Meta-Tag LeetCode Problems list is the best list in the U.S.
References
- https://productive-horse-bb0.notion.site/Meta-2021-11-2022-2-3052cadfe0584f8fbda57c86a56663fe?p=46de9980e1d44c41ae81f87e2a9aadc7&pm=s
- https://www.notion.so/1557653f2b3080d69303d3eae198d88c?v=1557653f2b3081d7b483000c06e42acf
Meta面经1
补充内容 (2024-09-11 09:55 +08:00):
今天面完了5轮onsite,3 coding + bq+ sd,下面是面试前我自己整理的地理面经(3月到现在),onsite和电面的题目全在里面。如果时间不多,1~2个月内就面试,你看这一个帖子差不多就够了
面senior的别担心算法,出的题目都是看一眼就知道答案。几年前拿过meta offer,当时还被面了2轮hard,现在算法要求降低很多。
algo
算法题目,下面是leetcode题号:
- 1 - 100: 7, 19, 21, 23, 26, 31, 34, 39, 43, 50, 56, 60, 62, 65, 71, 76, 79, 88
- 101 - 200: 116, 121, 125, 127, 129, 133, 138, 140, 146, 162, 190, 199, 200
- 201 - 400: 207, 210, 215, 219, 224, 227, 236, 249, 266, 283, 295, 301, 314, 317, 332, 339(不是给List,而是给字符串,可以用stack解题), 346, 347, 380
- 401 - 1000: 408, 426, 435, 437, 438, 443, 447, 494, 499, 523, 528, 543, 560, 658, 680, 721, 739(单调栈的典型应用 www.geeksforgeeks.org), 791, 827, 934, 938, 973, 986, 987
- Above 1000: 1004, 1047, 1060, 1091, 1123, 1161, 1209, 1216, 1249, 1382, 1539, 1570, 1644, 1650, 1762, 1778
sd
- Design a chess game, 要求可以撤回上一步
- 游戏leaderboard,需要有global&friends排名。这题准备过 但是面试官侧重点是怎么去sort我是没想到的
- 需要返回当前整个游戏的top N player、当前用户的前后N个player
- 返回当前用户朋友的top N player、当前用户朋友的前后N个player
- Hacker version Web crawler
- 有一些限定条件,比如说一万台机器,尽可能让每台机器的load evenly distributed。
- Design an Ads Aggregation System (广告点击)
- facebook 評論系統: user1 看到某個post1, user1 write comment, user2 看到post2, write comment, 同時要通知user1
- design zoom
- Design instagram
- Design ig auction: 设计一个auction system。 用户可以view current bid price 然就可以bid with higher price。 主要问了如果bid at same price 怎么解决conflict。以及怎么scale一个很hot的auction。
- ig newsfeed, 怎么处理new post来通知用户的情况
- design dropbox. 全程drive对话,自己说哪里是bottleneck,如何解决,面试官的问题都回答上了,后期dive in主要着重于how to chunk large file in detail, get updated file list 的时候如何提高performance,get updated file list的时候有什么edge case吗,如何解决。面试官最后looking very good。
- 设计一个抢票系统
- trending hashtags: Top K 问题
- 设计post的隐私设置
- proximity service
- price tracker
- design camel camel camel
- Ticketmaster
- deep dive facebook news feed API 包括pagination.. 如何实现at一个人等
- design Spotify
- Design hotel booking system.
- 设计一个streaming service: 需要支持video play、recommendation、subscription
- Presence indicator
- 设计google map中,选择一个地点,可以拖拽看到周围街景的那个功能。主要问了问怎么hash longtitude/latitude,看看alex xu绿皮书Google map那一章会有帮助。以及如何降低latency,如何存储image等等。
- metrics monitoring
- youtube
- LeetCode contest platform
bq
- conflict with others, xfn conflict
- biggest mistake
- have you ever broke prod code
- most proud project
- difficult working relationship
- conflict when you are right, conflict when you are wrong
- feedback from manager: negative feedback, critical feedback you received
- What did you learn from your tech lead, what do you want to improve?
- 多个task同时进行的时候怎么协调
Misc
lc339-Nested List Weight Sum
- difficulty: Medium
- tags:
- Depth-First Search
- Breadth-First Search
- https://leetcode.com/problems/nested-list-weight-sum
- https://github.com/doocs/leetcode/blob/main/solution/0300-0399/0339.Nested%20List%20Weight%20Sum/README_EN.md
You are given a nested list of integers nestedList. Each element is either an integer or a list whose elements may also be integers or other lists.
The depth of an integer is the number of lists that it is inside of. For example, the nested list [1,[2,2],[[3],2],1] has each integer’s value set to its depth.
Return the sum of each integer in nestedList multiplied by its depth.
Example 1: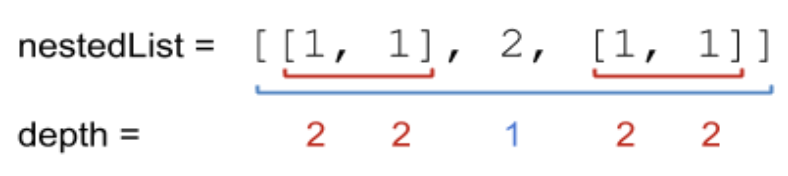
Input: nestedList = [[1,1],2,[1,1]]
Output: 10
Explanation: Four 1's at depth 2, one 2 at depth 1. 1*2 + 1*2 + 2*1 + 1*2 + 1*2 = 10.
