python
- mro问题
- 怎么实现一个协程库?
- mock是啥: https://zhuanlan.zhihu.com/p/30380243
import流程
- 当Python的解释器遇到import语句或者其他上述导入语句时,它会先去查看sys.modules中是否已经有同名模块被导入了,
- 如果有就直接取来用;没有就去查阅sys.path里面所有已经储存的目录.
- sys.path这个列表初始化的时候,通常包含一些来自外部的库(external libraries)或者是来自操作系统的一些库,当然也会有一些类似于dist-package的标准库在里面.这些目录通常是被按照顺序或者是直接去搜索想要的–如果说他们当中的一个包含有期望的package或者是module,这个package或者是module将会在整个过程结束的时候被直接提取出来保存在sys.modules中(sys.modules是一个模块名:模块对象的字典结构).
- 当然,这个 sys.path 是可以修改的(正如上文提到的一种解决办法)。值得注意的是,如果当前目录包含有和标准库同名的模块,会直接使用当前目录的模块而不是标准模块。
- 当在这些个地址中实在是找不着时,它就会抛出一个ModuleNotFoundError错误.
- 当我们要导入一个模块(比如 foo )时,解释器首先会根据命名查找内置模块,如果没有找到,它就会去查找 sys.path 列表中的目录,看目录中是否有 foo.py 。sys.path 的初始值来自于:
- 运行脚本所在的目录(如果打开的是交互式解释器则是当前目录)
- PYTHONPATH 环境变量(类似于 PATH 变量,也是一组目录名组成)
- Python 安装时的默认设置
为啥字符串join比加号连接快
字符串是不可变对象,当用操作符+连接字符串的时候,每执行一次+都会申请一块新的内存,然后复制上一个+操作的结果和本次操作的右操作符到这块内存空间,因此用+连接字符串的时候会涉及好几次内存申请和复制。而join在连接字符串的时候,会先计算需要多大的内存存放结果,然后一次性申请所需内存并将字符串复制过去,这是为什么join的性能优于+的原因。所以在连接字符串数组的时候,我们应考虑优先使用join。
is和==的区别
官方文档中说 is 表示的是对象标示符(object identity),而 == 表示的是相等(equality)。is 的作用是用来检查对象的标示符是否一致,也就是比较两个对象在内存中的地址是否一样,而 == 是用来检查两个对象是否相等。
我们在检查 a is b 的时候,其实相当于检查 id(a) == id(b)。而检查 a == b 的时候,实际是调用了对象 a 的 eq() 方法,a == b 相当于 a.eq(b)。
一般情况下,如果 a is b 返回True的话,即 a 和 b 指向同一块内存地址的话,a == b 也返回True,即 a 和 b 的值也相等。
元类
参考: https://www.liaoxuefeng.com/wiki/1016959663602400/1017592449371072
python元类的使用场景, 比如orm框架, ORM全称“Object Relational Mapping”,即对象-关系映射,就是把关系数据库的一行映射为一个对象,也就是一个类对应一个表,这样,写代码更简单,不用直接操作SQL语句。
type()函数既可以返回一个对象的类型,又可以创建出新的类型,比如,我们可以通过type()函数创建出Hello类,而无需通过class Hello(object)...的定义:
1 | \>>> def fn(self, name='world'): # 先定义函数 |
要创建一个 class 对象,type()函数依次传入 3 个参数:
- class 的名称;
- 继承的父类集合,注意 Python 支持多重继承,如果只有一个父类,别忘了 tuple 的单元素写法;
- class 的方法名称与函数绑定,这里我们把函数
fn绑定到方法名hello上。
通过type()函数创建的类和直接写 class 是完全一样的,因为 Python 解释器遇到 class 定义时,仅仅是扫描一下 class 定义的语法,然后调用type()函数创建出 class。
正常情况下,我们都用class Xxx...来定义类,但是,type()函数也允许我们动态创建出类来,也就是说,动态语言本身支持运行期动态创建类,这和静态语言有非常大的不同,要在静态语言运行期创建类,必须构造源代码字符串再调用编译器,或者借助一些工具生成字节码实现,本质上都是动态编译,会非常复杂。
metaclass
除了使用type()动态创建类以外,要控制类的创建行为,还可以使用 metaclass。
metaclass,直译为元类,简单的解释就是:
当我们定义了类以后,就可以根据这个类创建出实例,所以:先定义类,然后创建实例。
但是如果我们想创建出类呢?那就必须根据 metaclass 创建出类,所以:先定义 metaclass,然后创建类。
连接起来就是:先定义 metaclass,就可以创建类,最后创建实例。
所以,metaclass 允许你创建类或者修改类。换句话说,你可以把类看成是 metaclass 创建出来的 “实例”。
我们先看一个简单的例子,这个 metaclass 可以给我们自定义的 MyList 增加一个add方法:
定义ListMetaclass,按照默认习惯,metaclass 的类名总是以 Metaclass 结尾,以便清楚地表示这是一个 metaclass:1
2
3
4class ListMetaclass(type):
def __new__(cls, name, bases, attrs):
attrs\['add'\] = lambda self, value: self.append(value)
return type.__new__(cls, name, bases, attrs)
有了 ListMetaclass,我们在定义类的时候还要指示使用 ListMetaclass 来定制类,传入关键字参数metaclass:1
2class MyList(list, metaclass=ListMetaclass):
