算法白话总结
- 参考: https://programmercarl.com/
- 推荐参考本博客总结的 algo_newbie , 和本文对照着看
找工小队群里公司面经
- hong:
- 华人Wevision旗下小创业公司
- algo: 岛屿大小LC695, LC621,LC127, LC934
- 第一轮就一个算法题:岛屿大小,然后聊了点项目和简历
- 第二轮两个算法题:LC621,LC127
- 第三轮一个算法一个SD:LC934,短链服务
- 第四轮两个SD: 设计一个数据平台,设计一个消息通知系统
- 华人Wevision旗下小创业公司
- nao:
- DoorDash:
- DoorDash问的leetcode 124的变种 是他家高频面经, doordash的sd也是他家高频面经 设计一个评论系统, 其实不难 你提前做一做, 研究透了就行
- algo: 124,
- sd: 设计一个评论系统
- databricks:
- databricks都是面经 题目比较复杂 这里说不清, databricks就是纯面经题库 很容易押到题, databricks的问题就是你押中原题了 也不一定能做得好 因为太难了
- Walmart:
- algo:
- next permutation(题号lc31, 经典题),
- lc68,
- 写一个二叉搜索树, 能实现加节点和删除节点
- 另一个给出每张图片需要处理的起始天和终点天[start, end],和每张图片处理一天需要的花费,n张图片,每天处理的总花费如果超过x,总花费就视为x,求处理所有图片的最少花费 不是lc原题 是hackerrank上的题目
- 第一轮: lc68,先是一个简单版的 然后才是68本体,没写完本体 也给过了, 第一轮还问了一些k8s的八股 完全不会 也给过了
- 第二轮: 问了一些微服务的八股(问的咋实现无状态?以及一些分布式基础理论对吧, 幂等idempotency, redis没问) 然后是写一个二叉搜索树, 能实现加节点和删除节点
- 第三轮: 是lc31 和另一个给出每张图片需要处理的起始天和终点天[start, end],和每张图片处理一天需要的花费,n张图片,每天处理的总花费如果超过x,总花费就视为x,求处理所有图片的最少花费 不是lc原题 是hackerrank上的题目 第二题没写完 也过了
- 最后一轮: 就是跟老板聊天 比较随意
- algo:
- Amazon:
- bq: 亚麻bq大全, 答案要自己准备小故事, 16条军规 低职级的一般只考里面的10条, 4轮面试 每轮问两个不同的lp, 10选8, leadership principles, 就是军规, 其他公司的bq一般就是看你是不是个能一起工作的正常人, 亚麻是直接决定有没有offer
- algo:
- 都是原题, 亚麻coding很简单 主要是bq重要,
- 店面问了一个trie
- 两轮coding
- 一个是简单bfs(类似岛的数量number of islands, 经典中的经典了)
- 写一个能O1 add remove getrandom的set
- okx:
- 我还面了okx, coinbase之后的炒币app第二名, payment组
- algo: 一轮是lc49, 一轮是lc362
- sd: sd是设计一个notification system
- Google:
- algo:
- 除了google没人考dp, dp会几个经典的就行了(背包,股票,偷房子, 很多变形), dp难的是给竞赛生的,
- algo:
- Linkedin:
- algo: 785 ,366, 简化版432, 后面vo两轮coding 问了三道题, 第一轮 经典题200
- DoorDash:
Pilot Training Questions
Leetcode
- Arrays
- Two sum: https://leetcode.com/problems/two-sum/description/
- Contains Duplicate: https://leetcode.com/problems/contains-duplicate/description/
- Group Anagram: https://leetcode.com/problems/group-anagrams/description/
- Best Time to Buy and Sell Stock: https://leetcode.com/problems/best-time-to-buy-and-sell-stock/description/
- Top K Frequent Elements: https://leetcode.com/problems/top-k-frequent-elements/description/
- Longest Consecutive Sequence: https://leetcode.com/problems/longest-consecutive-sequence/description/
- Two Pointer
- Binary Search
- Binary Search: https://leetcode.com/problems/binary-search/description/
- Search in Rotated Sorted Array: https://leetcode.com/problems/search-in-rotated-sorted-array/description/
- Koko Eating Bananas: https://leetcode.com/problems/koko-eating-bananas/description/
- Sliding Window
- Longest Substring Without Repeating Characters: https://leetcode.com/problems/longest-substring-without-repeating-characters/description/
- Linked List
- Reverse Linked List: https://leetcode.com/problems/reverse-linked-list/description/
- Merge Two Sorted Lists: https://leetcode.com/problems/merge-two-sorted-lists/description/
- Linked List Cycle: https://leetcode.com/problems/linked-list-cycle/description/
- Copy List with Random Pointer: https://leetcode.com/problems/copy-list-with-random-pointer/description/
- Stack & Queue
- Valid Parentheses: https://leetcode.com/problems/valid-parentheses/description/
- Min Stack: https://leetcode.com/problems/min-stack/description/
- Implement Queue using Stacks: https://leetcode.com/problems/implement-queue-using-stacks/description/
- DFS & BFS
- Number of Islands: https://leetcode.com/problems/number-of-islands/description/
Rest API
- User Info
- Given URL: https://jsonplaceholder.typicode.com/users
- You need to write a REST api to call the given URL and return a user with its “name, username, zipcode”
- for example, if user id is 1, you should return a JSON file with username “Bret”, email “Sincere@april.biz” and zipcode “92998-3874”
- HINT: use “Rest Template”
- Result: OPEN a webbrowser and enter: http://localhost:8080/user/1 should return the correct result.
- Follow-up: id only 1-10, how to handle /user/11 → print in the page “Invalid ID”
- Solution
- Movie
- https://jsonmock.hackerrank.com/api/movies/search/?Title=waterworld
- GIVEN Above URL. Write a MVC with rest api to fetch this URL and then create new rest APIs to:
- Show all movies
- Show all movies sort by year
- Fetch a particular movie based on its imdbID.
- Hint: have multiple pages
- Solutions
- look at this URL date, it has multiple pages, each page has 10 movies, we need to fetch all pages to get a full list of movies and then filter to find the particular movie by imdbID
- each movie has Title, Year, imdbID three fields, we need to create a model to match them
- need org.json.simple to parse the json object from the given URL
- Build a POST API /greetings with below requirements
- Create a POST API /greetings
- INPUT – json array: [{“name”:”john doe”, “work”: “engineer”}, {“name”:”jane who”, “work”: “manager”}]
- OUTPUT - json: {“data”: [“Hello john the engineer”, “Hello jane the manager”], “timestamp”: “${requested_timestamp}”
- Use postman to call the API and pass input, it should return the correct response.
概绍
本群的每日刷题打卡活动, 按照 GitHub 49k star的项目 https://github.com/youngyangyang04/leetcode-master 的刷题顺序.
跟着群里有个伴一起刷题或许更容易坚持达成每日一题的目标. 做完题目之后可以在群里的小程序”今日leetcode刷题打卡”里打卡.