Example 2: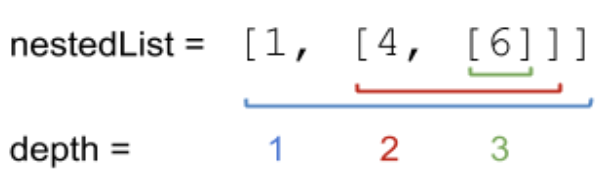
Input: nestedList = [1,[4,[6]]]
Output: 27
Explanation: One 1 at depth 1, one 4 at depth 2, and one 6 at depth 3. 1*1 + 4*2 + 6*3 = 27.
Example 3:
Input: nestedList = [0]
Output: 0
Constraints:
- 1 <= nestedList.length <= 50
- The values of the integers in the nested list is in the range [-100, 100].
- The maximum depth of any integer is less than or equal to 50.
Solutions:
1 | /** |
Array
lc1762-Buildings With an Ocean View
- difficulty: Medium
- tags:
- Stack
- Array
- Monotonic Stack
- https://leetcode.com/problems/buildings-with-an-ocean-view
- https://github.com/doocs/leetcode/blob/main/solution/0200-0299/0249.Group%20Shifted%20Strings/README_EN.md
There are n buildings in a line. You are given an integer array heights of size n that represents the heights of the buildings in the line.
The ocean is to the right of the buildings. A building has an ocean view if the building can see the ocean without obstructions. Formally, a building has an ocean view if all the buildings to its right have a smaller height.
Return a list of indices (0-indexed) of buildings that have an ocean view, sorted in increasing order.
Example 1:
Input: heights = [4,2,3,1]
Output: [0,2,3]
Explanation: Building 1 (0-indexed) does not have an ocean view because building 2 is taller.
Example 2:
Input: heights = [4,3,2,1]
Output: [0,1,2,3]
Explanation: All the buildings have an ocean view.
Example 3:
Input: heights = [1,3,2,4]
Output: [3]
Explanation: Only building 3 has an ocean view.
Constraints:
- 1 <= heights.length <= 105
- 1 <= heights[i] <= 109
Solutions:
1 | class Solution { |
lc163-Missing Ranges
- difficulty: Easy
- tags:
- Array
You are given an inclusive range [lower, upper] and a sorted unique integer array nums, where all elements are within the inclusive range.
A number x is considered missing if x is in the range [lower, upper] and x is not in nums.
Return the shortest sorted list of ranges that exactly covers all the missing numbers. That is, no element of nums is included in any of the ranges, and each missing number is covered by one of the ranges.
Example 1:
- Input: nums =
[0,1,3,50,75], lower = 0, upper = 99 - Output:
[[2,2],[4,49],[51,74],[76,99]] - Explanation: The ranges are:
[2,2][4,49][51,74][76,99]
Example 2:
- Input: nums =
[-1], lower = -1, upper = -1 - Output:
[] - Explanation: There are no missing ranges since there are no missing numbers.
Constraints:
- -109 <= lower <= upper <= 109
- 0 <= nums.length <= 100
- lower <=
nums[i]<= upper - All the values of nums are unique.
We can simulate the problem directly according to the requirements.
The time complexity is O(n), where n is the length of the array nums. Ignoring the space consumption of the answer, the space complexity is O(1).
1 | class Solution { |
LinkedList
lc708-Insert into a Sorted Circular Linked List
- difficulty: Medium
- tags:
- Linked List
- https://leetcode.com/problems/insert-into-a-sorted-circular-linked-list
- https://github.com/doocs/leetcode/blob/main/solution/0700-0799/0708.Insert%20into%20a%20Sorted%20Circular%20Linked%20List/README_EN.md
Given a Circular Linked List node, which is sorted in non-descending order, write a function to insert a value insertVal into the list such that it remains a sorted circular list. The given node can be a reference to any single node in the list and may not necessarily be the smallest value in the circular list.
If there are multiple suitable places for insertion, you may choose any place to insert the new value. After the insertion, the circular list should remain sorted.
If the list is empty (i.e., the given node is null), you should create a new single circular list and return the reference to that single node. Otherwise, you should return the originally given node.
Example 1:
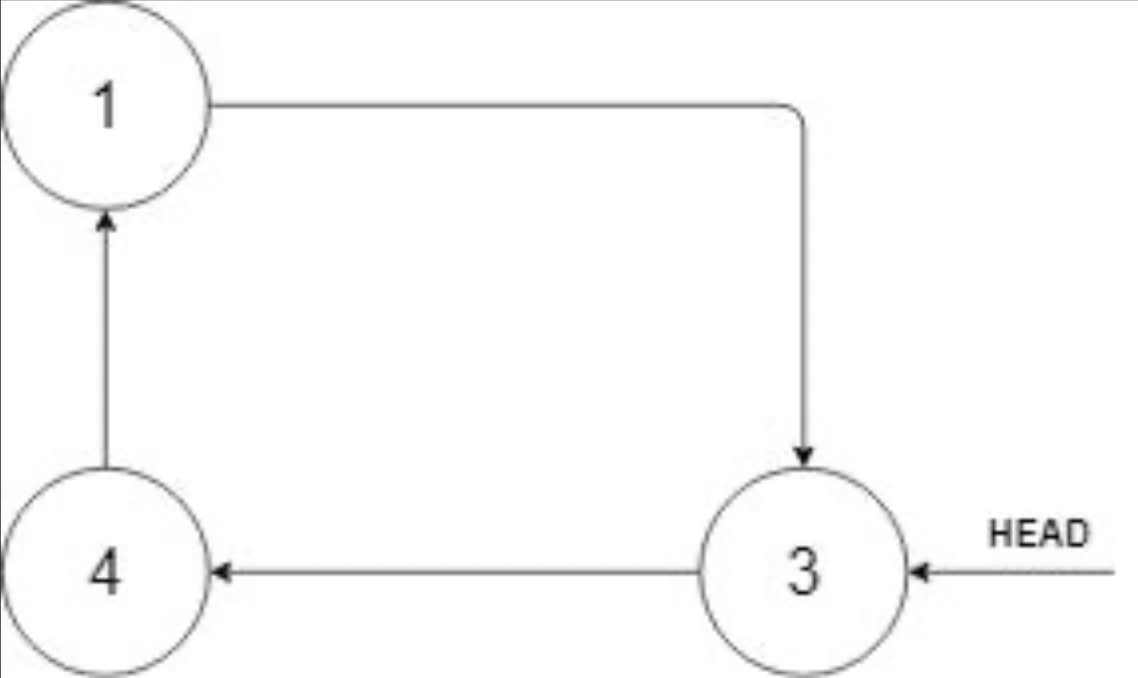
- Input: head =
[3,4,1], insertVal = 2 - Output:
[3,4,1,2] - Explanation: In the figure above, there is a sorted circular list of three elements. You are given a reference to the node with value 3, and we need to insert 2 into the list. The new node should be inserted between node 1 and node 3. After the insertion, the list should look like this, and we should still return node 3.
