因为UNP第三部分(第三版13-31章)的内容结合APUE(UNIX环境高级编程)和TLPI(The Linux Programming Interface)来看才能比较清晰,所以笔记整理会穿插很多这两本书的内容
引申知识,作业控制以及相关命令
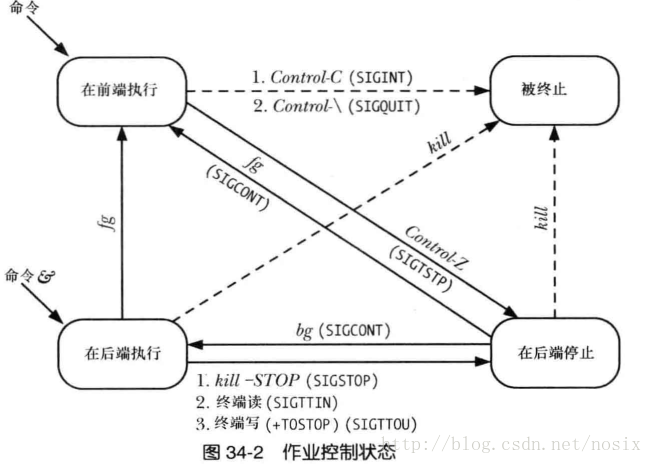
注: 但是如上方到后台执行的进程,其父进程还是当前终端shell的进程,而一旦父进程退出,则会发送hangup信号给所有子进程,子进程收到hangup以后也会退出。
13.4节
本节主要讲守护进程的相关知识
创建守护进程的步骤
自定义一个daemon_init函数,涉及到知识点为“如何创建一个daemon(守护进程)”,实现步骤如下(两fork一set, u工文dev):
(1)首先要做的是调用umask将文件模式创建屏蔽字设置为一个已知值(通常是0)。
由继承得来的文件模式创建屏蔽字可能会被设置为拒绝某些权限。如果守护进程要创建文件,那么它可能要设置特定的权限。例如,若守护进程要创建组可读、组可写的文件,继承的文件模式创建屏蔽字可能会屏蔽上述两种权限中的一种,而使其无法发挥作用。另一方面,如果守护进程调用的库函数创建了文件,那么将文件模式创建屏蔽字设置为一个限制性更强的值(如007)可能会更明智,因为库函数可能不允许调用者通过一个显式的函数参数来设置权限。
(2)调用fork,然后使父进程exit。
这样做实现了下面几点。第一,如果该守护进程是作为一条简单的shell命令启动的,那么父进程终止会让shell认为这条命令已经执行完毕。
第二,虽然子进程继承了父进程的进程组ID,但获得了一个新的进程ID,这就保证了子进程不是一个进程组的组长进程。这是下面将要进行的setsid调用的先决条件。
(3)调用setsid创建一个新会话。
使调用进程:(a)成为新会话的首进程,(b)成为一个新进程组的组长进程.(c)没有控制终端。也可概括为 : 开启一个新会话并释放它与控制终端之间的所有关联关系
(4)再次fork并杀掉首进程.