pass
当我们传入关键字参数metaclass时,魔术就生效了,它指示 Python 解释器在创建MyList时,要通过ListMetaclass.__new__()来创建,在此,我们可以修改类的定义,比如,加上新的方法,然后,返回修改后的定义。
__new__()方法接收到的参数依次是:
- 当前准备创建的类的对象;
- 类的名字;
- 类继承的父类集合;
- 类的方法集合。
测试一下MyList是否可以调用add()方法:1
2
3
4\>>> L = MyList()
>>> L.add(1)
>> L
\[1\]
而普通的list没有add()方法:1
2
3
4
5\>>> L2 = list()
>>> L2.add(1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'list' object has no attribute 'add'
装饰器
1 | def log(func): |
观察上面的log,因为它是一个decorator,所以接受一个函数作为参数,并返回一个函数。我们要借助Python的@语法,把decorator置于函数的定义处:1
2
3
def now():
print('2015-3-25')
调用now()函数,不仅会运行now()函数本身,还会在运行now()函数前打印一行日志:
1 | >>> now() |
把@log放到now()函数的定义处,相当于执行了语句:now = log(now)
由于log()是一个decorator,返回一个函数,所以,原来的now()函数仍然存在,只是现在同名的now变量指向了新的函数,于是调用now()将执行新函数,即在log()函数中返回的wrapper()函数。
wrapper()函数的参数定义是(args, *kw),因此,wrapper()函数可以接受任意参数的调用。在wrapper()函数内,首先打印日志,再紧接着调用原始函数。
如果decorator本身需要传入参数,那就需要编写一个返回decorator的高阶函数,写出来会更复杂。比如,要自定义log的文本:1
2
3
4
5
6
7def log(text):
def decorator(func):
def wrapper(*args, **kw):
print('%s %s():' % (text, func.__name__))
return func(*args, **kw)
return wrapper
return decorator
这个3层嵌套的decorator用法如下:1
2
3
def now():
print('2015-3-25')
执行结果如下:1
2
3>>> now()
execute now():
2015-3-25
和两层嵌套的decorator相比,3层嵌套的效果是这样的:now = log('execute')(now)
我们来剖析上面的语句,首先执行log(‘execute’),返回的是decorator函数,再调用返回的函数,参数是now函数,返回值最终是wrapper函数。
python命令行参数
- -u参数的使用:python命令加上-u(unbuffered)参数后会强制其标准输出也同标准错误一样不通过缓存直接打印到屏幕。
- -c参数,支持执行单行命令/脚本。如:
python -c "import os;print('hello'),print('world')"
python -m test_folder/test.py与python test_folder/test有什么不同
桌面的test_folder文件夹下有个test.py1
2import sys
print(sys.path)
运行看看:1
2
3
4
5
6
7hulinhong@GIH-D-14531 MINGW64 ~/Desktop
$ python test_folder/test.py
['C:\\Users\\hulinhong\\Desktop\\test_folder', 'C:\\Program Files\\Python37\\python37.zip', 'C:\\Program Files\\Python37\\DLLs', 'C:\\Program Files\\Python37\\lib', 'C:\\Program Files\\Python37', 'C:\\Program Files\\Python37\\lib\\site-packages', 'C:\\Program Files\\Python37\\lib\\site-packages\\redis_py_cluster-2.1.0-py3.7.egg']
hulinhong@GIH-D-14531 MINGW64 ~/Desktop
$ python -m test_folder.test
['C:\\Users\\hulinhong\\Desktop', 'C:\\Program Files\\Python37\\python37.zip', 'C:\\Program Files\\Python37\\DLLs', 'C:\\Program Files\\Python37\\lib', 'C:\\Program Files\\Python37', 'C:\\Program Files\\Python37\\lib\\site-packages', 'C:\\Program Files\\Python37\\lib\\site-packages\\redis_py_cluster-2.1.0-py3.7.egg']
细心的同学会发现,区别就是在第一个路径:
- python直接启动是把test.py文件所在的目录放到了sys.path属性中。
- 模块启动是把你输入命令的目录(也就是当前路径),放到了sys.path属性中
所以就会有下面的情况:
目录结构如下1
2
3
4
5
6package/
__init__.py
mod1.py
package2/
__init__.py
run.py
run.py 内容如下1
2
3import sys
from package import mod1
print(sys.path)
如何才能启动run.py文件?