- 网页版: 代码随想录 https://programmercarl.com/
- 本博客只记录那些有明显自我疑问而<<代码随想录>>没有说明清楚的题目, 会标识出来并注释
本文完整参考代码
https://github.com/no5ix/no5ix.github.io/blob/source/source/code/test_algo_na.java
Java常用接口和实现
Convert a number to a string and vice versa
1 | int num = 123; |
随机数
方法1: (推荐)
- nextInt() 返回的是任意整数,范围包括负数和正数。
- nextInt(bound) 返回一个随机整数,范围是从 0 到 bound(不包括 bound)。
1 | // 如果你想生成一个 1 到 100 之间的随机整数(包括1和100),可以这样写: |
方法2: (不推荐)
To generate a random number within the range
[3, 6], where both 3 and 6 are inclusive, you can modify the logic slightly from the[3, 6)approach:double randomNumber = 3 + (Math.random() * (6 - 3 + 1));
Math.random()generates a random number in the range[0.0, 1.0).- Multiplying it by
(6 - 3 + 1)(which is 4) adjusts the range to[0.0, 4.0). - Adding 3 shifts the range to
[3.0, 7.0). - Since the inclusive range is
[3, 6], you’ll need to truncate or floor the result if you’re generating an integer:int picked = (int) ((high - low + 1) * Math.random()) + low; - Notice: remember that
int picked = (int) (high - low + 1) * Math.random() + low;is not correct, because it will cause the error “incompatible types: possible lossy conversion from double to int”, you should always convert the multiplication result((high - low + 1) * Math.random())to an Integer but not(high - low + 1)only
值传递
- 记住:Java 中只有值传递!只是对于对象类型,值是对象的引用地址,这使得我们可以修改对象的内容,但不能改变对象的引用本身。
- 基本数据类型: 方法接收变量的值,修改不会影响原始变量。
- 对象类型:
- 方法接收的是对象引用的副本,可以通过引用修改对象内容。
- 方法不能改变引用本身的指向。
1 | // 解释:在 changeReference 方法中,person 被赋值为一个新的对象,但这只是改变了方法内的 person 引用,并不影响 main 方法中 p 的引用。 |
排序
普通递增排序:
1 | // Arrays.sort 用于对数组进行排序(primitive 或 Object 类型)。 |
举例说明自定义数字排序规则, 使用 Comparator:
- Collections.sort
- Arrays.sort
以下例子的这个排序逻辑首先按列 col 排序,如果列相同,则按行 row 排序,再根据节点的值进行排序。排序优先级依次是:列、行、值1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28// : List to store nodes with their column, row, and value
List<int[]> nodes = new ArrayList<>();
// nodes.add(new int[]{col, row, val});
nodes.add(new int[]{1, 2, 3});
nodes.add(new int[]{1, 3, 4});
nodes.add(new int[]{2, 2, 4});
// Sort nodes by column, row, and value
// 解释:
// • Collections.sort() 是 Java 中用于排序 List 的方法。它接受两个参数,第一个是需要排序的 List(在这里是 nodes),第二个是排序规则(通过 Comparator 来定义)。
// • 这是一个 lambda 表达式,它实现了 Comparator<int[]> 接口。tuple1 和 tuple2 是 nodes 中的元素(即 int[] 类型的数组)。tuple1 和 tuple2 是用来比较的两个元素。
Collections.sort(nodes, (tuple1, tuple2) -> {
// 排序规则:
// 1. 首先比较 tuple1[0] 和 tuple2[0]:
// 如果它们不相等(即列 col 不相同),则按列进行排序。
// 2. 如果列相同,则比较 tuple1[1] 和 tuple2[1]:
// 如果列相同,再按照行 row 进行排序。
// 3. 如果列和行都相同,则比较 tuple1[2] 和 tuple2[2]:
// 最后,如果列和行都相同,则按照节点的值进行排序。
if (tuple1[0] != tuple2[0]) {
// 这里的 tuple1[0] - tuple2[0] 是用来确定排序的方向。如果 tuple1[0] 小于 tuple2[0],结果为负数,意味着 tuple1 排在 tuple2 前面;如果大于,结果为正数,tuple1 排在后面;如果相等,则继续比较后续条件。
return tuple1[0] - tuple2[0];
} else if (tuple1[1] != tuple2[1]) {
return tuple1[1] - tuple2[1];
} else {
return tuple1[2] - tuple2[2];
}
});
举例说明自定义字母排序规则 (比如有个 List
1 | import java.util.*; |
Map
1 | Map<Integer, Integer> map = new HashMap<>(); |
Set
1 | Set<Integer> set = new HashSet<>(); |
List
1 | List<Integer> list = new ArrayList<>(); |
Queue
1 | Queue<Integer> queue = new ArrayDeque<>(); // 不要用 LinkedList(除非你要往队列里插入null, 因为ArrayDeque不准插入null, 但是LinkedList可以), ArrayDeque用circular buffer实现的, 是最高效的: https://stackoverflow.com/questions/6129805/what-is-the-fastest-java-collection-with-the-basic-functionality-of-a-queue |
Deque
1 | Deque<Integer> deque = new ArrayDeque<>(); // 不要用 LinkedList(除非你要往队列里插入null, 因为ArrayDeque不准插入null, 但是LinkedList可以), ArrayDeque用circular buffer实现的, 是最高效的: https://stackoverflow.com/questions/6129805/what-is-the-fastest-java-collection-with-the-basic-functionality-of-a-queue |
Stack(一般不用因为有性能问题)
注意!!! 在 Java 中,如果我们希望避免使用 Stack 类以减少同步带来的性能问题,可以使用其他不包含同步的集合类实现栈(stack)的功能,例如 Deque(双端队列)。Deque 接口的实现类如 ArrayDeque 都是很好的选择。Deque也可以直接 push, pop, peek
1 | Stack<Integer> stack = new Stack<>(); |
String and Character
1 | // Why use equals()? |
复杂度
留意数据规模, 不要以为复杂度分析是专门用来难为你的,它其实是来帮你的,它是来偷偷告诉你解题思路的。
你应该在开始写代码之前就留意题目给的数据规模,因为复杂度分析可以避免你在错误的思路上浪费时间,有时候它甚至可以直接告诉你这道题用什么算法。
为啥这样说呢,因为一般题目都会告诉我们测试用例的数据规模有多大,我们可以根据这个数据规模反推这道题能够允许的时间复杂度在什么范围,进一步反推我们应该要用什么算法。
举例来说吧:
- 比如一个题目给你输入一个数组,其长度能够达到 10^6 这个量级,那么我们肯定可以知道这道题的时间复杂度大概要小于 O(N2),得优化成 O(NlogN) 或者 O(N) 才行。因为如果你写的算法是 O(N2) 的,最大的复杂度会达到 10^12 这个量级,在大部分判题系统上都是跑不过去的。
- 为了把复杂度控制在 O(NlogN) 或者 O(N),我们的选择范围就缩小了,可能符合条件的做法是:对数组进行排序处理、前缀和、双指针、一维 dp 等等,从这些思路切入就比较靠谱。像嵌套 for 循环、二维 dp、回溯算法这些思路,基本可以直接排除掉了。
- 再举个更直接的例子,如果你发现题目给的数据规模很小,比如数组长度 N 不超过 20 这样的,那么我们可以断定这道题大概率要用暴力穷举算法。
- 因为判题平台肯定是尽可能扩大数据规模难为你,它一反常态给这么小的数据规模,肯定是因为最优解就是指数/阶乘级别的复杂度。你放心用回溯算法 招呼它就行了,不用想别的算法了。
所以说啊,很多读者看题都不看那个数据规模,上来就闷声写代码,这是不对滴。你先把题目给的所有信息都考虑进去,再写代码,这样才能少走弯路。
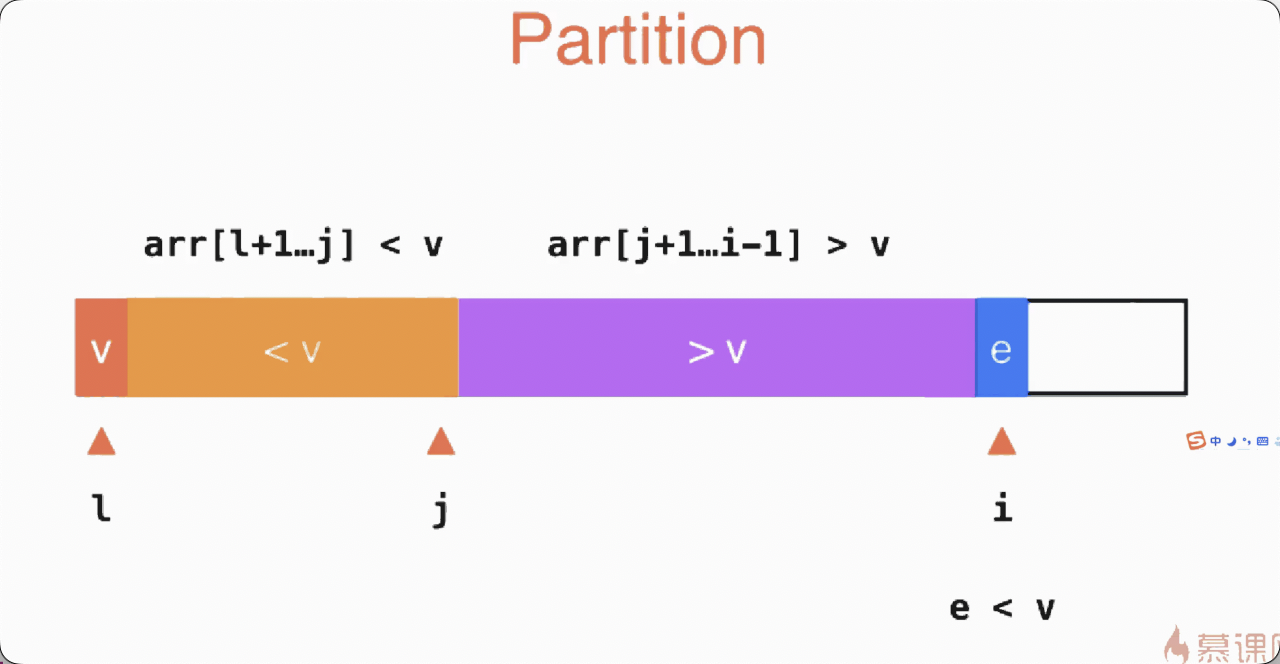
Quick Select
模板与诀窍
- 适合解决 Top K 问题, 因为最快
- 快速选择平均情况下,时间复杂度为 O(N)。
- 空间复杂度:O(N)。哈希表的大小为 O(N),用于排序的数组的大小也为 O(N),快速排序的空间复杂度最好情况为 O(logN),最坏情况为 O(N)。
- 参考 algo_newbie ##普通快排 里的代码, 及其动画演示(safari可能播放不了视频), 帮助理解
1 | Random random = new Random(); |
lc347 - Top K Frequent Elements
- https://leetcode.com/problems/top-k-frequent-elements/description/
- https://programmercarl.com/0347.前K个高频元素.html#其他语言版本
- Similar problem: https://leetcode.com/problems/kth-largest-element-in-an-array/
We should solve this kind of top-level problem using the “Quick Select” approach (it’s very similar to Quick Sort). Because its time complexity of O(n) is lower, this method is more efficient than the Heap-based approach with a time complexity of O(nlogn).
