etcd
- etcd 参考 https://wingsxdu.com/post/database/etcd/#gsc.tab=0
- raft 参考 https://www.jianshu.com/p/5aed73b288f7
etcd 是一个 Go 语言编写的分布式、高可用的强一致性键值存储系统,用于提供可靠的分布式键值(key-value)存储、配置共享和服务发现等功能。 etcd可以用于存储关键数据和实现分布式调度,它在现代化的集群运行中能够起到关键性的作用。
Raft用于保证分布式数据的一致性。动画演示Raft
Raft选主过程
动画演示Raft选主
前提知识:
- Election timeout选举周期: The election timeout is the amount of time a follower waits until becoming a candidate.
- heartbeat timeout心跳时间间隔
选主的具体流程如下:
- 假设三个节点的集群,三个节点上均运行 一个随机选举周期timer(每个 Timer 持续时间是随机的, 一般是150~300ms),Raft算法使用随机 Timer 来初始化 Leader 选举流程,第一个节点率先完成了 Timer,那它就要变成candidate,然后带着自身的数据版本信息发起vote
- 随后它就会向其他两个节点发送成为 Leader 的请求,其他follower节点接收到请求后会以投票回应然后第一个节点是否被选举为 Leader。
- 在每一任期内,最多允许一个节点被选举为leader
- 投票后就会重置一下选举周期timer, 重新计时
- 检查是否candidate的数据版本比自己要新, 如果比自己旧, 那就会无情拒绝,
- 如果有都变成了candidate的多个节点,follower们采取哪个candidate先来先投票的策略。
- 在一个任期内,一个节点只能投一票
- 如果超过半数的follower都认为他是合适做领导的,那么恭喜,新的leader产生了.
- 成为 Leader 后,该节点会以固定心跳时间间隔heartbeat timeout向其他节点发送通知确保自己仍是Leader,follower收到了心跳则会重置一下选举周期timer, 重新计时。
- 有些情况下当 Follower 们收不到 Leader 的通知后,比如说 Leader 节点宕机或者失去了连接,则其他节点当选举周期timer到期后就会会重复之前选举过程选举出新的 Leader。
- 如果多个candidate同时发起了选举:
- 只有follower能投票且只能投一次(投了a就不能投b了), candidate B 是不能给candidate A 投票的
- 如果其中一个candidate拿到了超过半数的选票也可以成为leader
- 如果所有candidate都没有获得大多数选票时(很可能发生这种情况, 因为在一个任期内,一个节点只能投一票, 投了A就不能再投B了),则所有节点还是还是继续走一个随机选举周期timer的选举流程, 等待下一次某个节点的选举周期timer触发则term加1进行下一任期的选举
数据读写流程如何保证一致性的
etcd写请求流程
写请求的过程简要总结:
- 在etcd-raft实现中,所有的写请求都会由leader执行并将请求日志同步到follower节点,且若follower节点收到客户端的写请求,则是把写请求转发给leader。
- 待该 写请求 日志被复制到集群半数以上的节点时,该 写请求 日志会被 Leader 节点确认为己提交,Leader 会回复客户端写请求操作成功
为什么说即使完成了一次写请求流程也有可能读到过期数据? etcd又是如何解决此问题的?(见此etcd线性一致性读)
- 前提知识:
- consensus共识在实现机制上属于复制状态机(Replicated State Machine)的范畴,复制状态机是一种很有效的容错技术,基于复制日志来实现,每个 Server 存储着一份包含命令序列的日志文件,状态机会按顺序执行这些命令。因为日志中的命令和顺序都相同,因此所有节点会得到相同的数据。因此保证系统一致性就简化为保证操作日志的一致,这种复制日志的方式被大量运用,如 GSF、HDFS、ZooKeeper和 etcd 都是这种机制。