Example 2:
- Input: head =
[], insertVal = 1 - Output:
[1] - Explanation: The list is empty (given head is null). We create a new single circular list and return the reference to that single node.
Example 3:
- Input: head =
[1], insertVal = 0 - Output:
[1,0]
Constraints:
- The number of nodes in the list is in the range
[0, 5 * 104]. -106 <= Node.val, insertVal <= 106
Solutions
1 | /* |
HashMap
lc266-Palindrome Permutation
- difficulty: Easy
- tags:
- Bit Manipulation
- Hash Table
- String
Given a string s, return true if a permutation of the string could form a palindrome and false otherwise.
Example 1:
- Input: s = “code”
- Output: false
Example 2:
- Input: s = “aab”
- Output: true
Example 3:
- Input: s = “carerac”
- Output: true
Constraints:
- 1 <= s.length <= 5000
- s consists of only lowercase English letters.
Solutions:
If a string is a palindrome, at most one character can appear an odd number of times, while all other characters must appear an even number of times. Therefore, we only need to count the occurrences of each character and then check if this condition is satisfied.
Time complexity is O(n), and space complexity is O(|\Sigma|). Here, n is the length of the string, and |\Sigma| is the size of the character set. In this problem, the character set consists of lowercase letters, so |\Sigma|=26.
1 | class Solution { |
lc249-Group Shifted Strings
- difficulty: Medium
- tags:
- Array
- Hash Table
- String
- https://leetcode.com/problems/group-shifted-strings
Perform the following shift operations on a string:
Right shift: Replace every letter with the successive letter of the English alphabet, where 'z' is replaced by 'a'. For example, "abc" can be right-shifted to "bcd" or "xyz" can be right-shifted to "yza".
Left shift: Replace every letter with the preceding letter of the English alphabet, where 'a' is replaced by 'z'. For example, "bcd" can be left-shifted to "abc" or "yza" can be left-shifted to "xyz".
We can keep shifting the string in both directions to form an endless shifting sequence.
For example, shift "abc" to form the sequence: … <-> "abc" <-> "bcd" <-> … <-> "xyz" <-> "yza" <-> …. <-> "zab" <-> "abc" <-> …
You are given an array of strings strings, group together all strings[i] that belong to the same shifting sequence. You may return the answer in any order.
Example 1:
Input: strings = ["abc","bcd","acef","xyz","az","ba","a","z"]
Output: [["acef"],["a","z"],["abc","bcd","xyz"],["az","ba"]]
Explanation: "az" can be left-shifted to "ba"
Example 2:
Input: strings = ["a"]
Output: [["a"]]
Constraints:
- 1 <= strings.length <= 200
- 1 <= strings[i].length <= 50
- strings[i] consists of lowercase English letters.
Solutions:
We use a hash table g to store each string after shifting and with the first character as ‘a‘. That is, g[t] represents the set of all strings that become t after shifting.
We iterate through each string. For each string, we calculate its shifted string t, and then add it to g[t].
Finally, we take out all the values in g, which is the answer.
The time complexity is O(L) and the space complexity is O(L), where L is the sum of the lengths of all strings.
1 | class Solution { |
lc1570-Dot Product of Two Sparse Vectors
- difficulty: Medium
- tags:
- Design
- Array
- Hash Table
- Two Pointers
Given two sparse vectors, compute their dot product.
Implement class SparseVector:
SparseVector(nums) Initializes the object with the vector numsdotProduct(vec)Compute the dot product between the instance of SparseVector and vec
A sparse vector is a vector that has mostly zero values, you should store the sparse vector efficiently and compute the dot product between two SparseVector.
Follow up: What if only one of the vectors is sparse?
Example 1:
Input: nums1 = [1,0,0,2,3], nums2 = [0,3,0,4,0]
Output: 8
Explanation: v1 = SparseVector(nums1) , v2 = SparseVector(nums2)
v1.dotProduct(v2) = 1*0 + 0*3 + 0*0 + 2*4 + 3*0 = 8
Example 2:
Input: nums1 = [0,1,0,0,0], nums2 = [0,0,0,0,2]
Output: 0
Explanation: v1 = SparseVector(nums1) , v2 = SparseVector(nums2)
v1.dotProduct(v2) = 0*0 + 1*0 + 0*0 + 0*0 + 0*2 = 0
Example 3:
Input: nums1 = [0,1,0,0,2,0,0], nums2 = [1,0,0,0,3,0,4]
Output: 6
Constraints:
- n == nums1.length == nums2.length
- 1 <= n <= 10^5
- 0 <= nums1[i], nums2[i] <= 100
Solutions:
1 | class SparseVector { |
Queue
lc346-Moving Average from Data Stream
- difficulty: Easy
- tags:
- Design
- Queue
- Array
- Data Stream
Given a stream of integers and a window size, calculate the moving average of all integers in the sliding window.