Referenced this: https://www.bilibili.com/video/BV1Bz4y117Fr/
- 时间复杂度:O(N),其中 N 为数组的长度。
设处理长度为 N 的数组的时间复杂度为 f(N)。由于处理的过程包括一次遍历和一次子分支的递归,最好情况下,有 f(N)=O(N)+f(N/2),根据 主定理,能够得到 f(N)=O(N)。 - 最坏情况下,每次取的中枢数组的元素都位于数组的两端,时间复杂度退化为 O(N)。但由于我们在每次递归的开始会先随机选取中枢元素,故出现最坏情况的概率很低。
- 平均情况下,时间复杂度为 O(N)。
- 空间复杂度:O(N)。哈希表的大小为 O(N),用于排序的数组的大小也为 O(N),快速排序的空间复杂度最好情况为 O(logN),最坏情况为 O(N)。
1 | import java.util.Map; |
数组
诀窍
没有思路的时候思考以下方法:
- 口诀: “前二, 双排, 滑倒”
- 先排个序
- 前缀和 (在涉及计算区间和的问题时非常有用!)
- 倒序遍历
- 二分法(注意:
int mid = left + (right - left) / 2;) - 双指针
- 滑动窗口
二分法诀窍与易错点
- 为什么要
int mid = left + (right - left) / 2? 答案见下方代码中的注释 - 是
while (leftIndex <= rightIndex)还是while (leftIndex < rightIndex)? 答案见下方代码注释或者这里 的讲解 - 二分查找, 当在数组中找不到对应的值, 循环完毕后的left和right的含义是什么?
- 如果目标值不在数组中,循环结束时满足条件:right < left,循环结束后的 left 和 right 的含义如下:
- left 的含义:
- left 指向插入目标值的位置(满足排序要求)。
- left 是第一个大于目标值的位置(在数组中的索引)。
- 如果目标值比数组中所有元素都大,left 将等于数组的长度,即指向超出数组范围的位置。
- right 的含义:
- right 是目标值的前一个可能位置(如果目标值存在的话)。
- right 是最后一个小于目标值的位置(在数组中的索引)。
- 如果目标值比数组中所有元素都小,right 将等于 -1,即在数组范围之外。
- 情况 1:目标值在数组范围内,但不存在
- 数组为 [1, 3, 5, 7, 9],目标值为 6。
- • 最终状态:
- • left = 3(第一个大于 6 的索引,值为 7)。
- • right = 2(最后一个小于 6 的索引,值为 5)。
- 数组为 [1, 3, 5, 7, 9],目标值为 6。
- 情况 2:目标值比数组中所有元素小
- 数组为 [3, 5, 7, 9],目标值为 2。
- • 最终状态:
- • left = 0(第一个大于 2 的索引,值为 3)。
- • right = -1(数组范围之外)。
- 数组为 [3, 5, 7, 9],目标值为 2。
- 情况 3:目标值比数组中所有元素大
- 数组为 [3, 5, 7, 9],目标值为 10。
- • 最终状态:
- • left = 4(数组长度,超出范围)。
- • right = 3(最后一个索引,值为 9)。
- 数组为 [3, 5, 7, 9],目标值为 10。
- 比如说给你有序数组
nums = [1,2,2,2,3], target 为 2,如果我想得到 target 的左侧边界,即索引 1,或者我想得到 target 的右侧边界,即索引 3, 怎么做呢?- 见下方代码的
left_bound和right_bound, 详细讲解请参考: https://leetcode.cn/problems/binary-search/solutions/8337/er-fen-cha-zhao-xiang-jie-by-labuladong/
- 见下方代码的
- https://programmercarl.com/0704.二分查找.html#二分法第一种写法
- https://leetcode.com/problems/binary-search/
1 | class Solution { |
二分查找扩展题-lc69-求平方
1 | class Solution { |
前缀和诀窍
- https://juejin.cn/post/7005057884555837476
- 前缀和理论基础: https://programmercarl.com/kamacoder/0058.区间和.html#思路
前缀和特别适合解决区间类的问题
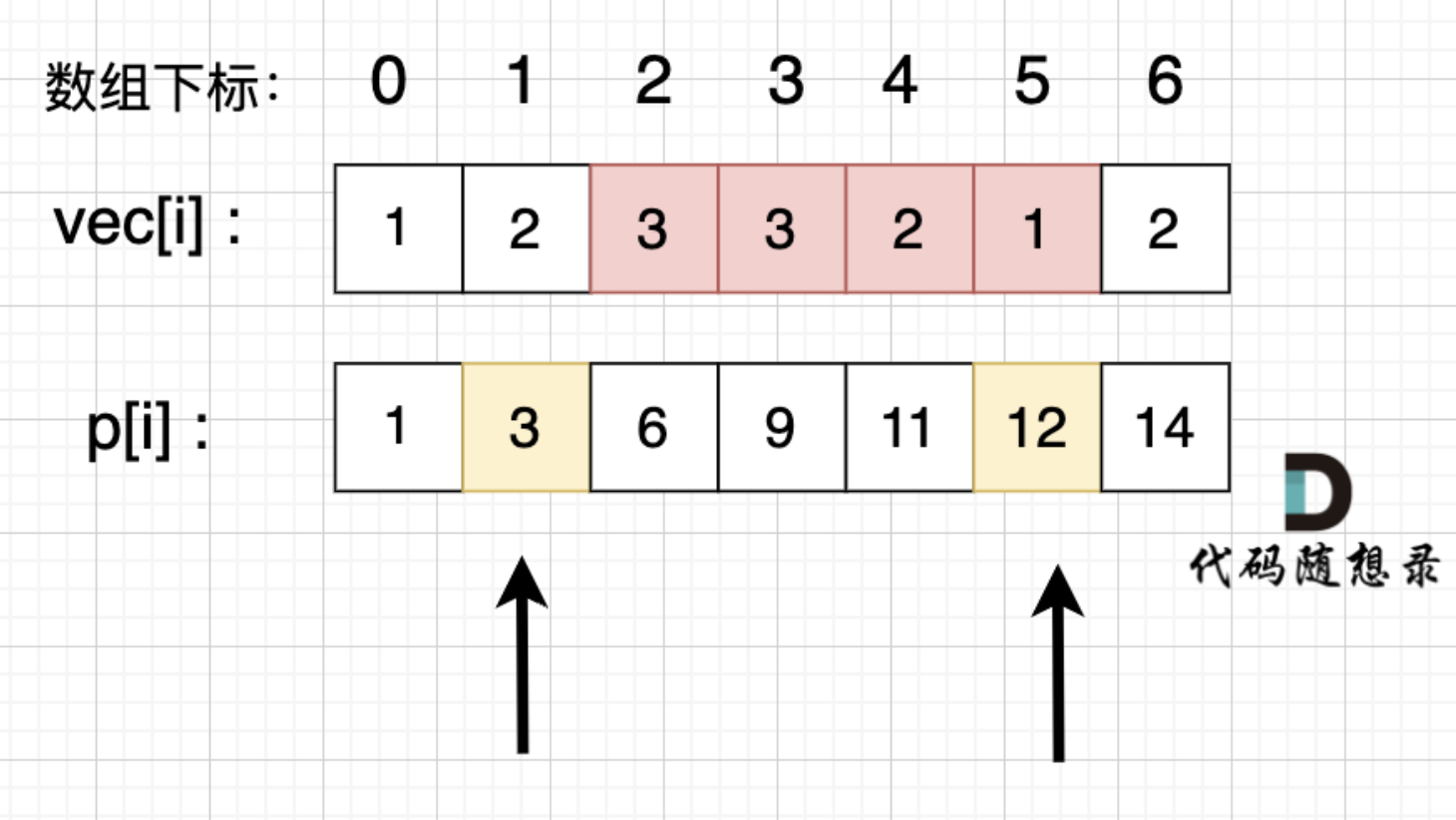
p[5] - p[1] 就是 红色部分的区间和。
而 p 数组是我们之前就计算好的累加和,所以后面每次求区间和的之后 我们只需要 O(1) 的操作。
特别注意: 在使用前缀和求解的时候,要特别注意 求解区间。
如上图,如果我们要求 区间下标 [2, 5] 的区间和,那么应该是 p[5] - p[1],而不是 p[5] - p[2]。
「前缀和」 是从 nums 数组中的第 0 位置开始累加,到第 iii 位置的累加结果,我们常把这个结果保存到数组 preSum 中,记为 preSum[i]。
下面以 [1, 12, -5, -6, 50, 3] 为例,讲解一下如何求 preSum 前缀和的另一种写法(在很多题里非常有用, 比如这题):
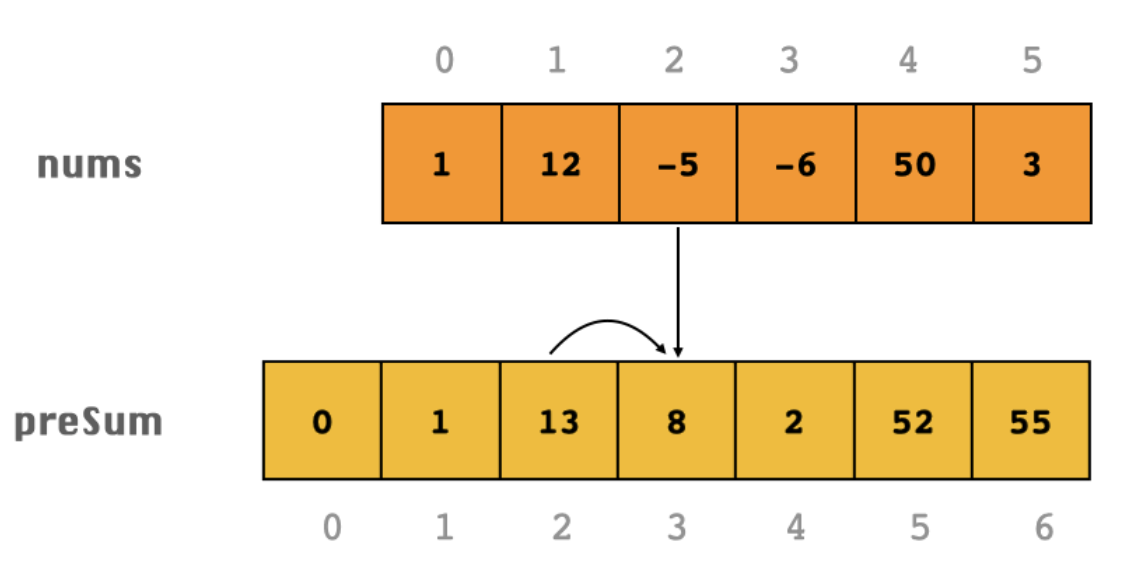
在前面计算「前缀和」的代码中,计算公式为 preSum[i] = preSum[i - 1] + nums[i] ,为了防止当 i = 0 的时候数组越界,所以加了个 if (i == 0) 的判断,即 i == 0 时让 preSum[i] = nums[i]。
在其他常见的写法中,为了省去这个 if 判断,我们常常把「前缀和」数组 preSum 的长度定义为 原数组的长度 + 1。preSum 的第 0 个位置,相当于一个占位符,置为 0。
那么就可以把 preSum 的公式统一为 preSum[i] = preSum[i - 1] + nums[i - 1],此时的 preSum[i] 表示 nums 中 iii 元素左边所有元素之和(不包含当前元素 iii)。1
2
3
4
5
6
7for (int i = 1; i <= gain.length; i++) {
prefixSum[i] = prefixSum[i - 1] + gain[i - 1];
}
// 或者
for (int i = 0; i < gain.length; i++) {
prefixSum[i + 1] = prefixSum[i] + gain[i];
}
lc528-前缀和+二分
- 前缀和理论基础: https://programmercarl.com/kamacoder/0058.区间和.html#思路
- https://leetcode.com/problems/random-pick-with-weight/
- https://leetcode.cn/problems/random-pick-with-weight/solutions/966335/cer-fen-xiang-jie-by-xiaohu9527-nsns/
lc528 Description:
You are given a 0-indexed array of positive integers w where w[i] describes the weight of the ith index.
You need to implement the function pickIndex(), which randomly picks an index in the range [0, w.length - 1] (inclusive) and returns it. The probability of picking an index i is w[i] / sum(w).
For example, if w = [1, 3], the probability of picking index 0 is 1 / (1 + 3) = 0.25 (i.e., 25%), and the probability of picking index 1 is 3 / (1 + 3) = 0.75 (i.e., 75%).
Example 1:
- Input
["Solution","pickIndex"][[[1]],[]]
- Output :
[null,0] - Explanation:
Solution solution = new Solution([1]);
solution.pickIndex(); // return 0. The only option is to return 0 since there is only one element in w.
Example 2:
- Input:
["Solution","pickIndex","pickIndex","pickIndex","pickIndex","pickIndex"][[[1,3]],[],[],[],[],[]]
- Output:
[null,1,1,1,1,0] Explanation:
Solution solution = new Solution([1, 3]);
solution.pickIndex(); // return 1. It is returning the second element (index = 1) that has a probability of 3/4.
solution.pickIndex(); // return 1
solution.pickIndex(); // return 1
solution.pickIndex(); // return 1
solution.pickIndex(); // return 0. It is returning the first element (index = 0) that has a probability of 1/4.Since this is a randomization problem, multiple answers are allowed.
All of the following outputs can be considered correct:
[null,1,1,1,1,0]
[null,1,1,1,1,1]
[null,1,1,1,0,0]
[null,1,1,1,0,1]
[null,1,0,1,0,0]
……
and so on.
Constraints:
- 1 <= w.length <= 104
- 1 <= w[i] <= 105
- pickIndex will be called at most 104 times.
1 | class Solution { |
双指针诀窍
双指针和滑动窗口的一般不同点是:
- 互相靠近: 双指针大多数时候是left指针在首, right在尾, 然后互相逐渐靠近
- 快慢指针: 或者一个快一个慢, right快(去寻找合适的数), left慢的指针就处理right找到数据;
- 数组问题中比较常见的快慢指针技巧,是让你原地修改数组。比如说看下力扣第 26 题「删除有序数组中的重复项」,让你在有序数组去重
- 而滑动窗口一般也是right快left慢, 但滑动窗口为了维护一个区间窗口, 一般是用来求一个子区间的
最大和/最小和之类的东西 - 理论上滑动窗口是双指针的一种, 只是比较像一个窗口而故名
lc27-Remove Element
- https://programmercarl.com/0027.移除元素.html#算法公开课
- https://leetcode.com/problems/remove-element/description/
双指针法(快慢指针法): 通过一个快指针和慢指针在一个for循环下完成两个for循环的工作。
定义快慢指针:
- 快指针:寻找新数组的元素 ,新数组就是不含有目标元素的数组
- 慢指针:指向更新 新数组下标的位置
诀窍: 应该想象成 slowIndex 之前的那些数组格子就是新的数组
1 | class Solution { |
lc977-有序数组的平方
- https://programmercarl.com/0977.有序数组的平方.html#算法公开课
- https://leetcode.com/problems/squares-of-a-sorted-array/description/
1 | class Solution { // lc977 |
lc15-3Sum
其实这道题目使用哈希法并不十分合适(4sum就没办法了),因为在去重的操作中有很多细节需要注意,在面试中很难直接写出没有bug的代码。
接下来我来介绍另一个解法:双指针法(4sum也是这种思路),这道题目使用双指针法 要比哈希法高效一些,那么来讲解一下具体实现的思路。
1 | class Solution { |
lc18-4Sum
1 | class Solution { |
滑动窗口模板与生动理论
- 滑动窗口一般也是right快left慢, 但滑动窗口为了维护一个区间窗口, 一般是用来求一个子区间的
最大和/最小和之类的东西 - 理论上滑动窗口是双指针的一种, 只是比较像一个窗口而故名
- https://leetcode.cn/problems/max-consecutive-ones-iii/solutions/609055/fen-xiang-hua-dong-chuang-kou-mo-ban-mia-f76z/
- 《挑战程序设计竞赛》这本书中把滑动窗口叫做
「虫取法」,我觉得非常生动形象。因为滑动窗口的两个指针移动的过程和虫子爬动的过程非常像:前脚不动,把后脚移动过来;后脚不动,把前脚向前移动。 - 滑动窗口中用到了左右两个指针,它们移动的思路是:以右指针作为驱动,拖着左指针向前走。右指针每次只移动一步,而左指针在内部 while 循环中每次可能移动多步。右指针是主动前移,探索未知的新区域;左指针是被迫移动,负责寻找满足题意的区间。
滑动窗口的复杂度
- 为啥是 O(N)?
- 肯定有读者要问了,你这个滑动窗口框架不也用了一个嵌套 while 循环?为啥复杂度是 O(N) 呢?
- 简单说,指针 left, right 不会回退(它们的值只增不减),所以字符串/数组中的每个元素都只会进入窗口一次,然后被移出窗口一次,不会说有某些元素多次进入和离开窗口,所以算法的时间复杂度就和字符串/数组的长度成正比。
- 反观嵌套 for 循环的暴力解法,那个 j 会回退,所以某些元素会进入和离开窗口多次,所以时间复杂度就是 O(N2) 了。
- 我在 算法时空复杂度分析实用指南 有具体教大家如何从理论上估算时间空间复杂度,这里就不展开了。
- 为啥滑动窗口能在 O(N) 的时间穷举子数组?
