Linux内存管理
为什么需要虚拟内存
虚拟内存的目的是为了让物理内存扩充成更大的逻辑内存,从而让程序获得更多的可用内存。
为了更好的管理内存,操作系统将内存抽象成地址空间。每个程序拥有自己的地址空间,这个地址空间被分割成多个块,每一块称为一页。这些页被映射到物理内存,但不需要映射到连续的物理内存,也不需要所有页都必须在物理内存中。当程序引用到不在物理内存中的页时,由硬件执行必要的映射,将缺失的部分装入物理内存并重新执行失败的指令。
从上面的描述中可以看出,虚拟内存允许程序不用将地址空间中的每一页都映射到物理内存,也就是说一个程序不需要全部调入内存就可以运行,这使得有限的内存运行大程序成为可能。例如有一台计算机可以产生 16 位地址,那么一个程序的地址空间范围是 0~64K。该计算机只有 32KB 的物理内存,虚拟内存技术允许该计算机运行一个 64K 大小的程序。
MMU工作原理
内存管理单元(MMU)管理着地址空间和物理内存的转换,其中的页表(Page table)存储着页(程序地址空间)和页框(物理内存空间)的映射表。
一个虚拟地址分成两个部分:
- 一部分存储页面号,
- 一部分存储偏移量。
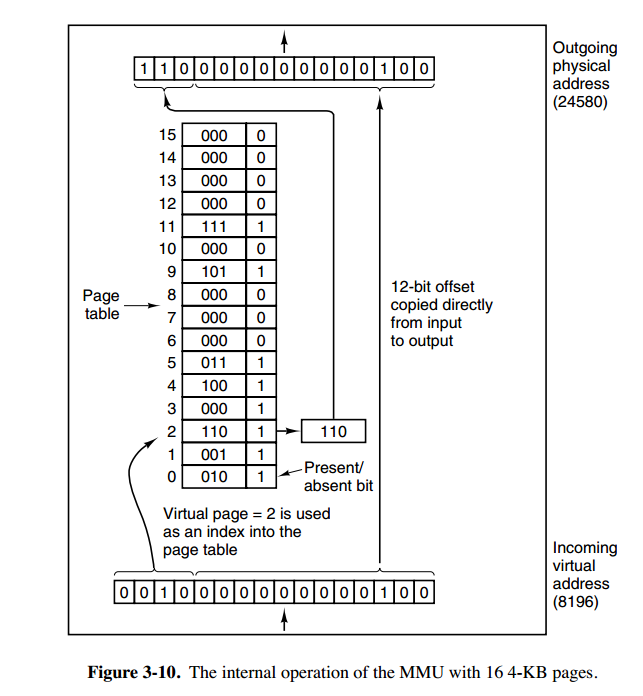
上图的页表存放着 16 个页,这 16 个页需要用 4 个比特位来进行索引定位。例如对于虚拟地址(0010 000000000100),前 4 位是存储页面号 2,读取表项内容为(110 1),页表项最后一位表示是否存在于内存中,1 表示存在。后 12 位存储偏移量。这个页对应的页框的地址为 (110 000000000100)。
主机字节序
主机字节序又叫 CPU 字节序,其不是由操作系统决定的,而是由 CPU 指令集架构决定的。主机字节序分为两种:
- 记忆技巧: 低序地址存了高序字节就叫大端, 反之就小端
- 大端字节序(Big Endian):高序字节存储在低位地址,低序字节存储在高位地址, 目前主要是ARM/PowerPC在用
- 小端字节序(Little Endian):低序字节存储在低位地址, 高序字节存储在高位地址,目前主要是Intel在用
存储方式:
32 位整数 0x12345678 是从起始位置为 0x00 的地址开始存放,则:
| 内存地址 | 0x00 | 0x01 | 0x02 | 0x03 |
|---|---|---|---|---|
| 大端 | 12 | 34 | 56 | 78 |
| 小端 | 78 | 56 | 34 | 12 |
网络字节序
网络字节顺序是 TCP/IP 中规定好的一种数据表示格式,它与具体的 CPU 类型、操作系统等无关,从而可以保证数据在不同主机之间传输时能够被正确解释。
网络字节顺序采用:大端(Big Endian)排列方式。
Linux虚拟地址空间如何分布
Linux 使用虚拟地址空间,大大增加了进程的寻址空间,由低地址到高地址(下图中从下到上即为从低到高)分别为(口诀: 文初堆栈):
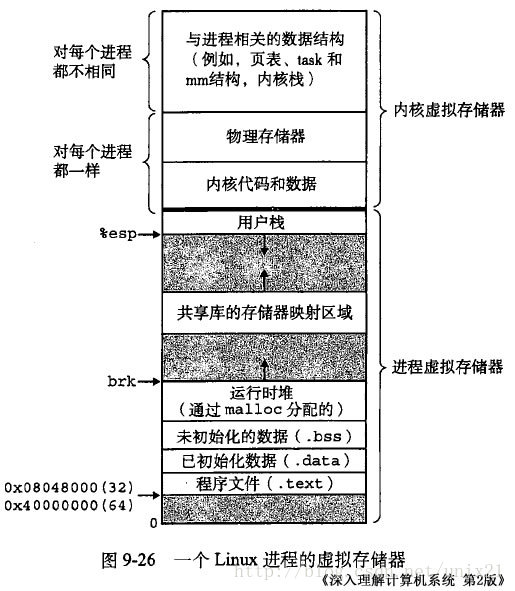