这样就确保了子进程不是一个会话首进程, 根据linux中获取终端的规则(只有会话首进程才能请求一个控制终端), 这样进程永远不会重新请求一个控制终端
(5)将当前工作目录更改为根目录。
从父进程处继承过来的当前工作目录可能在一个挂载的文件系统中。因为守护进程通常在系统再引导之前是一直存在的,所以如果守护进程的当前工作目录在一个挂载文件系统中,那么该文件系统就不能被卸载。
或者,某些守护进程还可能会把、与前工作目录更改到某个指定位置,并在此位置进行它们的
全部工作。例如,如果守护进程的当前工作目录是/usr/home目录,那么管理员在卸载/usr分区时会报错的。为了避免这个问题,可以调用chdir()函数将工作目录设置为根目录/。
(6)关闭不再需要的文件描述符。
这使守护进程不再持有从其父进程继承来的任何文件描述符(父进程可能是shell进程,或某个其他进程)。
可以使用open_max函数(见2.17节)或
getrlimit函数(见7.11节)来判定最高文件描述符值,并关闭直到该值的所有描述符。
(7) (这一步不是必要的)某些守护进程打开/dev/null使其具有文件描述符0、l和2.这样,任何一个试图读标准输入、写标准输出或标准错误的库例程都不会产生任何效果。
因为守护进程并不与终端设备相关联,所以其输出无处显示,也无处从交互式用户那里接收输入。
即使守护进程是从交互式会话启动的,但是守护进程是在后台运行的,所以登录会话的终止并不影响守护进程。如果其他用户在同一终端设备上登录,我们不希望在该终端上见到守护进程的输出,用户也不期望他们在终端上的输入被守护进程读取。
(
在关闭了文件描述符0、1和2之后,daemon通常会打开/dev/null并使用dup2()(或类似
的函数)使所有这些描述符指向这个设备。之所以要这样做是因为下面两个原因 :
- 它确保了当daemon调用了在这些描述符上执行I/O的库函数时不会出乎意料地
失败。 - 它防止了daemon后面使用描述符1或2打开…个文件的情况,因为库函数会将这些
描述符当做标准输出和标准错误来写入数据(进而破坏了原有的数据)。
)
进程组与会话
1 | 会 话 |
进程组
进程组就是一系列相互关联的进程集合,系统中的每一个进程也必须从属于某一个进程组;每个进程组中都会有一个唯一的 ID(process group id),简称 PGID;PGID 一般等同于进程组的创建进程的 Process ID,而这个进进程一般也会被称为进程组先导 (process group leader),同一进程组中除了进程组先导外的其他进程都是其子进程;
进程组的存在,方便了系统对多个相关进程执行某些统一的操作,例如,我们可以一次性发送一个信号量给同一进程组中的所有进程。
又例如:1
2
3
4
5$ ps -o pid,pgid,ppid,comm | cat
PID PGID PPID COMMAND
10179 10179 10177 bash
10263 10263 10179 ps
10264 10263 10179 cat
下边通过简单的示例来理解进程组
bash:进程和进程组ID都是 10179,父进程其实是 sshd(10177)
ps:进程和进程组ID都是 10263,父进程是 bash(10179),因为是在 Shell 上执行的命令
cat:进程组 ID 与 ps 的进程组 ID 相同,父进程同样是 bash(10179)
会话
会话(session)是一个若干进程组的集合,同样的,系统中每一个进程组也都必须从属于某一个会话;一个会话只拥有最多一个控制终端(也可以没有),该终端为会话中所有进程组中的进程所共用。一个会话中前台进程组只会有一个,只有其中的进程才可以和控制终端进行交互;除了前台进程组外的进程组,都是后台进程组;和进程组先导类似,会话中也有会话先导 (session leader) 的概念,用来表示建立起到控制终端连接的进程。在拥有控制终端的会话中,session leader 也被称为控制进程(controlling process),一般来说控制进程也就是登入系统的 shell 进程(login shell);

执行睡眠后台进程 sleep 50 & 之后,通过 ps 命令查看该进程及 shell 信息如上图:
- PPID 指父进程 id;
- PID 指进程 id;
- PGID 指进程组 id
- SID 指会话 id;
- TTY 指会话的控制终端设备;
- COMMAND 指进程所执行的命令
- TPGID 指前台进程组的 PGID。
dup介绍
函数原型 : int dup( int oldfd )
dup() 调用复制一个打开的文件描述符 oldfd , 并返回一个新描述符, 二者都指向同一打开的文件句柄. 系统会保证新描述符一定是编号值最低的未用文件描述符.
假设发起如下调用 :
newfd = dup(1);
再假定在正常情况下, shell已经代表程序打开了文件描述符0, 1和2, 且没有其他描述符在用, dup()调用会创建文件描述符1的副本, 返回的文件描述符编号值为3.
如果希望返回的文件描述符为2, 可以使用如下技术 :
1 | close(2); |
只有当描述符 0 已经打开时, 这段代码方可工作.
dup2介绍
如果想进一步简化上述代码, 同时总是能获得所期望的文件描述符, 可以调用dup2().
