LD refers to Little Dinosaur.
TOP 15 BQ
1. Why LEAVE job
Why did you leave your last job?
- from amazon to walmart:
- Currently, I’m working on AWS Marketing Tech internal tools. Before that, I spent about 10 years in e-commerce, so when they told me that this role at Walmart is e-commerce focused, I felt it would be a better fit and something I’d really enjoy.
- contract roles are usually very result-oriented, which fits my style of driving projects to completion quickly.
- From a personal perspective, I think contractor job is more flexible and it fits my current life plan.
- Personal experience:
- Because I wanted something more challenging and a job that fit my career plans better. I wanted to find a
place where I can use my skills to really make a difference. - That’s why I’m really excited about this job at your company. I researched your company and your project, Your
company’s job description is a total match for my work experience. I can really get things done. And there’s
also new stuff to learn. - For example, I really like Kafka. in this new job, I’ll have the opportunity to deeply explore Kafka, so i think This new job seems super suitable for me, I’m really excited about it.
- and I really think I can use the stuff from my old company to help your project succeed.
- Because I wanted something more challenging and a job that fit my career plans better. I wanted to find a
2. CONFLICT with team member
Describe a major conflict within or outside your team and how you handled it, or how you dealt with a difficult team member.
- General approach: Usually, I first figure out what’s causing the issue, then have a one-on-one chat to talk
with the team member. We consider the goals and find a way to reach a compromise, especially when deciding on
different approaches.I will also try my best to understand his idea. We will discuss and keep it transparent and try to choose the best solution. It does not matter who comes up with that solution, because our goal is to make best product for customers. If we cannot really agree on each other, we will escalate to manager and let manager decides, we should all agree on the final decision. - Personal experience: for example, At my previous company, I remember once I disagreed with a frontend
developer on the API design. He wanted something simple, but I knew we needed something more scalable. And then we discussed it, his idea is easier to implement and easier to use, but it’s not scalable; however, my idea is more complicated to implement but it’s more scalable. so After discussing the issue and considering the advantages and disadvantages, we found a compromise, that is, I create a simple version that the frontend can use right away, and also supported optional parameters to let the frontend get extra data. as the result, it worked well, and both of us were happy about it.
3. challenge-N
Describe a time when you had difficulty completing a task or making progress.
I remember once I had to take over an old Micro service, then handled our order processing. But there was almost no documentation, no diagrams, no data flow, and not even comments in the code.
So then I had to trace the Kafka topics. I had to read the code from scratch, and had to check out the old Jira tickets to understand the workflow. And it slowed me down by almost two days.
So I realized the system was more complex than I expected, so I immediately discussed the risk with my manager. I told him that I had to figure things out from scratch, and it would take a while. so we discussed we should push back the deadline or lower the priority of the ticket.
My manager appreciated that I reported it in advance. finally, my manager decided to push back the deadline.
After getting everything under control, I walked through and carefully read all the related code, I created a full diagram of the message flow, and wrote many detailed documentation and added many comments to the code. That way, the next person wouldn’t have to start from scratch like I did and could easily get things done.
As a result, I successfully took over the microservices. After that, I could easily modify the code related to the microservices and add new features easily.
4. CHANGE something is good enough
If your manager asks you to change something that you think is already good enough, how would you handle it?
- General approach: Usually, I listen to my manager’s reasons and then I share my view and show some data to
support it. If needed, I think we could come up with a compromise … - Personal experience: for example, I remember once I used Memcache to do the caching. but my manager wanted to
switch to use Redis. So we discussed it, I thought Memcache’s data structure was pretty simple so it’s very easy to use and it fully met our needs at that time. We just needed to cache some key - values then. But he told me that our project will become more complicated, and Redis had more features and it was more powerful to handle future changes and redis had better performance. so we ran some tests to compare their performance and we found that redis was better, and we found that Redis was also better than Memcache in many other ways. like:- for data processing, redis can handle different kinds of data, like lists, sets, and hashes. but Memcache can only deal with key - value pairs.
- for data persistence, redis can store data on the disk, but memcache can not.
- so finally, we decided to use redis to handle changes in the future, because redis is way better than Memcache.
5. disagree-N
what if the decision were made on a aspect you are not agree with? Team conflict
I remember once we were planning a big upgrade to our promotion system, and the team decided to use a third-party tool to manage the discount period. But I thought it didn’t support real-time rollback strategies and didn’t work well with our Redis caching.
So at the design meeting, I pointed out the risks, like possible latency issues and lack of responsibility capability. If there was something wrong with the promotion rules, we couldn’t handle that quickly. But the team chose to move ahead anyway. So I disagreed, but I respected the decision.
To reduce risk, I volunteered to build a caching proxy in front of the promotion engine. Also, we 安静。So I put some local override flags stored in Redis so that if the window system failed or returned incorrect logic, we could cut off the third-party logic and fall back immediately.
A few weeks later, one promotion rule broke during a big campaign—it started applying zero discount. My caching proxy worked, and we shut it down in minutes with no impact.
After that, the team adopted the fallback mechanism as the standard design requirement for all future vendor integrations.
For me, I learned it’s important to speak up when seeing risks, but once a decision is made, we must respect it and take steps to reduce risks. It’s not about who’s idea wins; it’s about being responsible and providing the best product to our customers.
if (redis.get("promoEngine.disabled").equals("true")) { |
9. SUDDENLY ASSIGNS you a new task
If you are working on a sprint and your manager suddenly assigns you a new task that needs to be finished as soon as possible, what would you do?
- General approach: This is really normal for me. First I will connect with manager to get an idea on the
priority/ praɪˈɔːrəti /of the task, and reorganize my priorities. ( in the middle say something like gotta
be a reason manager made the choice) - Personal experience: for example, I remember once I was working on a ticket to implement a new API
endpoint, suddenly manager assigned a new ticket for me, it’s related to the production issue, which was about
the delays in order processing, and the manager thought I have the ability to do that. Finally, manager is
really happy about how quickly I solved the issue.
11. found MISTAKE-N
when you found mistake or went for a extra mile for customer
Sure. At Costco, some enterprise users complained that our dashboard was slow, but only sometimes. Metrics looked fine, logs were clean—nothing obvious.
确定。 在 Costco,一些企业用户抱怨我们的控制面板很慢,但只是有时很慢。指标看起来不错,日志很干净 - 没有什么明显的。
I had a feeling it might only happen when users had a large amount of data. So after hours, I wrote a simple simulator that recreated a heavy account to simulate a real customer with thousands of items.
我有一种感觉,这可能只有在用户拥有大量数据时才会发生。因此,下班后,我编写了一个简单的模拟器,它重新创建了一个沉重的账户 — 基本上是模拟拥有数千件商品的真实客户。
and after a while, I found a downstream service was doing N+1 DB calls per item.
I fixed the query pattern, and the latency for those users was reduced by almost 50%.我们修复了查询模式,这些用户的延迟降低了近一半。
It wasn’t part of my sprint work, but in my view, if customers are stuck on something, I step up to fix it—even if it’s not officially my task.
-- 第1次查询:查用户所有订单 |
12. made MISTAKE
Share a time when you made a mistake in a team setting, how you resolved it, and what you learned from the experience.
- Personal experience:
- Situation: I remember once I made a mistake and let some sensitive user data show up in an API. It was a
security issue. - Task: I needed to quickly solve the problem to protect user data and make sure this kind of thing didn’t
happen again in the future. - Action: I took some actions to fix the security problem. I reproduced it in our local environment, I added checks and controls to limit data access
to those who could access the data. Then I held a meeting and made a presentation about this problem. and we
discussed how to prevent this kind of problem from happening again in the future. - Result: After that, I’m always careful about user data and always review my code before I push my code. our code review process became better and we added stricter security checks and more
reviews.
- Situation: I remember once I made a mistake and let some sensitive user data show up in an API. It was a
15. MENTORING a junior
If you are mentoring a junior colleague and they propose a new idea to the team, how would you handle it?
- General approach: Usually, I listen to the idea, I think about it if it’s a good solution, and I help them
show it to the team. - Personal experience: I remember many years ago ,once I was mentoring a junior colleague ; and he came out with an idea that we should use a new API testing tool named postman to replace our old API tester, I checked how it would work with our project, and and it’s much easier to
integrate into our CI/CD workflow. I encouraged them to show it to the team, and the team agreed to use the idea.as the result, it was very popular and we all like that very much
6. AGILE & Waterfall
Are you familiar with AGILE
/ ˈædʒ(ə)l /processes and Waterfall methodology/ ˌmeθəˈdɑːlədʒi /?
- General approach: Agile works in an iterative
/ ˈɪtəreɪtɪv/way. It breaks work into small cycles. This way,
you can get feedback all the time and make changes as you go. Waterfall is different. It’s sequential. That means
you have to follow the steps one by one. - Personal experience: In my experience, Agile is really good for projects that are fast - paced and need to be flexible. for example, At my previous company, we used Scrum. We had two - week sprints and daily stand - up meetings. This helped us change things fast based on what users said. But for smaller projects where everything is clearly defined, like a school project, I use Waterfall, When you have a clear plan from the beginning to the end,it’s easier to get the work done. Both methods are useful in their own ways, but I like Agile better because itcan adapt to different situations.
7. TYPICAL Day
What does a TYPICAL day look like for you?
- We follow Agile methodology, we have 2 weeks sprint.
- So at beginning of each sprint, we have a planning meeting which we sit together to discuss all the tickets we need to work in in the whole sprint, and after that we have grooming meeting which is for developers to get familiar their own tickets.
- Then in each day, we have daily standup meeting in the morning at around 10am when we discuss our progress on each ticket and any blockers (need to wait on others work) we have. After meeting, we go back to work on our tickets and sometimes, we have meeting with business team to discuss the detailed problems, we also have design meetings for each big stories and we also have developer meetings to discuss our common issues.
- AT the end of each sprint, we have retrospective/retro meeting to review what we have done.
- Percentage of daily time: 60-70% on coding including development and test cases, 10-20% on meetings, 10-20% on leading junior people or system design meeting
8. good team
What do you think are the most important factors for a successful team ?