直接启动(失败)
1
2
3
4
5➜ test_import_project git:(master) ✗ python package2/run.py
Traceback (most recent call last):
File "package2/run.py", line 2, in <module>
from package import mod1
ImportError: No module named package以模块方式启动(成功)
1
2
3
4➜ test_import_project git:(master) ✗ python -m package2.run
['C:\\Users\\hulinhong\\Desktop',
'/usr/local/Cellar/python/2.7.11/Frameworks/Python.framework/Versions/2.7/lib/python27.zip',
...]
当需要启动的py文件引用了一个模块。你需要注意:在启动的时候需要考虑sys.path中有没有你import的模块的路径!
这个时候,到底是使用直接启动,还是以模块的启动?目的就是把import的那个模块的路径放到sys.path中。你是不是明白了呢?
官方文档参考: http://www.pythondoc.com/pythontutorial3/modules.html
导入一个叫 mod1 的模块时,解释器先在当前目录中搜索名为 mod1.py 的文件。如果没有找到的话,接着会到 sys.path 变量中给出的目录列表中查找。 sys.path 变量的初始值来自如下:
输入脚本的目录(当前目录)。
- 环境变量 PYTHONPATH 表示的目录列表中搜索(这和 shell 变量 PATH 具有一样的语法,即一系列目录名的列表)。
- Python 默认安装路径中搜索。
- 实际上,解释器由 sys.path 变量指定的路径目录搜索模块,该变量初始化时默认包含了输入脚本(或者当前目录), PYTHONPATH 和安装目录。这样就允许 Python程序了解如何修改或替换模块搜索目录。
在python程序中调用cpp的库创建的线程是否受制于GIL?
首先要理解什么是GIL.
Python 的多线程是真的多线程,只不过在任意时刻,它们中只有一个线程能够取得 GIL 从而被允许执行 Python 代码。其它线程要么等着,要么干别的和 Python 无关的事情(比如等待系统 I/O,或者算点什么东西)。
那如果是通过CPP扩展创建出来的线程,可以摆脱这个限制么?
很简单,不访问 Python 的数据和方法,就和 GIL 没任何关系。如果需要访问 Python,还是需要先取得 GIL.
GIL 是为了保护 Python 数据不被并发访问破坏,所以当你不访问 Python 的数据的时候自然就可以释放(或者不取得)GIL。反过来,如果需要访问 Python 的数据,就一定要取得 GIL 再访问。PyObject 等不是线程安全的。多线程访问任何非线程安全的数据都需要先取得对应的锁。Python 所有的 PyObject 什么的都共享一个锁,它就叫 GIL。
__new__ 与 __del__ 与 __init__
先来看一个单例模式的实现1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Demo:
__isinstance = False
def __new__(cls, *args, **kwargs):
if not cls.__isinstance: # 如果被实例化了
cls.__isinstance = object.__new__(cls) # 否则实例化
return cls.__isinstance # 返回实例化的对象
def __init__(self, name):
self.name = name
print('my name is %s'%(name))
def __del__(self):
print('886, %s'%(self.name))
d1 = Demo('Alice')
d2 = Demo('Anew')
print(d1)
print(d2)
