编码知识
Base64 的原理?编码后比编码前是大了还是小了。
结论:
大了. 因为Base64 编码本质上是一种将二进制数据转成文本数据的方案。对于非二进制数据,是先将其转换成二进制形式,然后每连续 6 比特(2 的 6 次方 = 64)计算其十进制值,根据该值在上面的索引表中找到对应的字符,最终得到一个文本字符串。也就是说, 每 3 个原始字符编码成 4 个字符,如果原始字符串长度不能被 3 整除,那怎么办?使用 0 值来补充原始字符串。
base64的原理
Base64 编码之所以称为 Base64,是因为其使用 64 个字符来对任意数据进行编码,同理有 Base32、Base16 编码。标准 Base64 编码使用的 64 个字符为: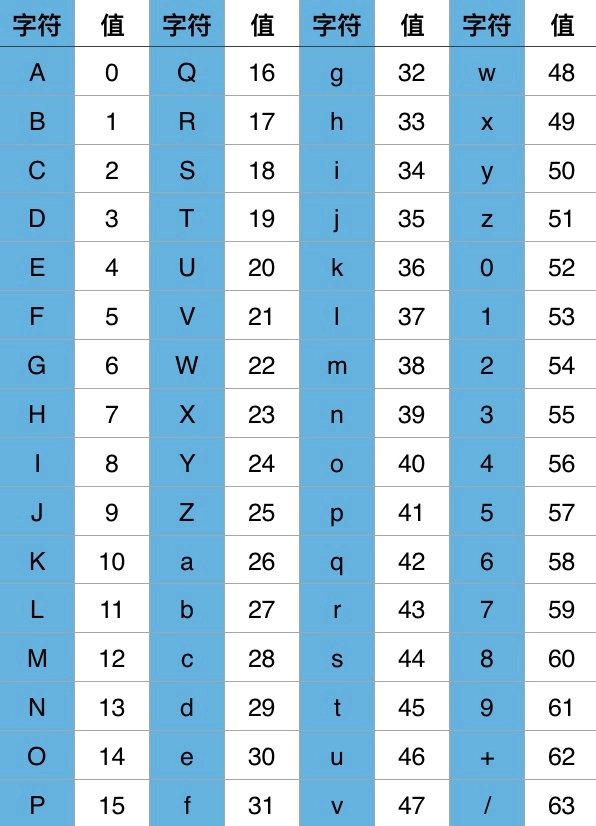
这 64 个字符是各种字符编码(比如 ASCII 编码)所使用字符的子集,基本,并且可打印。唯一有点特殊的是最后两个字符,因对最后两个字符的选择不同,Base64 编码又有很多变种,比如 Base64 URL 编码。
Base64 编码本质上是一种将二进制数据转成文本数据的方案。对于非二进制数据,是先将其转换成二进制形式,然后每连续 6 比特(2 的 6 次方 = 64)计算其十进制值,根据该值在上面的索引表中找到对应的字符,最终得到一个文本字符串。
假设我们要对 Hello! 进行 Base64 编码,按照 ASCII 表,其转换过程如下图所示:
可知 Hello! 的 Base64 编码结果为 SGVsbG8h ,原始字符串长度为 6 个字符,编码后长度为 8 个字符,每 3 个原始字符经 Base64 编码成 4 个字符,编码前后长度比 4/3,这个长度比很重要 - 比原始字符串长度短,则需要使用更大的编码字符集,这并不我们想要的;长度比越大,则需要传输越多的字符,传输时间越长。Base64 应用广泛的原因是在字符集大小与长度比之间取得一个较好的平衡,适用于各种场景。
是不是觉得 Base64 编码原理很简单?
