Cache Aside Pattern
什么是 “Cache Aside Pattern”?
答:旁路缓存方案的经验实践,这个实践又分读实践,写实践。
对于读请求
先读 cache,再读 db
如果,cache hit,则直接返回数据
如果,cache miss,则访问 db,并将数据 set 回缓存
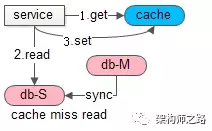
(1)先从 cache 中尝试 get 数据,结果 miss 了
(2)再从 db 中读取数据,从库,读写分离
(3)最后把数据 set 回 cache,方便下次读命中
对于写请求
先操作数据库,再淘汰缓存(淘汰缓存,而不是更新缓存)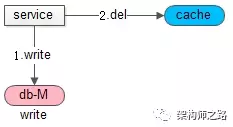
如上图:
(1)第一步要操作数据库,第二步操作缓存
(2)缓存,采用 delete 淘汰,而不是 set 更新
Cache Aside Pattern 为什么建议淘汰缓存,而不是更新缓存
答:如果更新缓存,在并发写时,可能出现数据不一致。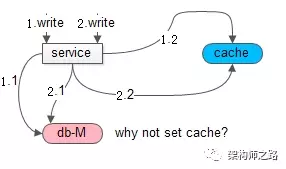
如上图所示,如果采用 set 缓存。
在 1 和 2 两个并发写发生时,由于无法保证时序,此时不管先操作缓存还是先操作数据库,都可能出现:
(1)请求 1 先操作数据库,请求 2 后操作数据库
(2)请求 2 先 set 了缓存,请求 1 后 set 了缓存
导致,数据库与缓存之间的数据不一致。
所以,Cache Aside Pattern 建议,delete 缓存,而不是 set 缓存。
Cache Aside Pattern 为什么建议先操作数据库,再操作缓存?
答:如果先操作缓存,在读写并发时,可能出现数据不一致。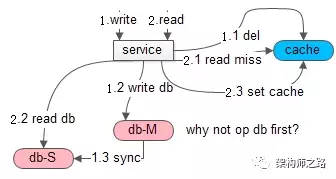
如上图所示,如果先操作缓存。
在 1 和 2 并发读写发生时,由于无法保证时序,可能出现:
(1)写请求淘汰了缓存
(2)写请求操作了数据库(主从同步没有完成)
(3)读请求读了缓存(cache miss)
(4)读请求读了从库(读了一个旧数据)
(5)读请求 set 回缓存(set 了一个旧数据)
(6)数据库主从同步完成
导致,数据库与缓存的数据不一致。
所以,Cache Aside Pattern 建议,先操作数据库,再操作缓存。
Cache Aside Pattern 方案存在什么问题?
答:如果先操作数据库,再淘汰缓存,在原子性被破坏时:
(1)修改数据库成功了
(2)淘汰缓存失败了
导致,数据库与缓存的数据不一致。
个人见解:这里个人觉得可以使用重试的方法,在淘汰缓存的时候,如果失败,则重试一定的次数。如果失败一定次数还不行,那就是其他原因了。比如说 redis 故障、内网出了问题。
关于这个问题,沈老师的解决方案是,使用先操作缓存(delete),再操作数据库。假如删除缓存成功,更新数据库失败了。缓存里没有数据,数据库里是之前的数据,数据没有不一致,对业务无影响。只是下一次读取,会多一次 cache miss。这里我觉得沈老师可能忽略了并发的问题,比如说以下情况:
一个写请求过来,删除了缓存,准备更新数据库(还没更新完成)。
然后一个读请求过来,缓存未命中,从数据库读取旧数据,再次放到缓存中,这时候,数据库更新完成了。此时的情况是,缓存中是旧数据,数据库里面是新数据,同样存在数据不一致的问题。
如图: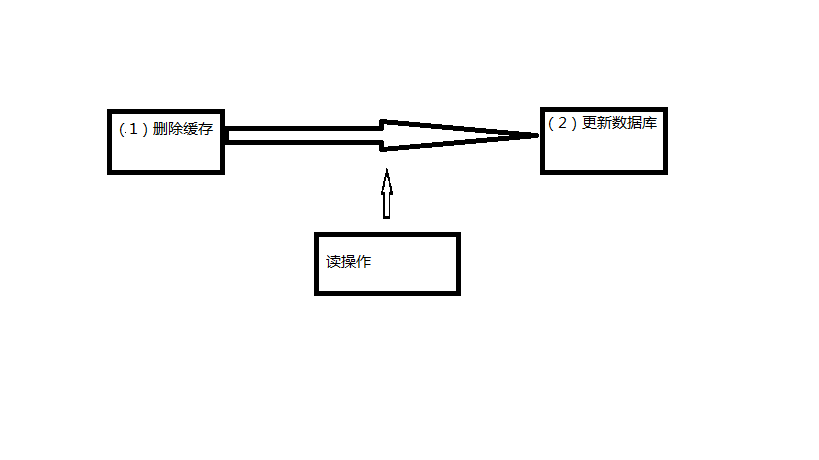
主从同步延迟导致的缓存和数据不一致问题
答:发生写请求后(不管是先操作 DB,还是先淘汰 Cache),在主从数据库同步完成之前,如果有读请求,都可能发生读 Cache Miss,读从库把旧数据存入缓存的情况。此时怎么办呢?
