C++
参考: 看之前一个哥们总结的c++要点 https://interview.huihut.com/
new和delete为什么要配对用:1
2
3
4
5class A{
//...
};
A *pa = new A();
A *pas = new A[NUM]();delete []pas; //详细流程: delete[] pas 用来释放pas指向的内存!!还逐一调用数组中每个对象的destructor!!
- delete []pa; //会发生什么, 答案是调用未知次数的A的析构函数. 因为delete[]会去通过pa+offset找一个基于pa的偏移量找一个内存里的数据, 他假定这个内存里放了要调用析构的次数n这个数据, 而这个内存里到底是多少是未知的.
- delete pas; //哪些指针会变成野指针, 答案是pas和A[0]中的指针会变成野指针. 因为只有这两个指针指向的内存被释放了, 也就是说, 仅释放了pas指针指向的这个数组的全部内存空间, 以及只调用了a[0]对象的析构函数
- cqq vec set map list
- map的
[]和insert的区别?- insert 含义是:如果key存在,则插入失败,如果key不存在,就创建这个key-value。实例:
map.insert((key, value)) - 利用下标操作的含义是:如果这个key存在,就更新value;如果key不存在,就创建这个key-value对 实例:
map[key] = value
- insert 含义是:如果key存在,则插入失败,如果key不存在,就创建这个key-value。实例:
- vector的resize和reserve的区别?
- 总结:
- resize既分配了空间,也创建了对象,可以通过下标访问。当new_size大于原size, 则resize既修改capacity大小,也修改size大小。否则只修改size大小.
- reserve只分配了空间, 也就是说它只修改capacity大小,不修改size大小, 若 new_cap 小于等于当前的 capacity(), 它啥也不干.
- resize: 重设容器大小以容纳 count 个元素。
若当前大小大于 count ,则减小容器为其首 count 个元素。
若当前大小小于 count:- 则后附额外的默认插入的元素
- 则后附额外的 value 的副本
- reserve: 增加 vector 的容量到大于或等于 new_cap 的值。若 new_cap 大于当前的 capacity() ,则分配新存储,否则该方法不做任何事。reserve() 不更改 vector 的 size 。若 new_cap 大于 capacity() ,则所有迭代器,包含尾后迭代器和所有到元素的引用都被非法化。否则,没有迭代器或引用被非法化。
- 总结:
- 字节对齐
定位new
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
using namespace std;
int main() {
char buffer[512]; //chunk of memory内存池
int *p2, *p3;
//定位new:
p2 = new (buffer) int[10];
p2[0] = 99;
p2[1] = 88;
cout << "buffer = " <<(void *)buffer << endl; //内存池地址
cout << "p2 = " << p2 << endl; //定位new指向的地址
cout << "p2[0] = " << p2[0] << endl;
p3 = new (buffer) int[2];
p3[0] = 1;
p3[1] = 2;
cout << "p3 = " << p3 << endl;
cout << "p2[0] = " << p2[0] << endl;
cout << "p2[1] = " << p2[1] << endl;
cout << "p2[2] = " << p2[2] << endl;
cout << "p2[3] = " << p2[3] << endl;
return 0;
}结果发现p3和p2还有buffer都是使用同样的内存地址,符合指定地址的内存块,而且p3在指定位置覆盖了p2的前两处的值。
- c++一个空类会生成什么 (答: 默认构造/析构(非虚)/赋值运算符/默认拷贝/取地址/const取地址)
虚函数(virtual)可以是内联函数(inline)吗?