但这里需要注意一个点:Base64 编码是每 3 个原始字符编码成 4 个字符,如果原始字符串长度不能被 3 整除,那怎么办?使用 0 值来补充原始字符串。
以 Hello!! 为例,其转换过程为: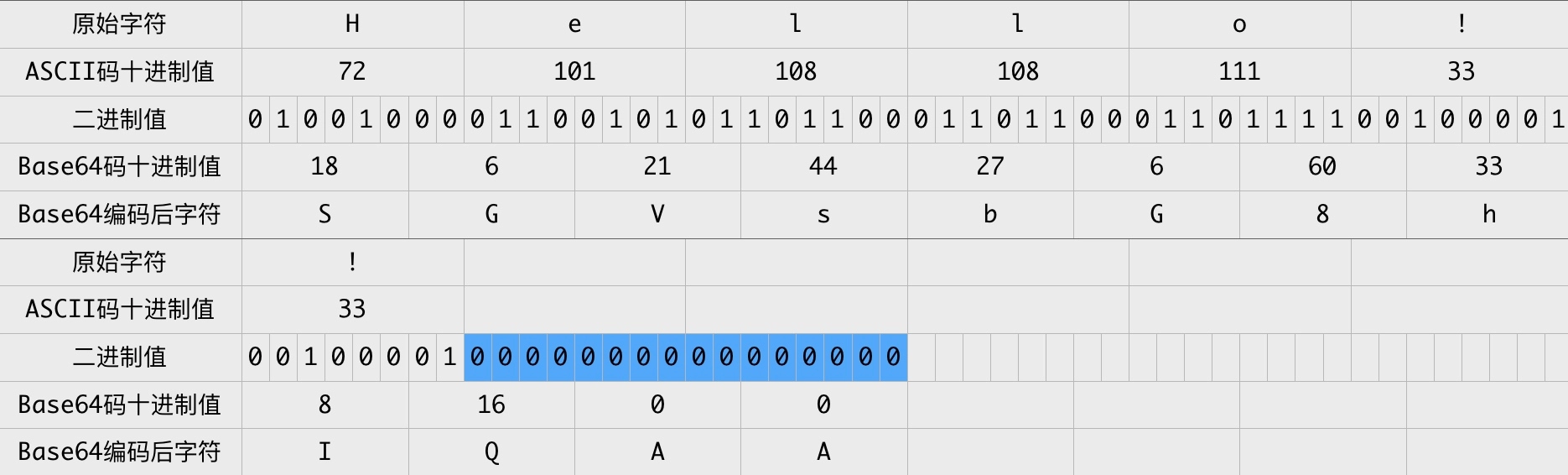
注:图表中蓝色背景的二进制 0 值是额外补充的。
Hello!! Base64 编码的结果为 SGVsbG8hIQAA 。最后 2 个零值只是为了 Base64 编码而补充的,在原始字符中并没有对应的字符,那么 Base64 编码结果中的最后两个字符 AA 实际不带有效信息,所以需要特殊处理,以免解码错误。
标准 Base64 编码通常用 = 字符来替换最后的 A,即编码结果为 SGVsbG8hIQ==。因为 = 字符并不在 Base64 编码索引表中,其意义在于结束符号,在 Base64 解码时遇到 = 时即可知道一个 Base64 编码字符串结束。
如果 Base64 编码字符串不会相互拼接再传输,那么最后的 = 也可以省略,解码时如果发现 Base64 编码字符串长度不能被 4 整除,则先补充 = 字符,再解码即可。
解码是对编码的逆向操作,但注意一点:对于最后的两个 = 字符,转换成两个 A 字符,再转成对应的两个 6 比特二进制 0 值,接着转成原始字符之前,需要将最后的两个 6 比特二进制 0 值丢弃,因为它们实际上不携带有效信息。
utf8编码和unicode字符集
总结:
- unicode是个字符集, 只是一个符号对应表, 它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储
- utf8是unicode符号具体的编码方式, 规定了该怎么存储
说到utf8,就不得不说一下unicode了。 Unicode是一个很大的集合,每一个unicode对应一个符号,不管是中文的汉字,英文字符,日文,韩文等等。现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母 Ain,U+0041表示英语的大写字母A,U+4E25表示汉字“严”。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。
需要注意的是,Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字“严”的unicode是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题,第一个问题是:如何才能区别unicode和ascii?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是:我们已经知道,英文字母只用一个字节表示就够了,如果unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
它们造成的结果是:
1)出现了unicode的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示unicode。
2)unicode在很长一段时间内无法推广,直到互联网的出现。
UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8就是在互联网上使用最广的一种unicode的实现方式。其他实现方式还包括UTF-16和UTF-32,不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8是Unicode的实现方式之一。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位(字节的最高位)设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
下表总结了编码规则,字母x表示可用编码的位。
Unicode符号范围 UTF-8编码方式(十六进制) | (二进制)1
2
3
4
5—————+———————————————————————
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
下面,还是以汉字“严”为例,演示如何实现UTF-8编码:
已知“严”的unicode是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800-0000 FFFF),因此“严”的UTF-8编码需要三个字节,即格式是“1110xxxx 10xxxxxx 10xxxxxx”。然后,从“严”的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,“严”的UTF-8编码是“11100100 10111000 10100101”,转换成十六进制就是E4B8A5。