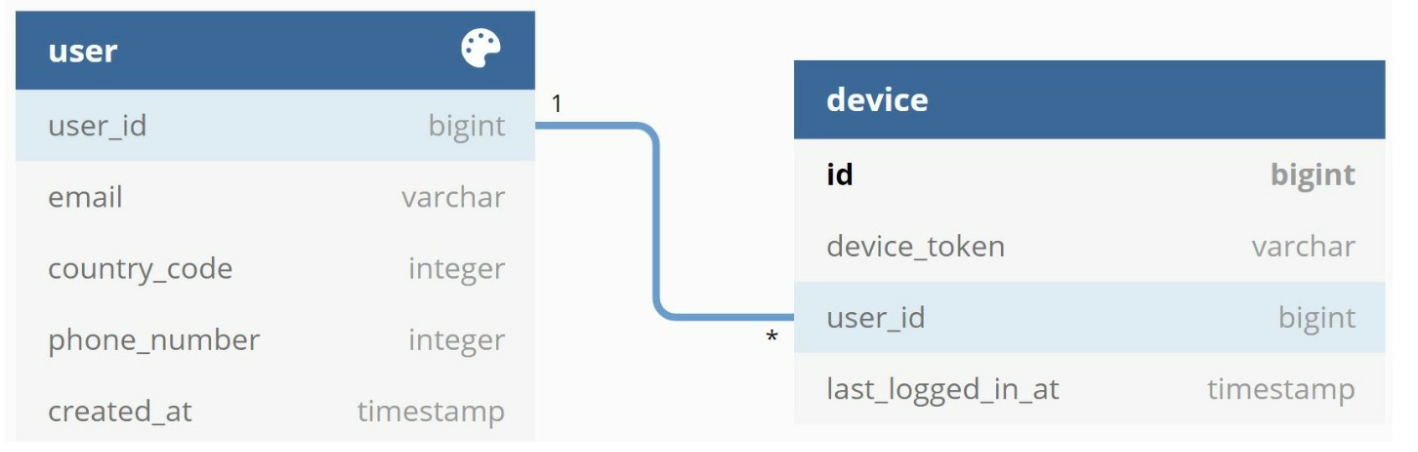
Contact info gathering flow
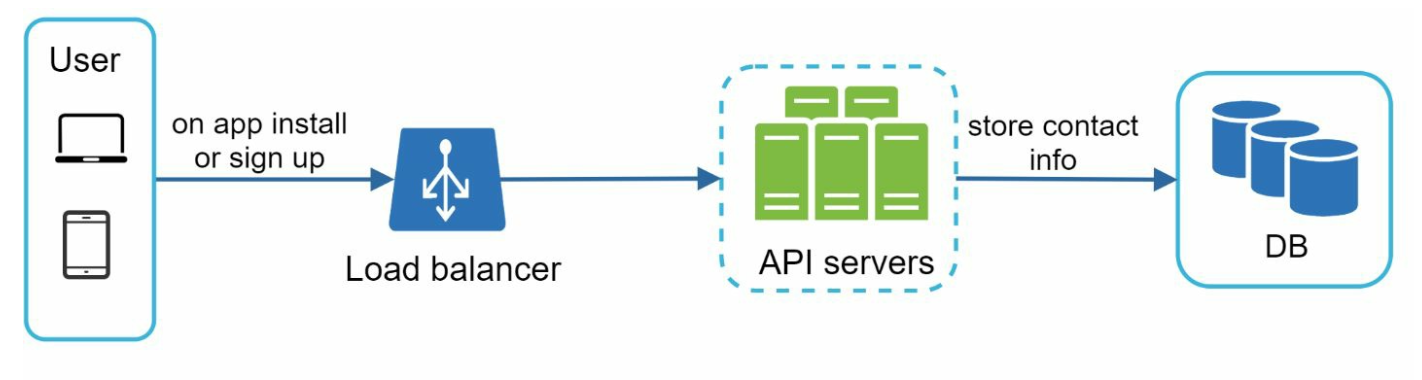
when a user installs our app or signs up for the first time,
API servers collect user contact info and store it in the database.