Implement the MovingAverage class:
MovingAverage(int size) Initializes the object with the size of the window size.double next(int val) Returns the moving average of the last size values of the stream.
Example 1:
Input:
["MovingAverage", "next", "next", "next", "next"]
[[3], [1], [10], [3], [5]]
Output:
[null, 1.0, 5.5, 4.66667, 6.0]
Explanation:
MovingAverage movingAverage = new MovingAverage(3);
movingAverage.next(1); // return 1.0 = 1 / 1
movingAverage.next(10); // return 5.5 = (1 + 10) / 2
movingAverage.next(3); // return 4.66667 = (1 + 10 + 3) / 3
movingAverage.next(5); // return 6.0 = (10 + 3 + 5) / 3
Constraints:
- 1 <= size <= 1000
- -105 <= val <= 105
- At most 104 calls will be made to next.
Solution:
1 | class MovingAverage { |
String
lc408-Valid Word Abbreviation
- difficulty: Easy
- tags:
- Two Pointers
- String
- https://leetcode.com/problems/valid-word-abbreviation
- https://github.com/doocs/leetcode/blob/main/solution/0400-0499/0408.Valid%20Word%20Abbreviation/README_EN.md
A string can be abbreviated by replacing any number of non-adjacent, non-empty substrings with their lengths. The lengths should not have leading zeros.
For example, a string such as “substitution” could be abbreviated as (but not limited to):
- “s10n” (“s ubstitutio n”)
- “sub4u4” (“sub stit u tion”)
- “12” (“substitution”)
- “su3i1u2on” (“su bst i t u ti on”)
- “substitution” (no substrings replaced)
The following are not valid abbreviations:
- “s55n” (“s ubsti tutio n”, the replaced substrings are adjacent)
- “s010n” (has leading zeros)
- “s0ubstitution” (replaces an empty substring)
Given a string word and an abbreviation abbr, return whether the string matches the given abbreviation.
A substring is a contiguous non-empty sequence of characters within a string.
Example 1:
Input: word = "internationalization", abbr = "i12iz4n"
Output: true
Explanation: The word "internationalization" can be abbreviated as "i12iz4n" ("i nternational iz atio n").
Example 2:
Input: word = "apple", abbr = "a2e"
Output: false
Explanation: The word "apple" cannot be abbreviated as "a2e".
Constraints:
- 1 <= word.length <= 20
- word consists of only lowercase English letters.
- 1 <= abbr.length <= 10
- abbr consists of lowercase English letters and digits.
- All the integers in abbr will fit in a 32-bit integer.
Solution 1:
We can directly simulate character matching and replacement.
Assume the lengths of the string word and the string abbr are m and n respectively. We use two pointers i and j to point to the initial positions of the string word and the string abbr respectively, and use an integer variable x to record the current matched number in abbr.
Loop to match each character of the string word and the string abbr:
If the character abbr[j] pointed by the pointer j is a number, if abbr[j] is '0' and x is 0, it means that the number in abbr has leading zeros, so it is not a valid abbreviation, return false; otherwise, update x to x * 10 + abbr[j] - '0'.
If the character abbr[j] pointed by the pointer j is not a number, then we move the pointer i forward by x positions at this time, and then reset x to 0. If i greater than or equal to m or word[i] is not equal to abbr[j] at this time, it means that the two strings cannot match, return false; otherwise, move the pointer i forward by 1 position.
Then we move the pointer j forward by 1 position, repeat the above process, until i exceeds the length of the string word or j exceeds the length of the string abbr.
Finally, if i + x equals m and j equals n, it means that the string word can be abbreviated as the string abbr, return true; otherwise return false.
The time complexity is O(m + n), where m and n are the lengths of the string word and the string abbr respectively. The space complexity is O(1).
1 | class Solution { |
Binary Tree
lc1650-Lowest Common Ancestor of a Binary Tree III
Description:
Given two nodes of a binary tree p and q, return their lowest common ancestor (LCA).
Each node will have a reference to its parent node. The definition for Node is below:
1 | class Node { |
According to the definition of LCA on Wikipedia: “The lowest common ancestor of two nodes p and q in a tree T is the lowest node that has both p and q as descendants (where we allow a node to be a descendant of itself).”
Example 1: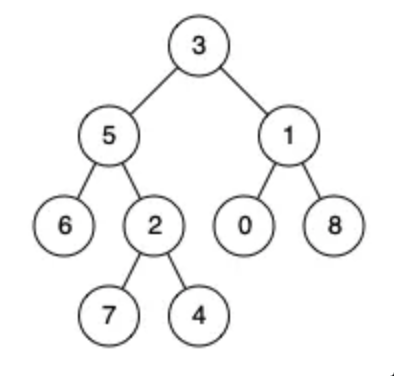
1 | Input: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1 |
Example 2: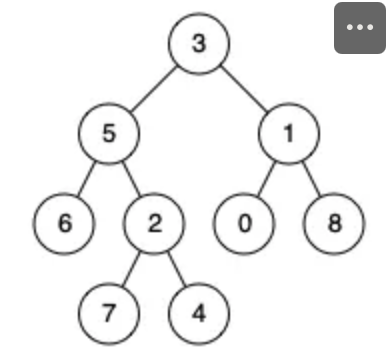
1 | Input: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4 |
Example 3:
1 | Input: root = [1,2], p = 1, q = 2 |
Constraints:
- The number of nodes in the tree is in the range
[2, 105]. 109 <= Node.val <= 109- All
Node.valare unique. p != qpandqexist in the tree.