- raft中的日志(log entry)并不是系统Debug日志,而是序列化后的command,这些Command复制到各个节点后,通过序列化内容的解析出命令后,在各个节点上执行并返回操作结果从而实现复制状态机
- 原因:
- etcd 就完成了一次写操作仅仅代表写请求日志操作成功完毕了,写操作成功仅仅意味着日志达成了一致(已经落盘),并不意味着这条日志被应用到状态机(状态机 apply 日志的行为在大多数 Raft 算法的实际实现中都是异步的, raft不管具体状态机如何实现, 他只规定了日志的复制流程算法标准),而并不能确保当前状态机也已经 apply 了日志。所以此时读取状态机并不能准确反应数据的状态,很可能会读到过期数据。
- Leader 应用了这条日志也不意味着所有的 Follower 都应用了这条日志,每个节点会独立地决定应用日志的时机,这中间可能存在着一定的延迟。虽然 etcd 应用日志的过程是异步的,但是这种批处理策略能够一次批量写入多条日志,可以提升节点的 I/O 性能。
- etcd 有额外的机制解决这个问题。这部分内容会在下文的etcd线性一致性读介绍到。
etcd线性一致性读
etcd 两种方案来保证线性一致性读:
- ReadIndex 方案
- ReadIndex是etcd-raft的默认方案。
- 虽然状态机应用日志的行为是异步的,但是已经提交的日志都满足线性一致,那么只要等待这些日志都应用到状态机中再执行查询,读请求也可以满足线性一致。
- ReadIndex机制的执行流程如下:
- 从 leader节点读:
1. 读操作执行前记录『此时』集群的 CommittedIndex(commitIndex即为log中最后一个被提交的index值. 因为此时自己就是leader, 所以从 leader 获取到的 commited index 就作为此次读请求的 ReadIndex),记为ReadIndex;
2. 向 Follower 发送心跳消息,如果超过法定人数的节点响应了心跳消息,那么就能保证 当前Leader 节点还是leader, 主要是防止本leader是已经隔离的了小集群里的leader,这样就确保了 Leader 节点的数据都是最新的
3. 等待状态机『至少』应用到ReadIndex,即 AppliedIndex >= ReadIndex;
4. 执行读请求,将结果返回给 Client。 - 从 follower 节点读:
- Follower 先向 Leader 询问 readIndex,Leader 收到 Follower 的请求后依然要通过 上述的第2步骤广播心跳确认自己 Leader 的身份,然后返回当前的 commitIndex 作为 readIndex,Follower 拿到 readIndex 后,等待本地的 applyIndex 大于等于 readIndex 后,即可读取状态机中的数据返回。
- 从 leader节点读:
- LeaseRead 方案
- etcd-raft不推荐采用此方案
- 基本的思路是 Leader 取一个比 Election Timeout选举周期 小的租期,在租期不会发生选举,确保 Leader 不会变,所以可以跳过 ReadIndex 的第二步,也就降低了延时。
- LeaseRead 与 ReadIndex 类似,但更进一步,不仅省去了 Log,还省去了网络交互。它可以大幅提升读的吞吐也能显著降低延时。
- 缺陷: LeaseRead 的正确性和时间挂钩,因此时间的实现至关重要,如果漂移严重,这套机制就会有问题。LeaseRead 的正确性和时间的实现挂钩,由于不同主机的 CPU 时钟有误差,所以也有可能读取到过期的数据。
etcd存在脑裂情况吗
etcd不存在脑裂情况.
众所周知 etcd 使用 Raft 协议来解决数据一致性问题。一个 Raft Group 只能有一个 Leader 存在,如果一旦发生网络分区,Leader 只会在多数派一边被选举出来,而少数派则全部处于 Follower 或 Candidate 状态,所以一个长期运行的集群是不存在脑裂问题的。etcd 官方文档也明确了这一点:
The majority side becomes the available cluster and the minority side is unavailable; there is no “split-brain” in etcd.