High-level design
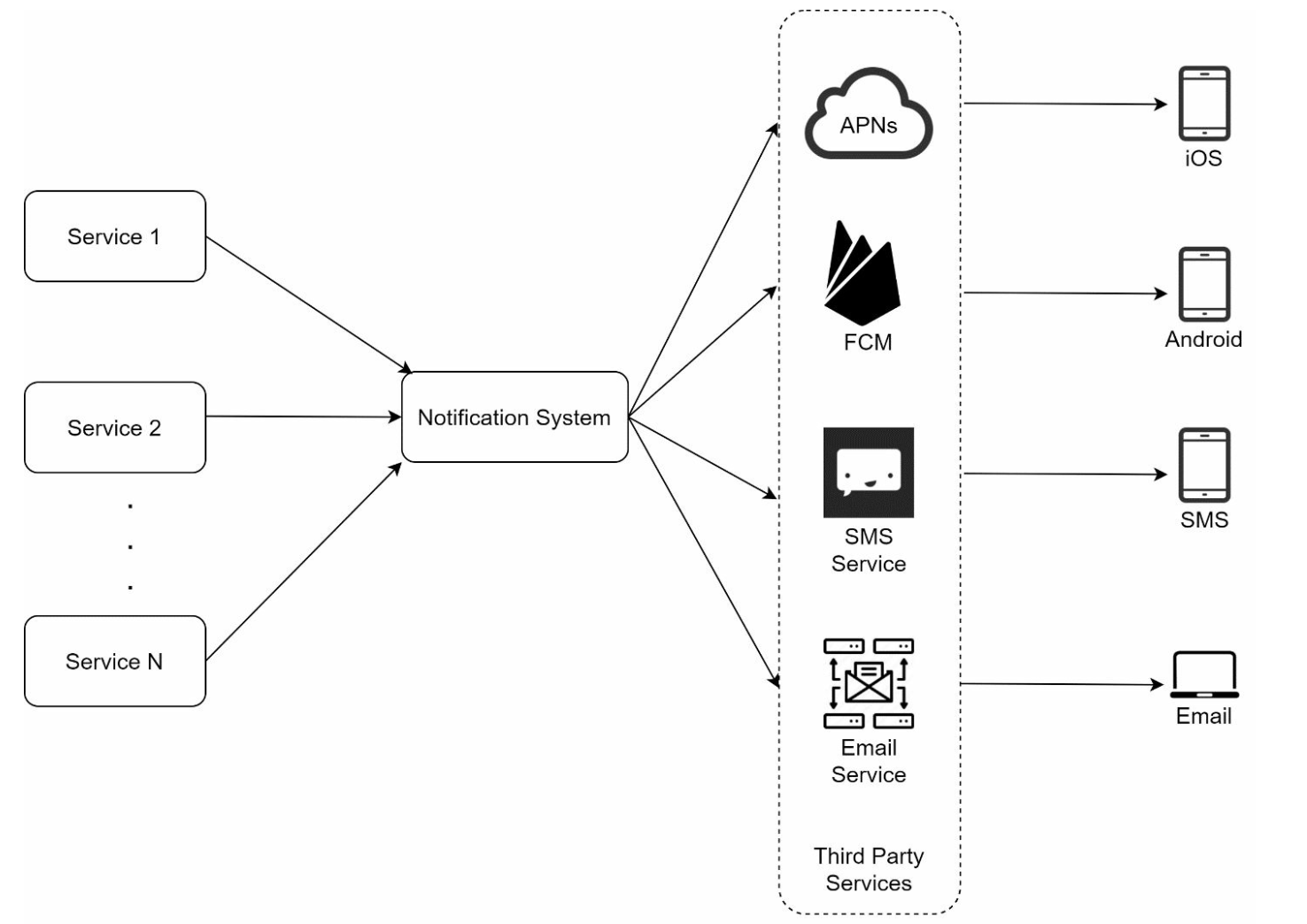
- Service 1 to N: A service can be a micro-service, a cron job, or a distributed system that triggers notification sending events.
- For example, a billing service sends emails to remind customers of their due payment or a shopping website tells customers that their packages will be delivered tomorrow via SMS messages.
- Notification system: The notification system is the centerpiece of sending/receiving notifications. Starting with something simple, only one notification server is used. It provides APIs for services 1 to N, and builds notification payloads for third party services.
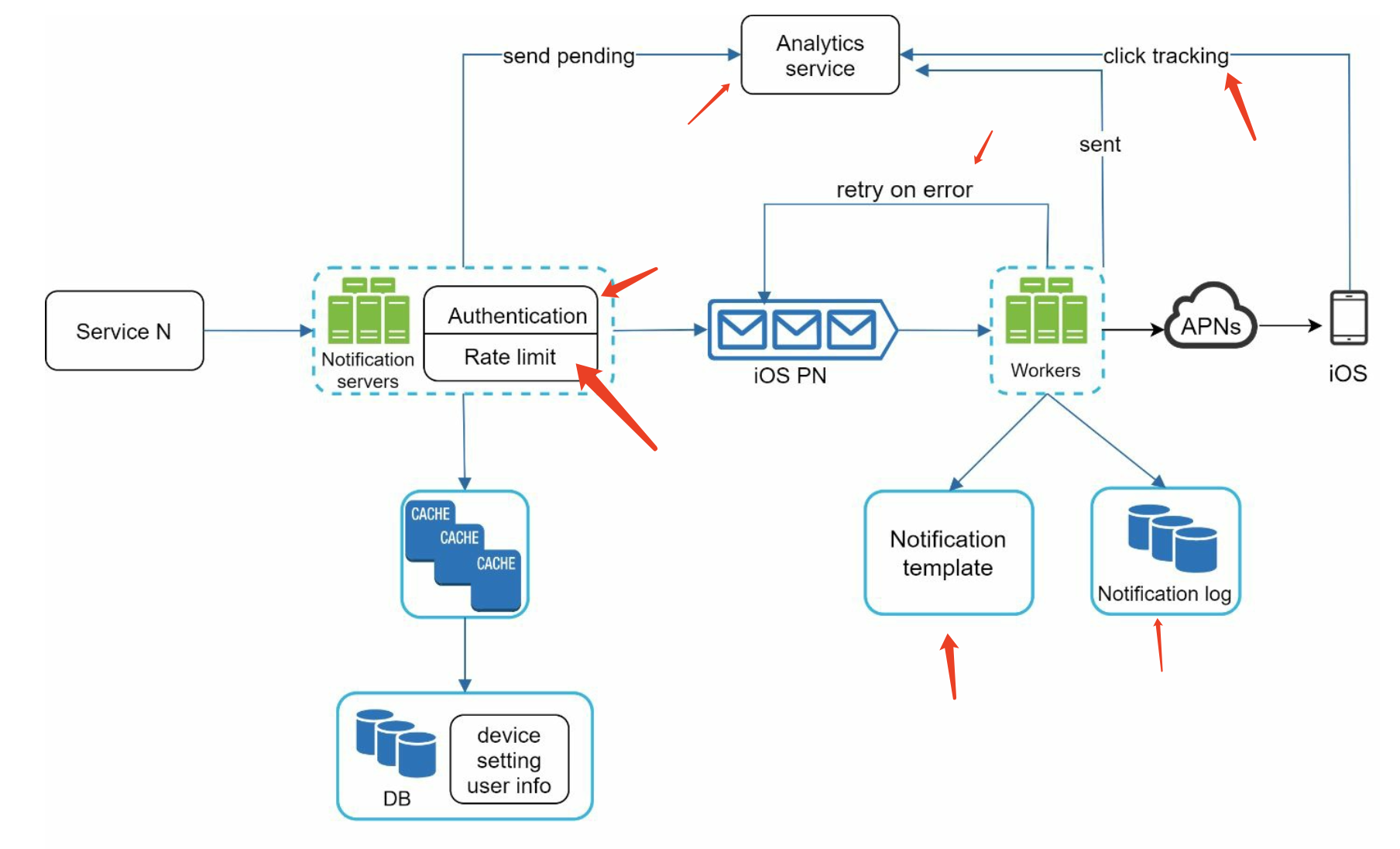
High-level design (improved)

we improve the design as listed below:
- • Move the database and cache out of the notification server.