Solution:
1 | // - 其实就变成求两条链表的相交点了, refer to : https://programmercarl.com/面试题02.07.链表相交.html#其他语言版本 |
DFS
BFS
lc314-lc987-Binary Tree vertical order traversal
- Medium
- https://leetcode.com/problems/binary-tree-vertical-order-traversal/description/
- https://productive-horse-bb0.notion.site/Meta-2021-11-2022-2-3052cadfe0584f8fbda57c86a56663fe?p=46de9980e1d44c41ae81f87e2a9aadc7&pm=s
- hint: BFS; queue and map with col number
- complexity: O(n)
Given the root of a binary tree, return the vertical order traversal of its nodes’ values. (i.e., from top to bottom, column by column).
If two nodes are in the same row and column, the order should be from left to right.
Example 1:
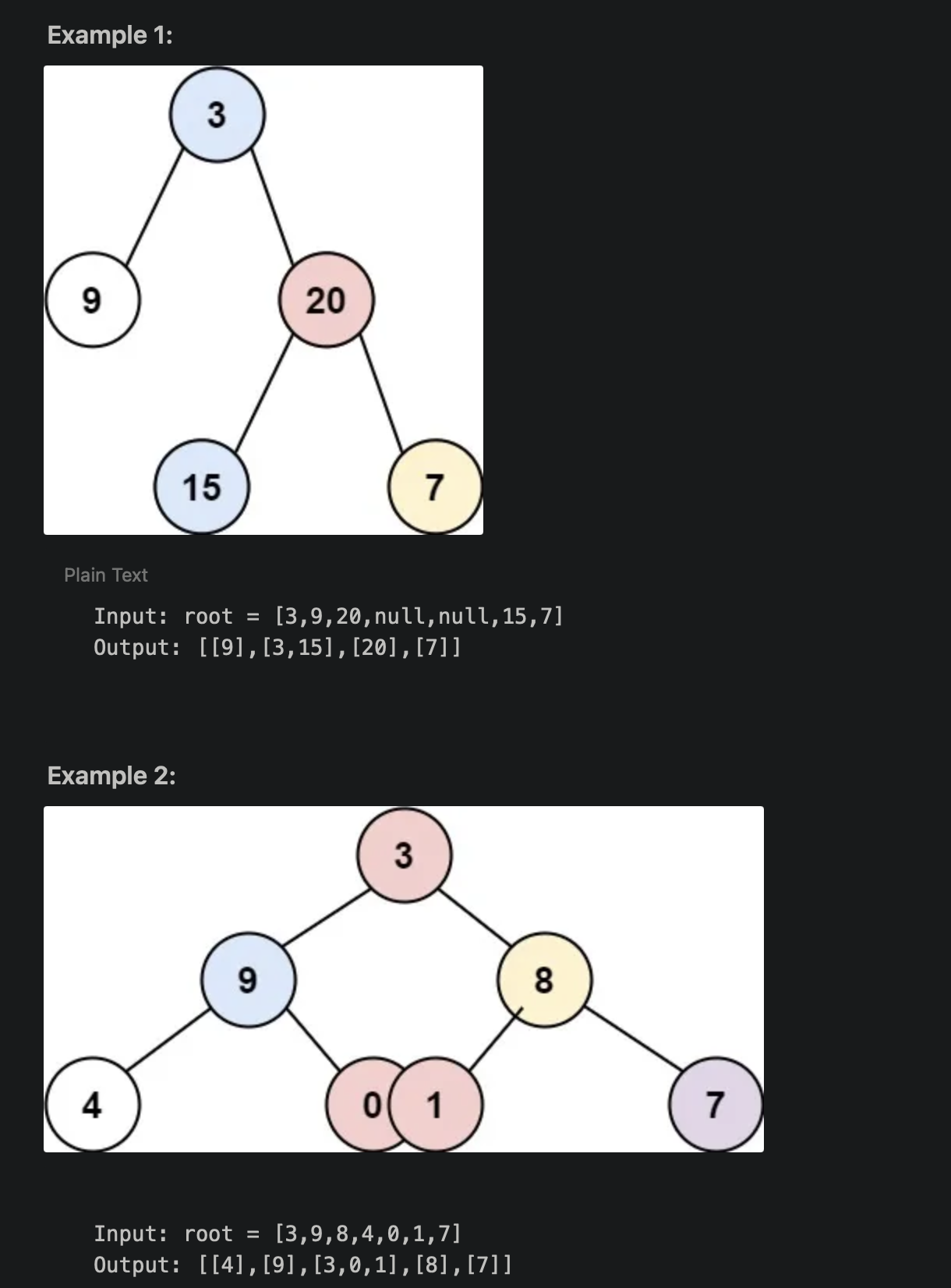
Input: root = [3,9,20,null,null,15,7]
Output: [[9],[3,15],[20],[7]]
Example 2:
Input: root = [3,9,8,4,0,1,7]
Output: [[4],[9],[3,0,1],[8],[7]]
Example 3:
Input: root = [3,9,8,4,0,1,7,null,null,null,2,5]
Output: [[4],[9,5],[3,0,1],[8,2],[7]]
Constraints:
The number of nodes in the tree is in the range [0, 100].
-100 <= Node.val <= 100
Solution1: (最优解, 而且最好理解, 还方便对于同行同列的值排序, 参见LC987)
1 | class Solution { |
Solution2: (这个解法还适合用来解”top/bottom view of binary tree”, 但是无法处理LC987的’对同行同列的值排序’这种情况, 因为 colToVals 这个 map只存了col信息, 无法排序)
1 | // - BFS level order traversal, time O(N), space O(N) |
Solution 3: (不推荐, 但是一种思路)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56class Solution {
public List<List<Integer>> verticalTraversal(TreeNode root) {
// List to store nodes with their column, row, and value
List<int[]> nodes = new ArrayList<>();
// Perform DFS traversal
dfs(root, 0, 0, nodes);
// 如果要对于同行同列的值排序, 就取消下面这几行代码的注释
// // Sort nodes by column, row, and value
// // 1.