- 这个问题本身就是错误的,滑动窗口并不能穷举出所有子串。要想穷举出所有子串,必须用那个嵌套 for 循环。
- 然而对于某些题目,并不需要穷举所有子串,就能找到题目想要的答案。滑动窗口就是这种场景下的一套算法模板,帮你对穷举过程进行剪枝优化,避免冗余计算。
- 所以在 算法的本质 中我把滑动窗口算法归为「如何聪明地穷举」一类。
滑动窗口的模板
能解决大多数的滑动窗口问题:
1 | def findSubArray(nums): |
lc1004-Max Consecutive Ones III
- https://leetcode.cn/problems/max-consecutive-ones-iii/solutions/609055/fen-xiang-hua-dong-chuang-kou-mo-ban-mia-f76z/
- https://leetcode.com/problems/max-consecutive-ones-iii/
1 | class Solution { |
链表
诀窍
- 没有思路的时候想想快慢指针, 能解决大部分链表问题
- 单链表弄个虚拟头结点, 可以很省事
- 双链表弄个虚拟头结点和虚拟尾结点, 刚开始就让虚拟头尾相连, 可以很省事, 参见LRU里的那个, 如下:
1
2
3
4this.head = new DLinkedNode(); // dummy
this.tail = new DLinkedNode(); // dummy
head.next = tail;
tail.pre = head; // 刚开始初始化的时候虚拟首尾节点的中间没有实际节点, 所以虚拟首尾节点是相连的.
lc206 - 链表反转
- https://programmercarl.com/0206.翻转链表.html#算法公开课
https://leetcode.com/problems/reverse-linked-list/description/
重要!!!!! 记忆口诀: 举一反(反转)三(3个指针! pre! cur! temp!)
- 核心要点就是需要保存一个后面可能要用的结点就弄一个指针出来, 比如这个pre
1 | // 双指针 |
lc24 - 两两交换链表中的节点
- https://programmercarl.com/0024.两两交换链表中的节点.html
重要!!!!! 记忆口诀(和反转链表很类似): 举一(1个dummyHead指针!)反(反转)三(3个指针! cur! node1! node2!)
- 核心要点(和反转链表很类似): 就是需要保存一个后面可能要用的结点就弄一个指针出来, 需要两个就弄两个指针, 比如这个node1, node2 !!
1 | // 将步骤 2,3 交换顺序,这样不用定义 temp 节点 |
字符串
lc28 - 实现strStr() - 20240923
暴力解法-掌握这个暴力解法即可
1 | class Solution { |
KMP不要求-面试基本不会出的-背代码就没意思了
- https://programmercarl.com/0028.实现strStr.html#算法公开课
- https://leetcode.com/problems/find-the-index-of-the-first-occurrence-in-a-string/
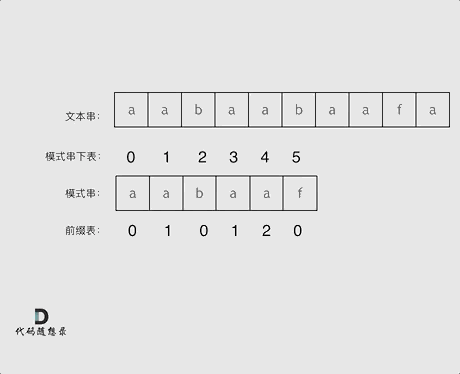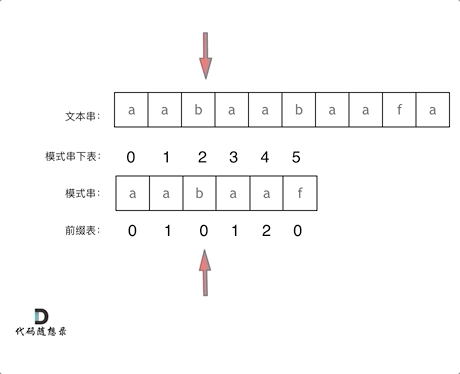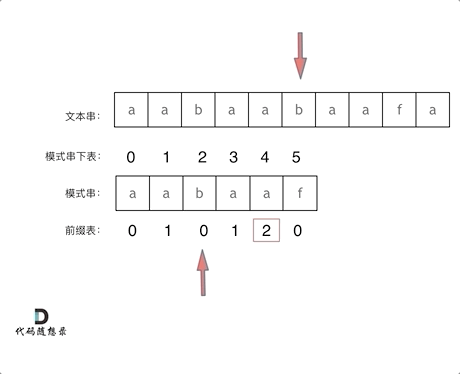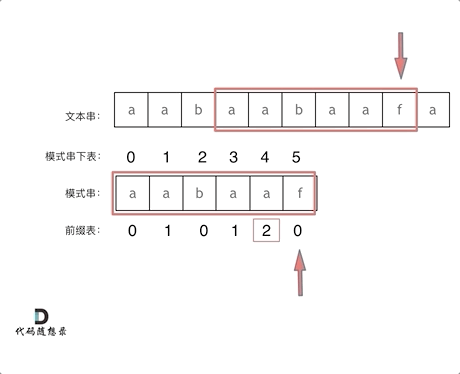
看一下如何利用 前缀表找到 当字符不匹配的时候应该指针应该移动的位置。如上动画所示:
找到的不匹配的位置, 那么此时我们要看它的前一个字符的前缀表的数值是多少。
为什么要前一个字符的前缀表的数值呢,因为要找前面字符串的最长相同的前缀和后缀。
所以要看前一位的 前缀表的数值。
前一个字符的前缀表的数值是2, 所以把下标移动到下标2的位置继续比配。 可以再反复看一下上面的动画。
最后就在文本串中找到了和模式串匹配的子串了。
1 | class Solution { |
lc459 - 重复的子字符串-暴力解法-掌握这个暴力解法即可
- https://programmercarl.com/0459.重复的子字符串.html#算法公开课
- https://leetcode.com/problems/repeated-substring-pattern/
1 | // 作者:力扣官方题解 |
栈与队列
诀窍
- 当遇到这类问题就要用栈了:
- 栈在系统中的路径问题, 如: 简化路径