- • Add more notification servers and set up automatic horizontal scaling.
- • Introduce message queues to decouple the system components.
New:
- Notification servers: They provide the following functionalities:
- • Provide APIs for services to send notifications. Those APIs are only accessible internally or by verified clients to prevent spams.
- • Carry out basic validations to verify emails, phone numbers, etc.
- • Query the database or cache to fetch data needed to render a notification.
- • Put notification data to message queues for parallel processing.
- Cache: User info, device info, notification templates are cached.
- DB: It stores data about user, notification, settings, etc.
- Message queues: They remove dependencies between components. Message queues serve as buffers when high volumes of notifications are to be sent out. Each notification type is assigned with a distinct message queue so an outage in one third-party service will not affect other notification types.
- Workers: Workers are a list of servers that pull notification events from message queues and send them to the corresponding third-party services.
step3-Design deep dive
How to prevent data loss?
To satisfy this requirement,
the notification system persists notification data in a database and implements a retry
mechanism. The notification log database is included for data persistence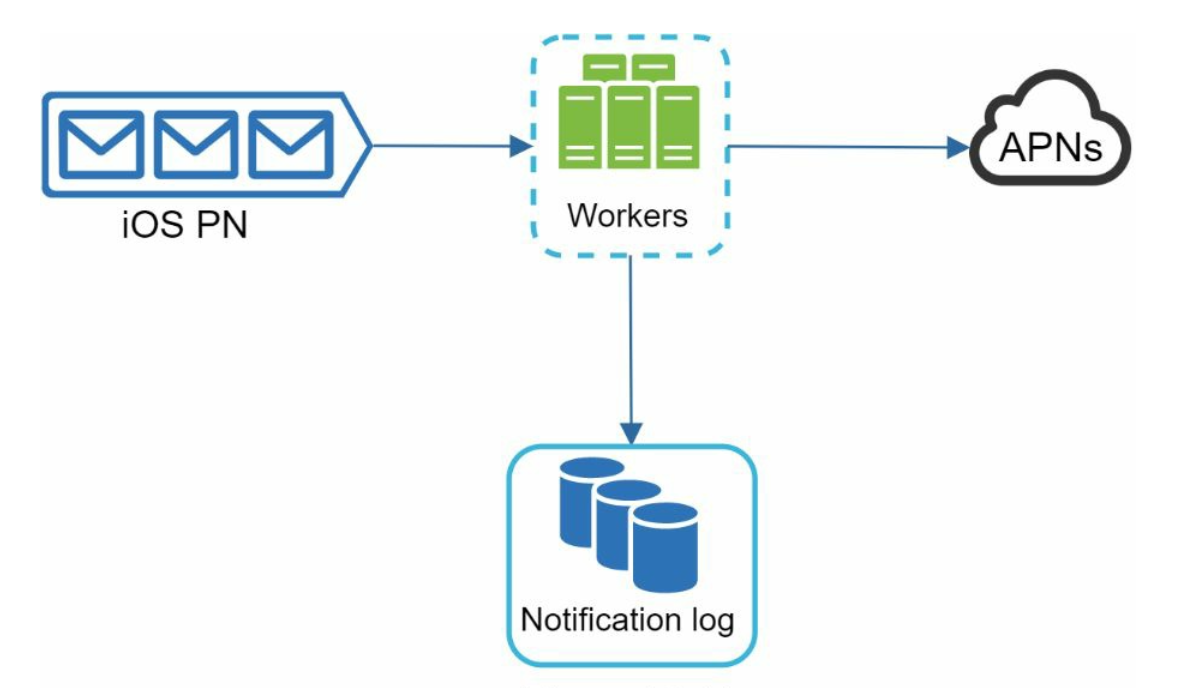
Will recipients receive a notification exactly once?
When a notification event first arrives, we check if it is seen before by checking the event ID.
If it is seen before, it is discarded. Otherwise, we will send out the notification.
Notification template
A large notification system sends out millions of notifications per day, and many of these
notifications follow a similar format. Notification templates are introduced to avoid building every notification from scratch.