// Collections.sort(nodes, (tuple1, tuple2) -> {
// // 2.
// // Collections.sort(nodes, new Comparator<int[]>() {
// // public int compare(int[] tuple1, int[] tuple2) {
// // 3.
// // Collections.sort(nodes, (int[] tuple1, int[] tuple2) -> {
// if (tuple1[0] != tuple2[0]) {
// return tuple1[0] - tuple2[0];
// } else if (tuple1[1] != tuple2[1]) {
// return tuple1[1] - tuple2[1];
// } else {
// return tuple1[2] - tuple2[2];
// }
// });
// List to store the final result (list of lists for each column)
List<List<Integer>> ans = new ArrayList<>();
// Variable to track the last column seen
int lastcol = Integer.MIN_VALUE;
// Iterate over sorted nodes and group by column
for (int[] tuple : nodes) {
int col = tuple[0], row = tuple[1], value = tuple[2];
if (col != lastcol) {
lastcol = col;
ans.add(new ArrayList<>());
}
ans.get(ans.size() - 1).add(value);
}
return ans;
}
// DFS method to traverse the tree and collect nodes with (col, row, value)
public void dfs(TreeNode node, int row, int col, List<int[]> nodes) {
if (node == null) {
return;
}
nodes.add(new int[]{col, row, node.val});
dfs(node.left, row + 1, col - 1, nodes);
dfs(node.right, row + 1, col + 1, nodes);
}
}
lc199-Binary Tree Right Side View
- https://leetcode.com/problems/binary-tree-right-side-view/description/
- https://programmercarl.com/0102.二叉树的层序遍历.html#_199-二叉树的右视图
1 | /** |
lc543-diameter-of-binary-tree
- https://leetcode.com/problems/diameter-of-binary-tree/description/
- solution: https://leetcode.cn/problems/diameter-of-binary-tree/solutions/139683/er-cha-shu-de-zhi-jing-by-leetcode-solution/
BST
lc938-range-sum-of-bst
lc426-Convert Binary Search Tree to Sorted Doubly Linked List
- difficulty: Medium
- tags:
- Stack
- Tree
- Depth-First Search
- Binary Search Tree