- General approach: Good communication, clear goals, trust, and a positive learning attitude are key for a team to succeed.Some points to mention:
- Good team culture, nice working environment
- Good skills and new technologies used in the team
- You feel you can grow in the team, someday you may become a senior or leading some juniors
- You feel being important to the project, you can make contributions and be needed by others as well.
10. yourself that is NOT ON YOUR RESUME
Tell me something about yourself that is not on your resume.
- Personal experience: I like to develop some productivity tools, like shell tool, I once developed a zshell
plugin that can search everything very quickly with the key tab, and I once developed a chrome plugins, which can
show the table of content for the web pages, so we can navigate to the chapter whatever we want very quickly, it’s
very helpful to read the long technical articles, and I introduced these tools to my team members, which helped
them complete their work more efficiently and also enhanced my coding skills.
13. on-call
Do you have on-call experience, and are you comfortable with overnight on-call duties?
- Personal experience: this is very normal for me, I’m totally comfortable with overnight on-call duties. I
remember when I was at my REI, I was on call during busy times. and there was a problem with the database, I fixed
it quickly and got the service running again.
14. pair programming
Do you know what pair programming is, and what are your thoughts on it?
- It’s like There are two developers and they are working together for tickets and they will share the idea to each other who is each other and they will learn something from each other.
- its advantages is like:
- Good to learn from the leader and good for new members to get familiar with project
- Good to trigger new ideas, when you discuss, new ideas come out more often then you just think by yourself
- and the disadvantage is like:
- Bad: coding is very slow.
- as for Work independent: I am experienced, so I can solve most of the tickets just by working on my own.
- But I also did pair programming with team members, like when we have Demo or Design meetings, or when I do knowledge transfer for some new team members, I do pair programming to help them.
Story:
- at Costco, I remember once a junior dev was assigned a backend module but was falling behind. The project was on the critical path.
- I volunteered to pair with him, walked him through breaking down the logic, and helped him set up proper debugging tools.
- He caught up within a week, and later he started handling the integration test writing by himself without needing to be told.
- as a result, he finally delivered successfully, and we were very happy about that.
- It wasn’t just about saving the delivery—it was about helping someone who could deliver long-term.
16. code review
Describe your code review process. What do you focus on during a code review?
- General approach: Usually, I focus on making code easy to read, and check if it has security risk and some
performance problems, and make sure it follows our coding standards.- Syntax error
- Possible duplicate logic
- Method possibilities to split to reusable methods.
- Make sure having unit test that covers the part
- Check performance improvements, like try to improve the time and space complexity.
- Check performance, like try to use cache or eliminate duplicate database calls.
- Personal experience: For example, when I was doing a code review, I found variable names that were not clear,
or a security problem like some colleagues didn’t check the access permissions in their APIs, or some performance
issues like redundant for loops to search something. We fixed those things, and the code became better and more secure.
Ask interviewer some questions
- What is your typical day like?
- Can I ask what your typical day looks like on this team?
- I wonder, like, what’s the daily routine work like? ‘Cause I remember it’s a hybrid, right? So I’m kind of interested in, like, the daily routine of the team.
- And this role is more like backend focused(frontend focused), I’m wondering what Frameworks that you guys are using?
- sounds fun and busy.
- you actually answered a lot. I have a bigger picture of what the task is.
- May I ask what would be like the future steps for the interview process?
- I think you have answered all my questions
- (if it’s only a vendor interview)
- thank u for your time and what’s the next step for the interview?
Ending
- Like all the things you said, I’m pretty familiar with them. Like a daily stand-up — at Costco, we do it every day, so we can align our expectations among all the people, so that we can keep each other on track with our work. So everything you said is pretty familiar to me. And I think once I can get on board, I can start working really easily and quickly.
- Yeah I really appreciate your time today and uh yeah thank you for taking your time to interview with me.
- it was really great to meet you.
- great meeting you.
- Have a good rest of your day.
Self - Introduction
requirements:
- Prepare a fluent self-introduction and a detailed summary of work/project experience.
- Familiarize yourself thoroughly with your resume.Be ready to elaborate on your roles, achievements, and
technologies/tools you used.
Hey there! I’m Michael Hu.
I’ve been working as a Java (fullstack) developer for over ten years now, I have project leadership experience. and I have experience building scalable,high-performance backend services and dynamic frontend web pages to solve real business problems.
I’m good at Java, JavaScript, Spring Boot and React. I used them to create many RESTful APIs. These APIs have detailed documentation, and I used these APIs to make backend services and frontend applications communicate with each other, and also make many different micro services communicate with each other in a distributed environment.
- In backend development:
- For security, I use Spring Security, OAuth2, JWT to implement authentication and authorization, to make sure
everything is secure. - For data processing, I also work with Apache
/ əˈpætʃi /Kafka for real-time data processing, to build
event-driven architectures that handle high-throughput data streams and scalable messaging systems. - For database, I mainly use MySQL and MongoDB and redis, I’ve got plenty of experience with Hibernate and JPA for
data persistence. (I design complex schemas, optimize queries, and ensure data integrity) - For cloud platforms, I worked with many AWS services. I use EC2(Elastic Compute Cloud) to deploy and manage virtual servers, EKS(ECS: Elastic Container Service亚麻自带的类似k8s的东西一般给小公司用, 还有个EKS是兼容k8s的容器编排管理服务, 大点的公司一般用EKS) to orchestrate
/ ˈɔːrkɪstreɪt /Microservices in containers,RDS to handle relational databases, S3 to handle scalable storage, I use CloudWatch to track performance, monitor logs, metrics, and system health.
- For security, I use Spring Security, OAuth2, JWT to implement authentication and authorization, to make sure
- In frontend development:
- for state management, I use
Reduxfor complicated state management, and useuseReducer + useContextfor simpler state management. - for responsive UI, I use
Material UIto provide a consistent user experience no matter what device or browser people use, they’ll have a similar experience. - for testing, I use
Jestfor unit testing andReact Testing Libraryfor behavior driven testing.
- for state management, I use
Amazon
Next, let me talk about the my current work experience.
I am part of the AWS Marketing Tech team, where we design and maintain scalable systems that power marketing campaign management across AWS services.
- On the backend, I build Java and
Coral(likeSpringBoot, Amazon’s internal library for service-to-service communication) microservices to manage complex workflows, including segmentation, targeting, and event processing. - On the frontend, I develop React-based applications that allow internal users to efficiently launch, monitor, and optimize marketing campaigns at a global scale.
and you know this project is a aws marketing technology project, our main goal is to automate the assignment of the marketing qualified leads(MQL) to sale representatives.
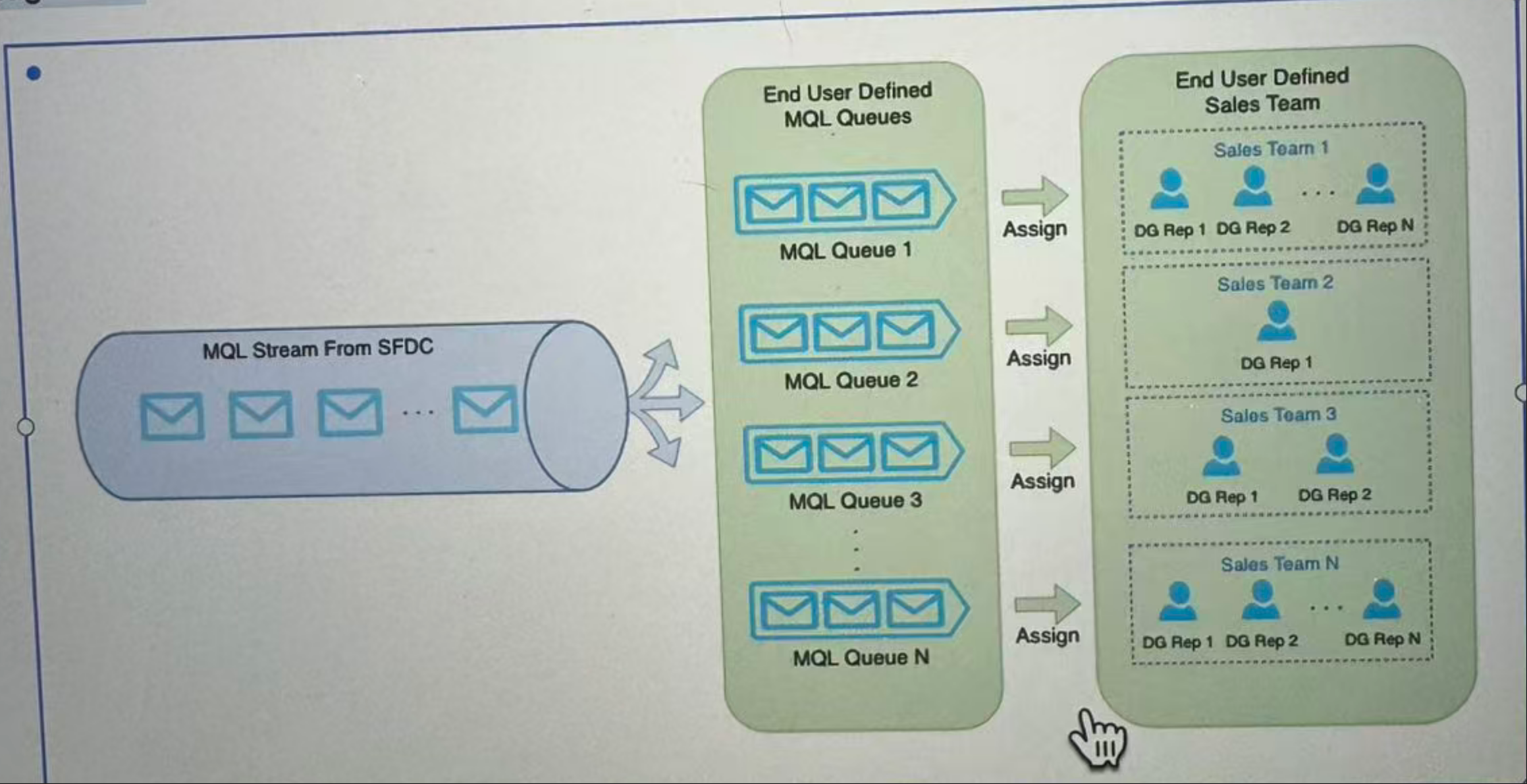
And its architecture has 3 parts:
MQLstream from SFDC(Saleforce, SFDC 的四个字母分别代表:S–Salesforce, F–Force, D–Dot, C–Com)- our process system with many
MQLqueues - sales team
So we just pull those data from the saleforce MQL stream. And then we process those data and assign those mQL To sales team representatives.
on the tech side, the project is AWS-based using like
- Backend
- Lambda – Serverless compute service to run backend logic without managing servers.