- 文本段(只读段):该部分空间只能读,不可写;(包括:代码段、rodata 段(C常量字符串和#define定义的常量) )
- 数据段(初始化数据段与未初始化数据段):保存初始化了的与未初始化的全局变量、静态变量的空间;
- 堆 :就是平时所说的动态内存, malloc/new 大部分都来源于此。其中堆顶的位置可通过函数 brk 和 sbrk 进行动态调整。
- 文件映射区域 :如动态库、共享内存等映射物理空间的内存,一般是 mmap 函数所分配的虚拟地址空间。
- 栈:用于维护函数调用的上下文空间,一般为 8M ,可通过 ulimit –s 查看。
- 内核虚拟空间:用户代码不可见的内存区域,由内核管理(页表就存放在内核虚拟空间)。上图是 32 位系统典型的虚拟地址空间分布(来自《深入理解计算机系统》)。
brk函数
先了解:brk()和sbrk()函数1
2int brk( const void *addr )
void* sbrk ( intptr_t incr );
这两个函数的作用主要是扩展heap的上界brk。第一个函数的参数为设置的新的brk上界地址,如果成功返回0,失败返回-1。第二个函数的参数为需要申请的内存的大小,然后返回heap新的上界brk地址。如果sbrk的参数为0,则返回的为原来的brk地址。
mmap
虚拟内存系统通过将虚拟内存分割为称作虚拟页 (Virtual Page,VP) 大小固定的块,一般情况下,每个虚拟页的大小默认是 4096 字节。同样的,物理内存也被分割为物理页(Physical Page,PP),也为 4096 字节。
在 LINUX 中我们可以使用 mmap 用来在进程虚拟内存地址空间中分配地址空间,创建和物理内存的映射关系。
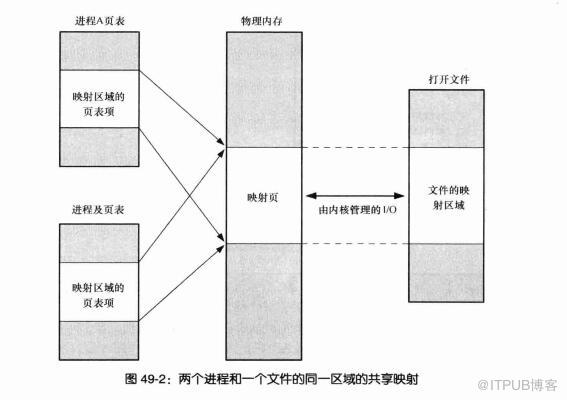
映射关系可以分为两种
- 文件映射
磁盘文件映射进程的虚拟地址空间,使用文件内容初始化物理内存。 - 匿名映射
初始化全为 0 的内存空间。
而对于映射关系是否共享又分为
- 私有映射 (MAP_PRIVATE)
多进程间数据共享,修改不反应到磁盘实际文件,是一个 copy-on-write(写时复制)的映射方式。 - 共享映射 (MAP_SHARED)
多进程间数据共享,修改反应到磁盘实际文件中。
因此总结起来有 4 种组合
- 私有文件映射
多个进程使用同样的物理内存页进行初始化,但是各个进程对内存文件的修改不会共享,也不会反应到物理文件中 - 私有匿名映射
mmap 会创建一个新的映射,各个进程不共享,这种使用主要用于分配内存 (malloc 分配大内存会调用 mmap)。
例如开辟新进程时,会为每个进程分配虚拟的地址空间,这些虚拟地址映射的物理内存空间各个进程间读的时候共享,写的时候会 copy-on-write。 - 共享文件映射
多个进程通过虚拟内存技术共享同样的物理内存空间,对内存文件 的修改会反应到实际物理文件中,他也是进程间通信 (IPC) 的一种机制。 - 共享匿名映射
这种机制在进行 fork 的时候不会采用写时复制,父子进程完全共享同样的物理内存页,这也就实现了父子进程通信 (IPC).