A notification template is a preformatted notification to create your unique notification by customizing parameters, styling, tracking links, etc. Here is an example template of push notifications.
BODY: |
Notification setting
Before any notification is sent to a user, we first check if a user is opted-in to receive this type
of notification.
| 字段名 | 类型 | 描述 |
|---|---|---|
user_id |
bigInt |
用户唯一标识 |
channel |
varchar |
通知渠道,例如 push notification、email、SMS |
opt_in |
boolean |
用户是否同意接收该渠道的通知(是否选择接收) |
Rate limiting
To avoid overwhelming users with too many notifications, we can limit the number of
notifications a user can receive. This is important because receivers could turn off
notifications completely if we send too often.
Retry mechanism
When a third-party service fails to send a notification, the notification will be added to the
message queue for retrying. If the problem persists, an alert will be sent out to developers.
Security in push notifications
For iOS or Android apps, appKey and appSecret are used to secure push notification APIs. Only authenticated or verified clients are allowed to send push notifications using our APIs.
Monitor queued notifications
A key metric to monitor is the total number of queued notifications. If the number is large,
the notification events are not processed fast enough by workers. To avoid delay in the
notification delivery, more workers are needed.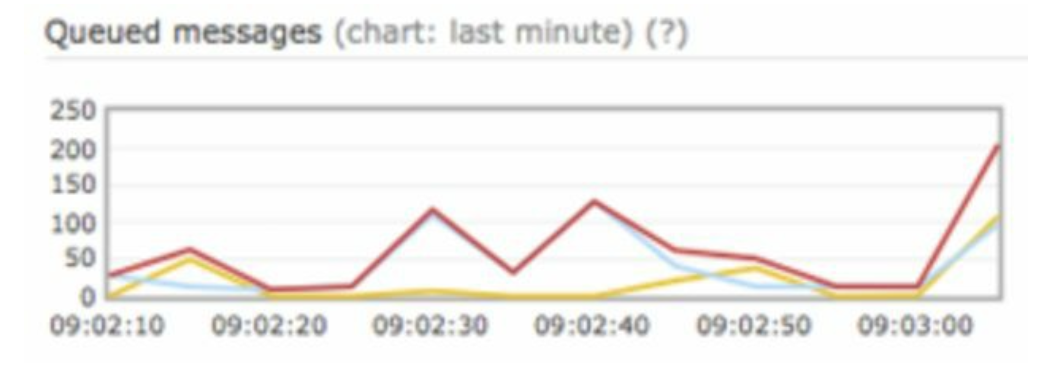
Events tracking
Notification metrics, such as open rate, click rate, and engagement are important in
understanding customer behaviors. Analytics service implements events tracking. Integration
between the notification system and the analytics service is usually required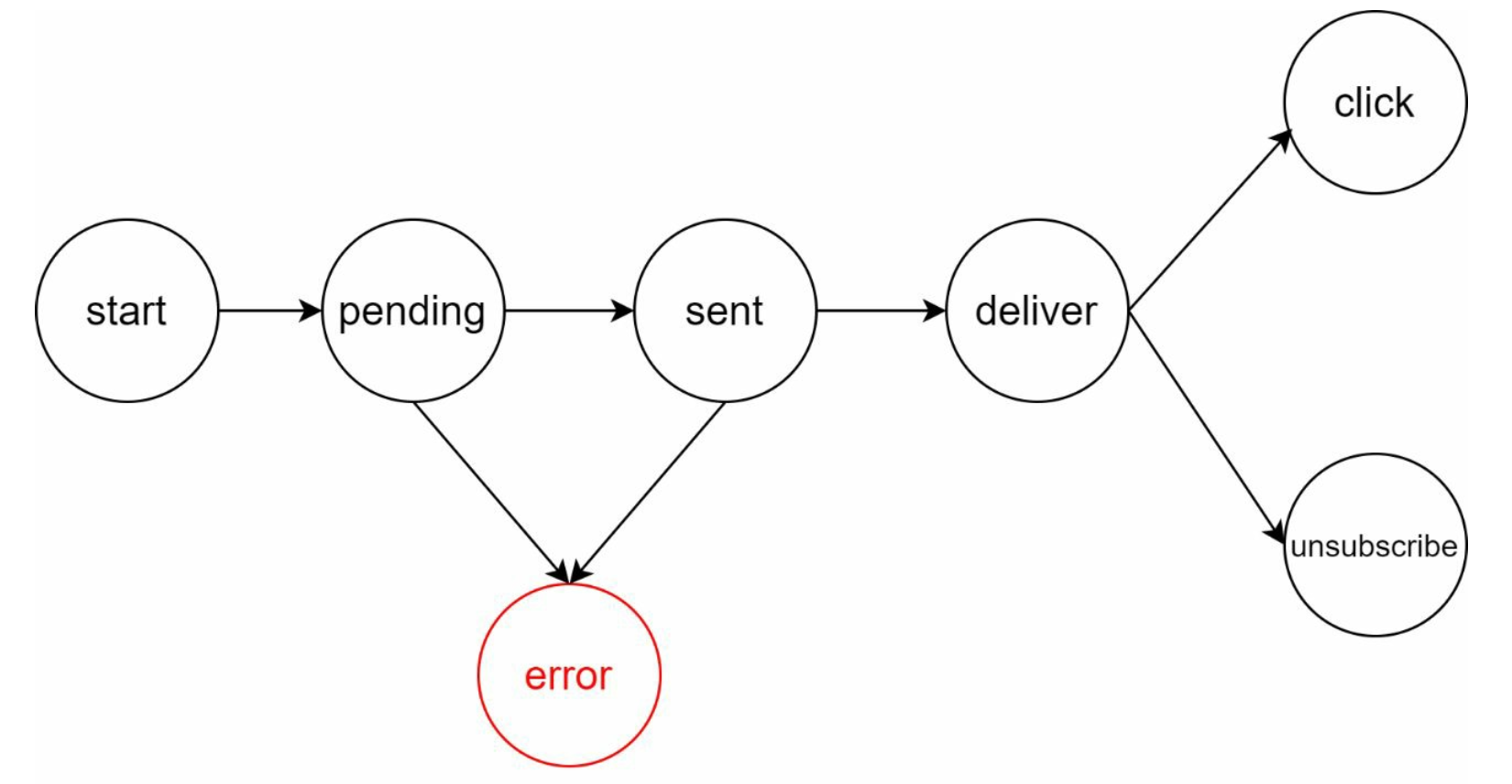
updated design
Design a Social Network (like Twitter)
- 关注/粉丝系统设计(fanout on write vs fanout on read)
- 动态(Feed)生成
- 分布式数据库与缓存优化(Redis, Cassandra, etc.)