- DynamoDB – like
MongoDB, Fully managed NoSQL database for fast and scalable data storage. - EventBridge – Event bus to route and integrate events between AWS services.
- SQS – like
Kakfa, Message queue for reliable decoupling of distributed systems. - CDK – Infrastructure as code framework to define AWS resources in code.
- Coral – like
SpringBoot, Amazon’s internal library for service-to-service communication. - Dagger – Dependency injection framework for managing component lifecycles.
- Smithy – Modeling language to define APIs and generate SDKs.
- Frontend
- React – JavaScript library for building dynamic user interfaces.
- Polaris UI – like
Material UI, Amazon’s internal UI component library for consistent design.
- CI/CD
- Brazil – Amazon’s internal build system for versioning and dependency management.
- Pipelines – it’s like a workflow for build, test, and deployment,
Pipelineswill triggerApolloto do the actual deployment of the software to the target environments.
- Apollo /əˈpɑːloʊ/ – Amazon’s internal deployment system for safe, large-scale rollouts.
Amazon-Lead version
略: At Amazon, in my first week, I solved a complicated sqs problem, and I have over 10 years lead experience, so then they just let me to lead the new project, but you know actually it’s a kind of tech lead role (but without the formal title.)
they just let me to lead the AWS marketing customer assignment project with 5 engineers, driving the architecture and designing the workflows, also coordinating with other stakeholders. I usually push projects quickly, and by the end of last month, we had finished most of the core work. We have almost delivered the main system, and the AWS customer assignment automation is working end-to-end.
略: The manager thought the project was almost complete, so they wanted the contract to end earlier. It was a 8 months contract, now they cut the budget, and decided to end it early. The contract will now end on September 30.
challenge
I had to take over a old Microservices that handle customer engagement events.There are some inconsistent campaign stats—like an “email opened” event being recorded before the “email sent” event.
, and but there was almost no documentation. Yeah, no data flow and no comments in the code and no diagrams and not even clear ownership info.
So I had to trace SQS topics, and I had to manually inspect those message payloads. And also to check out the old job tickets to understand the workflow and it slowed me down by at least two days, I remember.
Then I realized the system was more complex than expected, so I immediately Discuss the risk with my manager about the priority. I told him that this ticket, I had to figure things out from scratch and it would take a while. So we should. Lower its priority or just push back the deadline, I think.
And that way we can avoid rushing Yeah, because, you know, rushing makes bugs and my manager, I remember my manager was very happy about. I report it in advance
and after getting everything under control, I just walk through all the related code and And after that I create a diagram of the flow and also I did many. Documentation about the code
After digging in, I realized the issue was due to SQS message timing. Since we were using a standard queue, some messages were processed out of order. Our consumer logic assumed messages arrived in order, which caused these inconsistencies.
To fix it, so I just updated the consumer logic to check the current state before applying updates. I also added deduplication checks so retries wouldn’t corrupt the data. and also I added some many test cases to cover those. business Logic。
After these changes, the campaign metrics became reliable, and the AWS Marketing dashboards became accurate in real time.
Yeah, and with those documentation, I think the next person wouldn’t start from scratch like I did, it will increase the efficiency of our group.
Costco/Netease
- Costco has an office on Morena Blvd
/mɔːˈreɪnə ˈblʌvd/.in San Diego/sæn diˈeɪɡəʊ/. - SKU(Stock Keeping Unit,库存单位)是零售和供应链管理中用来唯一标识某一具体商品的编码。它通常反映了商品的属性,比如品牌、型号、颜色、尺寸等,用来区分不同的产品变体,方便库存管理、销售统计和补货决策。简单说,SKU就是产品的“身份证号”。
duty - lead version
And next, let me talk about my work experience:
- Situation: I was working at NetEase, I was in a e-commerce team.
- the project was a e-commerce platform.
- Role: I serve as a Tech Lead Java (Full-Stack) Developer, mainly driving backend architecture design, system scalability, and integration.
- Team: I was leading a core e-commerce engineering team, collaborating with product managers, frontend engineers, and data engineers.
- Project: One of the major projects was building and scaling an e-commerce platform to support high transaction volumes and diverse business models.
- Responsibilities:
- Designed and implemented core modules such as
- order management,
- payment processing,
- logistics(物流) / delivery tracking,
- and third-party system integration, like :
- payment gateways(like Apple pay, Paypal)
- logistics providers (SF Express, Cainiao),
- and notification services (email and SMS providers).
- I designed the integration in a way that isolates external dependencies,
- i Optimized system performance by refactoring legacy services, like
- using(introducing) asynchronous processing with Kafka,
- and using(leveraging) Redis for caching high-frequency queries.
- to handle deployment, I used Docker and Kubernetes to handle it.
- Mentored some engineers , providing technical guidance, reviewing code, and aligning the team on best practices.
- Designed and implemented core modules such as
duty
- and next let me talk about my work experience:
- Situation: First, let me talk about the company I’m currently working for. its name is Costco, it’s a retail and e-commerce company,
- I’m a senior/lead java (fullstack) developer there.
- I was in a e-commerce team.
- the project was a e-commerce platform.
- I’m mainly responsible for developing and maintaining the core modules, like retail data processing and system integration and optimizing the performance and handling some business logic like: e-commerce platform, order system, payment system, delivery system and so on.
- Because the number of transactions was growing very fast, but their old systems couldn’t keep up with new features and increasing user activity, so we needed a some stronger systems.
- Task: So I used Java/Spring Boot/kafka/redis/PostgreSQL/aws services/kubernetes to build a more scalable backend architecture and developed some microservices, and use JavaScript/React to build some responsive single-page application, and optimize the database-related parts and enhance security.
- Action(unnecessary, should skip): So I had to take some actions to finish my task. so First,(根据从处理数据一点点到部署的顺序记忆)
- to handle scalability, I used springboot to developed a modular microservices architecture and designed plenty of RESTful APIs. Each service handled a specific function, like user management, poll management, and data analysis.
- to handle security, I used Spring Security and OAuth2 for authentication and authorization.
- to handle data processing, I used Kafka to make data analysis much faster.
- to handle database, I used Redis caching to reduce database load and speed up responses. I also optimized database queries by adding indexes, removing redundant joins.
- to handle storage, I integrated AWS RDS to enhance data management. , integrating third-party analysis tools.
- to handle deployment, I used Docker and Kubernetes to handle it.
- Result(optional): as the result, The new microservices architecture made the system more flexible and easier to maintain. and the e-commerce platform also became more scalable, and its frontend also became more efficient, beautiful and easy to use, like: the web page loading time was reduced by 30%, our API response times improved by 30%, our system handled 20% more daily transactions, and user engagement went up by 25%.
Challenge1-long term
Because the number of transactions was growing very fast, but their old systems couldn’t keep up with new features and increasing user activity,(so we needed a some stronger systems.)
One challenge was with slow product page load times or even crashes during traffic spikes, like Black Friday, which hurt our conversion rate.
- so I led the team in continuously refactoring and splitting some core modules, like transactions, orders, delivery and payment and so on.
- so actually it’s kind of a long-term thing.
- and I also led our group members to do some optimizations:
- for PostgreSQL: So I made some presentation about SQL optimizations and invited some database experts of our company to do some knowledge transfer. then our group members learned how to optimize SQL,
- using read replicas for reporting queries during peak hours
- like using explain to inspect those slow queries, and then checked JOIN types and their efficiency, and then reviewed index usage, found some unoptimized joins.
- like creating some indexes on frequently joined columns, changed some LEFT JOINs to INNER JOINs .This way, we stop getting data we don’t need..
- For MongoDB: I profiled the APIs and found many Mongo queries were unindexed and hitting large collections. and then I wrote some documentation for mongodb optimization and assigned many tickets to our group members to fix that.
- So then they knew how to add compound indexes, optimized the schema for access patterns, like embedding documents for fast reads.
- We also paginated large result sets
- and i also encouraged them to give presentations about the best practices for the business logic related to mongodb.
- For Caching:
- I cached heavy read data in Redis, like some popular products,
- ◦ We also cached temporary computation results to speed up real-time APIs, like recommendation api based on their interests
- for boosting search: use Elasticsearch helped with fast product search across millions of SKUs.
- We structured our Elasticsearch indices by product category, with a shared template for common fields like name, brand, price, and availability.
- The benefit is that queries become faster because we only search within the relevant category.
- It also gives us flexibility — we can keep the common fields consistent across categories, while still adding category-specific fields like screen size for electronics or size and color for clothing.
- This structure makes the system more scalable, easier to manage, and prevents issues in one category from affecting others.
- We also used nested fields for things like product variants and attributes, so we could support complex filters — like color, size, or rating — in one query.
- To keep search fast, we indexed only the fields we needed for search and sorting, and excluded heavy metadata. This setup made it easy to scale and kept the queries performant.
- We structured our Elasticsearch indices by product category, with a shared template for common fields like name, brand, price, and availability.
- For the webpage: We also added pagination and lazy loading for large data sets
- For fault tolerance: I added more watches to Prometheus and Grafana to monitored services, used circuit breakers to isolate failures.
- for PostgreSQL: So I made some presentation about SQL optimizations and invited some database experts of our company to do some knowledge transfer. then our group members learned how to optimize SQL,
- Result(optional): as the result, the system became more flexible and easier to maintain and more performant. like: page load times dropped from 2s to under 500ms., our API response times improved by 30%, our system handled 20% more daily transactions, and user engagement went up by 25%.
