分布式系统中的概念
最简单的分布式系统
分布式可繁也可以简,最简单的分布式就是大家最常用的,
在负载均衡服务器后加一堆web服务器,然后在上面搞一个缓存服务器来保存临时状态,
后面共享一个数据库,其实很多号称分布式专家的人也就停留于此,
大致结构如下图所示:
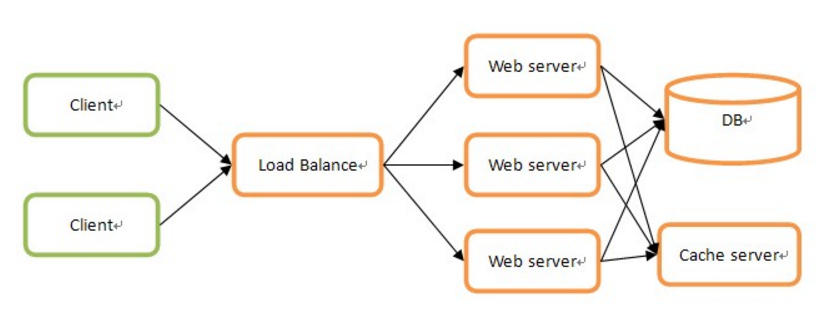
这种环境下真正进行分布式的只是web server而已,
并且web server之间没有任何联系,所以结构和实现都非常简单。
最完备的分布式体系的模块组成
有些情况下,对分布式的需求就没这么简单,
在每个环节上都有分布式的需求,
比如Load Balance、DB、Cache和文件等等,
并且当分布式节点之间有关联时,
还得考虑之间的通讯,
另外,
节点非常多的时候,
得有监控和管理来支撑。这样看起来,
分布式是一个非常庞大的体系,
只不过你可以根据具体需求进行适当地裁剪。按照最完备的分布式体系来看,
可以由以下模块组成:
分布式任务处理服务:负责具体的业务逻辑处理
分布式节点注册和查询:负责管理所有分布式节点的命名和物理信息的注册与
询,是节点之间联系的桥梁分布式DB:分布式结构化数据存取
分布式Cache:分布式缓存数据(非持久化)存取
分布式文件:分布式文件存取
网络通信:节点之间的网络数据通信
监控管理:搜集、监控和诊断所有节点运行状态
分布式编程语言:用于分布式环境下的专有编程语言,比如Elang、Scala
分布式算法:为解决分布式环境下一些特有问题的算法,比如解决一致性问题的Paxos算法
三元组
其实,分布式系统说白了,就是很多机器组成的集群,靠彼此之间的网络通信,担当的角色可能不同,共同完成同一个事情的系统。
如果按”实体“来划分的话,就是如下这几种:
1、节点 – 系统中按照协议完成计算工作的一个逻辑实体,可能是执行某些工作的进程或机器
2、网络 – 系统的数据传输通道,用来彼此通信。
通信是具有方向性的。
- 3、存储 – 系统中持久化数据的数据库或者文件存储。
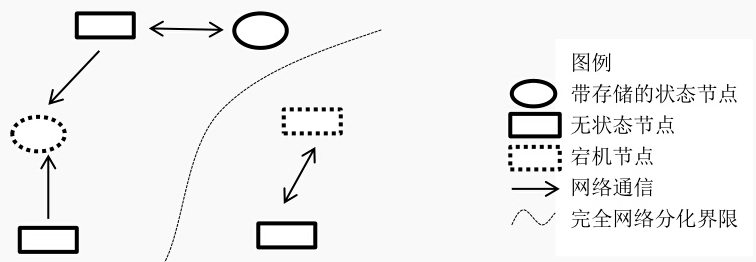
状态特性
各个节点的状态可以是“无状态”或者“有状态的”,
一般认为,节点是偏计算和通信的模块,一般是无状态的。
这类应用一般不会存储自己的中间状态信息,比如Nginx,一般情况下是转发请求而已,不会存储中间信息。
另一种“有状态”的,如MySQL等数据库,状态和数据全部持久化到磁盘等介质。
“无状态”的节点一般我们认为是可随意重启的,因为重启后只需要立刻工作就好。
“有状态”的则不同,需要先读取持久化的数据,才能开始服务。
所以,“无状态”的节点一般是可以随意扩展的,“有状态”的节点需要一些控制协议来保证扩展。
系统异常
异常,可认为是节点因为某种原因不能工作,此为节点异常。
还有因为网络原因,临时、永久不能被其他节点所访问,此为网络异常。
在分布式系统中,要有对异常的处理,保证集群的正常工作。
分布式系统与单节点的不同
从linux write()系统调用说起
众所周知,在unix/linux/mac(类Unix)环境下,两个机器通信,最常用的就是通过socket连接对方。
传输数据的话,无非就是调用write()这个系统调用,把一段内存缓冲区发出去。
但是可以进一步想一下,write()之后能确认对方收到了这些数据吗?