cd a/b/c/../../ - 括号匹配问题, 如: 给定一个只包括
'(',')','{','}','[',']'的字符串,判断字符串是否有效。 - 字符串去重问题, 如: lc1047. 删除字符串中的所有相邻重复项
- 栈在系统中的路径问题, 如: 简化路径
- 队列反而是在树的层序遍历里用的较多
lc239 - Sliding Window Maximum
- https://programmercarl.com/0239.滑动窗口最大值.html#其他语言版本
- https://leetcode.com/problems/sliding-window-maximum/
1 | //利用双端队列手动实现单调队列 |
二叉树
诀窍
- 二叉树的算法题型主要是用来培养递归思维的,而层序遍历属于迭代遍历,也比较简单
- 一共只有三种题目:
- 直接通过 dfs/bfs 可以计算的类型
- 路径类
- 最小祖先类
- 二叉树最重要的是层序遍历的模板, 可以解决
70%的二叉树题目 - 路径题和公共祖先题和深度高度的题一般才会用到
递归, 其他大多数时候都可以层序遍历 / 前中序遍历的迭代法解决 - 仔细观察,前中后序位置的代码,能力依次增强。
- 前序位置的代码只能从函数参数中获取父节点传递来的数据。
- 中序位置的代码不仅可以获取参数数据,还可以获取到左子树通过函数返回值传递回来的数据。
- 后序位置的代码最强,不仅可以获取参数数据,还可以同时获取到左右子树通过函数返回值传递回来的数据。
- 所以,某些情况下把代码移到后序位置效率最高;有些事情,只有后序位置的代码能做
- 二叉树递归写法诀窍, 递归函数什么时候需要返回值?什么时候不需要返回值?这里总结如下三点:
- 如果需要搜索整棵二叉树且不用处理递归返回值,递归函数就不要返回值。(这种情况就是本文下半部分介绍的113.路径总和ii, https://programmercarl.com/0112.路径总和.html#相关题目推荐)
- 如果需要搜索整棵二叉树且需要处理递归返回值,递归函数就需要返回值。 (这种情况我们在236. 二叉树的最近公共祖先, https://programmercarl.com/0236.二叉树的最近公共祖先.html#算法公开课)
- 如果要搜索其中一条符合条件的路径,那么递归一定需要返回值,因为遇到符合条件的路径了就要及时返回。(这种情况符合: https://programmercarl.com/0112.路径总和.html#算法公开课)
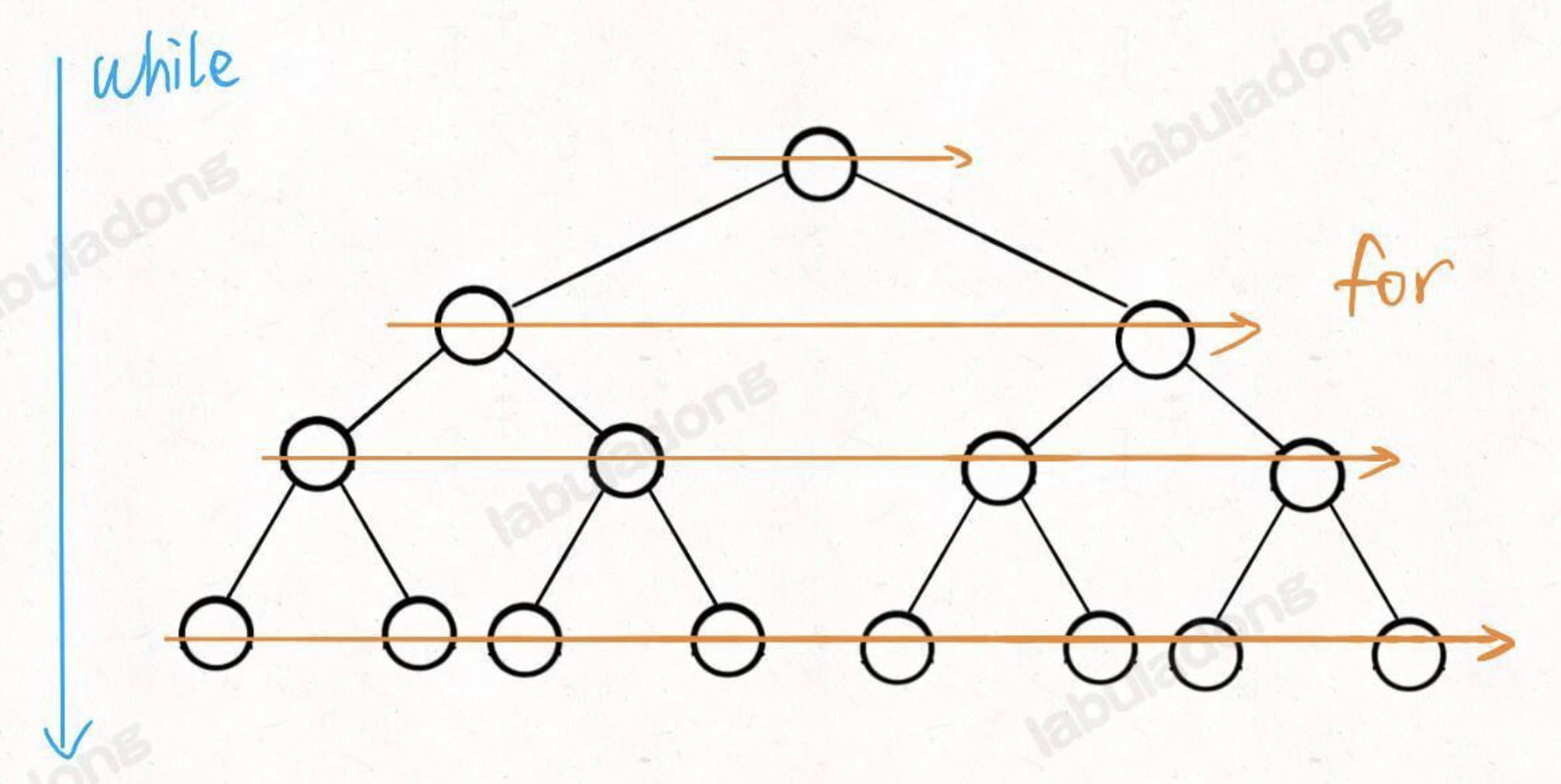
层序(相当重要)
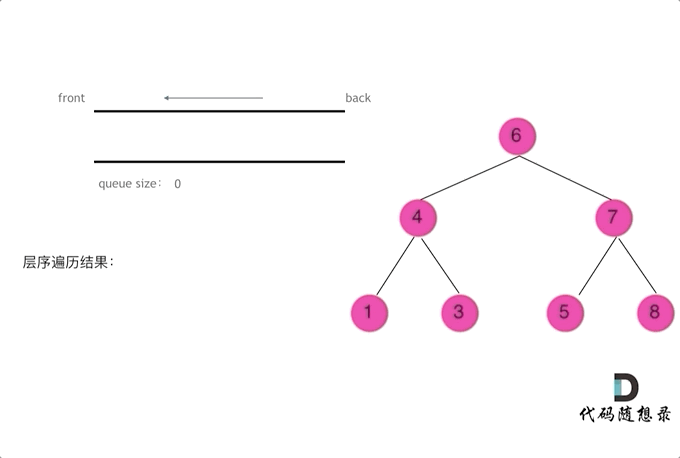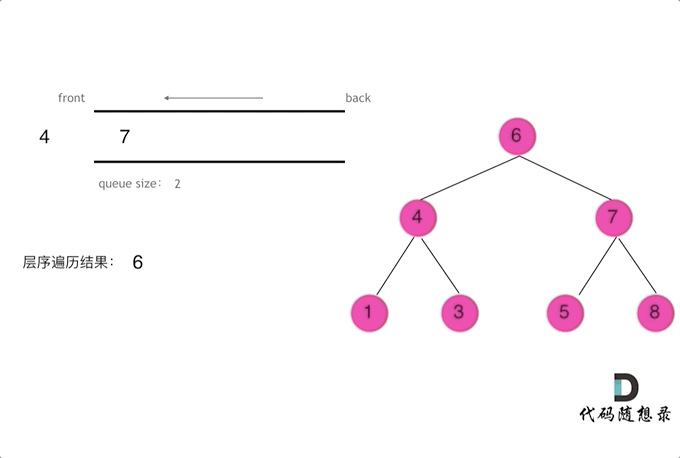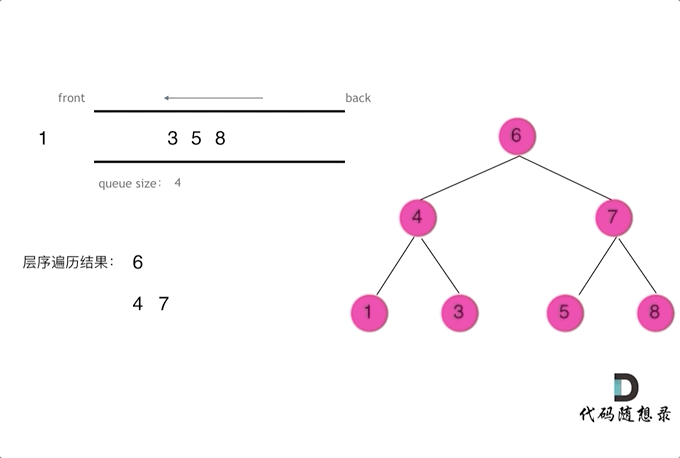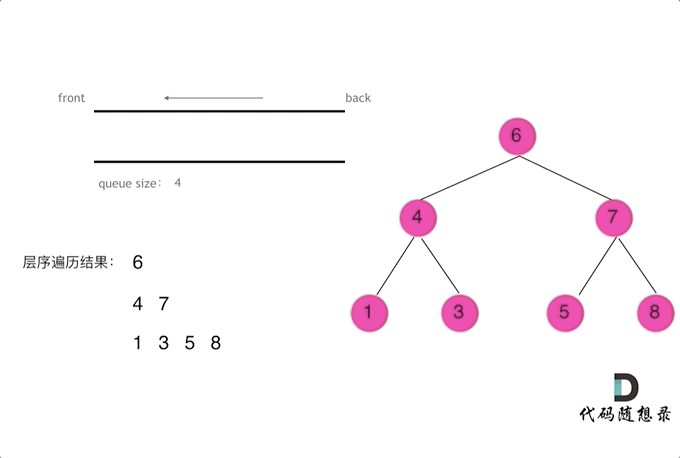
- 注意
while (len > 0) { }这个代码块里的就是同一层的结点处理 - 掌握了这个模板, 可以解决 70% 的二叉树题目
1 | class Solution { |
前序(迭代法重要)
.gif)
- 普通二叉树常用
- 前序遍历是中左右,每次先处理的是中间节点,那么先将根节点放入栈中,然后将右孩子加入栈,再加入左孩子。
- 为什么要先加入 右孩子,再加入左孩子呢? 因为这样出栈的时候才是中左右的顺序。
- 掌握了之后可以求
路径问题
1 | class Solution { |
中序(迭代法重要)
.gif)
- 二叉搜索树BST常用, 因为 BST 的 中序遍历 出来是个有序的递增数组)
- 中序遍历是左中右,先访问的是二叉树顶部的节点,然后一层一层向下访问,直到到达树左面的最底部,再开始处理节点(也就是在把节点的数值放进result数组中),这就造成了处理顺序和访问顺序是不一致的。
- 那么在使用迭代法写中序遍历,就需要借用指针的遍历来帮助访问节点,栈则用来处理节点上的元素。
1 | class Solution { |
后序(迭代法不重要,但递归解法的理解很重要)
- 后序
迭代法很少用到, 会前序按照以下方法就会写后序:- 先序遍历是
中左右 - 调整代码左右循序
- 变成
中右左-> 反转result数组 ->左右中 - 后序遍历是
左右中
- 先序遍历是
- 后序遍历的
递归法用得着, 那种需要从树底下往上走来统计信息的就用得到, 如公共祖先这种题就需要后序遍历递归法
举些具体的例子来感受下它们的能力区别。现在给你一棵二叉树,我问你两个简单的问题:
- 如果把根节点看做第 1 层,如何打印出每一个节点所在的层数?