打印:1
2
3
4
5my name is Alice
my name is Anew
<__main__.Demo object at 0x000001446604D3C8>
<__main__.Demo object at 0x000001446604D3C8>
886, Anew
__new__ 是负责对当前类进行实例化,并将实例返回,并传给__init__方法,__init__方法中的self就是指代__new__传过来的对象,所以再次强调,__init__是实例化后调用的第一个方法。
__del__在对象销毁时被调用,往往用于清除数据或还原环境等操作,比如在类中的其他普通方法中实现了插入数据库的语句,当对象被销毁时我们需要将数据还原,那么这时可以在__del__方法中实现还原数据库数据的功能。__del__被成为析构方法,同样和C++中的析构方法类似。
python垃圾回收
总体来说,在Python中,主要通过引用计数进行垃圾回收;通过 “标记-清除” 解决容器对象可能产生的循环引用问题;通过 “分代回收” 以空间换时间的方法提高垃圾回收效率。
- 引用计数
- 标记清除(Mark and Sweep)
- 分代回收
标记清除咋弄的
参考: https://zhuanlan.zhihu.com/p/83251959
Python 采用了 “标记-清除”(Mark and Sweep) 算法,解决容器对象可能产生的循环引用问题。(注意,只有容器对象才会产生循环引用的情况,比如列表、字典、用户自定义类的对象、元组等。而像数字,字符串这类简单类型不会出现循环引用。作为一种优化策略,对于只包含简单类型的元组也不在标记清除算法的考虑之列)
跟其名称一样,该算法在进行垃圾回收时分成了两步,分别是:
- A)标记阶段,遍历所有的对象,如果是可达的(reachable),也就是还有对象引用它,那么就标记该对象为可达;
- B)清除阶段,再次遍历对象,如果发现某个对象没有标记为可达,则就将其回收。
如下图所示,在标记清除算法中,为了追踪容器对象,需要每个容器对象维护两个额外的指针,用来将容器对象组成一个双端链表,指针分别指向前后两个容器对象,方便插入和删除操作。python 解释器 (Cpython) 维护了两个这样的双端链表,一个链表存放着需要被扫描的容器对象,另一个链表存放着临时不可达对象。在图中,这两个链表分别被命名为”Object to Scan”和”Unreachable”。图中例子是这么一个情况:link1,link2,link3 组成了一个引用环,同时 link1 还被一个变量 A(其实这里称为名称 A 更好)引用。link4 自引用,也构成了一个引用环。从图中我们还可以看到,每一个节点除了有一个记录当前引用计数的变量 ref_count 还有一个 gc_ref 变量,这个 gc_ref 是 ref_count 的一个副本,所以初始值为 ref_count 的大小。
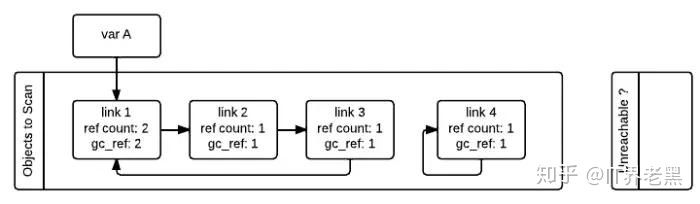
gc 启动的时候,会逐个遍历”Object to Scan” 链表中的容器对象,并且将当前对象所引用的所有对象的 gc_ref 减一。(扫描到 link1 的时候,由于 link1 引用了 link2, 所以会将 link2 的 gc_ref 减一,接着扫描 link2, 由于 link2 引用了 link3, 所以会将 link3 的 gc_ref 减一…..) 像这样将”Objects to Scan” 链表中的所有对象考察一遍之后,两个链表中的对象的 ref_count 和 gc_ref 的情况如下图所示。这一步操作就相当于解除了循环引用对引用计数的影响。
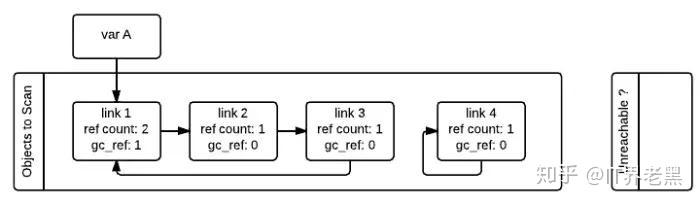
接着,gc 会再次扫描所有的容器对象,如果对象的 gc_ref 值为 0,那么这个对象就被标记为 GC_TENTATIVELY_UNREACHABLE,并且被移至”Unreachable” 链表中。下图中的 link3 和 link4 就是这样一种情况。
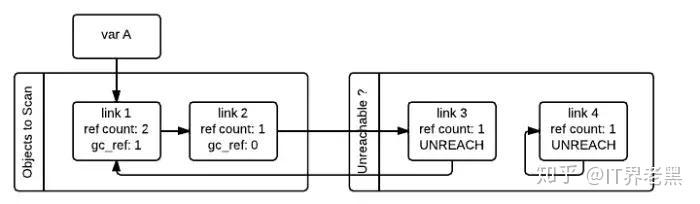