但是有一种特殊情况,假如旧的 Leader 和集群其他节点出现了网络分区,其他节点选出了新的 Leader,但是旧 Leader 并没有感知到新的 Leader,那么此时集群可能会出现一个短暂的「双 Leader」状态。这种情况并不能称之为脑裂,原因如下:
- etcd网络分区时
- 如果leader在少数派
- 此时多数派会有follower选举周期timer触发则任期term增加, 并且会选出多数派新leader,
- 此时少数派leader会检查法定人数是否大于节点数量一半, 检查确认后则少数派集群进入是不可用状态,不支持raft请求,只支持非一致性读请求。一旦网络分区清除,少数派因为任期term较小, 则这边会自动承认来自多数这边的 leader 并同步多数派的数据状态。
- 如果在leader在多数派, 则一切照旧
- 如果leader在少数派
- 网络分区时 etcd 也有 ReadIndex、LeaseRead 机制来解决这种状态下的数据一致性问题
新Leader会无条件提交旧Leader日志吗
其实这里有 4 种情况:
- Leader 复制给少数节点,然后宕机
- Leader 复制给多数节点,然后宕机
- Leader 复制给多数节点,本地提交成功,返回客户端成功,然后宕机
场景 1-2 压根没有给客户端承诺,所以是新 Leader 不会立即 commit 前任 Leader 的日志;场景 3 承诺了客户端,无论如何日志是不允许丢的,所以新 Leader 一定会 commit 日志。
etcd可以偶数个部署吗
可以, 但非常不建议.
偶数个节点的集群非但不能提升容错能力,反而会带来资源的浪费并可能使选举的时间变长。同时在奇数个集群的情况下,即使产生网络分区也能保证始终有一方占据大多数的节点,进而选举出新的 Leader 来保证集群的可用。而偶数个节点则可能会出现对半分的场景,这样任意一方都无法选举出 Leader,导致集群的不可用。
etcd架构及解析
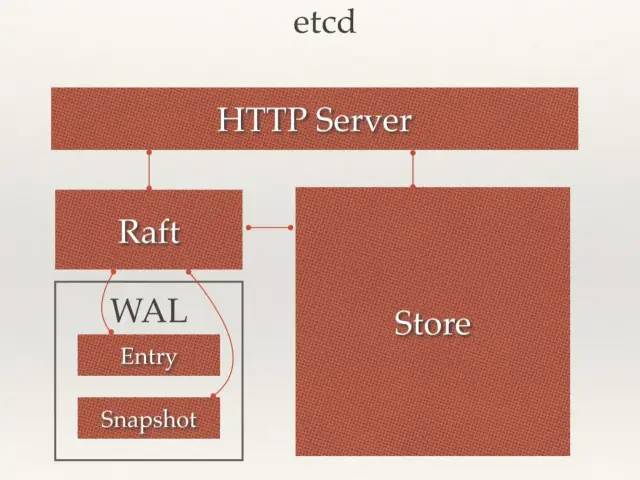
从 etcd 的架构图中我们可以看到,etcd 主要分为四个部分。
- HTTP Server: 用于处理用户发送的 API 请求以及其它 etcd 节点的同步与心跳信息请求。
- Store: 用于处理 etcd 支持的各类功能的事务,包括数据索引、节点状态变更、监控与反馈、事件处理与执行等等,是 etcd 对用户提供的大多数 API 功能的具体实现。
- Raft: Raft 强一致性算法的具体实现,是 etcd 的核心。
- WAL: Write Ahead Log(预写式日志),是 etcd 的数据存储方式。除了在内存中存有所有数据的状态以及节点的索引以外,etcd 就通过 WAL 进行持久化存储。WAL 中,所有的数据提交前都会事先记录日志。
Snapshot 是为了防止数据过多而进行的状态快照;Entry 表示存储的具体日志内容。
通常,一个用户的请求发送过来,会经由 HTTP Server 转发给 Store 进行具体的事务处理,如果涉及到节点的修改,则交给 Raft 模块进行状态的变更、日志的记录,然后再同步给别的 etcd 节点以确认数据提交,最后进行数据的提交,再次同步。
etcd的使用场景
- 服务发现
- 负载均衡
- 分布式锁
- 分布式队列
上面说到etcd可以很容易的实现分布式锁, 锁服务有两种使用方式,一是保持独占,二是控制时序。通过控制时序,即所有想要获得锁的用户都会被安排执行,但是获得锁的顺序也是全局唯一的,同时决定了执行顺序, 就可以实现分布式队列。etcd 为此也提供了一套 API(自动创建有序键),对一个目录建值时指定为POST动作,这样 etcd 会自动在目录下生成一个当前最大的值为键,存储这个新的值(客户端编号)。同时还可以使用 API 按顺序列出所有当前目录下的键值。此时这些键的值就是客户端的时序,而这些键中存储的值可以是代表客户端的编号。