这里值得注意的是,mmap 只是在虚拟内存分配了地址空间,只有在第一次访问虚拟内存的时候才分配物理内存。
在 mmap 之后,并没有在将文件内容加载到物理页上,只上在虚拟内存中分配了地址空间。当进程在访问这段地址时,通过查找页表,发现虚拟内存对应的页没有在物理内存中缓存,则产生 “缺页”,由内核的缺页异常处理程序处理,将文件对应内容,以页为单位 (4096) 加载到物理内存,注意是只加载缺页,但也会受操作系统一些调度策略影响,加载的比所需的多。
1 | void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset); |
这里要注意的是fd参数,fd为映射的文件描述符,如果是匿名映射,可以设为-1;
- mmap函数第一种用法是映射磁盘文件到内存中;而malloc使用的是mmap函数的第二种用法,即匿名映射,匿名映射不映射磁盘文件,而是向映射区申请一块内存。
- munmap函数是用于释放内存,第一个参数为内存首地址,第二个参数为内存的长度。接下来看下mmap函数的参数。
由于brk/sbrk/mmap属于系统调用,如果每次申请内存,都调用这三个函数中的一个,那么每次都要产生系统调用开销(即cpu从用户态切换到内核态的上下文切换,这里要保存用户态数据,等会还要切换回用户态),这是非常影响性能的;其次,这样申请的内存容易产生碎片,因为堆是从低地址到高地址,如果低地址的内存没有被释放,高地址的内存就不能被回收。
malloc和free原理
malloc:
- 当申请小内存的时,malloc使用sbrk分配内存
- 当申请大内存时,使用mmap函数申请内存
- 但是这只是分配了虚拟内存,还没有映射到物理内存,当访问申请的内存时,才会因为缺页异常,内核分配物理内存。
- 将所有空闲内存块连成链表,每个节点记录空闲内存块的地址、大小等信息
- 分配内存时,找到大小合适的块,切成两份,一分给用户,一份放回空闲链表
- free时,直接把内存块返回链表
- 解决外部碎片:将能够合并的内存块进行合并
malloc函数的实质体现在:它有一个将可用的内存块连接为一个长长的列表的所谓空闲链表。调用malloc函数时,它沿连接表寻找一个大到足以满足用户请求所需要的内存块。然后,将该内存块一分为二(一块的大小与用户请求的大小相等,另一块的大小就是剩下的字节)。接下来,将分配给用户的那块内存传给用户,并将剩下的那块(如果有的话)返回到连接表上。
这里注意,malloc找到的内存块大小一定是会大于等于我们需要的内存大小,下面会提到如果所有的内存块都比要求的小会怎么办?