如果对象的 gc_ref 不为 0,那么这个对象就会被标记为 GC_REACHABLE。同时当 gc 发现有一个节点是可达的,那么他会递归式的将从该节点出发可以到达的所有节点标记为 GC_REACHABLE, 这就是下图中 link2 和 link3 所碰到的情形。
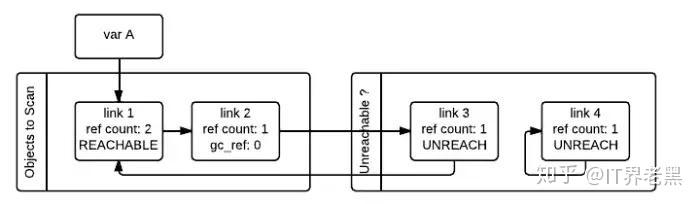
除了将所有可达节点标记为 GC_REACHABLE 之外,如果该节点当前在”Unreachable” 链表中的话,还需要将其移回到”Object to Scan” 链表中,下图就是 link3 移回之后的情形。
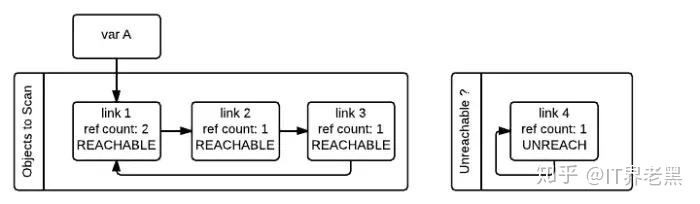
第二次遍历的所有对象都遍历完成之后,存在于”Unreachable” 链表中的对象就是真正需要被释放的对象。如上图所示,此时 link4 存在于 Unreachable 链表中,gc 随即释放之。
上面描述的垃圾回收的阶段,会暂停整个应用程序,等待标记清除结束后才会恢复应用程序的运行。
为啥标记清除回收无法回收重写了__del__方法的类对象
Circular references which are garbage are detected when the option cycle detector is enabled (it’s on by default), but can only be cleaned up if there are no Python-level
__del__() methods involved.
官方文档中表明启用周期检测器时会检测到垃圾的循环引用(默认情况下它是打开的),但只有在没有涉及 Python __del__() 方法的情况下才能清除。Python 不知道破坏彼此保持循环引用的对象的安全顺序,因此它则不会为这些方法调用析构函数。简而言之,如果定义了 __del__ 函数,那么在循环引用中Python解释器无法判断析构对象的顺序,因此就不做处理。
分代回收
在循环引用对象的回收中,整个应用程序会被暂停,为了减少应用程序暂停的时间,Python 通过“分代回收”(Generational Collection)以空间换时间的方法提高垃圾回收效率。
分代回收是基于这样的一个统计事实,对于程序,存在一定比例的内存块的生存周期比较短;而剩下的内存块,生存周期会比较长,甚至会从程序开始一直持续到程序结束。生存期较短对象的比例通常在 80%~90% 之间,这种思想简单点说就是:对象存在时间越长,越可能不是垃圾,应该越少去收集。这样在执行标记-清除算法时可以有效减小遍历的对象数,从而提高垃圾回收的速度。
python gc给对象定义了三种世代(0,1,2),每一个新生对象在generation zero中,如果它在一轮gc扫描中活了下来,那么它将被移至generation one,在那里他将较少的被扫描,如果它又活过了一轮gc,它又将被移至generation two,在那里它被扫描的次数将会更少。
gc的扫描在什么时候会被触发呢?答案是当某一世代中被分配的对象与被释放的对象之差达到某一阈值的时候,就会触发gc对某一世代的扫描。值得注意的是当某一世代的扫描被触发的时候,比该世代年轻的世代也会被扫描。也就是说如果世代2的gc扫描被触发了,那么世代0,世代1也将被扫描,如果世代1的gc扫描被触发,世代0也会被扫描。
该阈值可以通过下面两个函数查看和调整:
1 | gc.get_threshold() # (threshold0, threshold1, threshold2). |
下面对set_threshold()中的三个参数threshold0, threshold1, threshold2进行介绍。gc会记录自从上次收集以来新分配的对象数量与释放的对象数量,当两者之差超过threshold0的值时,gc的扫描就会启动,初始的时候只有世代0被检查。如果自从世代1最近一次被检查以来,世代0被检查超过threshold1次,那么对世代1的检查将被触发。相同的,如果自从世代2最近一次被检查以来,世代1被检查超过threshold2次,那么对世代2的检查将被触发。get_threshold()是获取三者的值,默认值为(700,10,10).