Requirements
Functional Requirements:
- Users should be able to post new tweets.
- A user should be able to follow other users.
- Users should be able to mark tweets as favorites.
- The service should be able to create and display a user’s timeline consisting of top tweets from all the people the user follows.
- Tweets can contain photos and videos.
Non-functional Requirements:
- Our service needs to be highly available.
- Acceptable latency of the system is 200ms for timeline generation.
- Consistency can take a hit (in the interest of availability); if a user doesn’t see
a tweet for a while, it should be fine.
Capacity Estimation and Constraints
Let’s assume we have one billion total users with 200 million daily active users
(DAU). Also assume we have 100 million new tweets every day and on average each
user follows 200 people.
How many favorites per day? If, on average, each user favorites five tweets per day
we will have:200M users * 5 favorites => 1B favorites
How many total tweet-views will our system generate? Let’s assume on average
a user visits their timeline 2 times a day and visits 5 other people’s pages. On
each page if a user sees 20 tweets, then our system will generate 28B/day total
tweet-views:200M DAU * ((2 + 5) * 20 tweets) => 28B/day
Storage Estimates: Let’s say each tweet has 140 characters and we need 2 bytes to
store a character without compression. Let’s assume we need 30 bytes to store
metadata with each tweet (like ID, timestamp, user ID, etc.). Total storage we would
need:100M * (280 + 30) bytes => 100M * 300bytes => 100M * 0.3KB => 30, 000, 000KB => 30, 000 MB => 30GB/day
What would our storage needs be for five years? How much storage we would need
for users’ data, follows, favorites? We will leave this for the exercise.
Not all tweets will have media, let’s assume that on average every fifth tweet has a
photo and every tenth has a video. Let’s also assume on average a photo is 200KB
and a video is 2MB. This will lead us to have 24TB of new media every day.(100M/5 photos * 200KB) + (100M/10 videos * 2MB) ~= 24TB/day
