MsgPack for python3
It’s like JSON.
but fast and small.
MessagePack is an efficient binary serialization format. It lets you exchange data among multiple languages like JSON. But it’s faster and smaller. Small integers are encoded into a single byte, and typical short strings require only one extra byte in addition to the strings themselves.
msgpack 比 json 模块序列化速度更快,所得到的数据体积更小
It’s like JSON,but fast and small
msgpack 用起来像 json,但是却比 json 快,并且序列化以后的数据长度更小,言外之意,使用 msgpack 不仅序列化和反序列化的速度快,数据传输量也比 json 格式小,msgpack 同样支持多种语言。
安装
msgpack 可以使用 pip 安装,安装命令如下:
1 | pip install msgpack |
使用
对数据流进行反序列化
msgpack 提供了一个 Unpacker 方法,可以对数据流进行反序列化,下面的代码改自官网的例子
1 | import msgpack |
自定义类型数据的序列化
msgpack 序列化函数提供了一个 default 参数,反序列化函数提供了一个 object_hook,其用法,与上一篇 json 中的 default 和 objec_thook 一样
1 | import datetime |
打印结果为:1
{'id': 1, 'created': {'__datetime__': True, 'as_str': '20210218T16:45:33.992339'}}
Extented类型
1 | import msgpack |
ProtoBuf
protobuf 是谷歌开源的一套序列化框架,基于二进制,速度快,体积小
protobuf
protobuf 是 google 开源的一个序列化框架,基于二进制,因此相比于 XML,json 要高效,它支持多种语言,php,java,c++,python,谷歌自己的许多系统间消息的传递就是用的它。
安装 protobuf
(1)git clone https://github.com/google/protobuf.git
(2)cd protobuf/
(3)./autogen.sh
第三步可能会出现一些问题,打开 autogen.sh 文件,会看到下面一段内容
1 | curl $curlopts -L -O https://github.com/google/googlemock/archive/release-1.7.0.zip |
这里要下载一个 gmock,有些朋友会在这一步上遇到障碍,这里一定要保证这两个文件下载成功,否则后续的安装无法成功
(4)make
(5)make check
(6)make install
(7)export LD_LIBRARY_PATH=/usr/local/lib:/usr/lib:/usr/local/lib64:/usr/lib64
完成这 7 步,就安装成功了,安装过程需要一点耐心,速度快慢视机器性能而定
定义. proto 文件
json,msgpack 在使用前都不需要定义数据格式,但 protobuf 需要,.proto 文件里定义的是可串行化的数据结构信息,新建一个名为 person.proto 的文件,内容为
1 | syntax = "proto2"; |
消息定义遵照固定的语法格式,字段定义格式如下
限定修饰符① | 数据类型② | 字段名称③ | = | 字段编码值④ | [字段默认值⑤]
(1)修饰符有 3 种,required 表示必须该字段必须赋值,optional 表示可选,允许不赋值,repeated 表示重复,相当于数组的意思
(2)数据类型,下图是数据类型表和与各种语言之间的对比关系
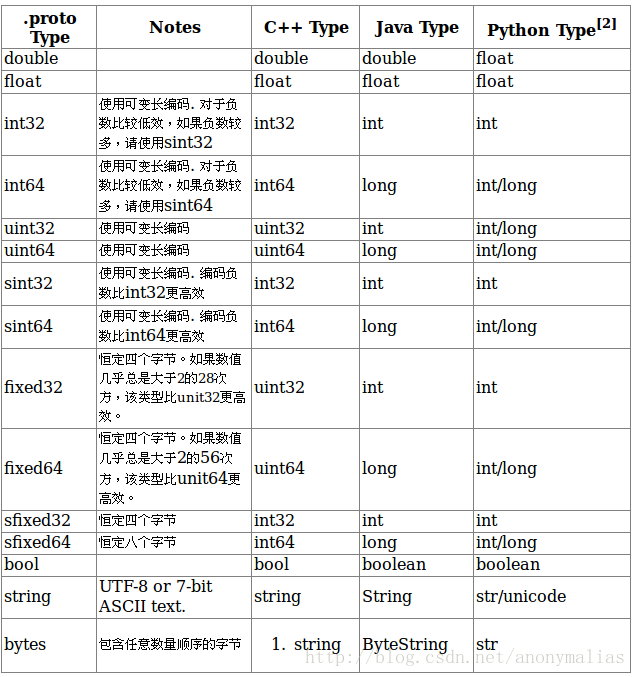
(3)字段名称
(4)字段编码值,从 1 开始,逐个递增
(5)字段默认值
编译. proto 文件
(1) 编译. proto 文件
在 person.proto 文件所在的目录里执行命令
protoc -I=. –python_out=. person.proto
命令执行后,在同目录下会生成一个名为 person_pb2.py 的文件,这个就是我们想要的东西
安装 python 包
pip install protobuf
序列化和反序列化
新建一个 python 脚本,内容如下
1 | from person_pb2 import Person |
执行一下脚本看看效果吧
个人愚见,小的系统最好不要用 protobuf,各个接口间消息的传递皆需要先定义. proto 文件,如果有所修改,就需要重新编译,不仅如此,不同系统间需要同时持有一份编译生成的_pb2.py 文件,这样导致工作很繁琐,小系统,直接使用 json 或者 msgpack 就好了
但如果是大系统,需要对接口进行明确规范的情况,使用 protbuf 却是非常合适,除去性能不谈,单单是使用统一的_pb2.py 文件,就能让工作变得条理清晰,避免个别工程师心花怒放随意定义数据格式