调用free函数时,它将用户释放的内存块连接到空闲链上。到最后,空闲链会被切成很多的小内存片段,如果这时用户申请一个大的内存片段,那么空闲链上可能没有可以满足用户要求的片段了。于是,malloc函数请求延时,并开始在空闲链上翻箱倒柜地检查各内存片段,对它们进行整理,将相邻的小空闲块合并成较大的内存块。
在对内存块进行了 free 调用之后,我们需要做的是诸如将它们标记为未被使用的等事情,并且,在调用 malloc 时,我们要能够定位未被使用的内存块。因此, malloc返回的每块内存的起始处首先要有这个结构:
这就解释了,为什么在程序中free之后,但是堆的内存还是没有释放。
内存控制块结构定义1
2
3
4struct mem_control_block {
int is_available;
int size;
};
现在,您可能会认为当程序调用 malloc 时这会引发问题 —— 它们如何知道这个结构?答案是它们不必知道;在返回指针之前,我们会将其移动到这个结构之后,把它隐藏起来。这使得返回的指针指向没有用于任何其他用途的内存。那样,从调用程序的角度来看,它们所得到的全部是空闲的、开放的内存。然后,当通过 free() 将该指针传递回来时,我们只需要倒退几个内存字节就可以再次找到这个结构。
关于 malloc 获得虚存空间的实现,与 glibc 的版本有关,但大体逻辑是:
- 若分配内存小于 128k ,调用 sbrk() ,将堆顶指针向高地址移动,获得新的虚存空间。
- 若分配内存大于 128k ,调用 mmap() ,在文件映射区域中分配匿名虚存空间。
接着: VSZ为虚拟内存 RSS为物理内存
- VSZ 并不是每次 malloc 后都增长,是与上一节说的堆顶没发生变化有关,因为可重用堆顶内剩余的空间,这样的 malloc 是很轻量快速的。
- 但如果 VSZ 发生变化,基本与分配内存量相当,因为 VSZ 是计算虚拟地址空间总大小。
- RSS 的增量很少,是因为 malloc 分配的内存并不就马上分配实际存储空间,只有第一次使用,如第一次 memset 后才会分配。
- 由于每个物理内存页面大小是 4k ,不管 memset 其中的 1k 还是 5k 、 7k ,实际占用物理内存总是 4k 的倍数。所以 RSS 的增量总是 4k 的倍数。
- 因此,不是 malloc 后就马上占用实际内存,而是第一次使用时发现虚存对应的物理页面未分配,产生缺页中断,才真正分配物理页面,同时更新进程页面的映射关系。这也是 Linux 虚拟内存管理的核心概念之一。
vmalloc和kmalloc和malloc的区别
- kmalloc和vmalloc是分配的是内核的内存,malloc分配的是用户的内存
- kmalloc保证分配的内存在物理上是连续的,vmalloc保证的是在虚拟地址空间上的连续,malloc不保证任何东西(这点是自己猜测的,不一定正确)
- kmalloc能分配的大小有限,vmalloc和malloc能分配的大小相对较大
- 内存只有在要被DMA访问的时候才需要物理上连续
- vmalloc比kmalloc要慢
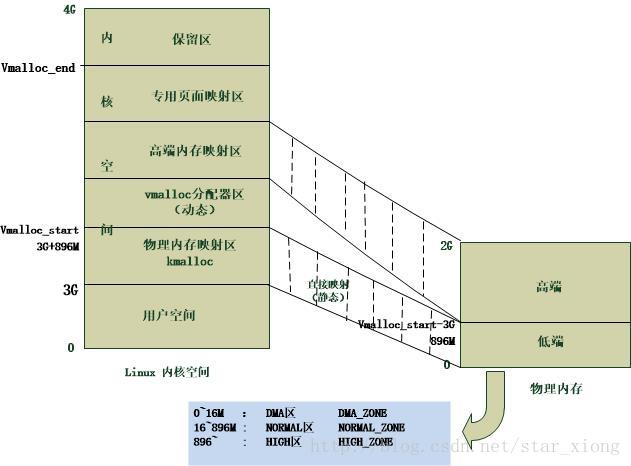
对于提供了MMU(存储管理器,辅助操作系统进行内存管理,提供虚实地址转换等硬件支持)的处理器而言,Linux提供了复杂的存储管理系统,使得进程所能访问的内存达到4GB。
进程的4GB内存空间被人为的分为两个部分–用户空间与内核空间。用户空间地址分布从0到3GB(PAGE_OFFSET,在0x86中它等于0xC0000000),3GB到4GB为内核空间。