计算如下:
20M * 0.2MB = 4,000,000 MB10M * 2MB = 20,000,000 MB- 总和:
4,000,000 + 20,000,000 = 24,000,000 MB
换算为其他单位:
24,000,000 MB = 24,000 GB = 24 TB
Bandwidth Estimates: Since total ingress is 24TB per day, this would translate into290MB/sec.
Remember that we have 28B tweet views per day. We must show the photo of every
tweet (if it has a photo), but let’s assume that the users watch every 3rd video they
see in their timeline. So, total egress(/ˈiːɡres/ n. 外出;出口) will be:(28B * 280 bytes) / 86400s of text => 93MB/s
+ (28B/5 * 200KB ) / 86400s of photos => 13GB/S
+ (28B/10/3 * 2MB ) / 86400s of Videos => 22GB/s
Total ~= 35GB/s
High level SD
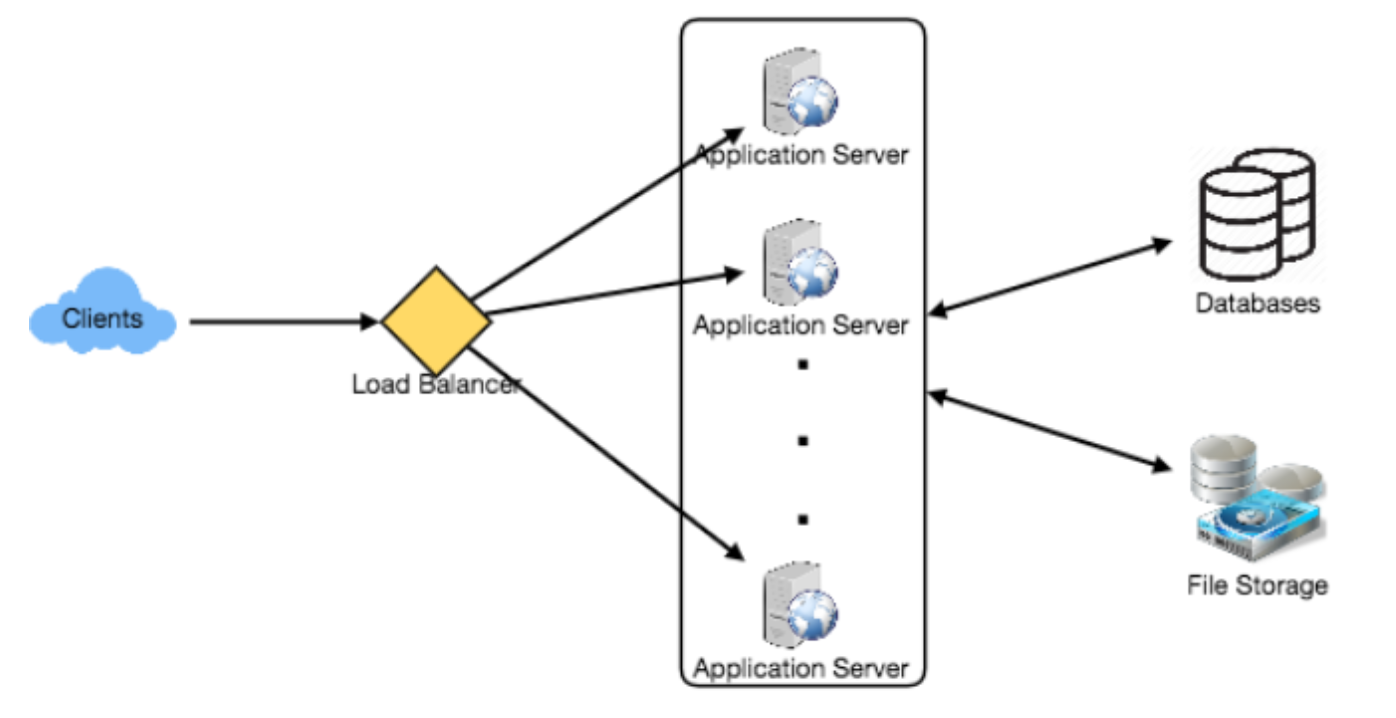
Database Schema
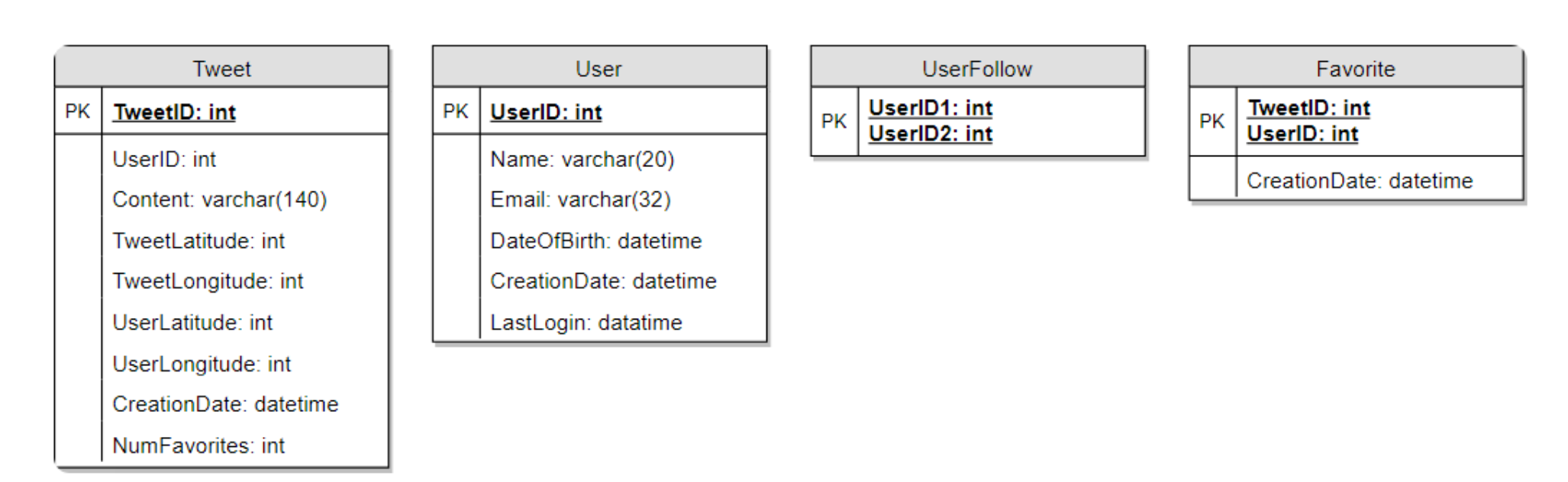
A straightforward approach for storing the above schema would be to use an
RDBMS like MySQL since we require joins. But relational databases come with their
challenges, especially when we need to scale them.
- We can store
photosin a distributed file storage like HDFS orS3. - We can store the above
schemain a distributed key-value store to enjoy the benefits offered by NoSQL.- All the metadata related to photos can go to a table where the ‘key’ would be the ‘PhotoID’ and the ‘value’ would be an object containing PhotoLocation, UserLocation, CreationTimestamp, etc.
- We need to store relationships between users and photos, to know who owns which photo. We also need to store the list of people a user follows.
- For both of these tables, we can use a wide-column datastore like Cassandra.
- For the ‘UserPhoto’ table, the ‘key’ would be ‘UserID’ and the ‘value’ would be the list of ‘PhotoIDs’ the user owns, stored in different columns. We will have a similar scheme for the ‘UserFollow’ table.
Cassandraor key-value stores in general, always maintain a certain number of replicas to offer reliability. Also, in such data stores, deletes don’t get applied instantly, data is retained for certain days (to support undeleting) before getting removed from the system permanently.