函数原型 : int dup2( int oldfd, int newfd )
dup2函数跟dup函数相似,但dup2函数允许调用者规定一个有效描述符和目标描述符的id
。dup2函数成功返回时,目标描述符(dup2函数的第二个参数)将变成源描述符(dup2函数的
第一个参数)的复制品,换句话说,两个文件描述符现在都指向同一个文件,并且是函数第一
个参数指向的文件。
下面我们用一段代码加以说明:1
2
3
4int oldfd;
oldfd = open("app_log", (O_RDWR | O_CREATE), 0644 );
dup2( oldfd, 1 );
close( oldfd );
本例中,我们打开了一个新文件,称为“app_log”,并收到一个文件描述符,该描述符
叫做fd1。我们调用dup2函数,参数为oldfd和1,这会导致用我们新打开的文件描述符替换掉
由1代表的文件描述符(即stdout,因为标准输出文件的id为1)。任何写到stdout的东西,现
在都将改为写入名为“app_log”的文件中。
umask介绍
当我们登录系统之后创建一个文件总是有一个默认权限的,那么这个权限是怎么来的呢?这就是umask干的事情。umask设置了用户创建文件的默认 权限,它与chmod的效果刚好相反,umask设置的是权限“补码”,而chmod设置的是文件权限码。
如何计算umask
umask 命令允许你设定文件创建时的缺省模式,对应每一类用户(文件属主、同组用户、其他用户)存在一个相应的umask值中的数字。对于文件来说,这一数字的最 大值分别是6。系统不允许你在创建一个文本文件时就赋予它执行权限,必须在创建后用chmod命令增加这一权限。目录则允许设置执行权限,这样针对目录来 说,umask中各个数字最大可以到7。
例如,对于umask值0 0 2,相应的文件和目录缺省创建权限是什么呢?
第一步,我们首先写下目录具有全部权限的模式,即777 (所有用户都具有读、写和执行权限)。
第二步,在下面一行按照umask值写下相应的位,在本例中是0 0 2。
第三步,在接下来的一行中记下上面两行中没有匹配的位。这就是目录的缺省创建权限。
稍加练习就能够记住这种方法。
第四步,对于文件来说,在创建时不能具有执行权限,只要拿掉相应的执行权限比特即可。
这就是上面的例子, 其中umask值为0 0 2:
1) 文件的最大权限 rwx rwx rwx (777)
2) umask值为0 0 2 — — -w-
3) 目录权限 rwx rwx r-x (775) 这就是目录创建缺省权限
4) 文件权限 rw- rw- r– (664) 这就是文件创建缺省权限
下面是另外一个例子,假设这次u m a s k值为0 2 2:
1) 文件的最大权限 rwx rwx rwx (777)
2 ) u m a s k值为0 2 2 — -w- -w-
3) 目录权限 rwx r-x r-x (755) 这就是目录创建缺省权限
4) 文件权限 rw- r– r– (644) 这就是文件创建缺省权限
创建守护进程的例子程序
下面是becomeDaemon()函数的实现,becomeDaeomon()函数接收一个位掩码参数flags,它允许调用者有选择地执行其中的步
骤,具体可参考注释。
1 |
|
1 |
|
nohup和setsid用法
如果我们要在退出shell的时候继续运行进程,则需要
- setsid将父进程设为init进程
- 使用nohup忽略SIGHUP信号
注: (SIGHUP 信号在 用户终端连接 (正常或非正常) 结束 时发出, 通常是在终端的控制进程结束时, 通知同一 session 内的各个作业, 这时它们与控制终端不再关联. 系统对 SIGHUP 信号的默认处理是终止收到该信号的进程。所以若程序中没有捕捉该信号,当收到该信号时,进程就会退出。),

nohup详解
nohup介绍用途: 不挂断地运行命令。
语法:nohup Command [Arg …] [ & ]
- 无论是否将 nohup 命令的输出重定向到终端,输出都将附加到当前目录的 nohup.out 文件中。
- 如果当前目录的 nohup.out 文件不可写,输出重定向到 $HOME/nohup.out 文件中。
- 如果没有文件能创建或打开以用于追加,那么 Command 参数指定的命令不可调用。
退出状态:该命令返回下列出口值:
- 126 可以查找但不能调用 Command 参数指定的命令。
- 127 nohup 命令发生错误或不能查找由 Command 参数指定的命令。否则 nohup 命令的退出状态是 Command 参数指定命令的退出状态。
nohup和&的关系
使用nohup 运行程序:
- 输出重定向,默认重定向到当前目录下 nohup.out 文件
- 使用 Ctrl + C 发送 SIGINT 信号,程序关闭