内核空间中,从3G到vmalloc_start这段地址是物理内存映射区域(该区域中包含了内核镜像、物理页框表mem_map等等),比如我们使用 的 VMware虚拟系统内存是160M,那么3G~3G+160M这片内存就应该映射物理内存。在物理内存映射区之后,就是vmalloc区域。对于 160M的系统而言,vmalloc_start位置应在3G+160M附近(在物理内存映射区与vmalloc_start期间还存在一个8M的gap 来防止跃界),vmalloc_end的位置接近4G(最后位置系统会保留一片128k大小的区域用于专用页面映射)
一般情况下,只有硬件设备才需要物理地址连续的内存,因为硬件设备往往存在于MMU之外,根本不了解虚拟地址;但为了性能上的考虑,内核中一般使用kmalloc(),而只有在需要获得大块内存时才使用vmalloc,例如当模块被动态加载到内核当中时,就把模块装载到由vmalloc()分配的内存上。
- kmalloc:
kmalloc申请的是较小的连续的物理内存,内存物理地址上连续,虚拟地址上也是连续的,使用的是内存分配器slab的一小片。申请的内存位于物理内存的映射区域。其真正的物理地址只相差一个固定的偏移。而且不对获得空间清零。可以查看slab分配器 - kzalloc:
用kzalloc申请内存的时候, 效果等同于先是用 kmalloc() 申请空间 , 然后用 memset() 来初始化 ,所有申请的元素都被初始化为 0. - vmalloc:
vmalloc用于申请较大的内存空间,虚拟内存是连续。申请的内存的则位于vmalloc_start~vmalloc_end之间,与物理地址没有简单的转换关系,虽然在逻辑上它们也是连续的,但是在物理上它们不要求连续。 - malloc:
malloc分配的是用户的内存。除非被阻塞否则他执行的速度非常快,而且不对获得空间清零。
Buddy(伙伴)分配算法
参考: https://zhuanlan.zhihu.com/p/149581303
伙伴系统用于管理物理页,主要目的在于维护可用的连续物理空间,避免外部碎片。所有关于内存分配的操作都会与其打交道,buddy是物理内存的管理的门户
Linux 内核引入了伙伴系统算法(Buddy system),什么意思呢?就是把相同大小的页框块用链表串起来,页框块就像手拉手的好伙伴,也是这个算法名字的由来。
具体的,所有的空闲页框分组为11个块链表,每个块链表分别包含大小为1,2,4,8,16,32,64,128,256,512和1024个连续页框的页框块。最大可以申请1024个连续页框,对应4MB大小的连续内存。
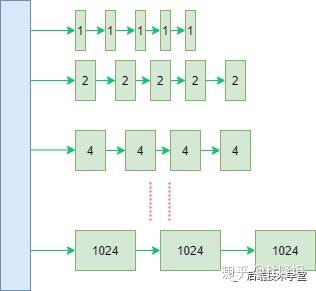
伙伴系统:
因为任何正整数都可以由 2^n 的和组成,所以总能找到合适大小的内存块分配出去,减少了外部碎片产生 。
分配实例:
比如:我需要申请4个页框,但是长度为4个连续页框块链表没有空闲的页框块,伙伴系统会从连续8个页框块的链表获取一个,并将其拆分为两个连续4个页框块,取其中一个,另外一个放入连续4个页框块的空闲链表中。释放的时候会检查,释放的这几个页框前后的页框是否空闲,能否组成下一级长度的块。
Slab分配器
伙伴系统和slab不是二选一的关系,slab 内存分配器是对伙伴分配算法的补充
slab的目的在于避免内部碎片。从buddy系统获取的内存至少是一个页,也就是4K,如果仅仅需要8字节的内存,显然巨大的内部碎片无法容忍。
slab从buddy系统申请空间,将较大的连续内存拆分成一系列较小的内存块。
用户申请空间时从slab中获取大小最相近的小块内存,这样可以有效减少内部碎片。在slab最大的块为8K,slab中所有块在物理上也是连续的。