- (optional)R: As the result, After that, page load times dropped from 2s to under 500ms. the query execution time was reduced by 50%. . (This whole thing really helped me understand more about databases optimization. i feel it was a great experience to me because I gained all the SQL experiences. )
Challenge2-deadline
Q1: How did you ensure your Spring Boot services could handle real-time trading demands under heavy load?**
I remember During the pandemic, our e-commerce department suddenly got a request: build a people-to-people trading platform, and we had only about a month to get it live. The timeline was extremely tight,
- first, I discussed with our business stakeholders , the key was priority, first make sure it’s stable and online, and only then go back and optimize.
- So in the first phase we focused on stability and fast delivery:
- we kept the architecture simple, used Spring Boot for the services,
- Redis for caching, and Kafka for decoupling to avoid any single point of failure.
- We deployed on Kubernetes with auto-scaling so the system could survive sudden traffic spikes.
- And also, we use the Prometheus and Grafana to monitor the system. Yeah, we see we watched the metrics and used it to pop out alerts on the trading latency or error.
- After going live, we started the optimization work:
- the real time trading required sub-second latency.
- Yes. So to meet that, we all optimized our spring boot, with the connection pooling and also we use the non-blocking web client. Yeah, and we will tune the thread pools to handle the high concurrency.
- So. And so. And also we use the Gatling to simulate the marketplace, and we use the results to modify our code,to optimize our code and we use the Kafka to decoupling those services, make it asynchronous, to reduce the sync bottlenecks.
- And also we use the
ZGCfor low latency. It’s kind of garbage collector and we use that for low latency and to avoid the gC pauses.
- So in the first phase we focused on stability and fast delivery:
AWS
Q0.5: How did you use AWS in your deployment?
A0.5:
- We use many AWS services,
- like we use AWS EC2 to deploy our back-end services,
- and also we use EKS to orchestrate those virtual servers in containers,
- and we use S3 for static assets,
- and for the machine learning pipelines,
- I used SageMaker, Glue, and Step functions, and API Gateway to build a machine learning pipeline.
Q1: How did you ensure low latency and high availability in your Spring Boot microservices deployed on AWS?
A1:
- For low latency, we optimize our spring boot. like the connection pooling and also we will tune the thread pools to handle the high concurrency.
- And also we will use the Redis to cache those hot data like the popular products and some other hot market data.
- And also we will use the ZGC for low latency. It’s a kind of garbage collector. We use that for low latency and to avoid GC pause.
- And also we will optimize our relational database. Like we will inspect those slow queries and optimize them.
- for the high availability, we use AWS EC2. So we just use the EKS to orchestrate those virtual servers. So we will configure the horizontal auto-scaling policy to ensure the high availability.
Q2: How did you handle configuration and secrets in your pipeline
A2:
- CodePipeline is triggered by a Git push event (e.g., to the main branch).
- CodeBuild assumes an IAM role with permissions to access both AWS Secrets Manager and Systems Manager Parameter Store securely.
- Secrets Manager provides sensitive data like database passwords, API keys, or tokens during the build.
- Parameter Store supplies non-sensitive configuration parameters (e.g., feature flags, environment settings) dynamically at runtime or build time.
- CodeBuild downloads additional configuration files (e.g.,
prod-config.yaml) from an S3 bucket based on the target environment. - The build process creates a Docker image, injects configurations and secrets, then deploys to the target environment, such as ECS, EKS, or Lambda.
CodePipeline
- A fully managed continuous delivery service that automates your release pipelines for fast and reliable application updates.
- Integrates with GitHub, CodeCommit, and other source providers to trigger pipelines on code changes.
- Coordinates the flow of build, test, and deploy stages across AWS services or third-party tools.
CodeBuild
- A fully managed build service that compiles source code, runs tests, and produces deployable artifacts.
- Supports custom build environments via Docker, and scales automatically with demand.
- In CI/CD, it runs the build steps defined in
buildspec.yml, including fetching secrets and configs.
AWS Secrets Manager
- Securely stores, manages, and retrieves sensitive information such as database credentials, API keys, and tokens.
- Supports automatic secret rotation and fine-grained access control via IAM policies.
- Enables secrets to be fetched dynamically during builds or runtime, avoiding hardcoding secrets in code.
IAM (Identity and Access Management)
- AWS’s centralized system for defining user, service, and resource permissions.
- Ensures that CodeBuild and CodePipeline have the least privilege necessary to access secrets, configs, and deploy targets.
- Supports roles and policies for secure, auditable permission management.
Unit testing
Q1: How did you ensure test coverage across frontend and backend codebases?
A1:
- For backend, JUnit + Mockito covered services and controllers.
- for Frontend, used React Testing Library and Jest for component/unit testing. End-to-end flows were validated with Playwright(参考). Coverage thresholds were enforced in CI.
注: TestNG 是一个 Java 测试框架,类似于 JUnit,但功能更强大,灵活性更高。
Kafka & RabbitMQ
Q0: How did you use Kafka and RabbitMQ?
A0:
- We mainly use Kafka for the order processing, like streaming the order events, to build an event-driven architecture, to handle the high throughput data stream,
- and we use the RabbitMQ to decouple those microservices, we used it to support asynchronous communication. for those microservices.
Q1: How did you decide when to use Kafka vs RabbitMQ?
A1:
- Kafka was usually used for high-throughput, persistent event streams like order placements and inventory updates.
- for RabbitMQ, we usually used it to handled point-to-point messaging between coupled services, and these services usually required low latency, complex routing.
Q2: What fault-tolerance mechanisms did you implement for these queues?
A2:
- Actually, these two kinds of message queues have their own fault tolerance mechanisms.
- Kafka, for example,
- has a replication logic. It’s like the broker contains many topics, right? And those topics are split into many partitions. And each partition has replication — has multiple replicas.
- Kafka also has a dead-letter queue to handle those failures when processing messages.
- Kafka has the acks configuration; we can configure acks to 0, 1, or all to implement different levels of acknowledgement.
- Kafka also has the auto-commit configuration — we can set auto-commit to false and manually submit the offsets to the broker. That’s also a way to implement fault tolerance and avoid data loss.
- As for RabbitMQ, it also has similar features.
Q3: How did you handle backpressure(指消费者来不及处理高速写入的数据时产生的“反压”机制或问题。) in Kafka consumers?
A3:
- We used bounded queues with flow control, This means that between the Kafka listener (the part that pulls messages from Kafka) and the actual business logic (where messages are processed), we added a bounded in-memory queue as a buffer.
- When a new message is received from Kafka, it’s put into this queue.
- and then we used many worker threads to pulls messages from the queue and processes them
- and we also applied manual offset commits only after downstream processing succeeded.
- In extreme load, we activated circuit breakers to ignore non-important processing.
bounded in-memory queue
- A bounded in-memory queue is a queue with a fixed size (e.g., 1000 messages).
- When a new message is received from Kafka, it’s put into this queue.
- A separate set of worker threads pulls messages from the queue and processes them.
Why do this?
Even though Kafka uses a pull model, if you process messages slowly, messages can still pile up in memory after being polled. By introducing a bounded queue:
- You decouple message fetching from message processing
- If processing is slow, the queue fills up and blocks further consumption, which acts as a backpressure mechanism
- It helps protect the system from overload, avoids memory overflow, and ensures stable throughput
Example:
BlockingQueue<Message> queue = new ArrayBlockingQueue<>(1000); |
In short: It’s a way to safely buffer messages and control load between Kafka consumption and processing, especially under high traffic.
Spring Security, OAuth2, and JWT
Q1: How did you implement role-based access control in your APIs?
A1:
I used Spring Security with JWT and oauth2, and then describe JWT and OAuth2 and use the annotation PreAuthorize to implement method-level access control based on those roles.("hasRole('ADMIN')")
("/admin/data")
public ResponseEntity<String> getAdminData() {
return ResponseEntity.ok("admin data");
}
Q2: What were some challenges in handling token expiration and refresh?
A2:
- One challenge was handling the token expiration without ruining the user experience.
- Because we use the short-lived JWT, We need a way to refresh tokens, but we don’t want our users to log in again
- so we implement a refresh token flow. That is, the front-end store the refresh token in the cookies, and when the access token expires, it would automatically request a new token.
DB & Redis
Q1: What kind of data did you cache in Redis, and why?
A1:
- We used Redis mainly to cache frequently requested but rarely changed data — like product details, pricing rules, and vendor info — to reduce load on SQL and MongoDB.
- We also cached temporary computation results to speed up real-time APIs, like recommendation api based on their interests
Q2: How did you optimize SQL and MongoDB queries for peak traffic?
A2:
- for sql:
- I created indexes on frequently joined columns, changed some LEFT JOINs to INNER JOINs .This way, we stop getting data we don’t need..
- We also used read replicas for reporting queries during peak hours (报表类查询(如导出数据、生成分析报表)通常读的数据多但不需要最新的写入结果。)
- For MongoDB:
- I used compound indexes and designed the schema(表结构) to match access patterns(读写访问数据的方式) — like embedding documents for fast reads.
- We also paginated large result sets
当然,这里是一个具体的mongodb例子,帮助你理解“ designed the schema to match access patterns — like embedding documents for fast reads”:
不嵌套(标准化)设计:
// orders collection |
- 每次查询订单时,还要去 items collection 查详情。
- 如果订单量大,这会导致大量 join-like 操作(MongoDB 不支持真正 join),影响性能。
嵌套文档(denormalized)设计:
// orders collection |
- 所有需要展示的信息都在一个文档中。
- 读取时只查一次,速度快很多,特别适合高并发读取场景(比如订单详情页、用户订单列表)。
Elasticsearch & circuit breaker
Q1: How did you structure your Elasticsearch indices to support product search?
A1:
- We structured our Elasticsearch indices by product category, with a shared template for common fields like name, brand, price, and availability.
- We also used nested fields for things like product variants and attributes, so we could support complex filters — like color, size, or rating — in one query.