Twitter这类应用,更适合使用 Cassandra 这样的宽列数据库(或类似架构),原因如下:
Twitter 特征分析:
- 写入密集型:用户不断发推、点赞、关注等,每秒写入量极高。
- 读性能可通过反范式设计优化:例如,用户主页 Feed 是预构建好的,而不是实时聚合查询。
- 高可用要求极高:宕机意味着全球范围的服务不可用。
- 全球部署,需要多数据中心支持。
- 一致性可以适当放松(最终一致性是可接受的)。
为什么是 Cassandra?
For an app like Twitter, we need a extremely high write throughput, because users constantly post tweets, like, follow, so the system needs to handle very high write throughput.
The read side is usually optimized by precomputing the user feeds rather than doing real-time aggregation queries.
Also, availability is super critical. Any downtime affects users worldwide. Since Twitter is deployed across multiple data centers globally, the database needs to support multi-region replication.
Cassandra fits well because it doesn’t have a single leader node—it’s decentralized and highly fault-tolerant. Plus, it offers tunable consistency, and eventual consistency is acceptable for this kind of application.
So overall, Cassandra’s write performance, high availability, global distribution support, and relaxed consistency model make it a great fit for Twitter-like systems.
| 要求 | Cassandra 提供 |
|---|---|
| 高写入吞吐 | LSM Tree + 去中心化架构,写性能极高 |
| 无单点故障 | P2P 架构,每个节点都能接收写 |
| 高可用 | 数据自动多副本,容错能力强 |
| 多数据中心部署 | 原生支持,多活同步写入 |
| 可调一致性 | 可根据业务选择强一致或最终一致 |
| 反范式建模支持 | 宽列模型天然支持冗余字段、反规范化存储 |
MongoDB 不太适合 Twitter 的原因:
- 写入压力高时主节点可能成为瓶颈。
- Sharding 和分布式部署复杂度更高。
- 多活写支持不如 Cassandra 成熟。
Data Sharding
Since we have a huge number of new tweets every day and our read load is extremely
high too, we need to distribute our data onto multiple machines such that we can
read/write it efficiently. We have many options to shard our data; let’s go through
them one by one:
- Sharding based on UserID
- Sharding based on TweetID
- Sharding based on Tweet creation time

Cache
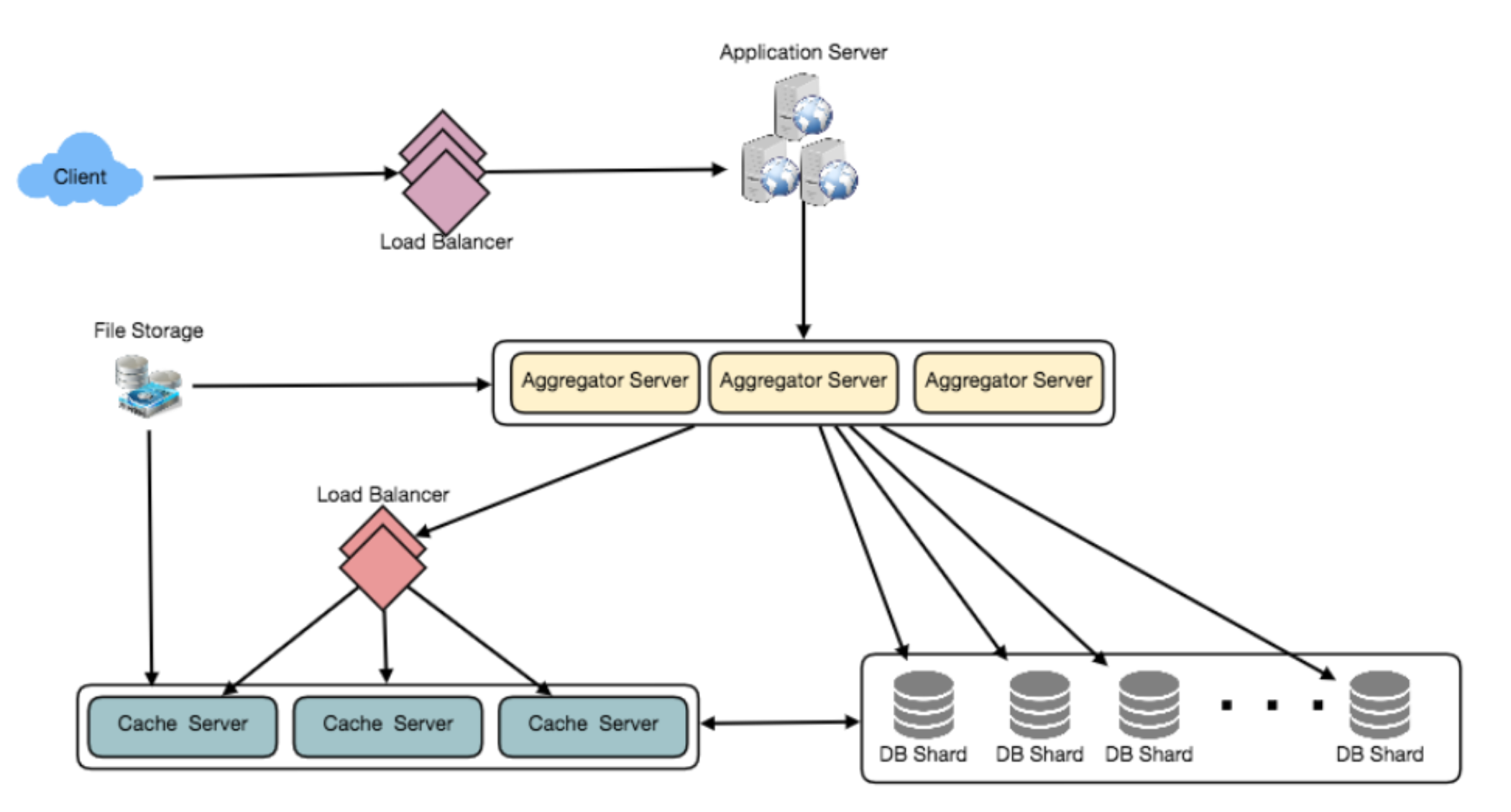
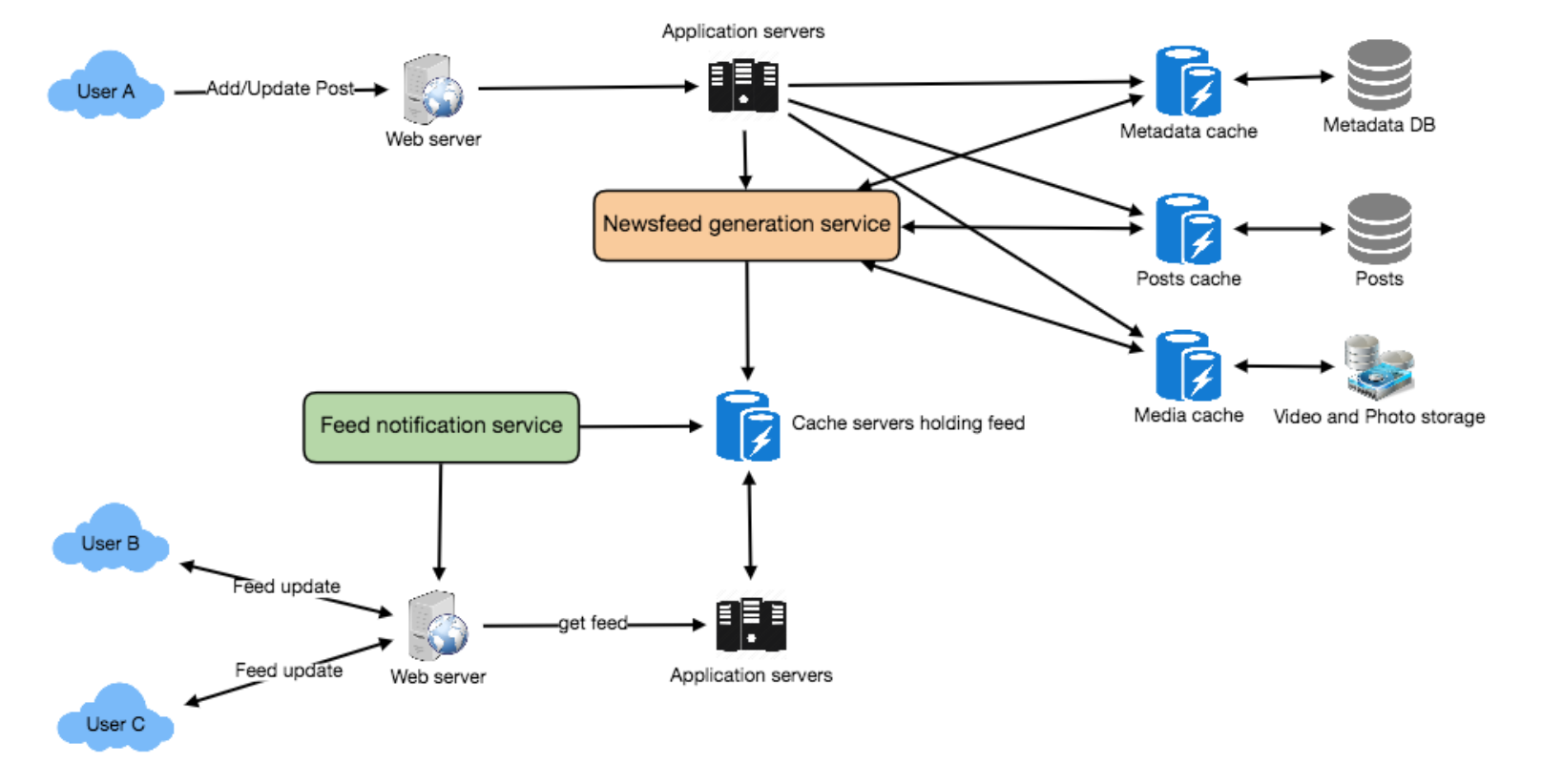
Timeline generation
- Feed generation: News feed is generated from the posts (or feed items) of users and
entities (pages and groups) that a user follows.- Offline generation for newsfeed: We can have dedicated servers that are continuously generating users’ newsfeed and storing them in memory. So, whenever a user requests for the new posts for their feed, we can simply serve it from the pre-generated, stored location.
- Feed publishing: The process of pushing a post to all the followers is called a fanout
- the
pushapproach is calledfanout-on-write, - the
pullapproach is calledfanout-on-load. hybrid
- the
Design a RESTful API backend for a fullstack web app
- 身份验证(JWT, OAuth)
- 多用户协作(文档编辑、聊天)
- 前端状态同步机制(useEffect + polling / WebSocket)
- 如何在 React 前端和 Spring Boot 后端协同设计接口