上面说的用于内存分配的slab是通用的slab,主要用于支持kmalloc分配内存。
slab还有一个作用就是用作对象池,针对经常分配和回收的对象比如task_struct,可以分配一个slab对象池对其优化。这种slab是独立于通用的内存分配slab的,在内核中有很多这样的针对特定对象的slab。
在内核中想要分配一段连续的内存,首先向slab系统申请,如果不满足(超过两个页面,也就是8K),直接向buddy系统申请。如果还不满足(超过4M,也就是1024个页面),将无法获取到连续的物理地址。可以通过vmalloc获取虚拟地址空间连续,但物理地址不连续的更大的内存空间。
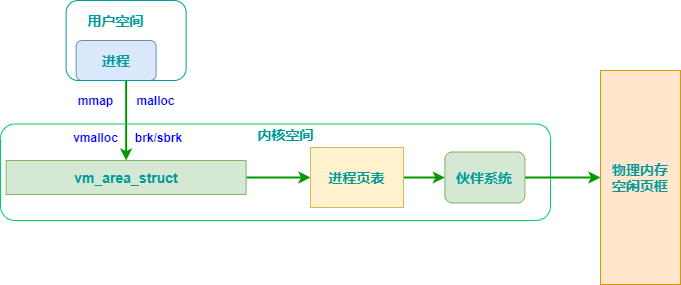
malloc是用户态使用的内存分配接口,最终还是向buddy申请内存,因为buddy系统是管理物理内存的门户。申请到大块内存后,再像slab一样对其进行细分维护,根据用户需要返回相应内存的指针。
fork内存语义
- 共享代码段, 子指向父 : 父子进程共享同一代码段, 子进程的页表项指向父进程相同的物理内存页(即数据段/堆段/栈段的各页)
- 写时复制(copy-on-write) : 内核会捕获所有父进程或子进程针对这些页面(即数据段/堆段/栈段的各页)的修改企图, 并为将要修改的页面创建拷贝, 将新的页面拷贝分配给遭内核捕获的进程, 从此父/子进程可以分别修改各自的页拷贝, 不再相互影响.
虽然fork创建的子进程不需要拷贝父进程的物理内存空间, 但是会复制父进程的空间内存页表. 例如对于10GB的redis进程, 需要复制约20MB的内存页表, 因为此fork操作耗时跟进程总内存量息息相关
零拷贝
参考 https://juejin.im/post/6844903949359644680
“先从简单开始,实现下这个场景:从一个文件中读出数据并将数据传到另一台服务器上?”
大概伪代码如下:1
2File.read(file, buf, len);
Socket.send(socket, buf, len);
可以看出, 这样效率是很低的.
下图分别对应传统 I/O 操作的数据读写流程,整个过程涉及 2 次 CPU 拷贝、2 次 DMA 拷贝总共 4 次拷贝,以及 4 次上下文切换,下面简单地阐述一下相关的概念。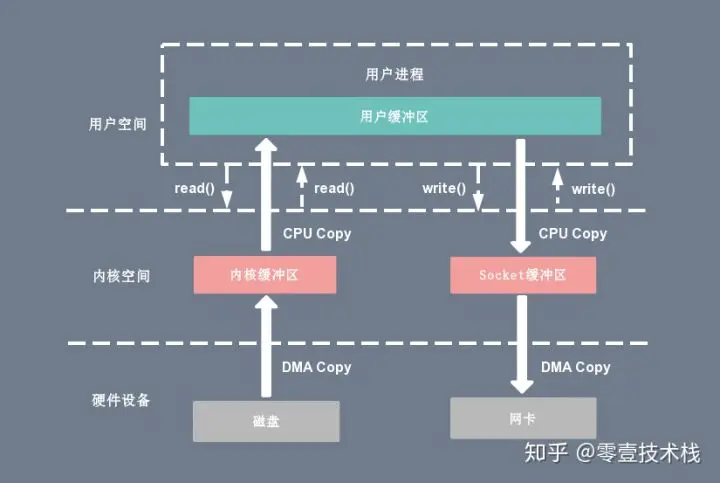
- 上下文切换:当用户程序向内核发起系统调用时,CPU 将用户进程从用户态切换到内核态;当系统调用返回时,CPU 将用户进程从内核态切换回用户态。
- CPU拷贝:由 CPU 直接处理数据的传送,数据拷贝时会一直占用 CPU 的资源。
- DMA拷贝:由 CPU 向DMA磁盘控制器下达指令,让 DMA 控制器来处理数据的传送,数据传送完毕再把信息反馈给 CPU,从而减轻了 CPU 资源的占有率。
传统读操作
当应用程序执行 read 系统调用读取一块数据的时候,如果这块数据已经存在于用户进程的页内存中,就直接从内存中读取数据;如果数据不存在,则先将数据从磁盘加载数据到内核空间的读缓存(read buffer)中,再从读缓存拷贝到用户进程的页内存中。1
read(file_fd, tmp_buf, len);
复制代码基于传统的 I/O 读取方式,read 系统调用会触发 2 次上下文切换,1 次 DMA 拷贝和 1 次 CPU 拷贝,发起数据读取的流程如下:
- 用户进程通过 read() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