- 如何打印出每个节点的左右子树各有多少节点?
第一个问题可以这样写代码:1
2
3
4
5
6
7
8
9
10
11
12
13// 二叉树遍历函数
void traverse(TreeNode root, int level) {
if (root == null) {
return;
}
// 前序位置
printf("Node %s at level %d", root.val, level);
traverse(root.left, level + 1);
traverse(root.right, level + 1);
}
// 这样调用
traverse(root, 1);
第二个问题可以这样写代码:
1 | // 定义:输入一棵二叉树,返回这棵二叉树的节点总数 |
这两个问题的根本区别在于:
一个节点在第几层,你从根节点遍历过来的过程就能顺带记录,用递归函数的参数就能传递下去;而以一个节点为根的整棵子树有多少个节点,你必须遍历完子树之后才能数清楚,然后通过递归函数的返回值拿到答案。
结合这两个简单的问题,你品味一下后序位置的特点,只有后序位置才能通过返回值获取子树的信息。
那么换句话说,一旦你发现题目和子树有关,那大概率要给函数设置合理的定义和返回值,在后序位置写代码了。
路径(重要)
- https://programmercarl.com/0257.二叉树的所有路径.html#思路
- https://leetcode.com/problems/binary-tree-paths/
- 学会后可以解”求根到叶子节点数字之和”: https://leetcode.com/problems/sum-root-to-leaf-numbers/
- https://leetcode.com/problems/path-sum/description/
https://leetcode.com/problems/path-sum-ii/description/
Given the root of a binary tree and an integer targetSum, return all root-to-leaf paths where the sum of the node values in the path equals targetSum. Each path should be returned as a list of the node values, not node references.
A root-to-leaf path is a path starting from the root and ending at any leaf node. A leaf is a node with no children.
- 要求从根节点到叶子的路径,所以需要前序遍历,这样才方便让父节点指向孩子节点,找到对应的路径。
- 注意其中的回溯, 特别是 count 的回溯注释, 方便深刻的理解回溯
1 | class Solution { |
高度
- 二叉树节点的高度:指从
该节点到叶子节点的最长简单路径边的条数或者节点数 - 二叉树节点的深度:指从
根节点到该节点的最长简单路径边的条数或者节点数 - 根节点的高度就是二叉树的最大深度
深度
- 求深度用
层序遍历是最适合的最直观容易理解 - 二叉树的深度: 根节点到最远叶子节点的最长路径上的节点数。
- 叶子节点: 是指没有子节点的节点。
最大深度
- https://programmercarl.com/0104.二叉树的最大深度.html
- https://leetcode.com/problems/maximum-depth-of-binary-tree/
使用迭代法的话,使用层序遍历是最为合适的,因为最大的深度就是二叉树的层数,和层序遍历的方式极其吻合。
在二叉树中,一层一层的来遍历二叉树,记录一下遍历的层数就是二叉树的深度,
迭代法
层序遍历:
1 | class Solution { |
递归法1-回溯(重要)
- 掌握后可以解树的最小深度, lc111: https://leetcode.com/problems/minimum-depth-of-binary-tree/description/
- 这个递归法中的
depth的计算写法 对于很多用到深度信息的二叉树的递归解都很有帮助, 算是个模板套路
1 | class Solution { |
递归法2
后序遍历, 掌握后可以解 树的最大直径 lc543: https://leetcode.com/problems/diameter-of-binary-tree/description/):
1 | class Solution { |
最小深度
- https://programmercarl.com/0111.二叉树的最小深度.html#算法公开课
- https://leetcode.com/problems/minimum-depth-of-binary-tree/description/
最小深度: 是从根节点到最近叶子节点的最短路径上的节点数量。
迭代法
层序遍历:
1 | class Solution { |
递归法-回溯
1 | class Solution { |
最近公共祖先(重要)
- https://programmercarl.com/0236.二叉树的最近公共祖先.html#算法公开课
- 自底向上查找就好了,这样就可以找到公共祖先了。那么二叉树如何可以自底向上查找呢?回溯啊,二叉树回溯的过程就是从低到上。
后序遍历(左右中)就是天然的回溯过程,可以根据左右子树的返回值,来处理中节点的逻辑。 - 如何判断一个节点是节点q和节点p的公共祖先呢? 判断逻辑是 如果递归遍历遇到q,就将q返回,遇到p 就将p返回,那么如果 左右子树的返回值都不为空,说明此时的中节点,一定是q 和p 的最近祖先。
1 | class Solution { |
二叉搜索树-诀窍(重要)
- 二叉搜索树的中序遍历是个递增有序数组, 利用好这一点非常方便解题
- 二叉搜索树的迭代遍历很好写, 大多数时候用不到递归方式来解题
- 空二叉树是二叉搜索树
- https://labuladong.online/algo/data-structure/bst-part2/#一、判断-bst-的合法性
https://leetcode.com/problems/validate-binary-search-tree/
Given the root of a binary tree, determine if it is a valid binary search tree (BST).
1 | boolean isValidBST(TreeNode root) { |
但是这个算法出现了错误,BST 的每个节点应该要小于右边子树的所有节点,
错误的原因在于,对于每一个节点 root,代码值检查了它的左右孩子节点是否符合左小右大的原则;但是根据 BST 的定义,root 的整个左子树都要小于 root.val,整个右子树都要大于 root.val。
问题是,对于某一个节点 root,他只能管得了自己的左右子节点,怎么把 root 的约束传递给左右子树呢?请看正确的代码:
1 | // https://labuladong.online/algo/data-structure/bst-part2/#一、判断-bst-的合法性 |
我们通过使用辅助函数,增加函数参数列表,在参数中携带额外信息,将这种约束传递给子树的所有节点,这也是二叉树算法的一个小技巧吧。
回溯
诀窍与模板
- 回溯本质是dfs, 所以回溯的模板和图论的dfs模板极为类似
- https://programmercarl.com/回溯算法理论基础.html#理论基础
- 起名: 在回溯算法中,我的习惯是函数起名字为backtrack,这个起名大家随意。
- 返回值: 回溯算法中函数返回值一般为void。
- 参数: 因为回溯算法需要的参数可不像二叉树递归的时候那么容易一次性确定下来,所以一般是先写逻辑,然后需要什么参数,就填什么参数。
1 | // DFS 算法把「做选择」「撤销选择」的逻辑放在 for 循环外面 |
看到了吧,你回溯算法必须把「做选择」和「撤销选择」的逻辑放在 for 循环里面,否则怎么拿到「树枝」的两个端点?