- 关闭 Shell Session 发送 SIGHUP 信号,程序免疫使用
& 运行程序:
- 程序转入后台运行
- 结果会输出到终端
-使用 Ctrl + C 发送 SIGINT 信号,程序免疫 - 关闭 Shell session 发送 SIGHUP 信号,程序关闭
nohup和&使用实例
一般两个一起组合使用不会受 Ctrl C 和 Shell 关闭的影响:
1 | # 最简单的后台运行 |
由于使用 nohup 时,会自动将输出写入 nohup.out 文件中,如果文件很大的话,nohup.out 就会不停的增大,
我们可以利用 Linux 下一个特殊的文件 /dev/null 来解决这个问题,这个文件就相当于一个黑洞,任何输出到这个文件的东西都将消失 只保留输出错误信息 nohup command >/dev/null 2>log & 所有信息都不要 nohup command >/dev/null 2>&1 &
这里解释一下后面的 2>&1 。参考重定向知识
其他相关命令
1 | # 结束当前任务 |
实战
1 | b@b-VirtualBox:~/my_temp_test$ nohup ./o_multi_thread_process & |
disown用法
那么对于已经在后台运行的进程,如果我们要在退出shell的时候继续运行进程, 该怎么办呢?可以使用disown命令
1 | b@b-VirtualBox:~/my_temp_test$ ./o_multi_thread_process & |
重定向知识
在 shell 脚本中,默认情况下,总是有三个文件处于打开状态,标准输入 (键盘输入)、标准输出(输出到屏幕)、标准错误(也是输出到屏幕),它们分别对应的文件描述符是 0,1,2 。
的意思是把标准输出重定向,与 1> 相同
- 2>&1 的意思是把 标准错误输出 重定向到 标准输出.
- &>file 的意思是把标准输出 和 标准错误输出 都重定向到文件 file 中
- /dev/null 是一个文件,这个文件比较特殊,所有传给它的东西它都丢弃掉
举例说明:
当前目录只有一个文件 a.txt.1
2
3
4[root@redhat box]# ls
a.txt
[root@redhat box]# ls a.txt b.txt
ls: b.txt: No such file or directory
由于没有 b.txt 这个文件, 于是返回错误值, 这就是所谓的 2 输出
a.txt 而这个就是所谓的 1 输出
再接着看:
[root@redhat box]# ls a.txt b.txt 1>file.out 2>file.err
执行后, 没有任何返回值. 原因是, 返回值都重定向到相应的文件中了, 而不再前端显示1
2
3
4[root@redhat box]# cat file.out
a.txt
[root@redhat box]# cat file.err
ls: b.txt: No such file or directory
一般来说, “1>” 通常可以省略成 “>”.
即可以把如上命令写成: ls a.txt b.txt >file.out 2>file.err
有了这些认识才能理解 “1>&2” 和 “2>&1”.
1>&2 正确返回值传递给 2 输出通道 &2 表示 2 输出通道
如果此处错写成 1>2, 就表示把 1 输出重定向到文件 2 中.
2>&1 错误返回值传递给 1 输出通道, 同样 & 1 表示 1 输出通道.
举个例子.1
2
3
4[root@redhat box]# ls a.txt b.txt 1>file.out 2>&1
[root@redhat box]# cat file.out
ls: b.txt: No such file or directory
a.txt
现在, 正确的输出和错误的输出都定向到了 file.out 这个文件中, 而不显示在前端.
补充下, 输出不只 1 和 2, 还有其他的类型, 这两种只是最常用和最基本的.
例如:rm -f $(find / -name core) &> /dev/null,
/dev/null 是一个文件,这个文件比较特殊,所有传给它的东西它都丢弃掉。
例如:
注意,为了方便理解,必须设置一个环境使得执行 grep da * 命令会有正常输出和错误输出,然后分别使用下面的命令生成三个文件:1
2
3
4grep da * > greplog1
grep da * > greplog2 1>&2
grep da * > greplog3 2>&1
grep da * 2> greplog4 1>&2
- 查看 greplog1 会发现里面只有正常输出内容
- 查看 greplog2 会发现里面什么都没有
- 查看 greplog3 会发现里面既有正常输出内容又有错误输出内容
- 查看 greplog4 会发现里面既有正常输出内容又有错误输出内容