- CPU利用DMA控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer)。
- CPU将读缓冲区(read buffer)中的数据拷贝到用户空间(user space)的用户缓冲区(user buffer)。
- 上下文从内核态(kernel space)切换回用户态(user space),read 调用执行返回。
传统写操作
当应用程序准备好数据,执行 write 系统调用发送网络数据时,先将数据从用户空间的页缓存拷贝到内核空间的网络缓冲区(socket buffer)中,然后再将写缓存中的数据拷贝到网卡设备完成数据发送。1
write(socket_fd, tmp_buf, len);
复制代码基于传统的 I/O 写入方式,write() 系统调用会触发 2 次上下文切换,1 次 CPU 拷贝和 1 次 DMA 拷贝,用户程序发送网络数据的流程如下:
- 用户进程通过 write() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
- CPU 将用户缓冲区(user buffer)中的数据拷贝到内核空间(kernel space)的网络缓冲区(socket buffer)。
- CPU 利用 DMA 控制器将数据从网络缓冲区(socket buffer)拷贝到网卡进行数据传输。
- 上下文从内核态(kernel space)切换回用户态(user space),write 系统调用执行返回。
sendfile
sendfile 系统调用在 Linux 内核版本 2.1 中被引入,目的是简化通过网络在两个通道之间进行的数据传输过程。sendfile 系统调用的引入,不仅减少了 CPU 拷贝的次数,还减少了上下文切换的次数,它的伪代码如下:1
sendfile(socket_fd, file_fd, len);
复制代码通过 sendfile 系统调用,数据可以直接在内核空间内部进行 I/O 传输,从而省去了数据在用户空间和内核空间之间的来回拷贝。与 mmap 内存映射方式不同的是, sendfile 调用中 I/O 数据对用户空间是完全不可见的。也就是说,这是一次完全意义上的数据传输过程。
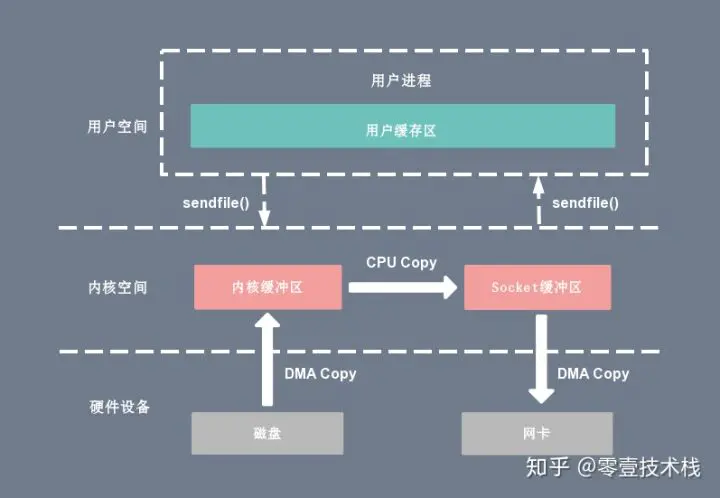
基于 sendfile 系统调用的零拷贝方式,整个拷贝过程会发生 2 次上下文切换,1 次 CPU 拷贝和 2 次 DMA 拷贝,用户程序读写数据的流程如下:
- 用户进程通过 sendfile() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
- CPU 利用 DMA 控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer)。
- CPU 将读缓冲区(read buffer)中的数据拷贝到的网络缓冲区(socket buffer)。
- CPU 利用 DMA 控制器将数据从网络缓冲区(socket buffer)拷贝到网卡进行数据传输。
- 上下文从内核态(kernel space)切换回用户态(user space),sendfile 系统调用执行返回。
相比较于 mmap 内存映射的方式,sendfile 少了 2 次上下文切换,但是仍然有 1 次 CPU 拷贝操作。sendfile 存在的问题是用户程序不能对数据进行修改,而只是单纯地完成了一次数据传输过程。
“这样确实改善了很多,但还没达到零拷贝的要求(还有一次cpu参与的拷贝),还有其它黑技术?”