数据库主从不一致
先回顾下,无缓存时,数据库主从不一致问题。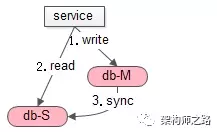
如上图,发生的场景是,写后立刻读:
(1)主库一个写请求(主从没同步完成)
(2)从库接着一个读请求,读到了旧数据
(3)最后,主从同步完成
导致的结果是:主动同步完成之前,会读取到旧数据。
可以看到,主从不一致的影响时间很短,在主从同步完成后,就会读到新数据。
缓存与数据库不一致
再看,引入缓存后,缓存和数据库不一致问题。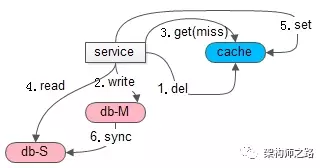
如上图,发生的场景也是,写后立刻读:
(1+2)先一个写请求,淘汰缓存,写数据库
(3+4+5)接着立刻一个读请求,读缓存,cache miss,读从库,写缓存放入数据,以便后续的读能够 cache hit(主从同步没有完成,缓存中放入了旧数据)
(6)最后,主从同步完成
导致的结果是:旧数据放入缓存,即使主从同步完成,后续仍然会从缓存一直读取到旧数据。
可以看到,加入缓存后,导致的不一致影响时间会很长,并且最终也不会达到一致。
问题分析
可以看到,这里提到的缓存与数据库数据不一致,根本上是由数据库主从不一致引起的。当主库上发生写操作之后,从库 binlog 同步的时间间隔内,读请求,可能导致有旧数据入缓存。
思路:那能不能写操作记录下来,在主从时延的时间段内,读取修改过的数据的话,强制读主,并且更新缓存,这样子缓存内的数据就是最新。在主从时延过后,这部分数据继续读从库,从而继续利用从库提高读取能力。
不一致解决方案
选择性读主
可以利用一个缓存记录必须读主的数据。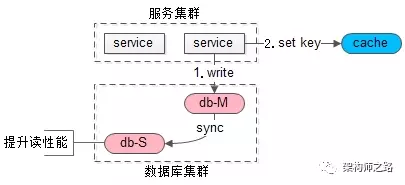
如上图,当写请求发生时:
(1)写主库
(2)将哪个库,哪个表,哪个主键三个信息拼装一个 key 设置到 cache 里,这条记录的超时时间,设置为 “主从同步时延”
PS:key 的格式为 “db:table:PK”,假设主从延时为 1s,这个 key 的 cache 超时时间也为 1s。
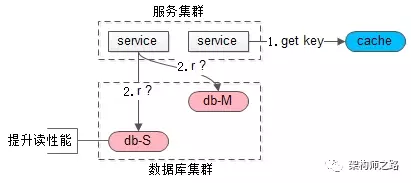
如上图,当读请求发生时:
这是要读哪个库,哪个表,哪个主键的数据呢,也将这三个信息拼装一个 key,到 cache 里去查询,如果,
(1)cache 里有这个 key,说明 1s 内刚发生过写请求,数据库主从同步可能还没有完成,此时就应该去主库查询。并且把主库的数据 set 到缓存中,防止下一次 cahce miss。
(2)cache 里没有这个 key,说明最近没有发生过写请求,此时就可以去从库查询
以此,保证读到的一定不是不一致的脏数据。
PS:如果系统可以接收短时间的不一致,建议建议定时更新缓存就可以了。避免系统过于复杂。