组合
没有剪枝的版本
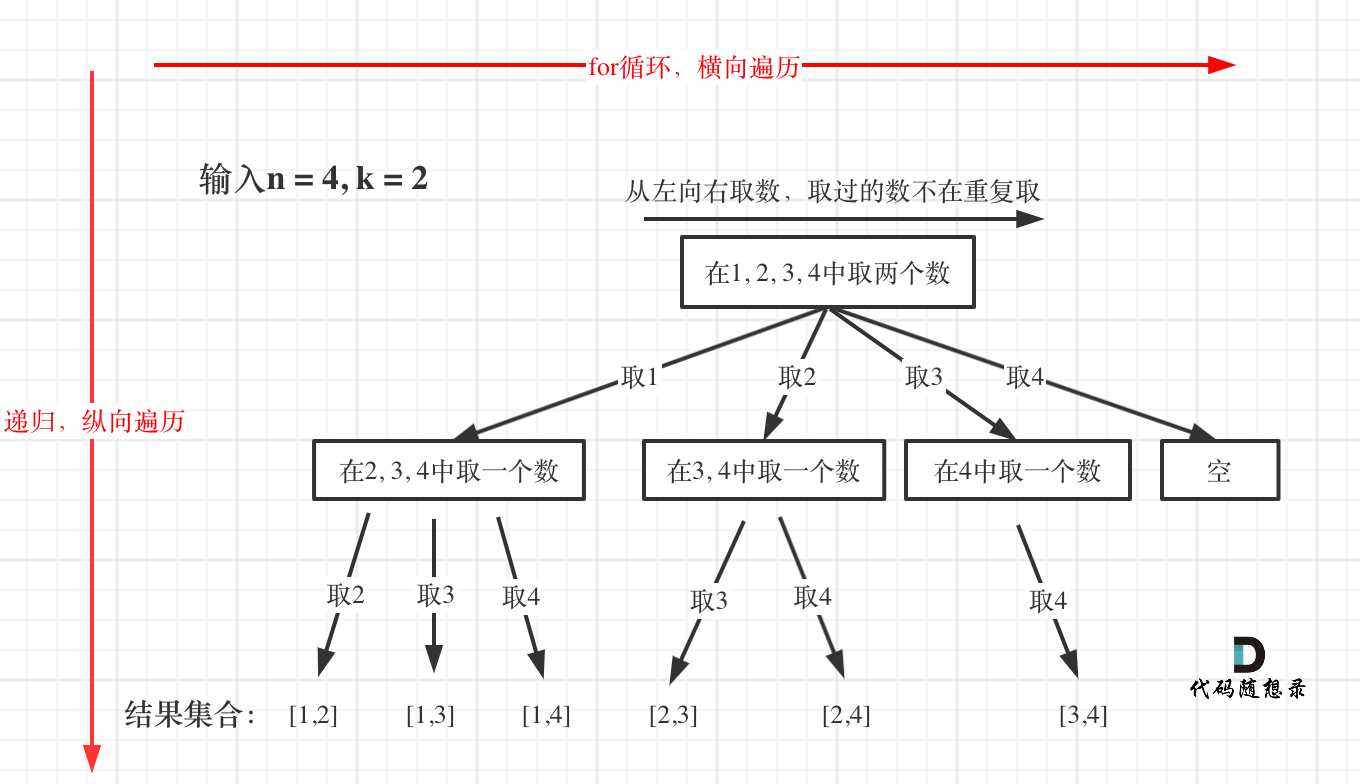
1 | class Solution { |
剪枝的版本
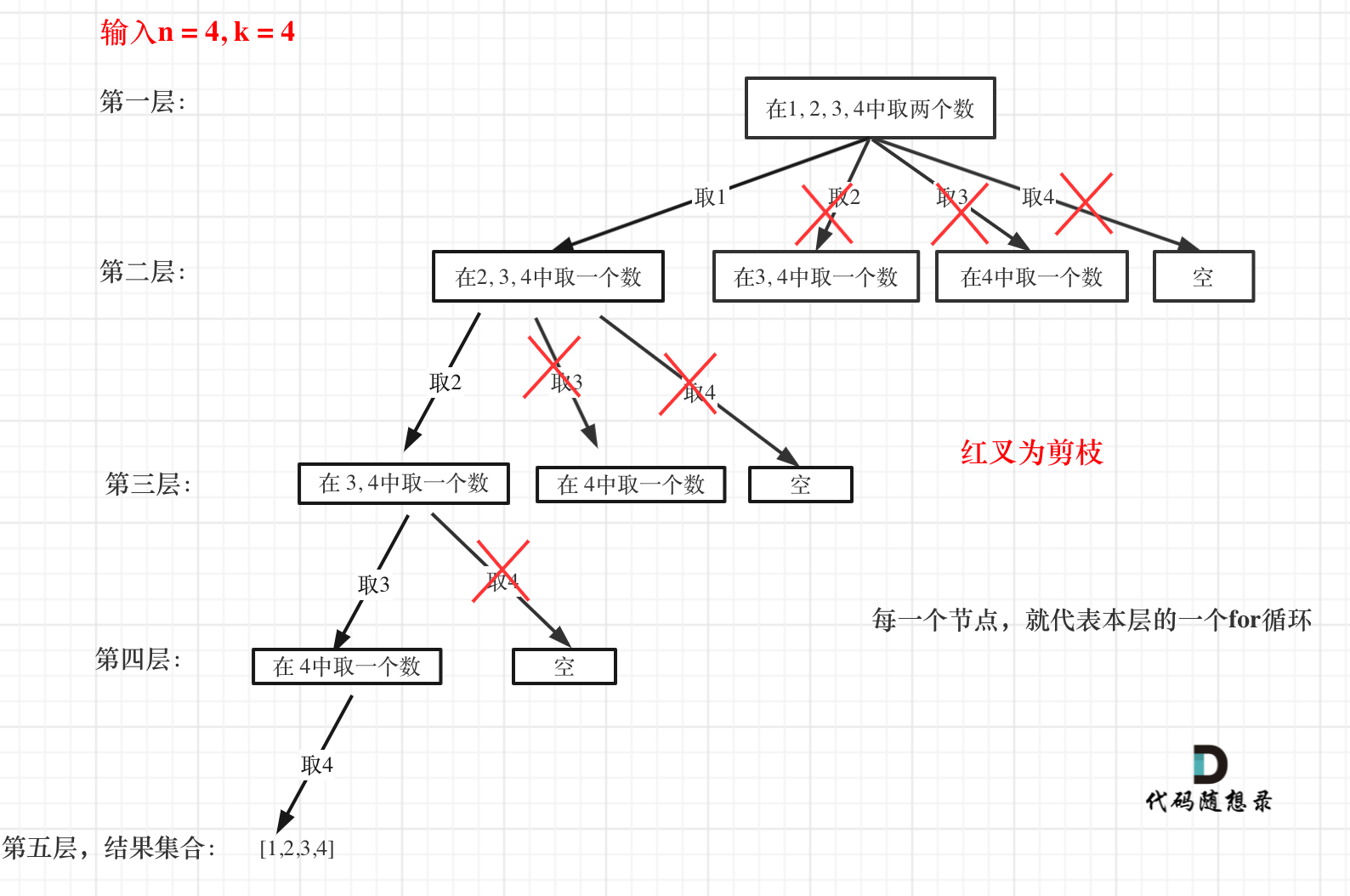
图中每一个节点(图中为矩形),就代表本层的一个for循环,那么每一层的for循环从第二个数开始遍历的话,都没有意义,都是无效遍历。
所以,可以剪枝的地方就在递归中每一层的for循环所选择的起始位置。
如果for循环选择的起始位置之后的元素个数 已经不足 我们需要的元素个数了,那么就没有必要搜索了。
注意代码中i,就是for循环里选择的起始位置。
for (int i = startIndex; i <= n; i++) {
接下来看一下优化过程如下:
- 已经选择的元素个数:
path.size(); - 还需要的元素个数为:
k - path.size(); - 在集合n中i最大可以从该起始位置开始遍历 :
n - (k - path.size()) + 1(备注:n - (k - path.size())就是表示从已经最大的数n往回退几个数再开始搜索遍历, 退几个数呢? 退k - path.size()个数, 后面多出来的那个+1是因为要包括起始位置,我们要是一个左闭的集合)
那为什么 n - (k - path.size()) + 1 有个+1呢? 因为包括起始位置,我们要是一个左闭的集合。
举个例子,n = 4,k = 3, 目前已经选取的元素为0个(即path.size()为0),n - (k - 0) + 1 即 4 - ( 3 - 0) + 1 = 2。
从2开始搜索都是合理的,可以是组合[2, 3, 4]。从”3”开始就不合理了, 因为只能[3, 4, ?], “4”后面没有了, 只有2个数字”3”和”4”能用.
这里大家想不懂的话,建议也举一个例子,就知道是不是要+1了。
所以优化之后的for循环是:
for (int i = startIndex; i <= n - (k - path.size()) + 1; i++) // i为本次搜索的起始位置
优化后整体代码 diff 如下:
1 | class Solution { |
图论
诀窍
dfs一般用来解决
求所有可达路径问题- 代码框架很类似回溯的代码框架, 因为回溯其实就是在做dfs
图论dfs框架 1
2
3
4
5
6
7
8
9
10
11
12void dfs(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本节点所连接的其他节点) {
处理节点;
dfs(图,选择的节点); // 递归
回溯,撤销处理结果
}
}
- 代码框架很类似回溯的代码框架, 因为回溯其实就是在做dfs
bfs一般用来解决
求最短路径问题- 只要BFS只要搜到终点一定是一条最短路径, 因为是一层一层一圈一圈来搜的, 搜到的就一定是最短的
- 代码框架很类似二叉树的bfs, 如下:
图论bfs框架 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 表示四个方向
// grid 是地图,也就是一个二维数组
// visited标记访问过的节点,不要重复访问
// x,y 表示开始搜索节点的下标
void bfs(vector<vector<char>>& grid, vector<vector<bool>>& visited, int x, int y) {
queue<pair<int, int>> que; // 定义队列
que.push({x, y}); // 起始节点加入队列
visited[x][y] = true; // 只要加入队列,立刻标记为访问过的节点
while(!que.empty()) { // 开始遍历队列里的元素
pair<int ,int> cur = que.front(); que.pop(); // 从队列取元素
int curx = cur.first;
int cury = cur.second; // 当前节点坐标
for (int i = 0; i < 4; i++) { // 开始想当前节点的四个方向左右上下去遍历
int nextx = curx + dir[i][0];
int nexty = cury + dir[i][1]; // 获取周边四个方向的坐标
if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 坐标越界了,直接跳过
if (!visited[nextx][nexty]) { // 如果节点没被访问过
que.push({nextx, nexty}); // 队列添加该节点为下一轮要遍历的节点
visited[nextx][nexty] = true; // 只要加入队列立刻标记,避免重复访问
}
}
}
}