- 虚函数可以是内联函数,内联是可以修饰虚函数的,但是当虚函数表现多态性的时候不能内联。
- 内联是在编译器建议编译器内联,而虚函数的多态性在运行期,编译器无法知道运行期调用哪个代码,因此虚函数表现为多态性时(运行期)不可以内联。
- inline virtual 唯一可以内联的时候是:编译器知道所调用的对象是哪个类(如 Base::who()),这只有在编译器具有实际对象而不是对象的指针或引用时才会发生。
虚函数内联使用:1
2
3
4
5
6
7
8
9
10// 此处的虚函数 who(),是通过类(Base)的具体对象(b)来调用的,
// 编译期间就能确定了,所以它可以是内联的,
// 但最终是否内联取决于编译器。
Base b;
b.who();
// 此处的虚函数是通过指针调用的,呈现多态性,
// 需要在运行时期间才能确定,所以不能为内联。
Base *ptr = new Derived();
ptr->who();
虚函数指针、虚函数表
- 虚函数指针:在含有虚函数类的对象中,指向虚函数表,在运行时确定。
- 虚函数表:在程序内存的
只读数据段(.rodata section,见:CPP目标文件内存布局),存放虚函数指针,如果派生类实现了基类的某个虚函数,则在虚表中覆盖原本基类的那个虚函数指针,在编译时根据类的声明创建。 - virtual修饰符:
如果一个类是局部变量则该类数据存储在栈区,如果一个类是通过new/malloc动态申请的,则该类数据存储在堆区。
如果该类是virutal继承而来的子类,则该类的虚函数表指针和该类其他成员一起存储。虚函数表指针指向只读数据段中的类虚函数表,虚函数表中存放着一个个函数指针,函数指针指向代码段中的具体函数。 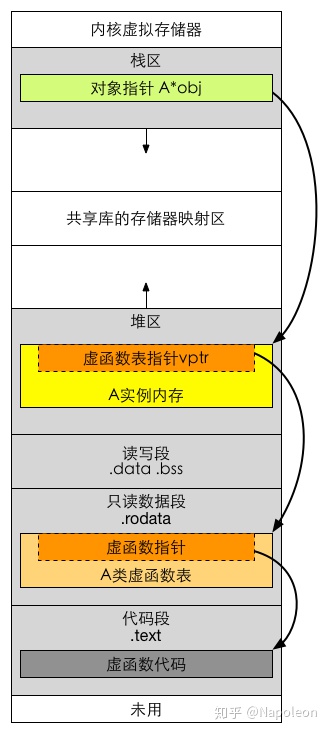
内存泄漏的工具 vargrid..? 还有啥工具
- 了解ASAN查找内存越界问题
- cpp找找冰川, 大梦龙图的面试题,网上常用题
- gdb怎么切换线程
- C++ 的动态多态怎么实现的?
- C++ 的构造函数可以是虚函数吗?
- 无锁队列原理是否一定比有锁快?(不一定, 如果临界区小因为有上下文切换则mutex慢, 再来看lockfree的spin,一般都遵循一个固定的格式:先把一个不变的值X存到某个局部变量A里,然后做一些计算,计算/生成一个新的对象,然后做一个CAS操作,判断A和X还是不是相等的,如果是,那么这次CAS就算成功了,否则再来一遍。如果上面这个loop里面“计算/生成一个新的对象”非常耗时并且contention很严重,那么lockfree性能有时会比mutex差。另外lockfree不断地spin引起的CPU同步cacheline的开销也比mutex版本的大。关于ABA问题)
编译过程
- 预处理(Preprocessing): 做一些类似于将所有的
#define删除,并且展开所有的宏定义的操作, 然后生成hello.i - 编译(Compilation): 编译过程就是把预处理完的文件进行一系列的词法分析,语法分析,语义分析及优化后生成相应的汇编代码。得到hello.a
- 汇编(Assembly): 汇编器是将汇编代码转变成机器可以执行的命令,每一个汇编语句几乎都对应一条机器指令。汇编相对于编译过程比较简单,根据汇编指令和机器指令的对照表一一翻译即可。得到hello.o
- 链接(Linking): 通过调用链接器ld来链接程序运行需要的一大堆目标文件,以及所依赖的其它库文件,最后生成可执行文件
- 静态链接: 指在编译阶段直接把静态库加入到可执行文件中去,这样可执行文件会比较大
- 动态链接: 指链接阶段仅仅只加入一些描述信息,而程序执行时再从系统中把相应动态库加载到内存中去。
目标文件
编译器编译源代码后生成的文件叫做目标文件。目标文件从结构上讲,它是已经编译后的可执行文件格式,只是还没有经过链接的过程,其中可能有些符号或有些地址还没有被调整。
可执行文件(Windows 的
.exe和 Linux 的ELF)、动态链接库(Windows 的.dll和 Linux 的.so)、静态链接库(Windows 的.lib和 Linux 的.a)都是按照可执行文件格式存储(Windows 按照 PE-COFF,Linux 按照 ELF)
目标文件格式:
- Windows 的 PE(Portable Executable),或称为 PE-COFF,
.obj格式 - Linux 的 ELF(Executable Linkable Format),
.o格式 - Intel/Microsoft 的 OMF(Object Module Format)
- Unix 的
a.out格式 - MS-DOS 的
.COM格式
PE 和 ELF 都是 COFF(Common File Format)的变种
CPP目标文件内存布局
| 段 | 功能 |
|---|---|
| File Header | 文件头,描述整个文件的文件属性(包括文件是否可执行、是静态链接或动态连接及入口地址、目标硬件、目标操作系统等) |
| .text section | 代码段,执行语句编译成的机器代码 |
| .data section | 数据段,已初始化的全局变量和局部静态变量 |
| .bss section | BSS 段(Block Started by Symbol),未初始化的全局变量和局部静态变量(因为默认值为 0,所以只是在此预留位置,不占空间) |
| .rodata section | 只读数据段,存放只读数据,一般是程序里面的只读变量(如 const 修饰的变量)和字符串常量 |
| .comment section | 注释信息段,存放编译器版本信息 |
| .note.GNU-stack section | 堆栈提示段 |