“对的,如果底层网络接口卡支持收集(gather)操作的话,就可以进一步的优化。”
“怎么说?”
“继续看下一小节”
sendfile + DMA gather copy
Linux 2.4 版本的内核对 sendfile 系统调用进行修改,如果底层网络接口卡支持收集(gather)操作的话, 为 DMA 拷贝引入了 gather 操作。它将内核空间(kernel space)的读缓冲区(read buffer)中对应的数据描述信息(内存地址、地址偏移量)记录到相应的网络缓冲区( socket buffer)中,由 DMA 根据内存地址、地址偏移量将数据批量地从读缓冲区(read buffer)拷贝到网卡设备中,这样就省去了内核空间中仅剩的 1 次 CPU 拷贝操作,sendfile 的伪代码如下:1
sendfile(socket_fd, file_fd, len);
复制代码在硬件的支持下,sendfile 拷贝方式不再从内核缓冲区的数据拷贝到 socket 缓冲区,取而代之的仅仅是缓冲区文件描述符和数据长度的拷贝,这样 DMA 引擎直接利用 gather 操作将页缓存中数据打包发送到网络中即可,本质就是和虚拟内存映射的思路类似。
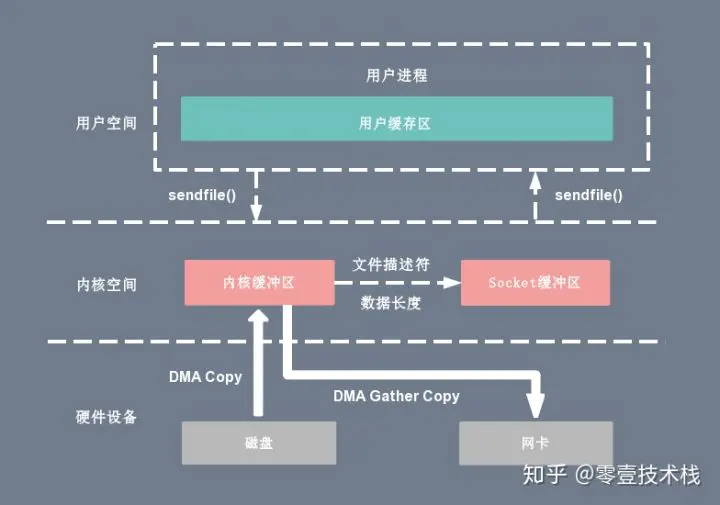
基于 sendfile + DMA gather copy 系统调用的零拷贝方式,整个拷贝过程会发生 2 次上下文切换、0 次 CPU 拷贝以及 2 次 DMA 拷贝,用户程序读写数据的流程如下:
- 用户进程通过 sendfile() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
- CPU 利用 DMA 控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer)。
- CPU 把读缓冲区(read buffer)的文件描述符(file descriptor)和数据长度拷贝到网络缓冲区(socket buffer)。
- 基于已拷贝的文件描述符(file descriptor)和数据长度,CPU 利用 DMA 控制器的 gather/scatter 操作直接批量地将数据从内核的读缓冲区(read buffer)拷贝到网卡进行数据传输。
- 上下文从内核态(kernel space)切换回用户态(user space),sendfile 系统调用执行返回。
sendfile + DMA gather copy 拷贝方式同样存在用户程序不能对数据进行修改的问题,而且本身需要硬件的支持,它只适用于将数据从文件拷贝到 socket 套接字上的传输过程。