- To keep search fast, we indexed only the fields we needed for searching and sorting, and excluded heavy metadata.
Q2: How did you implement the circuit breaker pattern in your microservices?
A2:
- i use Resilience4j in our Spring Boot apps. For example, when calling external pricing or inventory services, we wrapped the calls with circuit breakers that monitored failure rates and response times.
- If a service started failing too often or timing out, it stops requests to that service for a while, to give the service time to fix itself.
- and it usually has three status, like
- Closed: Requests go as usual, but we watch for failures. If too many failures happen, it turns to Open.
- Open: Requests just fail directly. After a while, it changes to Half - Open.
- Half - Open: We let a few test requests through. If they work, it goes back to Closed. If not, it stays Open.
当然,下面是一个更具体的例子,说明如何结构化 Elasticsearch 索引来支持商品搜索:
⸻
场景:电商商品搜索
- We structured our Elasticsearch indices by product category, with a shared template for common fields like
name,brand,price, andavailability. - For example, we had indices like
products_electronics,products_clothing, andproducts_home, but they all used the same index template for consistency. - We also used nested fields for product variants and attributes. For example:
{ |
With this structure, we could support complex filters in one query. For example:
- A customer wants red shoes in size 42 with rating > 4.0.
- Elasticsearch can run a nested query like:
{ |
- This way, we kept the schema flexible and allowed category-specific attributes without losing query performance or maintainability.
CI/CD
Q0: What CI/CD setup did you use?
A0:
- We mainly use Jenkins for our
CI-CDpipeline for its flexibility and the plugin system.- Like, it supports some custom deployment scripts. And also we have some old testing tools and some old code quality analysis tools.
- But we also use some AWS CI-CD services like CodeBuild and CodePipeline for specific task. For some parts,
- like we use
CodePipelineandCodeBuildto handle the configuration and secrets.
- like we use
Q2: How did you structure your CI/CD pipelines?
A2:
- we use
Jenkinsfor managing all of our CI-CD pipelines. - And also, we also use the
Dockerfor handling those virtual servers. - And also use the
Kubernetesto orchestrate those virtual servers. - And each microservice has its pipeline. And it will be triggered by the git commit or merge, git merge event.
- And the pipeline contains many stages like build, test, and docker image build, and security scan, and deployment.
- it’s like we package it, we will package it into a docker image and push it into a docker image. And then we will deploy it to
Kubernetes, - and for staging(预发布环境) and production. We have the manual approval gates, and the blue, green deployments to ensure the zero downtime.
- we use the
PrometheusandGrafanato monitor the logs and the metrics for the deployment in real time.
Q1: What did your CI/CD pipeline look like, and how did you ensure safety?
A1:
- To make sure nothing broke, we locked down branches so you couldn’t merge unless all the checks passed and someone reviewed the code.
- For deploying to production, we needed manual approval first. We did canary releases (like rolling it out to a small group first) and set up auto rollbacks if the health checks failed.
- We also used feature flags(类似天谕的那种开关) so we could turn new features on/off without deploying new code, and ran quick smoke tests after deploying to catch problems early before users noticed.
Agile
AI
What is ETL?
ETL stands for Extract, Transform, Load.
It’s a common data integration process used to move and prepare data for analytics and machine learning:
- Extract: Pull data from source systems (e.g., databases, APIs, flat files).
- Transform: Clean, filter, enrich, or aggregate data into the desired format.
- Load: Store the transformed data into a target system, like a data warehouse or data lake.
In the context of AWS, ETL workflows are often orchestrated using tools like Glue and Step Functions.
Amazon SageMaker
A fully managed machine learning platform that:
- Trains and tunes ML models.
- Hosts models for real-time or batch inference.
- Handles model versioning, scaling, and A/B testing.
In projects, we use SageMaker to deploy trained models behind APIs or for batch inference jobs.
AWS Glue
A serverless ETL service that:
- Crawls and catalogs data from S3 or databases.
- Runs PySpark or Python jobs to transform data at scale.
- Integrates with Data Catalog and Athena for querying.
It’s used to automate and scale data preprocessing pipelines.
Amazon S3 (Simple Storage Service)
A durable object storage service that:
- Stores raw, processed, or intermediate data.
- Hosts model artifacts, training datasets, and logs.
- Acts as a data lake foundation in most pipelines.
It’s the main storage layer for both data and ML artifacts.
AWS Step Functions
A serverless orchestration service that:
- Coordinates tasks (e.g., Glue jobs, Lambda, SageMaker, etc.) into stateful workflows.
- Adds retry, timeout, and error handling logic to ETL and ML pipelines.
- Makes pipelines maintainable and scalable.
We use it to build and visualize complex, multi-step data or ML workflows.
Amazon API Gateway
A fully managed service for creating, securing, and scaling APIs:
- Exposes REST or WebSocket endpoints to external clients.
- Integrates with Lambda, Step Functions, or SageMaker endpoints.
- Handles rate limiting, logging, and authentication.
It’s commonly used to serve model predictions or expose backend services securely.
Q1: ML pipeline 架构与挑战
英文问法:
Can you walk me through the architecture of one of the ML inference pipelines you built with SageMaker and Step Functions? What were the challenges and how did you address them?
口语化英文回答:
- Sure. At Costco’s e-commerce division, we built an end-to-end ML pipeline for dynamic pricing.
- The data came from transactional logs, product metadata, and external signals like holidays or promotions.
- We used AWS Glue for cleaning and transforming raw data,
- and stored everything in S3, like training data, models, outputs, stored intermediate results in S3.
- SageMaker handled both training and hosting, host our real-time pricing models as endpoints.
- SageMaker endpoint 是指 Amazon SageMaker 提供的 托管模型服务接口,你可以将训练好的机器学习模型部署到这些 endpoints 上,让其他系统通过 HTTP 请求实时调用模型进行预测(inference),那还有必要用 aws api gateway 来暴露吗? SageMaker endpoint 偏内网内部调用, aws api gateway 有各种鉴权和各种复杂配置, 适合暴露给外网外部来调用
- Step Functions handled connect all the steps into a pipeline,
- and AWS API Gateway exposed the AI model endpoint to call from other services or frontend apps.
- This setup helped us keep latency low and made it easy to monitor.
- One key challenge was handling retraining without downtime.
- for retraining:
- I used the step functions to build a pipeline for the retraining and batch inference.
- And it Will pull the new data from
S3and then will run ETL process withGlue, and then we’ll retrain the model inSageMaker. And finally, will register the new version in themodel registry.
- And for the zero downtime,
- I used the blue - green strategy with SageMaker endpoints. and then We will test a small dataset and then gradually replace the old version with a new version.
- for retraining:
中文大意:
在 Costco 电商组,我们做了一个用于动态定价的端到端 ML 推理流程。数据来自交易日志、商品元数据和外部信号(比如节假日、促销)。我们用 Glue 做 ETL,每晚处理数据后存在 S3,再用 SageMaker 完成训练和批量推理,最后通过 Step Functions 串起整个流程,从数据准备到最终的 API 更新。
挑战是怎么实现不停机的模型更新,我们用了 SageMaker 的 endpoint 版本控制和流量切换功能,支持 A/B 测试,能在正式上线前先观察效果。
Q2: 模型版本管理与监控
英文问法:
How did you handle model versioning, deployment, and monitoring in production with SageMaker?
口语化英文回答:
- For versioning, We used SageMaker Model Registry for versioning. Every trained model would be registered with metadata like training date, dataset version, and evaluation metrics.
- For the deployment, we used the blue - green strategy with SageMaker endpoints. and then We will test a small dataset and then gradually replace the old version with a new version.
- For monitoring, we integrated CloudWatch with some metrics: response time, error rate, and prediction drift. If the model started drifting, we triggered Step Functions to retrain or roll back.
中文大意:
我们用 SageMaker 的模型注册系统管理版本,每个模型都记录了训练时间、数据集版本和评估指标。部署时采用蓝绿部署策略,先用 shadow traffic 验证模型,再逐步切换。
监控方面,我们接入了 CloudWatch,打了自定义指标(响应时间、错误率、预测分布漂移)。如果模型表现异常,就用 Step Functions 启动重训练或回滚。
Q3: 与数据科学/业务协同
英文问法:
How did you collaborate with data scientists and business stakeholders to align the ML models with pricing and demand forecasting goals?
口语化英文回答:
- We worked in a cross-functional team.
- Data scientists built the models and provided model assets like model files and config files.
- I helped wrap those into SageMaker training/inference pipelines and deployed them into staging and prod.
- On the business side, we Usually had some meetings with the business team to discuss the pricing strategy, and we also validate the model output with them
中文大意:
我们是跨职能团队合作的,数据科学家负责模型开发和交付 artifact(模型文件、配置),我这边负责用 SageMaker 包装流程并部署。
业务方面,我们每两周和定价经理、供应链分析师开会,确认模型输出符合业务逻辑,比如毛利率、库存限制等。上线后我们也有反馈机制,根据业务表现迭代模型。
React
Q0: What kind of front-end work did you do with React?
A0:
I built internal tools like a supply chain config portal with React and Redux. The portal allowed planners to adjust inventory thresholds, vendor settings, and replenishment logic in real-time.
Q1: What design principles did you follow when architecting the React UI for planners?
A1:
- Keep components small and focused on a single responsibility.
- like: Each planner action was encapsulated into modular components.
- Use props to make components configurable.
- we should write detailed Documentation for components
- We should follow the unidirectional data flow rule to make our components easier to debug and maintain.
Q2: How did you ensure UI responsiveness and reliability under real-time updates?
A2:
for responsiveness, I used
Media queries to adjust styles:
@media (max-width: 600px) {
.container { flex-direction: column; }
}Percentages or
vw/vhunits.vw(Viewport Width):表示视口宽度的百分比。1vw等于视口宽度的 1%。例如,如果视口宽度为 1000px,那么 10vw就等于 100px。vh(Viewport Height):表示视口高度的百分比。1vh等于视口高度的 1%。例如,在一个高度为 800px 的视口内,20vh就是 160px。vw和vh单位在响应式设计中非常有用,它们可以使元素的尺寸随着视口的大小变化而自动调整,从而提供更好的用户体验。例如,一个占满整个视口宽度的导航栏可以设置为宽度 100vw,这样无论用户如何调整浏览器窗口大小,导航栏都能始终保持在屏幕顶部并占据全部宽度。
- Flexbox/Grid for flexible layout.