etcd概念术语
- Raft: etcd所采用的保证分布式系统强一致性的算法。
- Node: 一个Raft状态机实例。
- Member: 一个etcd实例。它管理着一个Node,并且可以为客户端请求提供服务。
- Cluster: 由多个Member构成可以协同工作的etcd集群。
- Peer: 对同一个etcd集群中另外一个Member的称呼。
- Client: 向etcd集群发送HTTP请求的客户端。
- WAL: 预写式日志,etcd用于持久化存储的日志格式。
- snapshot: etcd防止WAL文件过多而设置的快照,存储etcd数据状态。
- Proxy: etcd的一种模式,为etcd集群提供反向代理服务。
- Leader: Raft算法中通过竞选而产生的处理所有数据提交的节点。
- Follower: 竞选失败的节点作为Raft中的从属节点,为算法提供强一致性保证。
- Candidate: 当Follower超过一定时间接收不到Leader的心跳时转变为Candidate开始竞选。
- Term: 某个节点成为Leader到下一次竞选时间,称为一个Term。
- Index: 数据项编号。Raft中通过Term和Index来定位数据。
- Entry: 表示存储的具体日志内容。
etcd数据存储
etcd 的存储分为内存存储和持久化(硬盘)存储两部分,内存中的存储除了顺序化的记录下所有用户对节点数据变更的记录外,还会对用户数据进行索引、建堆等方便查询的操作。而持久化则使用预写式日志(WAL:Write Ahead Log)进行记录存储。
在 WAL 的体系中,所有的数据在提交之前都会进行日志记录。在 etcd 的持久化存储目录中,有两个子目录。一个是 WAL,存储着所有事务的变化记录;另一个则是 snapshot,用于存储某一个时刻 etcd 所有目录的数据。通过 WAL 和 snapshot 相结合的方式,etcd 可以有效的进行数据存储和节点故障恢复等操作。
- WAL(Write Ahead Log)最大的作用是记录了整个数据变化的全部历程。在 etcd 中,所有数据的修改在提交前,都要先写入到 WAL 中。使用 WAL 进行数据的存储使得 etcd 拥有两个重要功能:
- 故障快速恢复: 当你的数据遭到破坏时,就可以通过执行所有 WAL 中记录的修改操作,快速从最原始的数据恢复到数据损坏前的状态。
- 数据回滚(undo)/ 重做(redo):因为所有的修改操作都被记录在 WAL 中,需要回滚或重做,只需要方向或正向执行日志中的操作即可。
- WAL的缺陷: WAL 是一种 Append Only 的日志文件,只会在文件结尾不断地添加新日志,这样做可以避免大量随机 I/O 带来的性能损失,但是随着程序的运行,节点需要处理客户端和集群中其他节点发来的大量请求,相应的 WAL 日志量也会不断增加,这会占用大量的磁盘空间。当节点宕机后,如果要恢复其状态,则需要从头读取全部的 WAL 日志文件,这显然是非常耗时的。
- WAL的缺陷的解决方案: 快照, 为了解决WAL的这个缺陷,etcd 会定期创建快照,将整个节点的状态进行序列化,然后写入稳定的快照文件中,在该快照文件之前的日志记录就可以全部丢弃掉。在恢复节点状态时会先加载快照文件,使用快照数据将节点恢复到对应的状态,之后从 WAL 文件读取快照之后的数据,将节点恢复到正确的状态。
- etcd 的快照有两种:
- 一种是用于存储某一时刻 etcd 的所有数据的数据快照,
- 另一种是用于集群中较慢节点追赶数据的 RPC 快照。