- Linked List
- Binary Tree
- Doubly-Linked List
- https://github.com/doocs/leetcode/blob/main/solution/0400-0499/0426.Convert%20Binary%20Search%20Tree%20to%20Sorted%20Doubly%20Linked%20List/README_EN.md
- https://leetcode.com/problems/convert-binary-search-tree-to-sorted-doubly-linked-list
Convert a Binary Search Tree to a sorted Circular Doubly-Linked List in place.
You can think of the left and right pointers as synonymous to the predecessor and successor pointers in a doubly-linked list. For a circular doubly linked list, the predecessor of the first element is the last element, and the successor of the last element is the first element.
We want to do the transformation in place. After the transformation, the left pointer of the tree node should point to its predecessor, and the right pointer should point to its successor. You should return the pointer to the smallest element of the linked list.
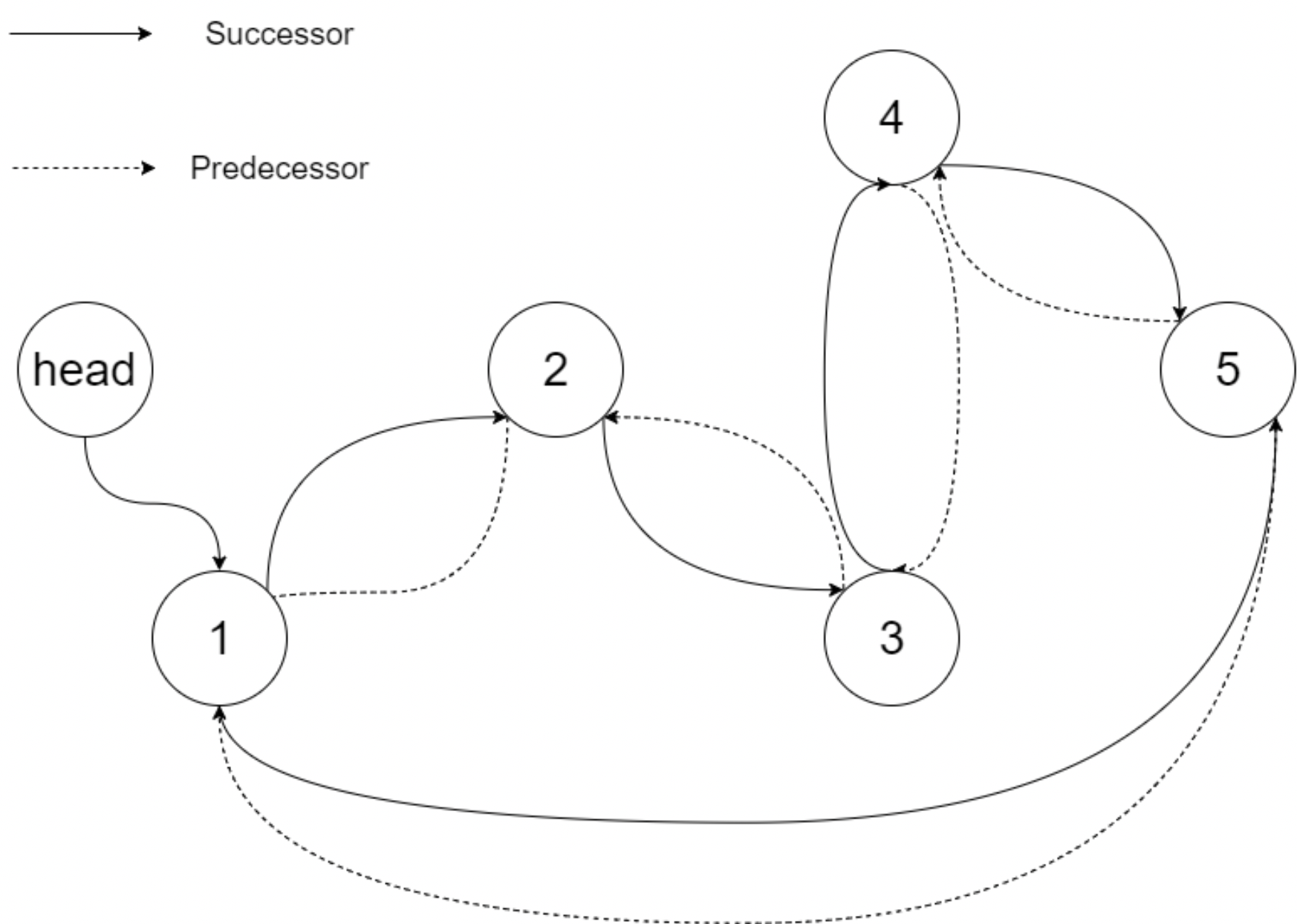
Example 1:
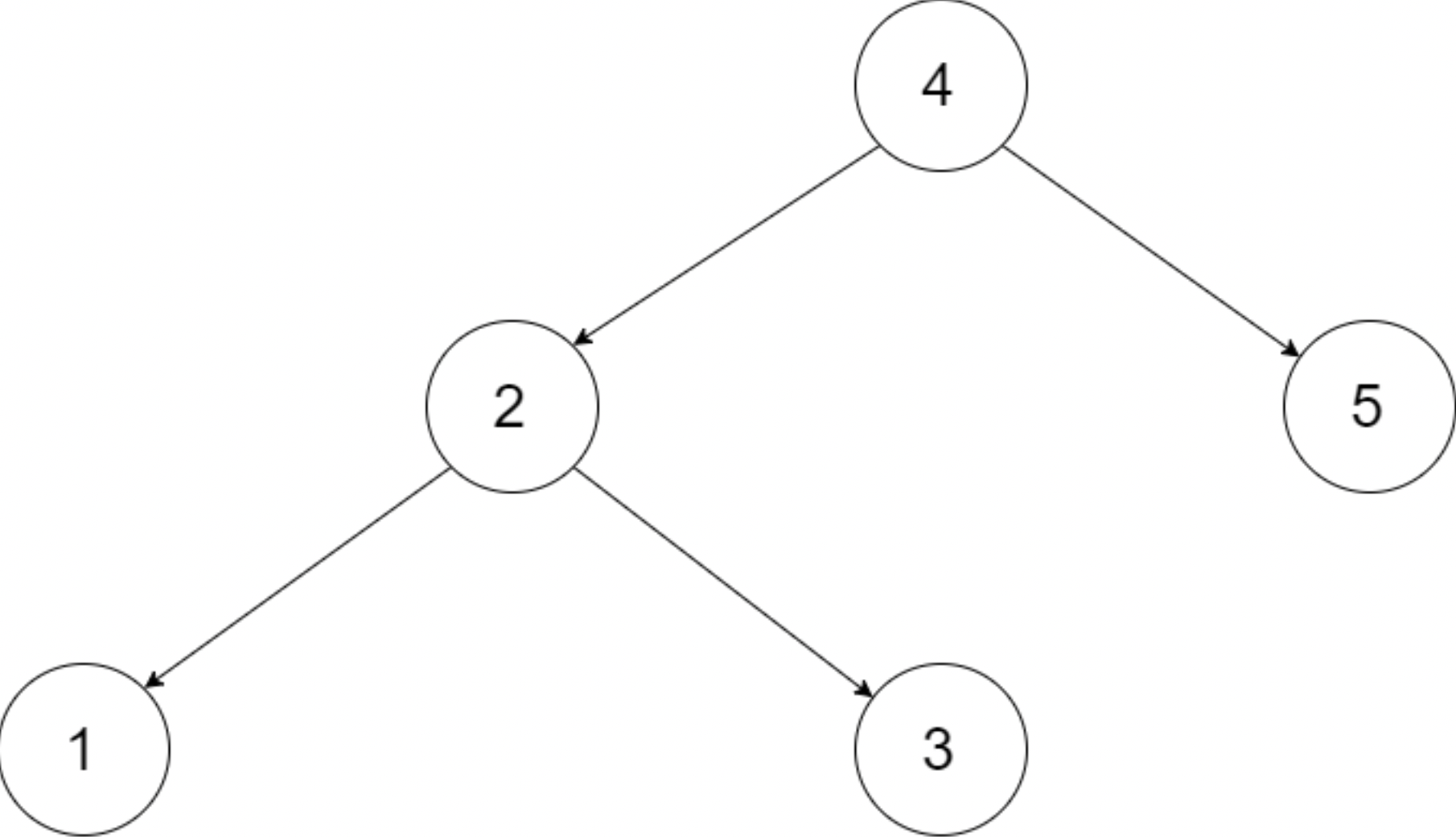
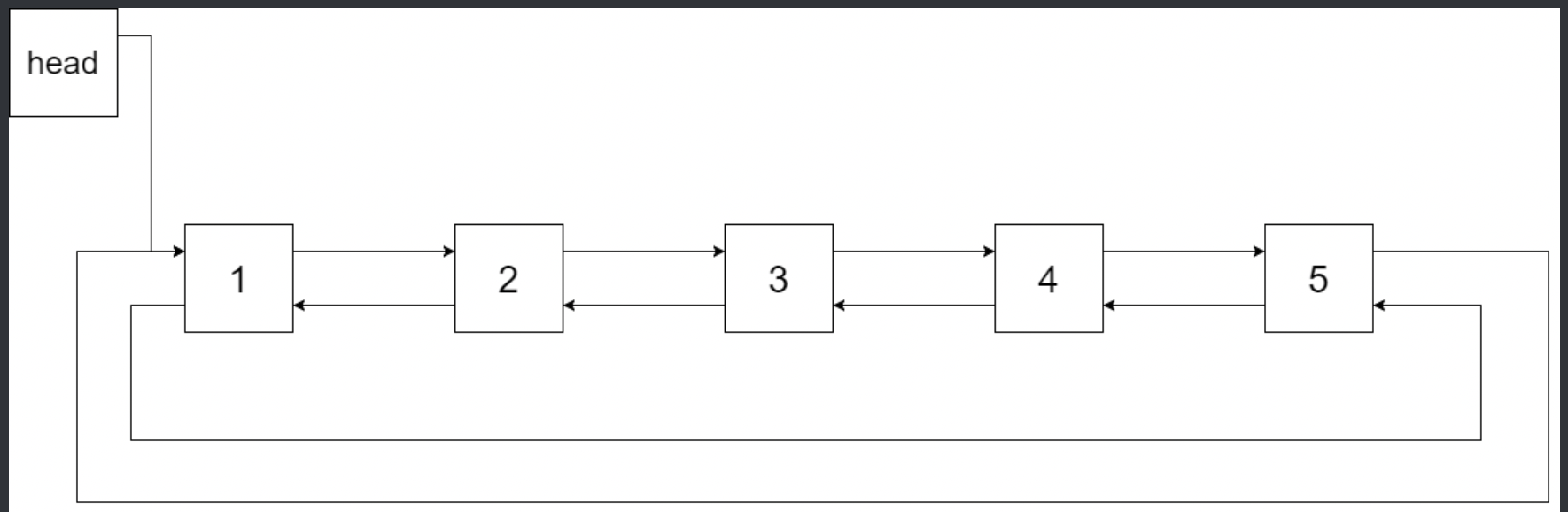
- Input: root = [4,2,5,1,3]
- Output: [1,2,3,4,5]
- Explanation: The figure below shows the transformed BST. The solid line indicates the successor relationship, while the dashed line means the predecessor relationship.
Example 2:
- Input: root = [2,1,3]
- Output: [1,2,3]
Constraints:
- The number of nodes in the tree is in the range [0, 2000].
- -1000 <= Node.val <= 1000
- All the values of the tree are unique.
Solution:
1 | /* |
lc270-Closest Binary Search Tree Value
- difficulty: Easy
- tags:
- Tree
- Depth-First Search
- Binary Search Tree
- Binary Search
- Binary Tree
- https://leetcode.com/problems/closest-binary-search-tree-value
- https://github.com/doocs/leetcode/blob/main/solution/0200-0299/0270.Closest%20Binary%20Search%20Tree%20Value/README_EN.md