- Responsive images using
max-width: 100%.
- for realtime update:
- debounced input handlers, to avoid extra re-render (在用户停止输入一段时间后,才触发处理逻辑。)
- optimistic UI updates, to make it looks really smooth (指在用户发起某个操作时,立即在界面上展示预期结果,不等待服务器响应)
- loading skeletons, to kept the UI responsive when we request some high-latency backend calls.
- for reliability, I used
- fallback error boundaries to To display fallback page To ensure the reliability.
React Hooks, Context API, and React Router
Q1: Why did you choose Context API over Redux for global state?
A1:
- Because for some simple situations, handling the global state is not a very difficult job. If there is no asynchronous workflow, we prefer the Context API to handle the global state because it’s lightweight and it’s native to React. So we prefer to use that for better performance.
- But for some more complicated global states, we prefer to use Redux with Redux-Saga.
Q2: How did you handle complex navigation flows across procurement tools using React Router?
A2:
- Yeah, so in one of our procurement platforms, we had pretty complex navigation flows
— like users jumping between purchase orders, vendor profiles, approval dashboards, and so on.- I used React Router to manage these routes. I broke down the app into nested routes so each tool or module had its own route structure, and I used dynamic routing when users clicked into specific records, like
/vendors/:id(读作vendors slash id) or/orders/:orderId.
- I used React Router to manage these routes. I broke down the app into nested routes so each tool or module had its own route structure, and I used dynamic routing when users clicked into specific records, like
React 中的**嵌套路由(Nested Routes)和动态路由(Dynamic Routes)**是前端路由设计的两个核心概念,通常结合使用,用于构建模块化、可复用、层次清晰的前端页面结构。
以下基于 react-router-dom v6 讲解,配合示例代码说明。
嵌套路由(Nested Routes)
嵌套路由是在父路由组件内部再定义子路由结构,实现页面组件之间的层级关系和布局复用。
使用场景:
- 页面有通用布局(如侧边栏、顶部导航)
- 子页面共用某些父级 UI 或逻辑
// App.jsx |
// Dashboard.jsx |
- 当访问
/dashboard/overview时,页面会先渲染Dashboard,然后在其中插入Overview。 Outlet是嵌套路由的插槽。
动态路由(Dynamic Routes)
动态路由使用 URL 参数(如 /users/:id)匹配路径,将变量传入组件,用于显示不同内容。
使用场景:
- 用户详情页(如
/users/123) - 商品详情页(如
/products/:sku)
// App.jsx |
// UserDetail.jsx |
访问 /users/42 页面时,输出:User ID: 42
二者结合使用示意
<Route path="/users" element={<UsersLayout />}> |
访问 /users/123 时:
- 渲染
UsersLayout作为外壳 - 通过
Outlet渲染UserDetail,并从useParams()中获取userId = 123
总结对比
| 概念 | 作用 | 示例路径 | 特点 |
|---|---|---|---|
| 嵌套路由 | 父子页面结构嵌套、共享布局 | /dashboard/settings |
使用 <Outlet /> 插入子组件 |
| 动态路由 | 路径中带变量 | /users/:userId |
用 useParams() 取值 |
Redux-Saga
Q1: Why did you choose Redux-Saga over Thunk or other middleware?
A1:
- because Redux-Saga is more powerful than Redux-Thunk.
- For example, if we want to implement debounce logic, throttle logic, or request cancellation, Redux-Saga natively supports ways to handle these patterns.
- And it also provides generator, so we can use it to write some logic in a synchronous way.
Q2: Can you describe a complex saga you implemented for supply planning?
A2:
- Sure — for supply planning, I wrote a saga to handle plan submission, it would trigger several async checks like inventory and vendor data
- I used debounce to prevent too many API calls when they are editing their plan,
- I used
takeLatest(the Redux natively way for request canceling) to cancel outdated tasks - Saga made it easier to manage all the async steps
Node.js
Q1: What kind of data consistency or concurrency issues did you encounter?
A1:
- One issue was with concurrent updates — like when multiple users tried editing the same procurement plan at the same time.
- Sometimes one user’s changes would overwrite another’s without warning.
- To fix that,
- on the backend: we added version checks and optimistic locking ,
- and on the frontend: we showed a warning if the data was stale.
Q2: How did you secure these APIs for real-time access?
A2:
We use middleware called express validation with the oauth2 and JWT to implement a role-based access control to make sure everything is safe
Tech stack version
java:
| 版本 | 使用场景 | 理由 |
|---|---|---|
| 2.7.x | 老项目主力版本 | 与 Java 8/11 兼容,无需 Jakarta 移植 |
| **3.1.2 | 新老项目并存(过渡阶段) | 支持 Java 17+,Jakarta 版本稳定 |
我们当前使用的版本:
| 技术组件 | 使用版本 | 说明与兼容性 |
|---|---|---|
| Java | 17 | Spring Boot 3.x 起步最低版本,LTS,兼容性好 |
| Spring Boot | 3.1.2 | 广泛使用的稳定版本,支持 Jakarta EE 9+ |
| Spring Framework | 6.0.11 | 与 Spring Boot 3.1.2 绑定发布(Spring 6 是强制依赖) |
| React | 18.2.0 | 当前最广泛使用的版本,支持 Concurrent Features,语法依赖 ES6 起始特性 |
| Node.js | 18.x LTS | ✅ 最广泛 |
| TypeScript | 5.2 | ✅ 推荐,生态广泛 |
| JavaScript 目标 | ES6 / ES2015+ | ✅ 默认标准 |
亚马逊 BQ 的核心规范
亚马逊(Amazon)的 BQ(Behavioral Questions,行为面试)规范可以概括为:基于 Leadership Principles 的结构化行为评估。它不只看你做了什么,更重视
- 你是怎么思考、
- 怎么做决策、
- 如何带人、
- 如何复盘的。
1. 所有问题都围绕 16 条领导力原则(Leadership Principles)展开
目前最新的是 16 条(2021 年后加入了 Strive to be Earth’s Best Employer 和 Success and Scale Bring Broad Responsibility)。
常考的包括:
- Customer Obsession(客户至上)
- Ownership(主人翁精神)
- Invent and Simplify(创新并简化)
- Are Right, A Lot(经常做出正确决策)
- Learn and Be Curious(好学好奇)
- Hire and Develop the Best(选拔和培养人才)
- Insist on the Highest Standards(追求卓越标准)
- Bias for Action(行动为先)
- Earn Trust(赢得信任)
- Dive Deep(深入细节)
- Have Backbone; Disagree and Commit(敢于争辩,服从大局)
2. 全部要求使用 STAR 框架作答
- Situation:场景
- Task:你的任务是什么
- Action:你具体做了什么
- Result:结果如何,是否量化
亚马逊特别看重:
- 是否主动承担了责任
- 是否挑战权威或流程
- 是否有深入分析和数据支撑
- 是否能推动结果,哪怕初始失败
3. 面试官每道题背后有明确的打分标准
BQ 回答的背后,面试官在评估:
- 是否符合所考察的 Leadership Principle
- 是否体现出高判断力、高执行力、高责任心
- 回答是否结构化、有数据、有深度
- 行为是否可复用,即是否代表“你经常这么做”,而不是“偶尔一次”
BQ 问题的提问方式和风格
亚马逊不会直接问“你有什么优点”这种问题,而是:
- Tell me about a time you had to make a difficult decision with incomplete data.
- Describe a situation where you took ownership beyond your role.
- Give me an example where you challenged a decision from your superior.
- Tell me about a time when you raised the quality bar on a project.
- Describe a time when you had to dive deep into a system failure.
BQ 回答注意事项
- 每个故事只讲一件事,结构清晰,突出你本人作用
- 用“我”,别用“我们”模糊责任
- 强调困难和你的应对思路,不仅仅是结果
- 回答完后,准备反问:“Would you like more detail on any part of this?”
面试建议
- 准备 6–8 个高质量 STAR 故事,分别匹配多个 leadership principles
- 每个故事最好能覆盖至少两个维度(如 Ownership + Dive Deep)
- 提前练习口头表达,精炼、干脆、有逻辑
- 提前准备5-6个万能故事,能改编套用到常见BQ上。什么领导力、冲突、失败、挑战全覆盖了。
- 所有回答都来个”三明治结构”:STAR+learnings
- 细节要具体,数字要有,但别太具体- 我们面试官根本不会去查证。“提升了30%”总比”提升了不少”有说服力。
- 永远别说是别人的错。哪怕真是队友坑了你,也得说”我应该更早干预”或”我沟通方式可以改进”。
Education
ysa
I’m using an EAD, which allows me to work full-time. It doesn’t require/need sponsorship, and it can be renewed forever/indefinitely. It’s just like a green card EAD, I can use it to work long-term.
if I say CPT
I have been working remotely from China for Netflix, Robinhood, and Costco. And Costco hoped that I would come to the U.S., so I came to the U.S. in October last year, and I’m still working for them using a CPT EAD. I’m currently studying at Trine University, which is a Day 1 CPT university.
I am currently on CPT EAD, which allows me to work legally up to 40 hours per week.
I’ll be graduating around the end of this year(in two months), and I’ll be able to switch to OPT after that. I still have about five to six months of CPT remaining.
(skip?) I should get my OPT in the next six months.
if I say OPT
TimeLine:
Georgia Tech Atlanta, GA, 2013 - 2017
Bachelor of Science in Computer Science
Georgia Tech Atlanta, GA, 2020 - 2021
Master of Science in Computer Science
Trine University Phoenix, AZ, 2024 - Present
Master of Science in Information Studies
- I graduated from Georgia Institute of Technology in 2017 and got my bachelor’s degree.
- I used CPT for 1 year
- and OPT for 3 years.