答案肯定是不能,原因就是发送数据需要走内核->网卡->链路->对端网卡->内核,这一路径太长了,所以只能是异步操作。
write()把数据写入内核缓冲区之后就返回到应用层了,具体后面何时发送、怎么发送、TCP怎么做滑动窗口、流控都是tcp/ip协议栈内核的事情了。
所以在应用层,能确认对方受到了消息只能是对方应用返回数据,逻辑确认了这次发送才认为是成功的。
这就却别与单系统编程,大部分系统调用、库调用只要返回了就说明已经确认完成了。
TCP/IP协议是“不可靠”的
教科书上明确写明了互联网是不可靠的,TCP实现了可靠传输。
何来“不可靠”呢?先来看一下网络交互的例子,有A、B两个节点,之间通过TCP连接,现在A、B都想确认自己发出的任何一条消息都能被对方接收并反馈,于是开始了如下操作:
A->B发送数据,然后A需要等待B收到数据的确认,B收到数据后发送确认消息给A,然后B需要等待A收到数据的确认,A收到B的数据确认消息后再次发送确认消息给B,然后A又去需要等待B收到的确认。
死循环了!!
其实,这就是著名的“拜占庭将军”问题
所以,通信双方是“不可能”同时确认对方受到了自己的信息。
而教科书上定义的其实是指“单向”通信是成立的,比如A向B发起Http调用,
收到了HttpCode 200的响应包,这只能确认,A确认B收到了自己的请求,并且B正常处理了,不能确认的是B确认A受到了它的成功的消息。
不可控的状态
在单系统编程中,我们对系统状态是非常可控的。
比如函数调用、逻辑运算,要么成功,要么失败,因为这些操作被框在一个机器内部,cpu/总线/内存都是可以快速得到反馈的。
开发者可以针对这两个状态很明确的做出程序上的判断和后续的操作。
而在分布式的网络环境下,这就变得微妙了。
比如一次rpc、http调用,可能成功、失败,还有可能是“超时”,这就比前者的状态多了一个不可控因素,导致后面的代码不是很容易做出判断。
试想一下,用A用支付宝向B转了一大笔钱,当他按下“确认”后,界面上有个圈在转啊转,然后显示请求超时了,然后A就抓狂了,不知道到底钱转没转过去,开始确认自己的账户、确认B的账户、打电话找客服等等。
所以分布式环境下,我们的其实要时时刻刻考虑面对这种不可控的“第三状态”设计开发,这也是挑战之一。
视异常为正常
单系统下,进程/机器的异常概率十分小。
即使出现了问题,可以通过人工干预重启、迁移等手段恢复。
但在分布式环境下,机器上千台,每几分钟都可能出现宕机、死机、网络断网等异常,出现的概率很大。
所以,这种环境下,进程core掉、机器挂掉都是需要我们在编程中认为随时可能出现的,这样才能使我们整个系统健壮起来,所以”容错“是基本需求。
异常可以分为如下几类:
- 节点错误:
一般是由于应用导致,一些coredump和系统错误触发,一般重新服务后可恢复。
- 硬件错误:
由于磁盘或者内存等硬件设备导致某节点不能服务,需要人工干预恢复。
- 网络错误:
由于点对点的网络抖动,暂时的访问错误,一般拓扑稳定后或流量减小可以恢复。
网络分化:
网络中路由器、交换机错误导致网络不可达,但是网络两边都正常,这类错误比较难恢复,并且需要在开发时特别处理。 【这种情况也会比较前面的问题较难处理】