Given the root of a binary search tree and a target value, return the value in the BST that is closest to the target. If there are multiple answers, print the smallest.
Example 1:
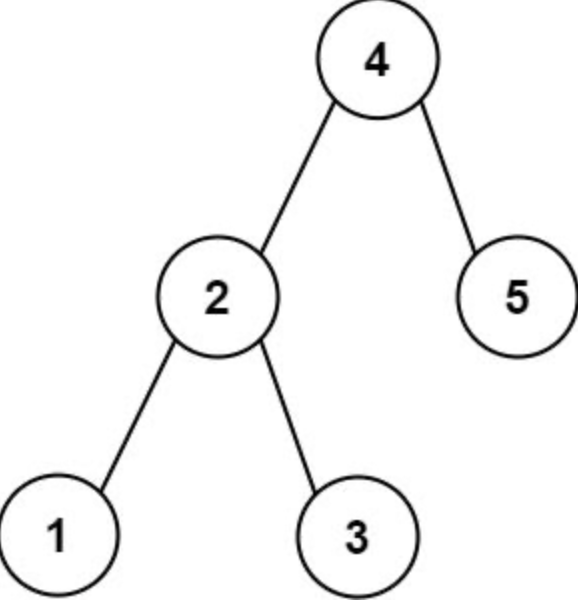
- Input: root = [4,2,5,1,3], target = 3.714286
- Output: 4
Example 2:
- Input: root = [1], target = 4.428571
- Output: 1
Constraints:
- The number of nodes in the tree is in the range [1, 104].
- 0 <= Node.val <= 109
- -109 <= target <= 109
Solution 1: Recursion
We define a recursive function dfs(node), which starts from the current node node and finds the node closest to the target value target. We can update the answer by comparing the absolute difference between the current node’s value and the target value. If the target value is less than the current node’s value, we recursively search the left subtree; otherwise, we recursively search the right subtree.
The time complexity is O(n), and the space complexity is O(n). Where n is the number of nodes in the binary search tree.
1 | class Solution { |
Solution 2: Iteration
We can rewrite the recursive function in an iterative form, using a loop to simulate the recursive process. We start from the root node and check whether the absolute difference between the current node’s value and the target value is less than the current minimum difference. If it is, we update the answer. Then, based on the size relationship between the target value and the current node’s value, we decide to move to the left subtree or the right subtree. The loop ends when we traverse to a null node.
The time complexity is O(n), where n is the number of nodes in the binary search tree. The space complexity is O(1).
1 | class Solution { |