- Then I went to a Day1 CPT university
- and used Day1 CPT for 3 years.
- After that, I returned to Georgia Tech and got my master’s degree in 2024.
- I used CPT for 1 year,
- and now I’m on OPT.
Robinhood
duty
- Before that, And I’ve also got experience in the financial industry directly, when I was at Robinhood,
- They have a tech team in Denver
/ˈdenvər/, Colorado/ˌkɑːləˈrædoʊ; / - I was in an online trading team.
- the project was a stock trading platform. I developed real-time market data pipelines, designed secure APIs for stock platform.
- We used Kafka to handle the data streams, and I focused on making sure the pipeline was low-latency and reliable, because any delay could affect trading decisions.
- I also helped design secure APIs for the trading platform, like for showing real-time prices, historical charts, and user portfolio data.
- and for a financial company, Security and stability were a big deal, so we built in access control, authentication, rate limiting, and monitoring to make sure the system ran smoothly.
challenge
…
Summary
Q0: Describe the backend architecture for real-time trading.
A0:
- OK. We use Java and Spring Boot to build a scalable micro services architecture.
- Yeah, and we also use the Kafka for the real time event streaming to build an event driven architecture to handle the order processing and to build a high high throughput data stream to handle live market quotes and trade executions
- Yeah, and for database we use the post SQL for the account and trade data,
- and we also use Redis to cache the hot data.
- Oh, we also use the GCP cloud services like the Compute Engine to. Deploy those venture servers to do the load balancing, and to use it’s auto scaling. Yeah, also to do the front tolerance.
- And our a C I/C d. Pipeline,
- it’s like we use Jenkins to build the pipeline
- and also we use Docker to deploy the virtual server.
- And Kubernetes is the orchestration. Those virtual servers.
- Yeah. And we use the Prometheus to extract data, and then export those data to the Grafana to do the data visualization and to monitor the citizen health and metrics and logs.
Q2: What design patterns did you use in your backend service architecture?
A2:
- OK, the design pattern we use like the
single pattern. Yeah, for the shared resources like the database collection pools and configuration managers. - And we also use a
factory pattern. Yeah, to recap the instantiation logic. - And also we use the
proxy pattern. Yeah, to create some proxy for the security checks and logging. - And also, we use the
observer pattern, yeah, to implement like a subscriber system. Yeah, the is like a mass system. To trigger some downstream sources, when I order is completed.
Q3: How did you handle consistency between portfolio data and market feeds?
A2:
- We used Kafka to decouple market data processing and portfolio updates.
- and We made the consumer services idempotent, so when we handle the versioning, we just need to ensure eventual consistency.
Non-blocking WebClient
It is an asynchronous, non-blocking HTTP client provided by Spring WebFlux. Unlike the traditional RestTemplate, WebClient uses Reactor (a reactive library) under the hood and leverages Netty or other non-blocking runtimes to handle I/O without blocking threads. This allows handling many concurrent requests efficiently. You typically create it via:
WebClient webClient = WebClient.create(); |
Requests return a Mono or Flux, representing asynchronous responses.
Gatling
Gatling is a high-performance load testing tool designed for simulating thousands of users and measuring system behavior under stress. It’s scriptable (in Scala), lightweight, and often used to model realistic traffic spikes, such as market open surges in trading systems.
Why offload critical paths using Kafka?
In high-throughput systems, some operations (like logging, auditing, or risk checks) can slow down the main request flow. We use Kafka to asynchronously handle these tasks by sending events to topics, which backend consumers process separately. This decouples the critical real-time path, reducing latency and improving scalability.
Spring WebFlux
Spring WebFlux is a reactive, non-blocking web framework introduced in Spring 5. It supports building asynchronous web applications with backpressure and event-driven programming. WebFlux uses Mono and Flux types to represent 0–1 and 0–many asynchronous values, respectively, enabling highly scalable and resource-efficient servers.
GCP & CI/CD
Q0: What role did GCP play in your architecture?
A0:
- we use gcp compute engine yeah to deploy our virtual servers
- We used the
GKE(Google kubernetes engine) to orchestrate our virtual servers - And for secrets and config management, we use the
secret manager and cloud storage. - And also we use
cloud buildfor our CI/Cd Pipeline for some parts like supporting thesecret manager and cloud storage, Jenkins is still our main CI/CD tool to work with some old integration, like code analysis - Yeah, and we use the
cloud monitoring and loggingto check our service health and latency. Error rate
Q1: How did you handle configuration and secrets in your pipeline?
A2:
In our GCP-based setup,
- when Cloud Build is triggered (e.g., like there is a Git push).
- Cloud Build uses Workload Identity to access Secret Manager.
- Secret Manager provides sensitive values, such as database passwords or API tokens.
- Cloud Build fetches configuration files (e.g.,
prod-config.yaml) from Cloud Storage. - The build process injects configs and secrets into the container image and then deploys it to the GKE
Q2: How did you configure your services to auto-scale under high load?
A2:
In our GCP-based setup, we configure the policy, the configuration about the auto scaling based on the CPU to handle the high load.
- For stateless services, it was simple to
scale-out横向扩展, it will automatically add more instances as needed. - Yeah, but for the stateful services like quote caching. , we use the shell Redis cluster. To ensure the consistency across services.
Cloud Build
- 用途:GCP 的托管 CI/CD 工具,用于构建、测试、部署代码。
特点:
- 与 GitHub、GitLab、Cloud Source Repositories 集成
- 支持构建步骤(如 Docker 构建)、环境变量注入、并行构建
- 可以通过 IAM 授权访问 Secret Manager 读取密钥
使用 secrets 示例(
cloudbuild.yaml):secrets:
- kmsKeyName: projects/my-project/locations/global/keyRings/my-kr/cryptoKeys/my-key
secretEnv:
DB_PASSWORD: projects/my-project/secrets/db-password/versions/latest
Workload Identity
- 用途:为 GCP 服务(如 Cloud Build、GKE Pod)提供安全的身份,让它们不需要使用明文服务账号密钥。
特点:
- 实现 服务之间的安全访问控制
- 用 IAM 精准控制谁能访问哪些资源(如 Secret Manager)
- 比 service account key 更安全(不落盘、不暴露)
应用场景:
- Cloud Build 获取 Secret Manager 中的密钥
- GKE Pod 访问 GCS、BigQuery、Firestore 等
Cloud Storage (for non-sensitive config)
- 用途:存储 YAML、JSON 等非敏感的配置文件,例如环境配置、构建参数等。
特点:
- 可以在 CI/CD 阶段下载配置并注入应用
- 配合 Signed URL 或 IAM 权限管理可实现按需访问
Secret Manager
- 用途:安全存储敏感信息,例如数据库密码、API Key、证书等。
特点:
- 数据自动加密(使用 Google-managed KMS 或自定义 KMS key)
- 支持版本控制、自动轮换、审计日志
- 可通过 Cloud Build、Cloud Run、GKE、Cloud Functions 动态注入
CLI 示例:
gcloud secrets versions access latest --secret=DB_PASSWORD
流程示意
- Cloud Build 被触发(通过 Git push)
- 使用 Workload Identity,Cloud Build 获得访问 Secret Manager 的权限
- Secret Manager 提供敏感信息(如 DB 密码、API Token)
- Cloud Build 下载配置文件(如
prod-config.yaml)从 GCS - 构建镜像,注入配置与密钥,并部署到目标环境(如 Cloud Run、GKE)
KAFKA
Q0: Describe your use of Kafka.
A0:
- Oh, we used Kafka to handle the markets Quote And user orders in real time,
- and I builds consumer services To handle the events and also to handle the trade execution .
- Yeah, we used it to build a event driven architecture to handle the data streams, to handle the high throughput data streams and the messaging system.
- Yeah, also we use it to decouple those micro services to make the communication from the sync way to the a async way. Yeah, so. So that’s the way we implement the real time processing.
Q1: What were the key design considerations when building your Kafka pipeline?
A1: Latency, ordering, and fault tolerance. We used compacted topics for quote updates and partitioned topics by instrument ID for order executions. Consumers had exactly-once semantics via transactional reads and offset commits.
I Think it’s exactly one semantics and fault tolerance.
- To implement the exactly one semantics,
- we need to implement the transactional producer. Yeah, and also we need to. Implement the consumer in the transactional way,
- like we need to handle the transaction operation, and we also need to do the manual offset commits , like operation so we need to handle the failures like the if some transactions failed we need to roll back。
- for fault tolerance
- We use the dead letter queue if some message was process unsuccessfully. We can just monitor the data queue and then we can extract the messages from the queue, and then we can. Do some analysis for them also we can debug or we can fix some bugs or we can reprocess the message. Yeah.
Spring Security, OAuth2, and JWT
Q0: How did you ensure API security?
A0: I Built REST APIs with Spring Security, JWT for user sessions to implement role-based authorization, and OAuth2 for third-party integrations.
Q1: How did you design your API’s security model for trading-related operations?
A1:
- I used Spring Security with JWT and oauth2, and then use the annotation
PreAuthorizeto implement method-level access control based on those roles. - For order placement,
- we required 2FA(Two-Factor Authentication) tokens
- and we also implemented a Redis-based OTP(One-Time Password) service.
("hasRole('ADMIN')") |
Q2: How did you handle JWT expiration and refresh in real-time systems?
A2:
Because we use shorter lived JW t for security, so we implement a refresh token flow. Yeah, that is the front end stored the refreshed token. In the cookies and when the assess token expired. It will automatically request a new one.
PostgreSQL and Redis
Q0: Tell me about your database optimizations.
A0:
- for sql:
- I created indexes on frequently joined columns, changed some LEFT JOINs to INNER JOINs .This way, we stop getting data we don’t need.. We also used read replicas for reporting queries (报表类查询(如导出数据、生成分析报表)通常读的数据多但不需要最新的写入结果。) during peak hours
- For MongoDB:
- I used compound indexes and also designed some schemas to match a set patterns like embedding documents for fast reads. We also do some pageant pagination for those large results sets.
- For Redis:
- We used Redis to cache some hot data like: order book snapshots(订单簿快照).
Q2: How was Redis used in your system, and what issues did you face?
A2:
- we mainly use Redis to cache some hot data online like old book order, book snapshot.
- One challenge is the memory pressure. Because the order broker can grow a very quickly during the peak load, so we have to tune the Redis policy like we use the LRU policy, to make sure we were keeping the most relevant data in memory.
- Oh, we also notice that we stored too many different types of data in the same Redis instance. Yeah, so we. So we isolate those data. Across different Redis instance.
Monitoring
Q0: How did you monitor trading system health?
A0:
- We use the Prometheus and Grafana and also we use a GCP cloud monitoring and logging.
- To check the latency,
- P50(50th percentile):中位数,表示一半请求的延迟低于这个值。反映正常负载下的平均性能。
- P95(95th percentile):表示95% 的请求延迟低于这个值,但有 5% 的请求更慢。适合衡量系统在接近压力边界时的表现。
- P99(99th percentile):表示99% 的请求都比这个快,是衡量极端场景(如高并发下尾部请求)的关键指标。
- and also to check the order rejection rates
- and to see the system health,
- and also to check the metrics to make sure we can satisfy the financial SLA(Service-Level Agreement) requirements.
- Kafka lag,
- Redis hit ratio,
- and API error rates
- To check the latency,
- we configured the Alerts with Slack integrations. So if there is a mistake, we can get an alert to fix that.
翻译:所以如果出现错误,我们可以收到警报来解决它。
在 Robinhood 这样的金融科技公司中,SLA(Service-Level Agreement) 通常指的是对某个服务或系统在可用性、性能和响应时间等方面的明确承诺或内部目标。虽然“Agreement”在外部是客户协议,但在 Robinhood 内部,SLA 多用于 系统可靠性和业务关键性指标的设定与监控。
Q2: How did you debug latency spikes during market open(开盘) or earnings hours(财报发布时段)?
A2:
- We used distributed tracing (OpenTelemetry
/ təˈlemətri /) to track slow spans(span 表示一次操作的时间片段), and Check if the spikes happened at the same time as high CPU or memory usage.- OpenTelemetry n. [自] 遥测技术;遥感勘测;自动测量记录传导,
- OpenTelemetry是openTracing的继任者
- and used Grafana’s heatmaps to identify hot services.
- We also use JProfiler to do GC tuning and thread pool analysis.
REACT and Node.js
Q0: What frontend work did you do with React?
A0:
- I built portfolio dashboards and order placement UIs.
- Used WebSockets and polling for real-time trading data.
- Focused on responsive design and performance optimization for market data visualization and user portfolio
Q1: (CHALLENGE)How did you optimize the React frontend for real-time data visualization?
A1:
- One big CHALLENGE was handling real-time state with live market data and ensuring that the UI stayed responsive and correct.
- so I used
React.memoto make sure components only refresh when their props actually change, - and
useCallbackto keep functions from changing so their child components don’t reload unnecessarily. This stopped extra refreshes and boosted performance. - I also used
useMemoto store complex calculations, so they don’t repeat every time the screen updates. - When dealing with complicated state (especially for live data), I used
useReducerinstead ofuseStateto keep the state logic clean. That prevented messy updates that could trigger extra refreshes. - For live data, I used WebSockets to connect and added a “throttling” feature to limit how often the UI gets updates. This kept the app smooth and prevented it from crashing.
- All these changes made the UI fast and responsive, even with constant data coming in.
Netflix
duty
- Yeah, they’ve got an office in Midtown Manhattan
/mæn'hæt(ə)n/, New York City. - I spent 2 years at Netflix,
- I was part of the recommendation team.
- the project was a consumer engagement platform.
- where I built high-throughput, low-latency backend services to support real-time content recommendation and consumer engagement across platforms.
- Netflix was doing research to predict what users will like based on their age and their gender and some kinds of their personal information.
- And we also used a large model to make these predictions. For example we use their location data subscribe information and watch history as input and then the model will decide what should be shown to the user.
- And my job was to develop some services to handle the user data in real time. We wanted to make sure the personalized content immediately whenever a user’s actions changed.
- We also developed a microservices architecture to handle millions of users and tools like Kubernetes to ensure its scalability.
- that’s pretty much what I did, I read very carefully about this job description, I think this position is a perfect match for me .
Adobe
duty
- I spent 2 years at Adobe,
- Their main office is in San Jose
/sænhəu'zei/, California. - (optional) i was remote in Adobe,
- I was in a Collaboration Services Team. I developed backend microservices using Spring Boot to support video conferencing, chat, and collaboration features.
- the project was a Collaboration Platform.
- we developed backend microservices using Spring Boot to support video conferencing, chat, and collaboration features.
- like Users can start or join scheduled video meetings with a single click,
- and Users can send direct messages or participate in group chats while in a meeting
- During a video chat, users can edit documents together at the same time using the collaboration features
- My main responsibility was designing and building RESTful APIs to handle session management, user presence, messaging, and collaboration events.
fulltime job BQs
- ~ 宁可保守表达,也不要踩雷。很多时候,过于强调自己的“领导力”或“功劳”反而让 HM 产生反感。要多用“we”,少用“我一个人搞定”;强调合作,而不是独自英雄主义。
- ~ 别一兴奋就一直说。面试是双向交流,不是演讲。说多了容易暴露短板、绕远路,反而让人觉得你控制力不足。
- ~ 倾听,有时候比表达更关键。真正成熟的沟通,往往体现在你能否听懂对方的关注点,并围绕它精准回应。所以,当我们准备 Behavioral、HM 面 或系统设计时,不妨更多地从“对方角度”出发,理解他们在乎什么、担心什么、欣赏什么,而不是一味展示自己。
下面是一些我碰到的面试问题:
- ~ Tell me about a time you worked on a team project.
- ~ If your boss tell you 1+1=3 and ask you to continue working on it. What would you do?
- ~ Describe a situation where you had to work with a difficult teammate.
- ~ How do you handle disagreements in a team?
- ~ Give an example of how you contributed to a team’s success.
- ~ Tell me about a difficult problem you faced and how you solved it.
- ~ How do you prioritize multiple tasks when deadlines are tight?
- ~ Tell me about a time you worked under significant pressure.. 1point 3 acres
- ~ Describe a time when you led a project or initiative.
- ~ How do you handle taking on responsibilities outside your job description?
- ~ What are you most proud of professionally?
- ~ Tell me about a time when you set and achieved a challenging goal.
Pilot Training Questions
How to Answer a Corp-to-Corp Vendor’s Call?
Vendor: May I talk with ZhangSan?
You: Yes, this is ZhangSan. What can I do for you ?
Vendor: Hi ZhangSan, how are you today?
You: I’m good, thanks! How about you?
Vendor: I’m [Name] from [Company]. Are you looking for a Java Developer/Full Stack Developer position?
You: Yes! May I know if your position is a Corp to Corp (C2C) position?
(If Vendor says “No, it’s W2”)
You: Does your company have any Corp to Corp opportunities?
• If “No” → End the conversation: I have an employer and I’m only looking for C2C opportunities. Thanks for your time!
• If “Yes” → Continue the discussionYou: Is this position remote or onsite?
Vendor: It’s onsite.
You: May I know the location?
(If the location is your current city)
You: I’m local to that area.
(If relocation is needed)
You: I have no problem with relocation.
Vendor: What visa are you on?
You: [Answer according to mock discussions]
Vendor: What is your expected rate?
You: The rate needs to be discussed with my employer.
Vendor: Understood. I’ll send you the job description/RTR over email.
(If Vendor does not mention email, you ask first)
You: May I know if you have sent an email to my email ID?
(If received, confirm)
You: I received it. I will reply shortly. I will also provide my employer’s phone number and email ID, so please discuss the rate and send rate confirmation to them.
(If not received, request it)
You: Please send it over, and I will reply once I receive it. I will also provide my employer’s phone number and email ID for rate discussion.
Email Follow-Up:
• If they need a Bench Sales Contact, you can provide:
This is my bench sales contact, Edward.
• Phone: 2017246910
• Email: jade@pilottechnologies.net
opening
- how are you doing?
- I’m in San Diego right now.
- I’m currently based in San Diego.
- I’m totally comfortable with relocation.
- Yes, I’m definitely open to relocating to Florida. I’ve always liked the vibe there — the beaches, the palm trees, the warm weather — it’s a place I’d genuinely enjoy living in.”
- I’m definitely open to the West Coast. I’ve always liked the mix of tech and nature — like being close to the ocean or mountains is pretty awesome.
- Yeah, I’d be cool with moving to the East Coast. I kind of enjoy having all four seasons.
- Yeah, I’m open to the Midwest. I’ve heard
Austin and Denverhave a great food and music scene — I think I’d really enjoy living there.
- Yes, I’m definitely open to relocating to Florida. I’ve always liked the vibe there — the beaches, the palm trees, the warm weather — it’s a place I’d genuinely enjoy living in.”
- when interviewer is late:
- They might say: Sorry, I’m late
- u can say: no worries.
- That’s totally fine. I was a little anxious when I first joined and waited for a while, but now I’m feeling much more relaxed now It’s a good thing.
- No problem at all, I completely understand. I really appreciate you taking the time to speak with me today. I’m looking forward to our conversation.
- They might say: Sorry, I’m late
when their audio was breaking up or not coming through clearly
I think u were cutting out.
Is this a very common saying in america?
Yes, “cutting out” is a very common and natural expression in American English, especially during phone or online voice/video calls.
You’ll often hear people say:
- “You’re cutting out.”
- “I think you cut out for a second.”
- “Can you hear me? You were cutting in and out.”
These phrases are used to describe intermittent audio loss or unstable connection. They’re informal but widely used in both casual and professional settings.
Location
- Most of the time I stay in San Jose, but I often come to Arizona to help my sister take care of her baby.
- I don’t know how to drive yet, and I usually live close to the office, I usually go to work by Uber or bus or just walking.
- many people said that The driving test in California is more difficult than Arizona, and my sister suggested that I take the test in Arizona,
my brother-in-law is teaching me how to drive, and I got my driver’s permit here in Arizona.